Open-Vocabulary and Referring Segmentation for 3D Gaussians Using 2D Detectors
Pith reviewed 2026-06-30 05:51 UTC · model grok-4.3
The pith
GaussDet lets 3D Gaussian scenes handle complex referring expressions by voting from multi-view 2D detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
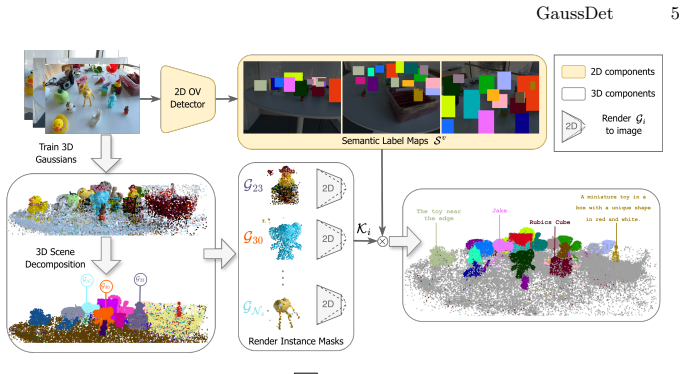
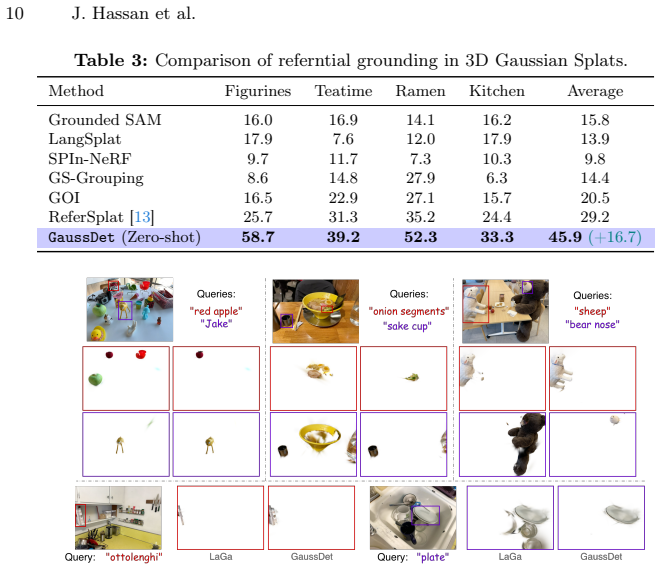
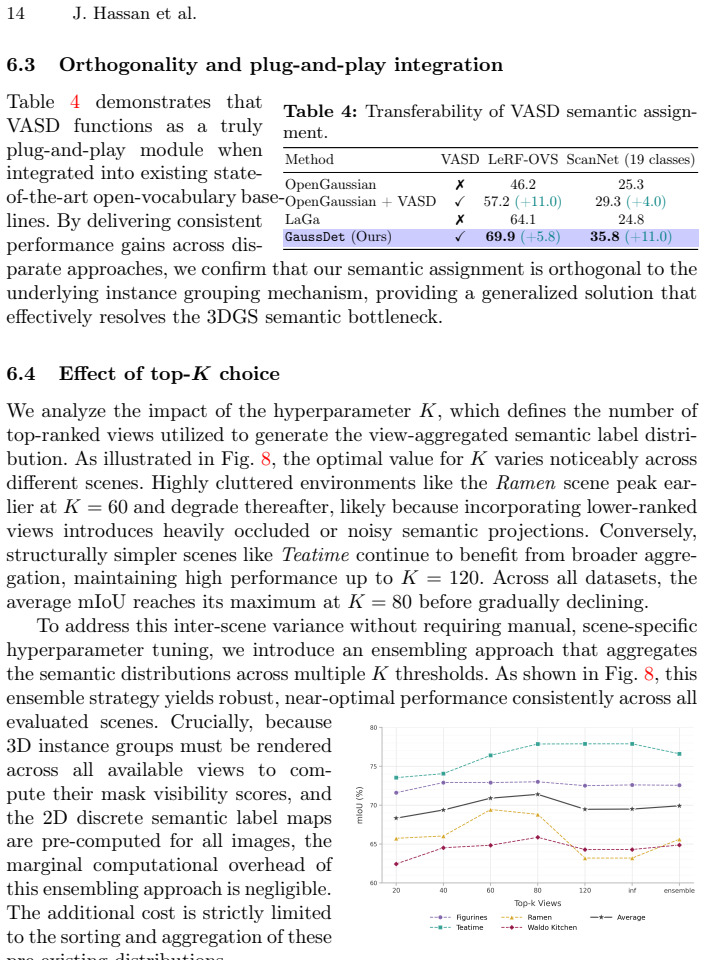
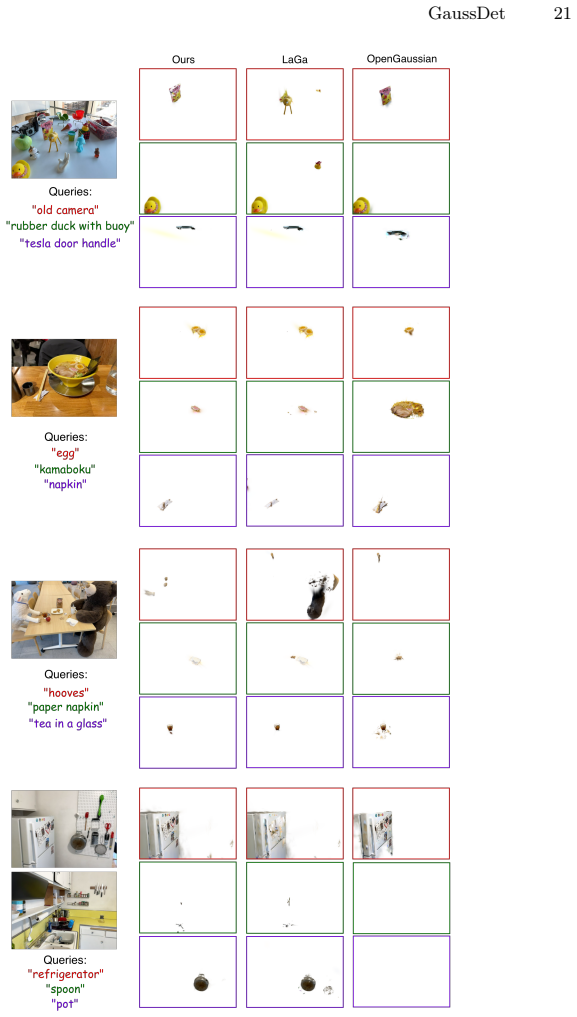
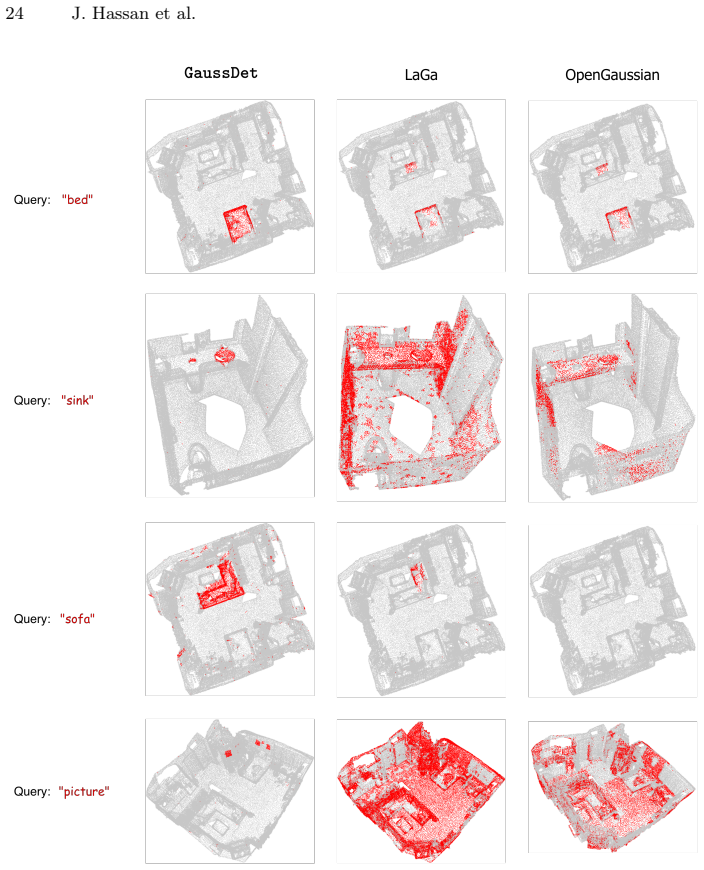
GaussDet decomposes scenes into 3D instances via learned Gaussian features, renders the instances, and aggregates discrete open-vocabulary labels from 2D detectors into a per-instance VASD; this produces robust semantics that extend from basic language queries to complex referential expressions and yields consistent improvements on open-vocabulary segmentation and referring grounding benchmarks.
What carries the argument
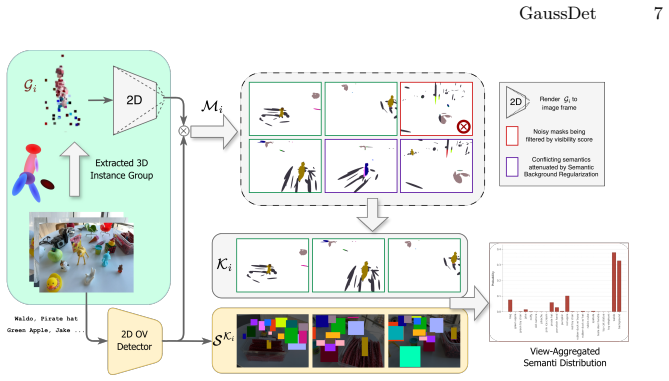
The View-Aggregated Semantic Label Distribution (VASD) formed by rendering 3D instance groups and collecting votes from multi-view 2D detections.
If this is right
- The method supports zero-shot transfer from simple noun queries to complex referential expressions without retraining.
- View aggregation acts as a regularizer that reduces spurious labels from low-quality 3D groups.
- Consistent accuracy gains appear on both open-vocabulary segmentation and referring expression tasks.
- The approach avoids the need for a predefined number of instances or bottom-up clustering used in earlier work.
Where Pith is reading between the lines
- The same voting mechanism could be tested on dynamic or time-varying Gaussian scenes if 2D detectors track objects across frames.
- Replacing continuous CLIP embeddings with discrete detector outputs may lower memory use during scene optimization.
- The framework suggests that any 2D model supplying instance-level labels could be plugged in without changing the 3D grouping step.
- Embodied agents might use the resulting 3D instance labels for spatial planning tasks that require reference resolution.
Load-bearing premise
Multi-view aggregation of 2D detector outputs will consistently correct errors introduced by noisy 3D instance grouping.
What would settle it
Performance on Ref-LeRF remains unchanged when the view-aggregation step is removed and only single-view 2D detections are used.
Figures





read the original abstract
3D Gaussian Splatting (3DGS) has emerged at the forefront of 3D scene reconstruction. Extending 3DGS with language-driven, open-vocabulary understanding has gained significant attention for real-world applications such as embodied AI. Recent methods achieve this by learning an instance feature attribute and assigning semantics by distilling high-dimensional Contrastive Language-Image Pretraining (CLIP) features directly into the scene representation. However, the instance grouping mechanisms of these methods either require a predefined number of instances or suffer from noise in their bottom-up grouping strategies. Furthermore, the reliance on CLIP restricts semantic understanding to simple noun phrases, preventing complex spatial reasoning and referential expression grounding. We present GaussDet, a method that circumvents the need for dense CLIP features by leveraging discrete, open-vocabulary 2D object detectors with referring expression capabilities. We learn instance features for individual Gaussians to decompose the scene into 3D instance groups. By rendering these groups and aggregating semantic votes from multi-view 2D detections, we generate a robust View-Aggregated Semantic Label Distribution (VASD) for each 3D instance. This view-aggregation strategy acts as a strong regularizer, attenuating spurious labels caused by low-quality instance grouping. Our approach enables a straightforward, zero-shot extension from simple language queries to complex referential grounding. Extensive evaluations across two key tasks -- open-vocabulary segmentation (LeRF-OVS, ScanNet) and referring expression grounding (Ref-LeRF) -- demonstrate that GaussDet achieves consistent improvements over existing methods. Most notably, we achieve a substantial 16.7% mIoU improvement in referential grounding within a strict zero-shot setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GaussDet, which extends 3D Gaussian Splatting to open-vocabulary segmentation and referring expression grounding by learning per-Gaussian instance features, rendering instance groups, and aggregating semantic votes from multi-view 2D detectors into a View-Aggregated Semantic Label Distribution (VASD) per 3D instance. The view-aggregation is presented as a regularizer against spurious labels from imperfect bottom-up grouping. The method claims a straightforward zero-shot extension from simple queries to complex referential grounding and reports consistent gains over prior CLIP-based methods, including a 16.7% mIoU improvement on Ref-LeRF in a strict zero-shot setting.
Significance. If the results hold, the work is significant because it replaces dense CLIP feature distillation with discrete 2D detectors that natively support referring expressions, enabling complex spatial reasoning in 3DGS without predefined instance counts. The zero-shot referential grounding capability is a practical advance for embodied AI applications. The view-aggregation idea is conceptually appealing as a regularizer, though its contribution to the reported gains requires direct empirical isolation.
major comments (2)
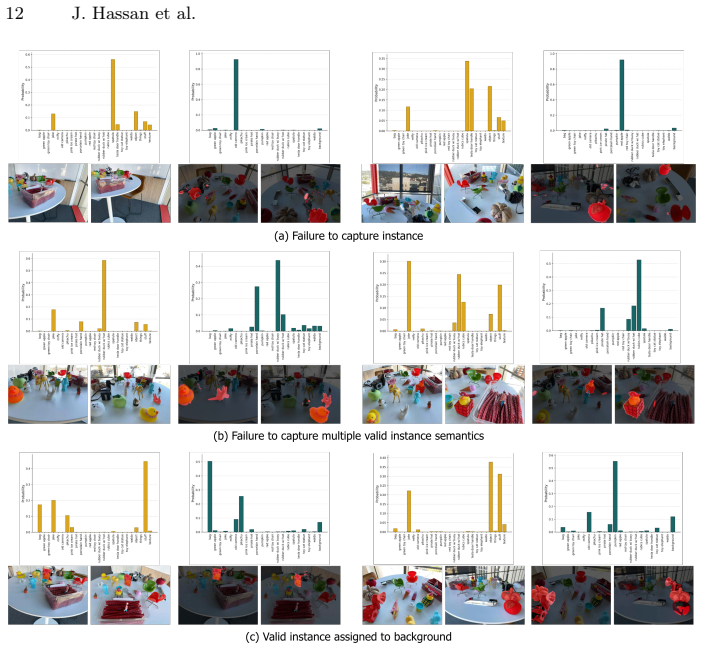
- [Abstract] Abstract: the assertion that 'This view-aggregation strategy acts as a strong regularizer, attenuating spurious labels caused by low-quality instance grouping' is load-bearing for attributing the 16.7% mIoU gain, yet the manuscript provides no ablation that decouples grouping quality from the aggregation step (e.g., VASD versus per-view labels on identical rendered masks, or controlled injection of grouping noise). If errors are correlated across views, aggregation may reinforce rather than attenuate them.
- [Experiments] Experiments section: quantitative improvements are reported without sufficient detail on experimental methodology, potential confounding factors (such as detector choice or view selection), or error analysis, which limits assessment of whether the data support the zero-shot referential grounding claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will revise the manuscript to strengthen the presentation of our method and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'This view-aggregation strategy acts as a strong regularizer, attenuating spurious labels caused by low-quality instance grouping' is load-bearing for attributing the 16.7% mIoU gain, yet the manuscript provides no ablation that decouples grouping quality from the aggregation step (e.g., VASD versus per-view labels on identical rendered masks, or controlled injection of grouping noise). If errors are correlated across views, aggregation may reinforce rather than attenuate them.
Authors: We agree that an explicit ablation isolating the contribution of view aggregation would strengthen the claim. In the revised manuscript we will add an ablation comparing VASD against per-view labels applied to identical rendered masks, and we will include controlled analysis of error correlation across views to address the possibility that aggregation could reinforce correlated mistakes. revision: yes
-
Referee: [Experiments] Experiments section: quantitative improvements are reported without sufficient detail on experimental methodology, potential confounding factors (such as detector choice or view selection), or error analysis, which limits assessment of whether the data support the zero-shot referential grounding claims.
Authors: We acknowledge that additional methodological detail is needed. The revised Experiments section will expand on detector configurations and versions used, view selection criteria and counts, controls for potential confounding factors, and a dedicated error analysis of failure modes in the zero-shot referential grounding experiments. revision: yes
Circularity Check
No circularity; method relies on external 2D detectors and standard aggregation
full rationale
The paper presents GaussDet as a pipeline that learns instance features on 3D Gaussians, renders groups, and aggregates votes from off-the-shelf open-vocabulary 2D detectors to form VASD. No equations, fitted parameters, or self-citations are shown that reduce a claimed prediction or uniqueness result back to the input by construction. The regularization statement about view aggregation is an empirical claim about the method's behavior rather than a definitional or self-referential step. Evaluations on external benchmarks (LeRF-OVS, ScanNet, Ref-LeRF) are independent of any internal fitting loop described in the provided text. This is the normal case of a self-contained engineering method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.14151 (2025) 3
Arnaud, S., McVay, P., Martin, A., Majumdar, A., Jatavallabhula, K.M., Thomas, P., Partsey, R., Dugas, D., Gejji, A., Sax, A., et al.: Locate 3d: Real-world object localization via self-supervised learning in 3d. arXiv preprint arXiv:2504.14151 (2025) 3
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the IEEE/CVF international conference on computer vision
Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srini- vasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5855–5864 (2021) 3
2021
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19697–19705 (2023) 3
2023
-
[5]
arXiv preprint arXiv:2406.02548 (2024) 1, 6, 13
Boudjoghra, M.E.A., Dai, A., Lahoud, J., Cholakkal, H., Anwer, R.M., Khan, S., Khan, F.S.: Open-yolo 3d: Towards fast and accurate open-vocabulary 3d instance segmentation. arXiv preprint arXiv:2406.02548 (2024) 1, 6, 13
-
[6]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the AAAI conference on artificial intelligence
Cen, J., Fang, J., Yang, C., Xie, L., Zhang, X., Shen, W., Tian, Q.: Segment any 3d gaussians. In: Proceedings of the AAAI conference on artificial intelligence. vol. 39, pp. 1971–1979 (2025) 19
1971
-
[8]
arXiv preprint arXiv:2505.24746 (2025) 2, 3, 4, 5, 9, 10, 11, 19, 20
Cen, J., Zhou, X., Fang, J., Wen, C., Xie, L., Zhang, X., Shen, W., Tian, Q.: Tack- ling view-dependent semantics in 3d language gaussian splatting. arXiv preprint arXiv:2505.24746 (2025) 2, 3, 4, 5, 9, 10, 11, 19, 20
-
[9]
In: European conference on computer vision
Chen, D.Z., Chang, A.X., Nießner, M.: Scanrefer: 3d object localization in rgb-d scans using natural language. In: European conference on computer vision. pp. 202–221. Springer (2020) 3
2020
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, T., Song, L., Ge, Y., Liu, W., Wang, X., Shan, Y.: Yolo-world: Real-time open-vocabulary object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16901–16911 (2024) 2 16 J. Hassan et al
2024
-
[11]
In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., et al.: Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning. In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5021–5028. IEEE (2024) 1
2024
-
[12]
IEEE Robotics and Automation Letters (2025) 2, 3
Halacheva, A.M., Zaech, J.N., Wang, X., Paudel, D.P., Van Gool, L.: Gaussianvlm: Scene-centric 3d vision-language models using language-aligned gaussian splats for embodied reasoning and beyond. IEEE Robotics and Automation Letters (2025) 2, 3
2025
-
[13]
arXiv preprint arXiv:2508.08252 (2025) 2, 3, 8, 10
He, S., Jie, G., Wang, C., Zhou, Y., Hu, S., Li, G., Ding, H.: Refersplat: Referring segmentation in 3d gaussian splatting. arXiv preprint arXiv:2508.08252 (2025) 2, 3, 8, 10
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hess, G., Lindström, C., Fatemi, M., Petersson, C., Svensson, L.: Splatad: Real- timelidarandcamerarenderingwith3dgaussiansplattingforautonomousdriving. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 11982–11992 (2025) 2, 3
2025
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 21357–21366 (2024) 2
2024
-
[16]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 1, 3
2023
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023) 2, 19
2023
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning seg- mentation via large language model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9579–9589 (2024) 3
2024
-
[19]
Language-driven Semantic Segmentation
Li, B., Weinberger, K.Q., Belongie, S., Koltun, V., Ranftl, R.: Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546 (2022) 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Li, H., Wu, Y., Meng, J., Gao, Q., Zhang, Z., Wang, R., Zhang, J.: Instance- gaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 14078–14088 (2025) 3
2025
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y., Ma, Q., Yang, R., Li, H., Ma, M., Ren, B., Popovic, N., Sebe, N., Konukoglu, E., Gevers, T., et al.: Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4961–4972 (2025) 2
2025
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Chen, Z., Li, Z., Xu, Y.: Spacetime gaussian feature splatting for real- time dynamic view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8508–8520 (2024) 2
2024
-
[23]
In: European Conference on Computer Vision
Lin, Z., Geng, S., Zhang, R., Gao, P., De Melo, G., Wang, X., Dai, J., Qiao, Y., Li, H.: Frozen clip models are efficient video learners. In: European Conference on Computer Vision. pp. 388–404. Springer (2022) 1
2022
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ling, H., Kim, S.W., Torralba, A., Fidler, S., Kreis, K.: Align your gaussians: Text- to-4d with dynamic 3d gaussians and composed diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8576–8588 (2024) 2 GaussDet 17
2024
-
[25]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024) 3
2024
-
[26]
In: 2024 International Conference on 3D Vision (3DV)
Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 2024 International Conference on 3D Vision (3DV). pp. 800–809. IEEE (2024) 2
2024
-
[27]
McInnes, L., Healy, J., Astels, S., et al.: hdbscan: Hierarchical density based clus- tering. J. Open Source Softw.2(11), 205 (2017) 2, 19
2017
-
[28]
Commu- nications of the ACM65(1), 99–106 (2021) 3
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021) 3
2021
-
[29]
In: European conference on computer vision
Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Doso- vitskiy, A., Mahendran, A., Arnab, A., Dehghani, M., Shen, Z., et al.: Simple open-vocabulary object detection. In: European conference on computer vision. pp. 728–755. Springer (2022) 2
2022
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Nguyen, P., Ngo, T.D., Kalogerakis, E., Gan, C., Tran, A., Pham, C., Nguyen, K.: Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 4018–4028 (2024) 1
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Peng, S., Genova, K., Jiang, C., Tagliasacchi, A., Pollefeys, M., Funkhouser, T., et al.: Openscene: 3d scene understanding with open vocabularies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 815– 824 (2023) 1
2023
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qin, M., Li, W., Zhou, J., Wang, H., Pfister, H.: Langsplat: 3d language gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20051–20060 (2024) 2, 3, 20
2024
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rasheed, H., Khattak, M.U., Maaz, M., Khan, S., Khan, F.S.: Fine-tuned clip models are efficient video learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6545–6554 (2023) 1
2023
-
[34]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Shi, J.C., Wang, M., Duan, H.B., Guan, S.H.: Language embedded 3d gaussians for open-vocabulary scene understanding. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 5333–5343 (2024) 2
2024
-
[35]
arXiv preprint arXiv:2405.04378 (2024) 2, 3
Shorinwa, O., Tucker, J., Smith, A., Swann, A., Chen, T., Firoozi, R., Kennedy III, M.,Schwager,M.:Splat-mover:Multi-stage,open-vocabularyroboticmanipulation via editable gaussian splatting. arXiv preprint arXiv:2405.04378 (2024) 2, 3
-
[36]
arXiv preprint arXiv:2306.13631 (2023) 1
Takmaz, A., Fedele, E., Sumner, R.W., Pollefeys, M., Tombari, F., Engelmann, F.: Openmask3d: Open-vocabulary 3d instance segmentation. arXiv preprint arXiv:2306.13631 (2023) 1
-
[37]
Advances in Neural Information Processing Systems 37, 19114–19138 (2024) 2, 3, 4, 5, 8, 9, 19, 20
Wu, Y., Meng, J., Li, H., Wu, C., Shi, Y., Cheng, X., Zhao, C., Feng, H., Ding, E., Wang, J., et al.: Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding. Advances in Neural Information Processing Systems 37, 19114–19138 (2024) 2, 3, 4, 5, 8, 9, 19, 20
2024
-
[38]
In: European conference on computer vision
Ye, M., Danelljan, M., Yu, F., Ke, L.: Gaussian grouping: Segment and edit any- thing in 3d scenes. In: European conference on computer vision. pp. 162–179. Springer (2024) 2
2024
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yi, T., Fang, J., Wang, J., Wu, G., Xie, L., Zhang, X., Liu, W., Tian, Q., Wang, X.: Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6796–6807 (2024) 2 18 J. Hassan et al
2024
- [40]
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zareian, A., Rosa, K.D., Hu, D.H., Chang, S.F.: Open-vocabulary object detection using captions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14393–14402 (2021) 1
2021
-
[42]
In: Proceedings of the IEEE international conference on computer vision
Zhao, H., Puig, X., Zhou, B., Fidler, S., Torralba, A.: Open vocabulary scene parsing. In: Proceedings of the IEEE international conference on computer vision. pp. 2002–2010 (2017) 1
2002
-
[43]
Zhou, H., Shao, J., Xu, L., Bai, D., Qiu, W., Liu, B., Wang, Y., Geiger, A., Liao, Y.: Hugs:Holisticurban3dsceneunderstandingviagaussiansplatting.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21336–21345 (2024) 2
2024
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou,S.,Chang,H.,Jiang,S.,Fan,Z.,Zhu,Z.,Xu,D.,Chari,P.,You,S.,Wang,Z., Kadambi, A.: Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21676–21685 (2024) 2, 3
2024
-
[45]
Detect the objects corresponding to the following description if present: ‘{target_str}’
Zhou, X., Lin, Z., Shan, X., Wang, Y., Sun, D., Yang, M.H.: Drivinggaussian: Com- posite gaussian splatting for surrounding dynamic autonomous driving scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 21634–21643 (2024) 2, 3 GaussDet 19 Supplementary Material A Overview The following supplementary materia...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.