SDM-Q: Cost-Aware Staged Decision-Making for Multi-Omics Classification with Deep Q-Learning
Pith reviewed 2026-06-29 00:03 UTC · model grok-4.3
The pith
Deep Q-learning decides whether to acquire additional omics modalities or stop and classify, using a terminal reward that trades off accuracy against total cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
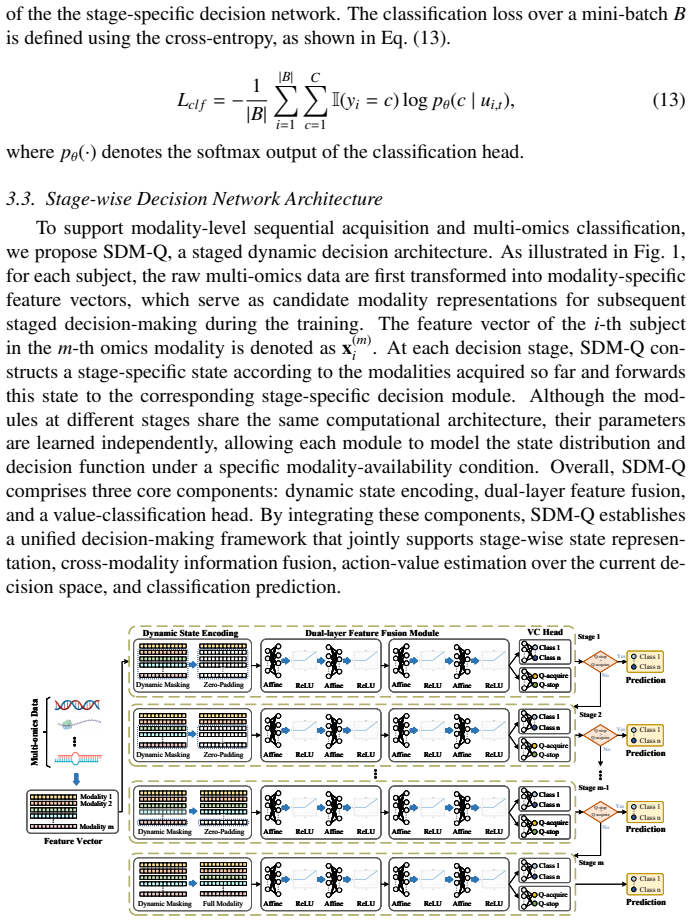
SDM-Q reformulates multi-omics classification as a finite-horizon Markov decision process whose state is the subset of acquired modalities, whose actions are to request a new modality or to terminate with a class prediction, and whose sole reward is a function of final classification correctness and negative cumulative cost; a deep Q-network learns the action-value function and a backward stage-wise optimization yields the policy.
What carries the argument
The action-value function that, at each stage, evaluates whether the expected improvement in terminal reward from acquiring one more modality exceeds its cost.
If this is right
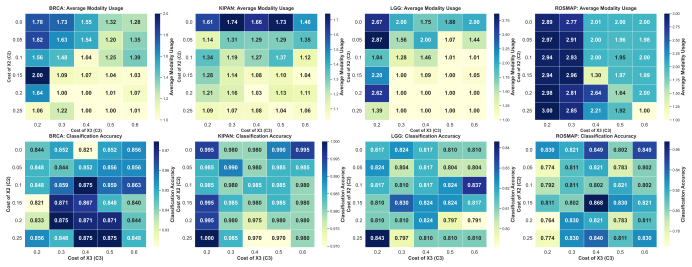
- More than 99 percent of subjects in the BRCA dataset receive accurate classification after a single modality.
- More than 95 percent of subjects in the KIPAN dataset receive accurate classification after a single modality.
- Average modalities acquired stay below two on the ROSMAP and LGG datasets.
- Classification performance remains competitive with methods that always receive the complete multi-omics input.
Where Pith is reading between the lines
- The same staged-decision structure could be applied to other costly multi-modal diagnostic pipelines that combine imaging, laboratory assays, and genetic panels.
- The backward optimization step may transfer to other finite-horizon reinforcement-learning settings that require early stopping decisions.
- Real-world use would need prospective validation to confirm that the learned stopping thresholds align with existing clinical workflows.
Load-bearing premise
The terminal reward defined only by final classification correctness and cumulative acquisition cost, together with backward stage-wise optimization, produces policies that stay stable and clinically relevant outside the four evaluated datasets.
What would settle it
A fifth multi-omics dataset, drawn from a different disease or population, on which the trained policy either requires an average number of modalities close to the full set or falls below the accuracy achieved by any full-modality baseline.
Figures
read the original abstract
Multi-omics data provide complementary molecular characterizations of disease phenotypes and play an important role in disease diagnosis and subtype classification in precision medicine. However, acquiring complete multi-omics profiles is expensive and time-consuming, while most existing deep learning methods assume full modality availability during inference, resulting in substantial redundancy and limited practicality in clinical settings. To address this issue, we propose SDM-Q, a reinforcement learning framework for adaptive and cost-aware multi-omics classification. Specifically, multi-omics diagnosis is reformulated as a finite-horizon sequential decision problem, where the currently acquired omics modalities define the diagnostic state at each stage. An action--value function determines whether to acquire an additional modality or terminate the decision process and output the final prediction. To balance diagnostic utility and acquisition cost, the reward is defined only at the terminal stage and jointly determined by classification correctness and cumulative modality acquisition cost. A backward stage-wise optimization strategy is introduced to improve policy consistency and training stability. Experiments on four public multi-omics datasets, including ROSMAP, LGG, BRCA, and KIPAN, demonstrate that SDM-Q effectively reduces redundant modality acquisition while maintaining competitive classification performance compared with methods using complete multi-omics inputs. In the BRCA and KIPAN datasets, more than 99\% and 95\% of subjects, respectively, achieve accurate classification using only a single omics modality, while the average number of acquired modalities remains below two for ROSMAP and LGG. These results suggest that cost-aware sequential decision-making provides an effective paradigm for improving the efficiency of precision medicine workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SDM-Q, a deep Q-learning framework that reformulates multi-omics classification as a finite-horizon sequential decision process. At each stage the state is the set of acquired modalities; the agent chooses either to acquire one more modality or to terminate and output a classification. The terminal reward balances classification correctness against cumulative acquisition cost. A backward stage-wise optimization procedure is used to train the action-value function. Experiments on the four public datasets ROSMAP, LGG, BRCA and KIPAN are reported to show that the learned policy achieves competitive accuracy while acquiring far fewer modalities on average (e.g., >99 % of BRCA subjects classified correctly from a single modality).
Significance. If the reported empirical results hold under proper controls, the work supplies a concrete, cost-sensitive paradigm for multi-omics diagnosis that could materially reduce the expense of precision-medicine workflows. The explicit modeling of modality acquisition as a staged MDP with a terminal reward that trades accuracy against cost is a clear technical contribution, and the use of four public datasets provides a reproducible starting point for further study.
major comments (1)
- [Experimental evaluation section] Experimental evaluation section: the manuscript supplies no description of train/test splits, preprocessing pipelines, baseline implementations, error bars, or statistical significance tests for the four datasets. Because the central claim is that SDM-Q “maintains competitive classification performance” while reducing modality count, the absence of these controls renders the quantitative results unverifiable and is load-bearing for the empirical conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental evaluation. We agree that the current manuscript lacks sufficient detail on experimental controls, which is necessary to support the central claims regarding classification performance and modality reduction. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Experimental evaluation section] Experimental evaluation section: the manuscript supplies no description of train/test splits, preprocessing pipelines, baseline implementations, error bars, or statistical significance tests for the four datasets. Because the central claim is that SDM-Q “maintains competitive classification performance” while reducing modality count, the absence of these controls renders the quantitative results unverifiable and is load-bearing for the empirical conclusion.
Authors: We acknowledge that the manuscript does not currently provide explicit descriptions of train/test splits, preprocessing pipelines, baseline implementations, error bars, or statistical significance tests. This is a valid concern that affects the verifiability of the reported results on ROSMAP, LGG, BRCA, and KIPAN. In the revised manuscript, we will expand the Experimental Evaluation section with a new subsection that includes: (i) details on train/test split ratios and any stratification or cross-validation procedures used; (ii) the full preprocessing pipelines applied to each dataset, including normalization, missing value handling, and feature selection; (iii) implementation details or references for all baselines; (iv) error bars (standard deviations across runs) for accuracy and modality count metrics; and (v) statistical significance tests (e.g., paired t-tests or McNemar’s test) with p-values comparing SDM-Q to baselines. These additions will directly support the claims of competitive performance with reduced modality acquisition. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper reformulates multi-omics classification as a standard finite-horizon MDP with states defined by acquired modalities, an action-value function for acquisition/termination decisions, and a terminal reward combining classification accuracy with cumulative cost. A backward stage-wise optimization is applied for training stability. These are conventional RL elements applied to the domain; no equation or result is shown to equal its own inputs by construction. Reported performance numbers (e.g., >99% single-modality accuracy on BRCA) are presented as experimental outcomes on four public datasets, not as fitted parameters or self-defined predictions. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or described method. The work is self-contained empirical demonstration rather than a closed derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Cai, R. C. Poulos, J. Liu, Q. Zhong, Machine learning for multi-omics data integration in cancer, Iscience 25 (2) (2022)
2022
-
[2]
Zhang, Y
J. Zhang, Y . Che, R. Liu, Z. Wang, W. Liu, Deep learning–driven multi-omics analysis: enhancing cancer diagnostics and therapeutics, Briefings in bioinfor- matics 26 (4) (2025) bbaf440
2025
-
[3]
D. Xu, Y . Tang, J. Luo, C. Wen, Computational approaches to multimodal data integration in rheumatoid arthritis: from data landscape to clinical translation, Briefings in Bioinformatics 27 (1) (2026) bbag073
2026
-
[4]
J. L. Ballard, Z. Wang, W. Li, L. Shen, Q. Long, Deep learning-based approaches for multi-omics data integration and analysis, BioData Mining 17 (1) (2024) 38
2024
-
[5]
Teerapittayanon, B
S. Teerapittayanon, B. McDanel, H.-T. Kung, Branchynet: Fast inference via early exiting from deep neural networks, in: 2016 23rd international conference on pattern recognition (ICPR), IEEE, 2016, pp. 2464–2469
2016
-
[6]
Contardo, L
G. Contardo, L. Denoyer, T. Artières, Sequential cost-sensitive feature acquisi- tion, in: International symposium on intelligent data analysis, Springer, 2016, pp. 284–294
2016
-
[7]
C. An, Q. Zhou, S. Yang, A reinforcement learning guided adaptive cost- sensitive feature acquisition method, Applied Soft Computing 117 (2022) 108437
2022
-
[8]
Z. Miao, H. Luo, M. Li, J. Zhang, Colaformer: Communicating local–global features with linear computational complexity, Pattern Recognition 157 (2025) 110870
2025
-
[9]
Liang, H
W. Liang, H. Wang, K. Zhang, J. Gong, Y . Gao, X. Tan, L. Ma, From static to adaptive multi-view: Nuanced expert prompt tuning for fine-grained image retrieval, Pattern Recognition (2026) 113884
2026
-
[10]
Chaudhary, O
K. Chaudhary, O. B. Poirion, L. Lu, L. X. Garmire, Deep learning–based multi- omics integration robustly predicts survival in liver cancer, Clinical cancer re- search 24 (6) (2018) 1248–1259
2018
-
[11]
T. Wang, W. Shao, Z. Huang, H. Tang, J. Zhang, Z. Ding, K. Huang, Mogonet integrates multi-omics data using graph convolutional networks allowing pa- tient classification and biomarker identification, Nature communications 12 (1) (2021) 3445. 27
2021
-
[12]
R. B. Tanvir, M. M. Islam, M. Sobhan, D. Luo, A. M. Mondal, Mogat: a multi- omics integration framework using graph attention networks for cancer subtype prediction, International Journal of Molecular Sciences 25 (5) (2024) 2788
2024
-
[13]
N. Mu, H. Yang, C. Zhao, An uncertainty-aware dynamic decision framework for progressive multi-omics integration in classification tasks, Computer Meth- ods and Programs in Biomedicine (2025) 109179
2025
-
[14]
Z. Wu, T. Nagarajan, A. Kumar, S. Rennie, L. S. Davis, K. Grauman, R. Feris, Blockdrop: Dynamic inference paths in residual networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8817– 8826
2018
-
[15]
R. S. Sutton, A. G. Barto, et al., Reinforcement learning: An introduction, V ol. 1, MIT press Cambridge, 1998
1998
-
[16]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, T. Darrell, Curiosity-driven exploration by self-supervised prediction, in: International conference on machine learning, PMLR, 2017, pp. 2778–2787
2017
-
[17]
D. A. Bennett, J. A. Schneider, Z. Arvanitakis, R. S. Wilson, Overview and find- ings from the religious orders study, Current Alzheimer Research 9 (6) (2012) 628–645
2012
-
[18]
A Bennett, J
D. A Bennett, J. A Schneider, A. S Buchman, L. L Barnes, P. A Boyle, R. S Wil- son, Overview and findings from the rush memory and aging project, Current Alzheimer Research 9 (6) (2012) 646–663
2012
-
[19]
Cancer Genome Atlas Research Network, et al., The cancer genome atlas pan- cancer analysis project, Nat
J. Cancer Genome Atlas Research Network, et al., The cancer genome atlas pan- cancer analysis project, Nat. Genet 45 (10) (2013) 1113–1120
2013
-
[20]
C. G. A. Network, et al., Comprehensive molecular portraits of human breast tumours, Nature 490 (7418) (2012) 61–70
2012
-
[21]
Fix, Discriminatory analysis: nonparametric discrimination, consistency properties, V ol
E. Fix, Discriminatory analysis: nonparametric discrimination, consistency properties, V ol. 1, USAF school of Aviation Medicine, 1985
1985
-
[22]
Cortes, V
C. Cortes, V . Vapnik, Support-vector networks, Machine learning 20 (3) (1995) 273–297
1995
-
[23]
Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B: Statistical Methodology 58 (1) (1996) 267– 288
R. Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B: Statistical Methodology 58 (1) (1996) 267– 288
1996
-
[24]
T. K. Ho, Random decision forests, in: Proceedings of 3rd international confer- ence on document analysis and recognition, V ol. 1, IEEE, 1995, pp. 278–282
1995
-
[25]
W. S. McCulloch, W. Pitts, A logical calculus of the ideas immanent in nervous activity, The bulletin of mathematical biophysics 5 (4) (1943) 115–133. 28
1943
-
[26]
M. A. Van De Wiel, T. G. Lien, W. Verlaat, W. N. van Wieringen, S. M. Wilting, Better prediction by use of co-data: adaptive group-regularized ridge regression, Statistics in medicine 35 (3) (2016) 368–381
2016
-
[27]
Singh, C
A. Singh, C. P. Shannon, B. Gautier, F. Rohart, M. Vacher, S. J. Tebbutt, K.-A. Lê Cao, Diablo: an integrative approach for identifying key molecular drivers from multi-omics assays, Bioinformatics 35 (17) (2019) 3055–3062
2019
-
[28]
Z. Han, C. Zhang, H. Fu, J. T. Zhou, Trusted multi-view classification with dy- namic evidential fusion, IEEE transactions on pattern analysis and machine in- telligence 45 (2) (2022) 2551–2566
2022
-
[29]
D. Hong, L. Gao, N. Yokoya, J. Yao, J. Chanussot, Q. Du, B. Zhang, More di- verse means better: Multimodal deep learning meets remote-sensing imagery classification, IEEE Transactions on Geoscience and Remote Sensing 59 (5) (2020) 4340–4354
2020
-
[30]
Gated Multimodal Units for Information Fusion
J. Arevalo, T. Solorio, M. Montes-y Gómez, F. A. González, Gated multimodal units for information fusion, arXiv preprint arXiv:1702.01992 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Z. Han, F. Yang, J. Huang, C. Zhang, J. Yao, Multimodal dynamics: Dynam- ical fusion for trustworthy multimodal classification, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 20707–20717
2022
-
[32]
J. Liu, B. Zhuang, Z. Zhuang, Y . Guo, J. Huang, J. Zhu, M. Tan, Discrimination- aware network pruning for deep model compression, IEEE Transactions on Pat- tern Analysis and Machine Intelligence 44 (8) (2021) 4035–4051
2021
-
[33]
C. Zhao, A. Liu, X. Zhang, X. Cao, Z. Ding, Q. Sha, H. Shen, H.-W. Deng, W. Zhou, Clclsa: Cross-omics linked embedding with contrastive learning and self attention for integration with incomplete multi-omics data, Computers in biology and medicine 170 (2024) 108058
2024
-
[34]
F. Chen, Y . Zhang, Y . ¸ Senbabao˘glu, G. Ciriello, L. Yang, E. Reznik, B. Shuch, G. Micevic, G. De Velasco, E. Shinbrot, et al., Multilevel genomics-based tax- onomy of renal cell carcinoma, Cell reports 14 (10) (2016) 2476–2489
2016
-
[35]
Y . Yuan, E. M. Van Allen, L. Omberg, N. Wagle, A. Amin-Mansour, A. Sokolov, L. A. Byers, Y . Xu, K. R. Hess, L. Diao, et al., Assessing the clinical utility of cancer genomic and proteomic data across tumor types, Nature biotechnology 32 (7) (2014) 644–652. 29
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.