Synergistic Perception-Reasoning Governance: Grounding Medical MLLMs with Verifiable Anatomical Evidence
Pith reviewed 2026-07-02 20:02 UTC · model grok-4.3
The pith
A training-free framework grounds medical MLLMs with ROI-derived anatomical evidence to reduce hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
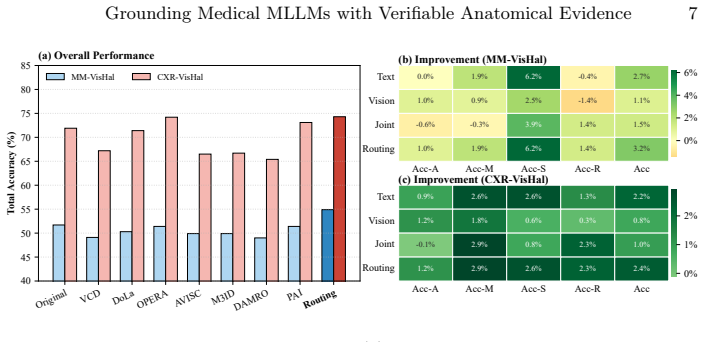
Dual-side evidence injection via ROI-guided activation modulation for perception and anatomical coordinate mapping to semantic tokens for reasoning, selected by a task-aware dynamic router, mitigates hallucinations in medical MLLMs, yielding up to 6 percent higher close-ended accuracy and 35 percent fewer open-ended hallucinations across LLaVA, Qwen, and InternVL models on five datasets.
What carries the argument
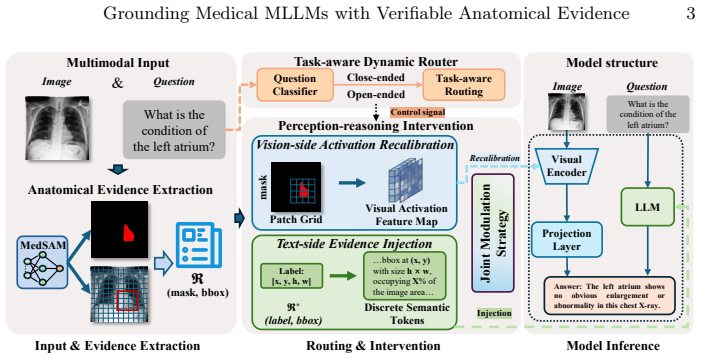
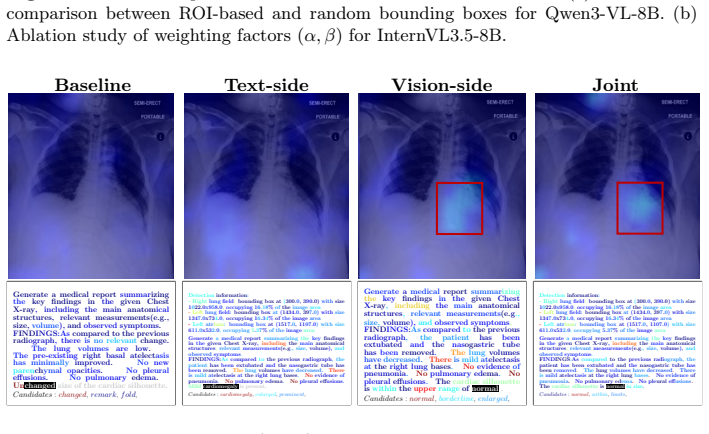
Dual-side evidence injection that recalibrates the visual perception trajectory with ROI-guided activation modulation and anchors the textual reasoning trajectory by mapping anatomical coordinates into discrete semantic tokens, chosen by a task-aware dynamic router.
If this is right
- Close-ended medical VQA accuracy rises by up to 6 percent on the evaluated benchmarks.
- Open-ended hallucinations drop by approximately 35 percent without added training cost.
- The same framework applies to multiple base models including LLaVA-1.5-7B, Qwen3-VL variants, and InternVL-3.5 variants.
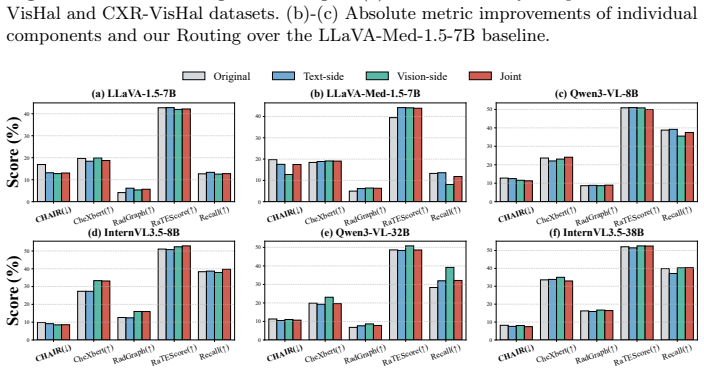
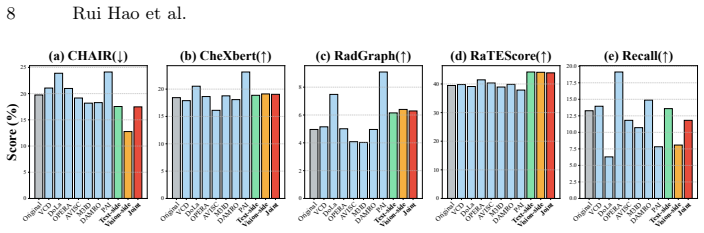
- Controlled ablations confirm that both perception recalibration and reasoning anchoring contribute to the gains.
- The method remains training-free and generalizes across two tasks and five datasets.
Where Pith is reading between the lines
- The separation of perception recalibration from reasoning anchoring could be tested as independent modules on non-medical vision-language tasks.
- If coordinate-to-token mapping proves robust, similar discrete memory mechanisms might reduce hallucinations in other grounded reasoning domains.
- The router's task-semantic selection offers a testable route for extending the approach to new clinical subtasks without redesigning the full pipeline.
Load-bearing premise
ROI priors extracted by MedSAM stay accurate enough across different imaging conditions and the router chooses interventions without creating new perceptual or linguistic mistakes.
What would settle it
Performance gains disappear on a held-out test set of images where MedSAM ROI extraction produces large segmentation errors under varied contrast or noise conditions.
Figures
read the original abstract
Multimodal large language models (MLLMs) show strong promise for clinical VQA and radiology report generation, yet inference-time hallucinations still undermine trustworthy use: models can produce fluent conclusions that conflict with imaging evidence. Existing mitigation strategies typically rely on additional training, external retrieval/knowledge bases, or multi-stage post-hoc verification, which increases cost and pipeline complexity and often generalizes poorly across models and tasks.To address this, we propose a holistic, training-free evidence-injection framework that systematically mitigates hallucinations through dual-side evidence injection. By leveraging ROI priors acquired using MedSAM in our implementation, we recalibrate the visual perception trajectory via ROI-guided activation modulation while anchoring the textual reasoning trajectory by mapping anatomical coordinates into discrete semantic tokens as verifiable external memory. Then we introduce a task-aware dynamic router to select modality-specific interventions based on task semantics, balancing perceptual grounding and linguistic fluency. We conduct systematic evaluations on 2 tasks and 5 datasets using \texttt{LLaVA-1.5-7B}, \texttt{LLaVA-Med-1.5-7B}, \texttt{Qwen3-VL-8B/32B}, and \texttt{InternVL-3.5-8B/38B}. Controlled ablations and visualizations further validate the framework, which consistently outperforms baselines across medical benchmarks, improving close-ended accuracy by up to $\sim\mathbf{6}\%\uparrow$ and reducing open-ended hallucinations by $\sim\mathbf{35}\%\downarrow$. The code has been made available on GitHub: \href{https://github.com/Henry991115/SPRG}{\textcolor{blue}{https://github.com/Henry991115/SPRG}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPRG, a training-free framework for medical MLLMs that injects verifiable anatomical evidence via MedSAM-derived ROI priors: ROI-guided activation modulation for visual perception and coordinate-to-token memory injection for textual reasoning, selected by a task-aware dynamic router. Evaluations on close-ended VQA and open-ended report generation across five datasets and multiple models (LLaVA-1.5-7B, LLaVA-Med, Qwen3-VL, InternVL) report up to ~6% accuracy gains and ~35% hallucination reduction, supported by controlled ablations and visualizations; code is released.
Significance. If the central claims hold after addressing the MedSAM validation gap, the work provides a lightweight, model-agnostic method for grounding MLLMs with anatomical evidence without retraining or external retrieval, which could meaningfully improve trustworthiness in clinical VQA and report generation. The training-free design, multi-model evaluation, and public code release are positive factors for adoption and reproducibility.
major comments (2)
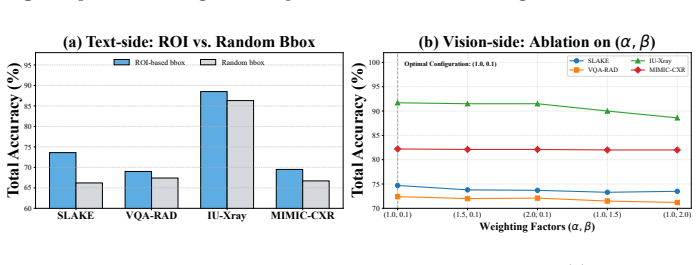
- [§4 and §3.2] §4 (Experiments) and §3.2 (ROI-guided modulation): the headline gains of ~6% accuracy and ~35% hallucination reduction presuppose that MedSAM ROIs are sufficiently accurate on the five evaluation datasets to modulate tokens and supply non-misleading coordinates, yet no quantitative MedSAM error rates (e.g., Dice/IoU on the test splits), no ablation replacing MedSAM ROIs with ground-truth segmentations, and no ablation with controlled noise are reported; this leaves open whether the improvements are robust or conditional on imaging conditions where MedSAM succeeds.
- [§3.3] §3.3 (task-aware dynamic router): the router selects modality-specific interventions based on task semantics, but the manuscript provides no mechanism to gate or down-weight low-confidence MedSAM ROIs before they reach the router or the memory injection step; without such a safeguard or an ablation that measures router error propagation under ROI noise, it is unclear whether the framework can avoid introducing new perceptual or semantic errors.
minor comments (2)
- [Abstract and §4] The abstract and §4 mention "controlled ablations" but do not list which components (router, modulation, memory injection) were ablated or report per-component deltas; adding an explicit ablation table would strengthen the validation.
- [§3] Notation for the coordinate-to-token mapping and the activation modulation function is introduced without an equation number or pseudocode; a compact formal definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the MedSAM validation gap and router safeguards. We address each point below and will revise the manuscript accordingly to strengthen the evidence for robustness.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (ROI-guided modulation): the headline gains of ~6% accuracy and ~35% hallucination reduction presuppose that MedSAM ROIs are sufficiently accurate on the five evaluation datasets to modulate tokens and supply non-misleading coordinates, yet no quantitative MedSAM error rates (e.g., Dice/IoU on the test splits), no ablation replacing MedSAM ROIs with ground-truth segmentations, and no ablation with controlled noise are reported; this leaves open whether the improvements are robust or conditional on imaging conditions where MedSAM succeeds.
Authors: We agree this is a substantive gap. The framework relies on MedSAM-derived ROIs, and without reported segmentation metrics or robustness ablations the source of the observed gains remains partially opaque. In the revised manuscript we will add: (1) Dice and IoU scores computed for MedSAM on the test splits of all five datasets, (2) an ablation that substitutes ground-truth segmentations (where available) for MedSAM ROIs, and (3) a controlled noise-injection study that perturbs ROI coordinates and masks at varying levels. These additions will directly quantify the dependence on MedSAM accuracy and demonstrate whether the dual-side injection remains beneficial under realistic segmentation error. revision: yes
-
Referee: [§3.3] §3.3 (task-aware dynamic router): the router selects modality-specific interventions based on task semantics, but the manuscript provides no mechanism to gate or down-weight low-confidence MedSAM ROIs before they reach the router or the memory injection step; without such a safeguard or an ablation that measures router error propagation under ROI noise, it is unclear whether the framework can avoid introducing new perceptual or semantic errors.
Authors: The observation is correct: the current router description contains no explicit confidence gating for MedSAM outputs, leaving open the possibility of error propagation. We will revise §3.3 to incorporate a lightweight confidence gate that uses MedSAM’s internal mask-quality scores (or an auxiliary uncertainty estimate) to down-weight or bypass low-confidence ROIs before they reach either the modulation or memory-injection modules. We will also add an ablation that systematically varies ROI noise levels and reports both router decision accuracy and end-to-end task metrics, thereby quantifying error propagation and the effectiveness of the proposed safeguard. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation of an external-component framework
full rationale
The manuscript describes a training-free method that injects MedSAM-derived ROI priors via activation modulation and coordinate-to-token mapping, then routes interventions with a task-aware dynamic router. All performance numbers (∼6% accuracy lift, ∼35% hallucination reduction) are reported as outcomes of controlled experiments on five datasets with multiple base MLLMs. No equations, fitted parameters, or derivation steps appear in the abstract or described pipeline; the gains are not presented as mathematical consequences of the method's own definitions. MedSAM is treated as an external black-box prior rather than a self-derived quantity. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are referenced. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: AAAI 2024 Spring Symposium Series (Clinical Foundation Models)
Chen, Z., Varma, M., Delbrouck, J.-B., Paschali, M., Blankemeier, L., Van Veen, D., et al.: CheXagent: Towards a foundation model for chest X-ray interpretation. In: AAAI 2024 Spring Symposium Series (Clinical Foundation Models). OpenRe- view.net (2024).https://openreview.net/forum?id=P3LOmrZWGR
2024
-
[2]
In: Proceedings of the 3rd Machine Learning for Health Symposium (ML4H 2023)
Moor, M., Huang, Q., Wu, S., Yasunaga, M., Dalmia, Y., Leskovec, J., Zakka, C., Reis, E.P., Rajpurkar, P.: Med-Flamingo: A multimodal medical few-shot learner. In: Proceedings of the 3rd Machine Learning for Health Symposium (ML4H 2023). Proceedings of Machine Learning Research, vol. 225, pp. 353–367. PMLR (2023)
2023
-
[3]
In: Proceedings of the 23rd Workshop on Biomedical Natural Language Processing (BioNLP 2024), pp
Thawakar, O.C., Shaker, A.M., Mullappilly, S.S., Cholakkal, H., Anwer, R.M., Khan, S., Laaksonen, J., Khan, F.: XrayGPT: Chest radiographs summarization using large medical vision-language models. In: Proceedings of the 23rd Workshop on Biomedical Natural Language Processing (BioNLP 2024), pp. 440–448. Associ- ation for Computational Linguistics (2024)
2024
-
[4]
Nature Communications16, 7866 (2025) 10 Rui Hao et al
Wu, C., Zhang, X., Zhang, Y., Hui, H., Wang, Y., Xie, W.: Towards generalist foun- dation model for radiology by leveraging web-scale 2D&3D medical data. Nature Communications16, 7866 (2025) 10 Rui Hao et al
2025
-
[5]
In: International Conference on Learning Representations (ICLR) (Poster) (2024)
Lee, S., Kim, W.J., Chang, J., Ye, J.C.: LLM-CXR: Instruction-finetuned LLM for CXR image understanding and generation. In: International Conference on Learning Representations (ICLR) (Poster) (2024). OpenReview.net.https:// openreview.net/forum?id=BqHaLnans2
2024
-
[6]
In: Proceedings of the 2025 International Conference on Multimedia Retrieval (ICMR), pp
Jing, L., Zhang, Y., Du, X.: Tutorial proposal: Hallucinations in large language models and large vision-language models. In: Proceedings of the 2025 International Conference on Multimedia Retrieval (ICMR), pp. 2138–2139 (2025)
2025
-
[7]
Artificial Intelligence Review57(9) (2024)
Lin, Z., Guan, S., Zhang, W., Zhang, H., Li, Y., Zhang, H.: Towards trustwor- thy LLMs: A review on debiasing and dehallucinating in large language models. Artificial Intelligence Review57(9) (2024)
2024
-
[8]
International Journal of Computer Vision134(1) (2025)
Tu, C., Ye, P., Zhou, D., Bai, L., Yu, G., Chen, T., Ouyang, W.: Attention real- location: Towards zero-cost and controllable hallucination mitigation of MLLMs. International Journal of Computer Vision134(1) (2025)
2025
-
[9]
Chang, A., Huang, L., Bhatia, P., Kass-Hout, T., Ma, F., Xiao, C.: MedHEval: Benchmarking hallucinations and mitigation strategies in medical large vision- language models. arXiv:2503.02157 (2025)
-
[10]
In: Findings of the Association for Computational Linguistics: ACL 2025, pp
Zhu, Z., Zhang, Y., Zhuang, X., Zhang, F., Wan, Z., Chen, Y., Long, Q., Zheng, Y., Wu, X.: Can we trust AI doctors? A survey of medical hallucination in large language and large vision-language models. In: Findings of the Association for Computational Linguistics: ACL 2025, pp. 6748–6769. Association for Computa- tional Linguistics (2025)
2025
-
[11]
npj Digital Medicine8, 274 (2025)
Asgari, E., Montaña-Brown, N., Dubois, M., et al.: A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation. npj Digital Medicine8, 274 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13872–13882 (2024)
2024
-
[13]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Chuang, Y.-S., Xie, Y., Luo, H., Kim, Y., Glass, J., He, P.: DoLa: Decoding by contrasting layers improves factuality in large language models. arXiv:2309.03883 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: OPERA: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13418–13427 (2024)
2024
-
[15]
Woo, S., Kim, D., Jang, J., Choi, Y., Kim, C.: Don’t miss the forest for the trees: Attentional vision calibration for large vision language models. arXiv:2405.17820 (2024)
-
[16]
In: Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pp
Gong, X., Ming, T., Wang, X., Wei, Z.: DAMRO: Dive into the attention mecha- nism of LVLM to reduce object hallucination. In: Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pp. 7696– 7712 (2024)
2024
-
[17]
In: European Conference on Com- puter Vision (ECCV), pp
Liu, S., Zheng, K., Chen, W.: Paying more attention to image: A training-free method for alleviating hallucination in LVLMs. In: European Conference on Com- puter Vision (ECCV), pp. 125–140. Springer (2025)
2025
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Favero, A., Zancato, L., Trager, M., Choudhary, S., Perera, P., Achille, A., Swami- nathan, A., Soatto, S.: Multi-modal hallucination control by visual information grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14303–14312 (2024) Grounding Medical MLLMs with Verifiable Anatomical Evidence 11
2024
-
[19]
IEEE, pp
Liu,B.,Zhan,L.-M.,Xu,L.,Ma,L.,Yang,Y.,Wu,X.-M.:SLAKE:Asemantically- labeledknowledge-enhanceddatasetformedicalvisualquestionanswering.In:2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). IEEE, pp. 1650–1654 (2021)
2021
-
[20]
Scientific Data 5(1), 1–10 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data 5(1), 1–10 (2018)
2018
-
[21]
Journal of the American Medical Informatics Association23(2), 304–310 (2016)
Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiol- ogy examinations for distribution and retrieval. Journal of the American Medical Informatics Association23(2), 304–310 (2016)
2016
-
[22]
Scientific Data6(1), 317 (2019)
Johnson, A.E.W., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.-Y., Mark, R.G., Horng, S.: MIMIC-CXR, a de-identified publicly avail- able database of chest radiographs with free-text reports. Scientific Data6(1), 317 (2019)
2019
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 26296–26306 (2024)
2024
-
[24]
In: Advances in Neural Information Processing Systems, vol
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J.-W., Naumann, T., Poon, H., Gao, J.: LLaVA-Med: Training a large language-and-vision assistant for biomedicine in one day. In: Advances in Neural Information Processing Systems, vol. 36, pp. 28541–28564. Curran Associates, Inc. (2023)
2023
-
[25]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.