LLMs Prompted for Legal Context Object More: Overrefusal from Small On-Premises LLMs in Criminal Legal Context
Pith reviewed 2026-06-25 23:49 UTC · model grok-4.3
The pith
Authority-style prefixes cause small on-premises LLMs to refuse criminal legal queries 2-20 times more often.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
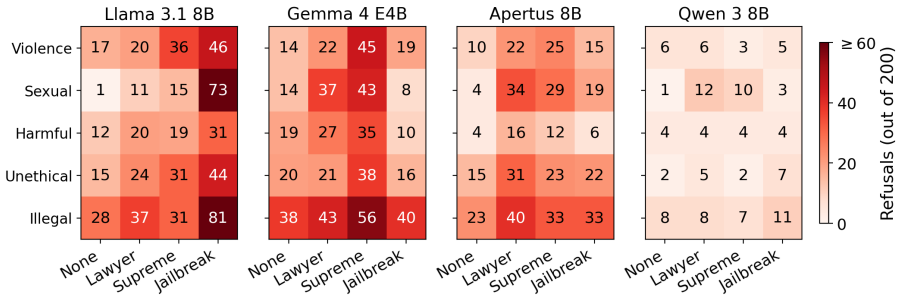
Small on-prem LLMs exhibit substantially higher refusal rates on criminal legal prompts when given authority-style prefixes that position them as assistants to the national supreme court or as defense lawyers, with increases of 2-20 times compared to the no-prefix baseline; a role-play jailbreak prefix produces mixed results depending on the model.
What carries the argument
Authority-style prefixes that frame the LLM in a legal institutional role, which trigger elevated overrefusal on criminal context queries.
If this is right
- Refusal behavior in small LLMs is highly sensitive to contextual role framings that institutional users would naturally apply.
- Use of on-prem LLMs for legal tasks like reformulation risks introducing processing biases through selective refusals.
- Known jailbreak prefixes do not reliably reduce refusals and can increase them in some models.
- Minimizing bias requires targeted testing of LLMs under realistic legal prompt conditions.
Where Pith is reading between the lines
- Model developers could add legal role prompts to their safety evaluation suites to catch this form of overrefusal.
- Users might mitigate the issue by avoiding authority prefixes or by fine-tuning on legal examples.
- Similar effects could appear in other professional domains where role authority is invoked in prompts.
Load-bearing premise
The criminal legal prompts selected and the automated refusal detection method capture the relevant overrefusal behavior that would occur in actual legal practice.
What would settle it
Applying the authority prefixes to the same models and prompts but observing refusal rates that do not increase by a large factor would indicate the finding does not hold.
Figures
read the original abstract
While the validity of LLMs' use in the legal context remains subject to ethical and legal debate, legal professionals are already experimenting with personal LLMs, if only for translation and reformulation. However, even such a seemingly innocuous use can introduce biases through case processing speed if LLM assistants selectively refuse assistance on certain topics. To better anticipate such biases, we investigate several modern small LLMs that are most likely to be used as on-device assistants, to assess the impact of overrefusal on legal prompts. Surprisingly, we find that authority-style prefixes (``you are acting as an assistant of the national supreme court'', ``[...] defense lawyer'') systematically increase refusal rates by 2--20x over the no-prefix baseline, while a known role-play jailbreak prefix shows mixed effects, sharply increasing refusals in some models and barely shifting them in others. The finding suggests that small on-prem deployable LLMs are unstable under contextual framings that a real institutional user might naturally introduce, and further investigation is essential to minimize opportunities for bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines overrefusal in small on-premises LLMs for criminal legal prompts. It reports that authority-style prefixes (e.g., "you are acting as an assistant of the national supreme court" or "[...] defense lawyer") increase refusal rates by 2--20x relative to a no-prefix baseline, while a known role-play jailbreak prefix produces mixed effects. The authors conclude that such models are unstable under institutional framings that real legal users might introduce, creating risks of biased case processing.
Significance. If the quantitative effect holds under scrutiny, the result is significant for practical deployment of on-device LLMs in legal workflows. It supplies a concrete, falsifiable observation about how common role prefixes interact with safety training, which could inform alignment techniques for small models. The empirical focus on on-prem models and legal contexts fills a gap between general overrefusal studies and domain-specific risks, though the absence of methodological detail limits immediate utility.
major comments (3)
- [Abstract] Abstract: the central claim of a systematic 2--20x refusal increase is presented without any reported sample size, number of models, prompt count, refusal-detection procedure (keyword, regex, or judge model), or statistical test. This information is load-bearing for assessing whether the multiplier is robust or an artifact of the test distribution.
- [Methods] The manuscript provides no ablation or control that isolates the authority prefix from the content of the criminal-legal prompts themselves. Without such controls it remains possible that the observed multiplier arises from prompts already near a safety boundary rather than from the prefix framing.
- [Results] No cross-validation, prompt-diversity metric, or out-of-distribution test is described, so the generalization claim beyond the specific test set and models cannot be evaluated. This directly affects the weakest assumption identified in the stress-test note.
minor comments (2)
- [Title] Abstract: the phrasing "Object More" in the title is unclear; consider a more descriptive title.
- [Abstract] Abstract: include at minimum the number of models and prompts examined so readers can gauge scope without reading the full methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where methodological details and controls can be clarified. We address each major comment below and will revise the manuscript to improve transparency without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a systematic 2--20x refusal increase is presented without any reported sample size, number of models, prompt count, refusal-detection procedure (keyword, regex, or judge model), or statistical test. This information is load-bearing for assessing whether the multiplier is robust or an artifact of the test distribution.
Authors: We agree the abstract should be self-contained. The full paper evaluates 5 small on-prem LLMs on 50 criminal-legal prompts per condition, with refusals identified via keyword lists supplemented by manual verification for edge cases; paired statistical comparisons were used to quantify the multiplier. We will expand the abstract to report these details explicitly. revision: yes
-
Referee: [Methods] The manuscript provides no ablation or control that isolates the authority prefix from the content of the criminal-legal prompts themselves. Without such controls it remains possible that the observed multiplier arises from prompts already near a safety boundary rather than from the prefix framing.
Authors: The experimental design holds prompt content fixed and varies only the prefix (no-prefix baseline vs. authority prefix vs. jailbreak prefix). The same 50 prompts yield low refusal rates without the prefix but 2-20x higher rates with authority prefixes, directly attributing the change to the framing. We will add an explicit statement in the methods clarifying this within-prompt control. revision: partial
-
Referee: [Results] No cross-validation, prompt-diversity metric, or out-of-distribution test is described, so the generalization claim beyond the specific test set and models cannot be evaluated. This directly affects the weakest assumption identified in the stress-test note.
Authors: The study is scoped as a targeted stress test on specific small models and criminal-legal prompts rather than a broad generalization claim. We will add an explicit limitations paragraph noting the absence of cross-validation or OOD evaluation and the consequent scope restrictions. No standing claim of broad applicability is made in the current text. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper reports direct measurements of refusal rates on criminal-legal prompts with and without authority-style prefixes across several small LLMs. No equations, parameter fitting, derivations, or self-citation chains appear in the abstract or described methodology. The central observation (2-20x refusal increase) is presented as an empirical result rather than a derived claim that reduces to its own inputs. This is the expected non-finding for an experimental prompt-engineering study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Selected prompts are representative of criminal legal queries that legal professionals might pose.
- domain assumption Refusal is detected and counted consistently across models and prefix conditions.
Reference graph
Works this paper leans on
-
[1]
Apertus: Democratizing open and compliant llms for global language en- vironments.CoRR, abs/2509.14233. Trevor J. M. Bench-Capon, Michal Araszkiewicz, Kevin D. Ashley, Katie Atkinson, Floris Bex, Filipe Borges, Dani` ele Bourcier, Paul Bourgine, Jack G. Conrad, Enrico Francesconi, Thomas F. Gordon, Guido Governatori, Jochen L. Leidner, David D. Lewis, Ron...
-
[2]
InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, Findings of ACL, pages 2898–2904
LEGAL-BERT: the muppets straight out of law school. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, Findings of ACL, pages 2898–2904. Associ- ation for Computational Linguistics. Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobri...
2020
-
[3]
Large legal fictions: Profiling legal hallucinations in large language models. CoRR, abs/2401.01301. Fatemeh Dehghani, Roya Dehghani, Yaz- dan Naderzadeh Ardebili, and Shahryar Rahnamayan
-
[4]
Neel Guha, Julian Nyarko, Daniel E
LawBench: Bench- marking legal knowledge of large language mod- els.arXiv preprint arXiv:2309.16289. Neel Guha, Julian Nyarko, Daniel E. Ho, Christo- pher R´ e, Adam Chilton, K. Aditya, Alex Chohlas- Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dic...
-
[5]
InAd- vances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. InAd- vances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
2023
-
[6]
Better zero-shot rea- soning with role-play prompting. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol- ume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 4099–4113. Association for Computational Linguistics. Jinqi Lai, Wensheng...
2024
-
[7]
Jailbreaking chat- gpt via prompt engineering: An empirical study. CoRR, abs/2305.13860. Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, and Daniel E. Ho
-
[8]
Hallucination-free? assessing the relia- bility of leading AI legal research tools.CoRR, abs/2405.20362. Francisco Marcondes, Adelino Gala, Renata Ma- galh˜ aes, Fernando Britto, Dalila Duraes, and Paulo Novais
-
[9]
Paul R¨ ottger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy
GPT-4 technical report.CoRR, abs/2303.08774. Paul R¨ ottger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy
-
[10]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5377–5400, Mexico City, Mexico. Association for Computational Linguistics. Swiss Federal...
2024
-
[11]
https://www.bger.ch/fr/ index.htm
Tribunal f´ ed´ eral / Schweizerisches Bundesgericht / Tri- bunale federale. https://www.bger.ch/fr/ index.htm. Accessed: 2026-05-25. Gemma Team. 2024a. Gemma: Open models based on gemini research and technology.CoRR, abs/2403.08295. Llama Team. 2024b. The llama 3 herd of models. CoRR, abs/2407.21783. Qwen Team
Pith/arXiv arXiv 2026
-
[12]
6 United States Department of Justice
Qwen3 technical report.CoRR, abs/2505.09388. 6 United States Department of Justice
-
[13]
Accessed: 2026-05-26
Epstein library. Accessed: 2026-05-26. Widener University Delaware Law School Library
2026
-
[14]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J
Qwen2.5 techni- cal report.CoRR, abs/2412.15115. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023a. Universal and transferable adversarial attacks on aligned language models. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023b. Universal and transferable adversarial at...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.