Adaptive Oscillatory-State Alignment for Time Series Forecasting
Pith reviewed 2026-06-28 02:48 UTC · model grok-4.3
The pith
AOSNET improves long-term forecasts by aligning local states to a learnable oscillatory prior instead of matching fixed templates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
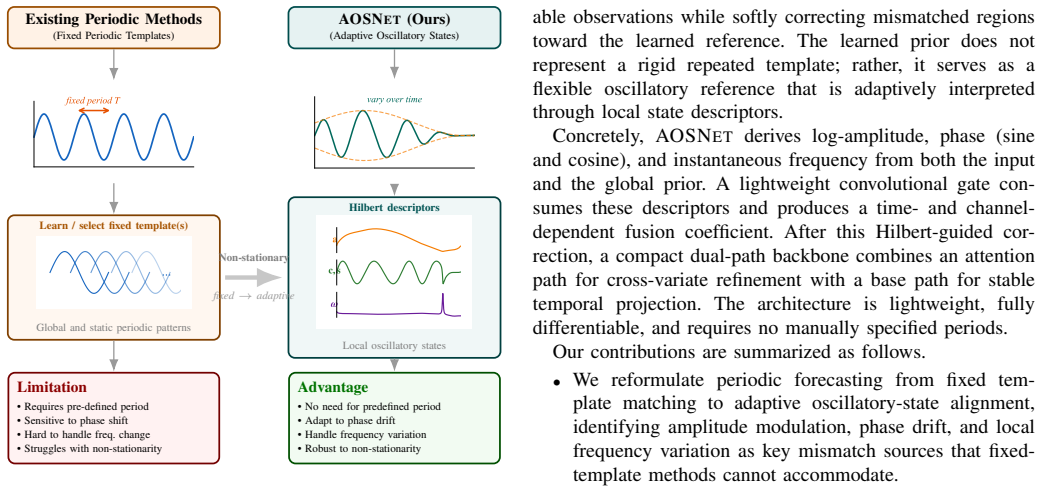
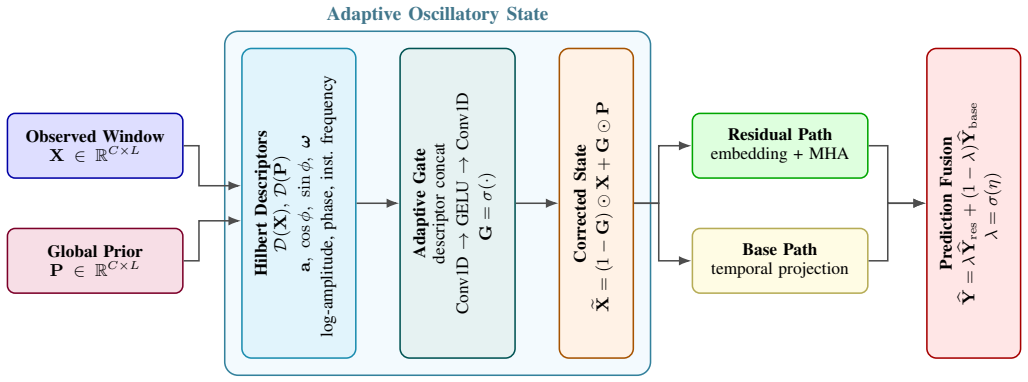
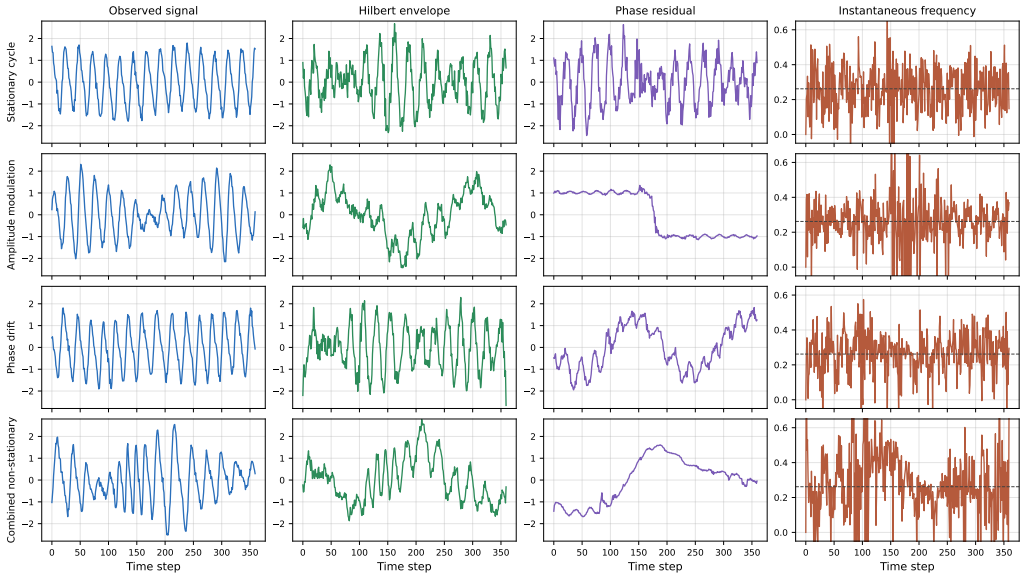
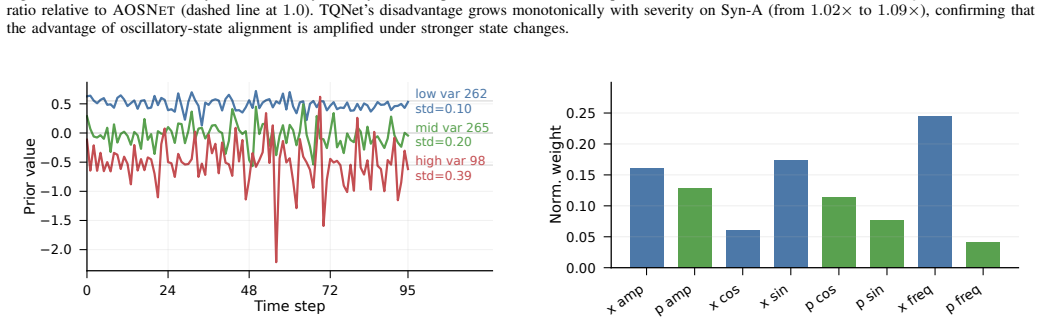
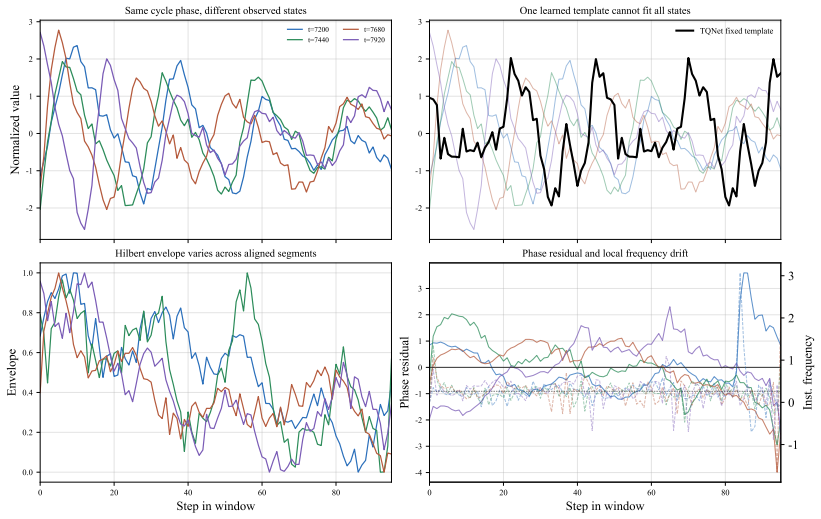
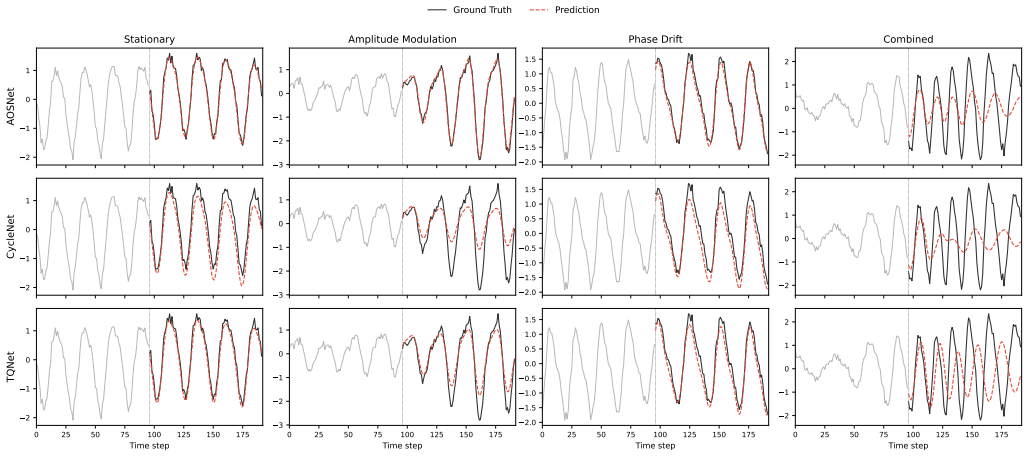
AOSNET reformulates periodic forecasting from fixed template matching to adaptive oscillatory-state alignment. It extracts analytic-signal descriptors from both the observed sequence and a learnable global oscillatory prior, then adaptively aligns local states through a descriptor-conditioned gate that selectively preserves reliable observations while softly correcting mismatched regions. The learned prior functions as a flexible oscillatory reference interpreted through local state dynamics rather than a rigid repeated template.
What carries the argument
The descriptor-conditioned gate that uses analytic-signal features to decide how much of the local observation versus the global prior to retain at each point.
If this is right
- Accuracy stays competitive or superior across eight real benchmarks that contain varying degrees of non-stationarity.
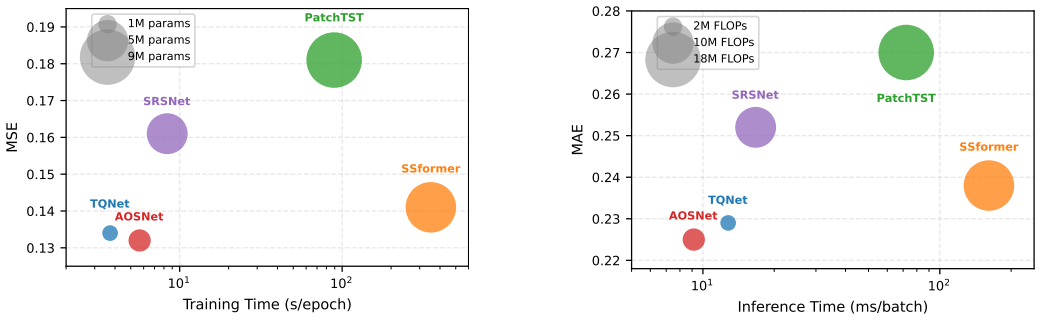
- Inference remains fast because the alignment uses a single learnable prior and a lightweight gate.
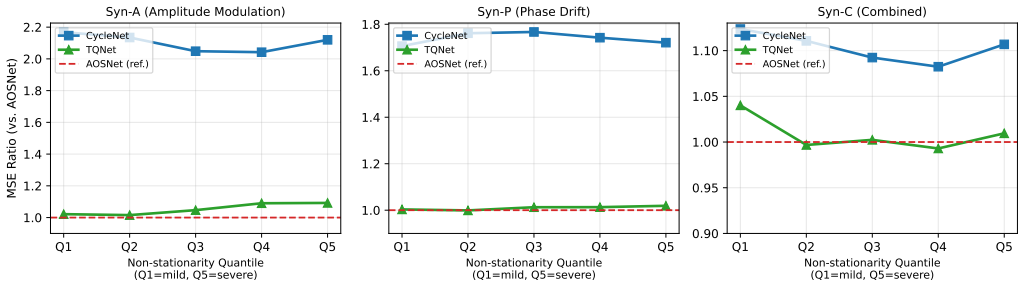
- The performance margin widens as the controlled synthetic tests increase the strength of amplitude modulation, phase drift, or local frequency change.
Where Pith is reading between the lines
- The same descriptor-plus-gate mechanism could be inserted into other sequence models that already handle long-range dependencies.
- The learned prior might serve as an interpretable summary of the dominant oscillation even in datasets where periodicity is not labeled in advance.
- If the gate learns to ignore the prior in highly non-oscillatory regions, the framework could naturally fall back to non-periodic modeling without extra switches.
Load-bearing premise
Oscillatory patterns in real time series change through amplitude modulation, phase drift, and local frequency shifts instead of staying rigidly periodic.
What would settle it
On synthetic series engineered with strong phase drift or frequency variation, if AOSNET shows no accuracy gain over fixed-template baselines, the advantage of adaptive alignment would be refuted.
Figures
read the original abstract
Long-term time series forecasting benefits from inductive biases that expose recurring temporal structure. Existing periodic forecasting methods typically model recurrence through predefined periods, global spectral components, or fixed learnable templates. However, real-world temporal dynamics are rarely rigidly periodic: oscillatory behavior often evolves through amplitude modulation, phase drift, and local frequency variation. Under these conditions, fixed-template periodic modeling can become fundamentally mismatched to the underlying temporal states. We propose AOSNET, a Hilbert-guided forecasting framework that reformulates periodic forecasting from fixed template matching to adaptive oscillatory-state alignment. AOSNET extracts analytic-signal descriptors from both the observed sequence and a learnable global oscillatory prior, then adaptively aligns local states through a descriptor-conditioned gate that selectively preserves reliable observations while softly correcting mismatched regions. The learned prior serves not as a rigid repeated template but as a flexible oscillatory reference interpreted through local state dynamics. Experiments on eight benchmarks demonstrate state-of-the-art or highly competitive accuracy with fast inference speed. Controlled synthetic studies isolating amplitude modulation, phase drift, and local frequency variation confirm that the advantage of oscillatory-state alignment consistently increases as non-stationarity intensifies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing periodic forecasting methods relying on predefined periods, global spectral components, or fixed learnable templates are mismatched to real-world time series exhibiting amplitude modulation, phase drift, and local frequency variation. It proposes AOSNET, a Hilbert-guided framework that extracts analytic-signal descriptors from both the observed sequence and a learnable global oscillatory prior, then applies a descriptor-conditioned gate to adaptively align local states by preserving reliable observations and softly correcting mismatches. The learned prior acts as a flexible reference rather than a rigid template. Experiments on eight benchmarks report state-of-the-art or competitive accuracy with fast inference, while controlled synthetic studies isolating the three non-stationarity types show that the advantage of oscillatory-state alignment grows with increasing non-stationarity.
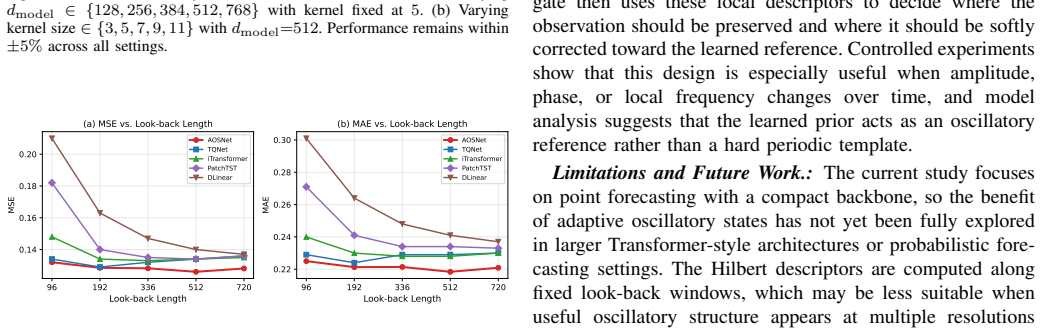
Significance. If the central claims hold, the work offers a principled shift from fixed-template periodic modeling to adaptive alignment using analytic signals, which could improve long-term forecasting in domains with evolving oscillatory dynamics. The controlled synthetic experiments that isolate amplitude modulation, phase drift, and local frequency variation provide a clear falsifiable test of the method's robustness and are a methodological strength.
major comments (2)
- [Abstract/Method] Abstract and Method (central construction): the learnable global oscillatory prior is optimized on the same data used for alignment and forecasting; this creates a moderate circularity risk because it is unclear whether the descriptor-conditioned alignment metric supplies an independent reference or reduces to a fitted quantity by construction. An ablation separating prior optimization from the alignment objective is needed to substantiate the claim that the prior functions as a flexible oscillatory reference.
- [Experiments] Experiments section: the abstract asserts SOTA or competitive results on eight benchmarks, but without reported error bars, data splits, or baseline implementation details it is impossible to verify whether the gains are robust or attributable to the adaptive alignment rather than hyperparameter tuning or dataset-specific effects.
minor comments (2)
- [Abstract] Abstract: the phrase 'fast inference speed' is stated without quantitative comparison to baselines or complexity analysis; adding a brief runtime table or FLOPs count would strengthen the claim.
- [Method] Notation: the term 'analytic-signal descriptors' is introduced without an explicit equation or reference to the Hilbert transform definition in the main text; a short definition or pointer to the standard formula would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance and the value of the controlled synthetic experiments. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract/Method] Abstract and Method (central construction): the learnable global oscillatory prior is optimized on the same data used for alignment and forecasting; this creates a moderate circularity risk because it is unclear whether the descriptor-conditioned alignment metric supplies an independent reference or reduces to a fitted quantity by construction. An ablation separating prior optimization from the alignment objective is needed to substantiate the claim that the prior functions as a flexible oscillatory reference.
Authors: We agree that joint optimization of the prior and the alignment objective introduces a potential circularity that merits explicit verification. While the prior is intended as a global reference and the descriptor-conditioned gate provides local adaptation, an ablation isolating the prior's optimization from the alignment loss would strengthen the claim. In the revision we will add such an ablation: one variant optimizes the prior solely via a reconstruction or forecasting loss without the alignment term, and another freezes the prior after an initial phase before applying alignment. This will clarify whether the adaptive alignment supplies an independent benefit beyond fitting the prior. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts SOTA or competitive results on eight benchmarks, but without reported error bars, data splits, or baseline implementation details it is impossible to verify whether the gains are robust or attributable to the adaptive alignment rather than hyperparameter tuning or dataset-specific effects.
Authors: We acknowledge that the current experimental reporting lacks sufficient detail for full reproducibility and robustness assessment. In the revised manuscript we will report mean performance with standard deviations over at least three random seeds, explicitly state the train/validation/test splits (including any preprocessing or normalization), and provide additional implementation details for all baselines (hyperparameter search ranges, training protocols, and code references where applicable). These additions will allow readers to assess whether the reported gains are attributable to the proposed alignment mechanism. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a standard neural architecture (AOSNET) with a learnable global oscillatory prior trained end-to-end on the forecasting data, followed by descriptor extraction and gated alignment. No equations or steps are shown that reduce a claimed prediction to a fitted quantity by construction, nor does the provided text invoke self-citations as load-bearing uniqueness theorems. The reformulation from fixed templates to adaptive alignment is presented as an architectural choice with external validation on benchmarks and controlled synthetics, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable global oscillatory prior
axioms (1)
- domain assumption The Hilbert transform yields useful analytic-signal descriptors that capture amplitude and phase information suitable for state alignment.
invented entities (1)
-
descriptor-conditioned gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Trans- formers in Time Series: A Survey,
Q. Wen, T. Zhou, C. Zhang, W. Chen, Z. Ma, J. Yan, and L. Sun, “Trans- formers in Time Series: A Survey,”arXiv preprint arXiv:2202.07125, 2022
-
[2]
TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods,
X. Qiu, J. Hu, L. Zhou, X. Wu, J. Du, B. Zhang, C. Guo, A. Zhou, C. S. Jensen, Z. Sheng, and B. Yang, “TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods,” inInternational Conference on Very Large Data Bases (VLDB), Guangzhou, China, Aug. 26-30, 2024
2024
-
[3]
Explor- ing Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis,
Z. Shao, F. Wang, Y . Xu, W. Wei, C. Yu, Z. Zhang, D. Yao, T. Sun, G. Jin, X. Cao, G. Cong, C. S. Jensen, and X. Cheng, “Explor- ing Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis,”IEEE Transactions on Knowledge and Data Engineering, vol. 37, pp. 291–305, Jan. 2025
2025
-
[4]
A Survey of Deep Learning for Time Series Forecasting: Taxonomy, Analysis and Future Directions,
Q. Guo, B. Zhao, M. Song, and G. Zhong, “A Survey of Deep Learning for Time Series Forecasting: Taxonomy, Analysis and Future Directions,”IEEE Transactions on Knowledge and Data Engineering, pp. 1–20, 2026
2026
-
[5]
Informer: Beyond Efficient Transformer for Long Sequence Time- Series Forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond Efficient Transformer for Long Sequence Time- Series Forecasting,” inProceedings of The AAAI Conference on Artificial Intelligence, Virtual Event, Feb. 2-9, 2021
2021
-
[6]
Are Transformers Effective for Time Series Forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are Transformers Effective for Time Series Forecasting?” inProceedings of The AAAI Conference on Artificial Intelligence, Washington, DC, USA, Feb. 7-14, 2023
2023
-
[7]
Multi-Period Learning for Financial Time Series Forecasting,
X. Zhang, Z. Huang, Y . Wu, X. Lu, E. Qi, Y . Chen, Z. Xue, Q. Wang, P. Wang, and W. Wang, “Multi-Period Learning for Financial Time Series Forecasting,” inProceedings of The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Toronto, ON, Canada, Aug. 3-7, Jul. 2025, pp. 2848–2859. [Online]. Available: http://arxiv.org/abs/2511.08622
-
[8]
FuXi: A Cascade Machine Learning Forecasting System for 15-Day Global Weather Forecast,
L. Chen, X. Zhong, F. Zhang, Y . Cheng, Y . Xu, Y . Qi, and H. Li, “FuXi: A Cascade Machine Learning Forecasting System for 15-Day Global Weather Forecast,”npj Climate and Atmospheric Science, vol. 6, no. 1, p. 190, Nov. 2023
2023
-
[9]
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecast- ing,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecast- ing,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Virtual, Dec. 6-14, 2021
2021
-
[10]
A Time Series Is Worth 64 Words: Long-Term Forecasting with Transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A Time Series Is Worth 64 Words: Long-Term Forecasting with Transformers,” in International Conference on Learning Representations (ICLR), Kigali, Rwanda, May 1-5, 2023
2023
-
[11]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “iTransformer: Inverted Transformers Are Effective for Time Series Forecasting,” inInternational Conference on Learning Representations (ICLR), Vienna, Austria, May 7-11, 2024
2024
-
[12]
Frequency Adaptive Normaliza- tion for Non-Stationary Time Series Forecasting,
W. Ye, S. Deng, Q. Zou, and N. Gui, “Frequency Adaptive Normaliza- tion for Non-Stationary Time Series Forecasting,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, Dec. 10 - 15, 2024
2024
-
[13]
TimeBridge: Non-Stationarity Matters for Long-Term Time Series Forecasting,
P. Liu, B. Wu, Y . Hu, N. Li, T. Dai, J. Bao, and S.-T. Xia, “TimeBridge: Non-Stationarity Matters for Long-Term Time Series Forecasting,” in International Conference on Machine Learning (ICML), Vancouver, Canada, Jul. 13-19, 2025
2025
-
[14]
Diffusion-based spatio-temporal channel prediction via non-stationarity decoupling,
Z. Song, X. Zhang, L. Zhuang, T. Guo, X. Zhao, Y . Xu, and S. Jin, “Diffusion-based spatio-temporal channel prediction via non-stationarity decoupling,”IEEE Transactions on Cognitive Communications and Networking, vol. 12, pp. 7647–7661, 2026
2026
-
[15]
CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Pat- terns,
S. Lin, W. Lin, X. Hu, W. Wu, R. Mo, and H. Zhong, “CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Pat- terns,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, Dec. 9-15, 2024
2024
-
[16]
Temporal Query Network for Efficient Multivariate Time Series Forecasting,
S. Lin, H. Chen, H. Wu, C. Qiu, and W. Lin, “Temporal Query Network for Efficient Multivariate Time Series Forecasting,” inInternational Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 267. BC, Canada, Jul. 13-19: PMLR / OpenReview.net, 2025. [Online]. Available: https://proceedings.mlr.press/v267/lin25e.html
2025
-
[17]
FILM: Frequency Improved Legendre Memory Model for Long-Term Time Series Forecasting,
T. Zhou, Z. Ma, Q. Wen, L. Sun, T. Yao, W. Yin, R. Jinet al., “FILM: Frequency Improved Legendre Memory Model for Long-Term Time Series Forecasting,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), LA, USA, Nov. 28-Dec. 9, 2022
2022
-
[18]
FreDF: Learning to Forecast in The Frequency Domain,
H. Wang, L. Pan, Y . Shen, Z. Chen, D. Yang, Y . Yang, S. Zhang, X. Liu, H. Li, and D. Tao, “FreDF: Learning to Forecast in The Frequency Domain,” inInternational Conference on Learning Representations (ICLR), Singapore, Apr. 24-28, 2025. [Online]. Available: https://openreview.net/forum?id=4A9IdSa1ul
2025
-
[19]
Amplifier: Bringing Attention to Neglected Low-Energy Components in Time Series Forecasting,
J. Fei, K. Yi, W. Fan, Q. Zhang, and Z. Niu, “Amplifier: Bringing Attention to Neglected Low-Energy Components in Time Series Forecasting,” inProceedings of The AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, Feb. 25 - Mar. 4, 2025. [Online]. Available: https://doi.org/10.1609/aaai.v39i11.33267
-
[20]
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting,
S. Wang, H. Wu, X. Shi, T. Hu, H. Luo, L. Ma, J. Y . Zhang, and J. Zhou, “TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting,” inInternational Conference on Learning Representations (ICLR), Vienna, Austria, May 7-11, 2024
2024
-
[21]
Revi- talizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling,
G. Yu, J. Zou, X. Hu, A. I. Aviles-Rivero, J. Qin, and S. Wang, “Revi- talizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling,” in International Conference on Machine Learning (ICML), Vienna, Austria, Jul. 21-27, 2024
2024
-
[22]
Parsimony or Capability? Decomposition Delivers Both in Long-Term Time Series Forecasting,
J. Deng, F. Ye, D. Yin, X. Song, I. Tsang, and H. Xiong, “Parsimony or Capability? Decomposition Delivers Both in Long-Term Time Series Forecasting,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, Dec. 9-15, 2024
2024
-
[23]
Theory of Communication,
D. Gabor, “Theory of Communication,”Journal of the Institution of Electrical Engineers, vol. 93, no. 26, pp. 429–457, 1946
1946
-
[24]
Estimating and Interpreting the Instantaneous Frequency of a Signal. I. Fundamentals,
B. Boashash, “Estimating and Interpreting the Instantaneous Frequency of a Signal. I. Fundamentals,”Proceedings of the IEEE, vol. 80, no. 4, pp. 520–568, 1992
1992
-
[25]
FED- FOrmer: Frequency Enhanced Decomposed Transformer for Long-Term Series Forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “FED- FOrmer: Frequency Enhanced Decomposed Transformer for Long-Term Series Forecasting,” inInternational Conference on Machine Learning (ICML),, Baltimore, MD, Jul. 17-23, 2022
2022
-
[26]
MICN: Multi-Scale Local and Global Context Modeling for Long-Term Series Forecasting,
H. Wang, J. Peng, F. Huang, J. Wang, J. Chen, and Y . Xiao, “MICN: Multi-Scale Local and Global Context Modeling for Long-Term Series Forecasting,” inInternational Conference on Learning Representations (ICLR), Kigali, Rwanda, May 1-5, 2023
2023
-
[27]
SparseTSF: Modeling Long-Term Time Series Forecasting with *1k* Parameters,
S. Lin, W. Lin, W. Wu, H. Chen, and J. Yang, “SparseTSF: Modeling Long-Term Time Series Forecasting with *1k* Parameters,” inInternational Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235. Vienna, Austria, Jul. 21-27: PMLR / OpenReview.net, 2024, pp. 30 211–30 226. [Online]. Available: https://proceedings.mlr....
2024
-
[28]
MoFo: Empowering Long-Term Time Series Forecasting with Periodic Pattern Modeling,
J. Ma, B. Wang, Q. Huang, G. Wang, P. Wang, Z. Zhou, and Y . Wang, “MoFo: Empowering Long-Term Time Series Forecasting with Periodic Pattern Modeling,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), San Diego, CA, USA, Dec. 2-7, 2026. [Online]. Available: https://openreview.net/forum?id=sbvLts2HqR
2026
-
[29]
FITS: Modeling Time Series with10K Parameters,
Z. Xu, A. Zeng, and Q. Xu, “FITS: Modeling Time Series with10K Parameters,” inInternational Conference on Learning Representations (ICLR), Vienna, Austria, May 7-11, 2024
2024
-
[30]
Attention Is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Long Beach, California, USA, Dec. 4-9, 2017
2017
-
[31]
Channel, Trend and Periodic-Wise Representation Learning for Multivariate Long-Term Time Series Forecasting,
Z. Song, N. Jiang, M. He, X. Zhao, and T. Guo, “Channel, Trend and Periodic-Wise Representation Learning for Multivariate Long-Term Time Series Forecasting,” inInternational Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain, May 4- 8: IEEE, 2026, pp. 4821–4825
2026
-
[32]
The Capacity and Robustness Trade-Off: Revisiting The Channel Independent Strategy for Multivariate Time Series Forecasting,
L. Han, H.-J. Ye, and D.-C. Zhan, “The Capacity and Robustness Trade-Off: Revisiting The Channel Independent Strategy for Multivariate Time Series Forecasting,”IEEE Transactions on Knowledge and Data Engineering, 2024
2024
-
[33]
Crossformer: Transformer Utilizing Cross- Dimension Dependency for Multivariate Time Series Forecasting,
Y . Zhang and J. Yan, “Crossformer: Transformer Utilizing Cross- Dimension Dependency for Multivariate Time Series Forecasting,” inInternational Conference on Learning Representations (ICLR). Kigali, Rwanda, May 1-5: OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=vSVLM2j9eie
2023
-
[34]
HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting,
Q. Huang, L. Shen, R. Zhang, J. Cheng, S. Ding, Z. Zhou, and Y . Wang, “HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting,” inProceedings of The AAAI Conference on Artificial Intelligence, Vancouver, Canada, Feb. 20-27, 2024
2024
-
[35]
SAMformer: Unlocking The Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention,
R. Ilbert, A. Odonnat, V . Feofanov, A. Virmaux, G. Paolo, T. Palpanas, and I. Redko, “SAMformer: Unlocking The Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention,” inInternational Conference on Machine Learning (ICML), vol. 235. Vienna, Austria, Jul. 21-27: PMLR, 2024. [Online]. Available: ht...
2024
-
[36]
The Fast Fourier Transform,
E. O. Brigham and R. E. Morrow, “The Fast Fourier Transform,”IEEE Spectrum, 1967
1967
-
[37]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian Error Linear Units (GELUs),” arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Dropout: A Simple Way to Prevent Neural Networks from Overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014
1929
-
[39]
Pytorch: An Imperative Style, High-Performance Deep Learning Library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An Imperative Style, High-Performance Deep Learning Library,” inAnnual Conference on Neural Information Processing Systems (NeurIPS), Van- couver, Canada, Dec. 8-14, 2019
2019
-
[40]
Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective,
X. Wu, X. Qiu, H. Cheng, Z. Li, J. Hu, C. Guo, and B. Yang, “Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective,” inAnnual Conference on Neural Information Pro- cessing Systems (NeurIPS), Vancouver, Canada, Dec. 9-14, 2025
2025
-
[41]
Sparse-scale transformer with bidirectional awareness for time series forecasting,
Y . Liu, B. Liu, S. Huang, G. Luo, W. Hu, M. Wang, and R. Hong, “Sparse-scale transformer with bidirectional awareness for time series forecasting,” inProceedings of The AAAI Conference on Artificial Intelligence. Singapore, January 20-27: AAAI Press, 2026, pp. 23 899– 23 907. [Online]. Available: https://doi.org/10.1609/aaai.v40i28.39566
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.