M³Exam: Benchmarking Multimodal Memory for Realistic User-Agent Interactions
Pith reviewed 2026-06-27 22:09 UTC · model grok-4.3
The pith
M³Exam benchmark reveals gaps in cross-modal grounding and cross-session reasoning for multimodal language models in realistic user-agent settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
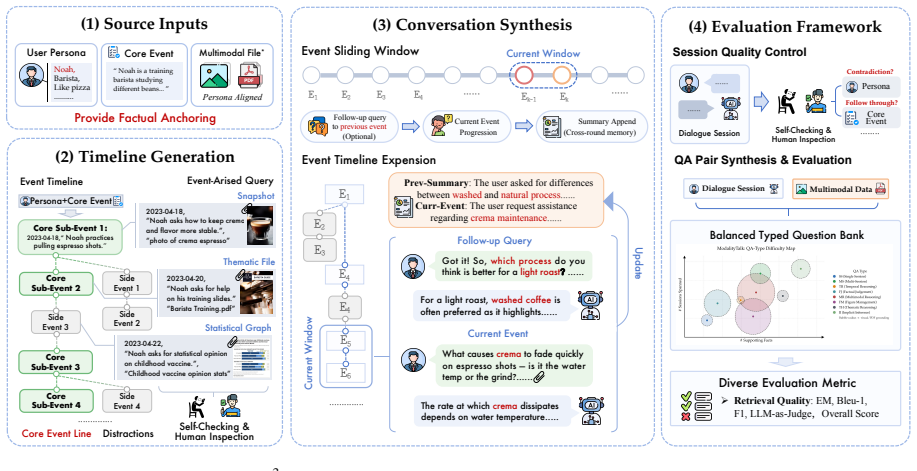
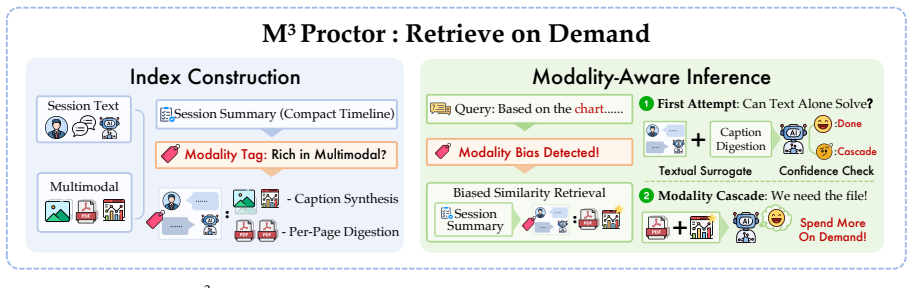
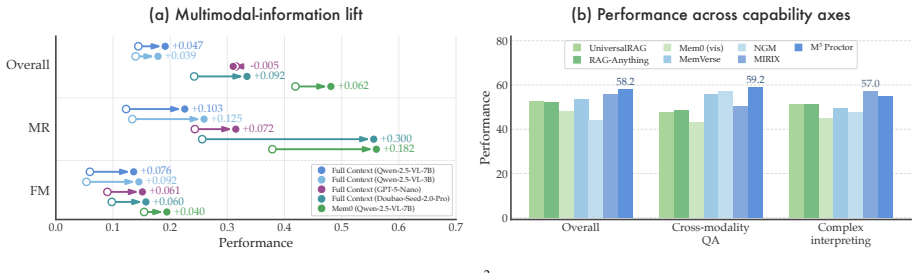
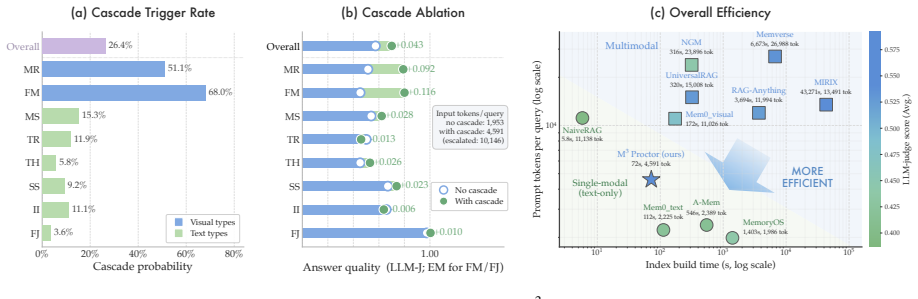
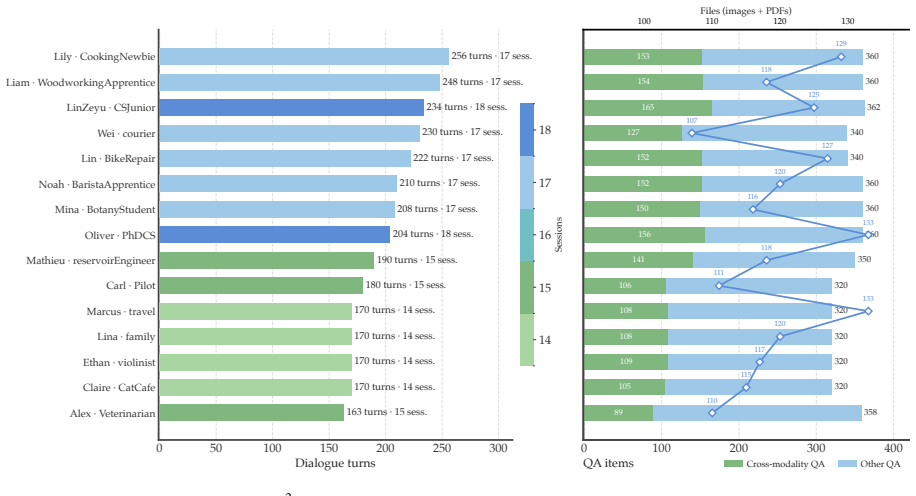
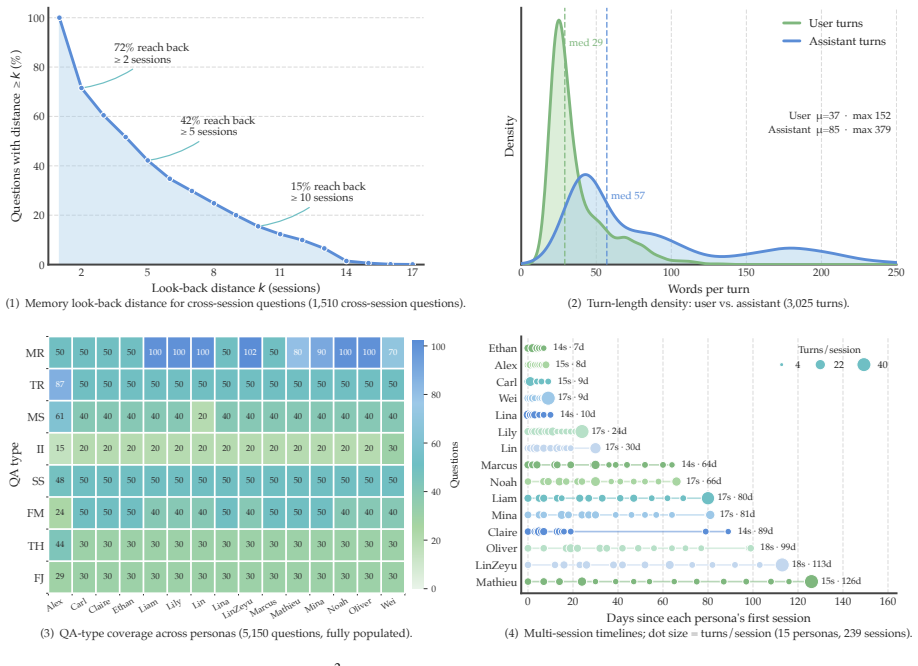
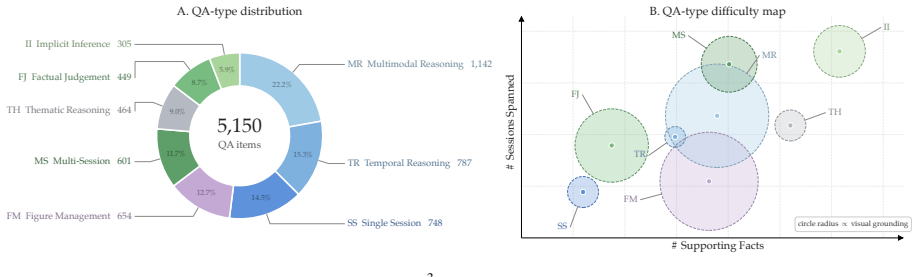
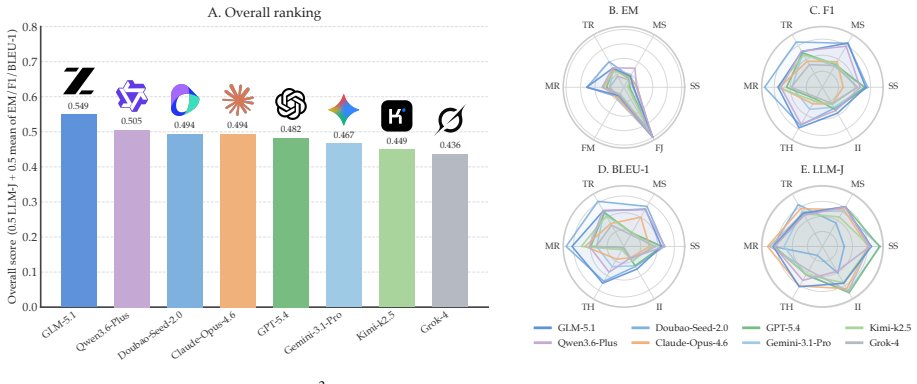
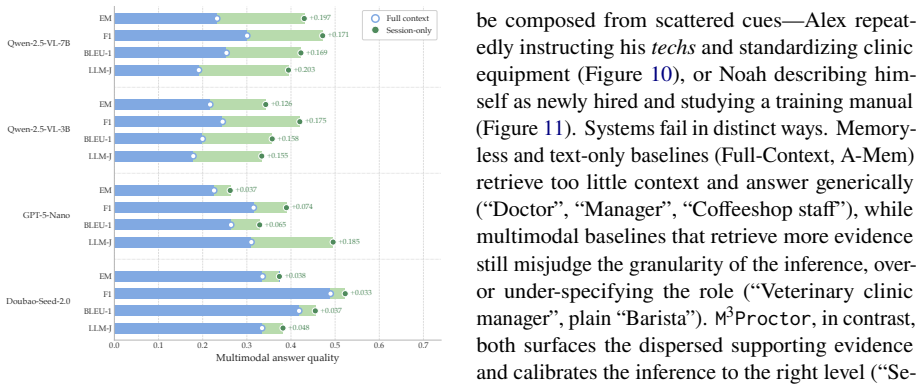
M³Exam is a benchmark for multimodal memory in user-agent interactions that includes concealed user information and authentic multimodal files. Benchmarking shows gaps in cross-modal grounding, cross session reasoning, and efficiency. M³Proctor detects query modality bias and consumes raw visual sources only on demand, improving accuracy by 13% while cutting index-construction time and retrieved tokens by over 70%.
What carries the argument
M³Exam, a query-centric multimodal conversational memory benchmark, and M³Proctor, a multimodal memory method that detects query modality bias.
If this is right
- Agents will require improved mechanisms for cross-modal grounding to handle realistic interactions.
- Memory systems must address cross-session reasoning over accumulating multimodal context.
- The efficiency cost of accumulating multimodal context needs to be mitigated for practical deployment.
- M³Proctor-style on-demand visual consumption can reduce index-construction time and retrieved tokens significantly.
Where Pith is reading between the lines
- The modality bias detection in M³Proctor might generalize to improve efficiency in non-memory multimodal tasks such as visual question answering.
- Future work could test whether the gaps persist when user information is not concealed but still multimodal.
- Lower retrieved token counts could allow agents to maintain longer interaction histories without proportional compute increases.
Load-bearing premise
The M³Exam benchmark construction accurately captures realistic user-agent interactions including concealed user information and authentic multimodal file use.
What would settle it
A direct comparison where M³Proctor fails to deliver the reported accuracy gain or token reduction when applied to a different set of user-agent interaction logs with real multimodal files.
Figures













read the original abstract
Language agents are increasingly deployed over accumulating multimodal information, yet existing benchmarks assume a human-human form with sparse visuals and straightforward content, evaluating neither reasoning over authentic multimodal file interaction nor the interpretation of concealed user information. We therefore introduce M$^3$Exam, a query-centric multimodal conversational memory benchmark built on realistic user-agent interaction, with multi-dimensional evaluation spanning cross-modal grounding and implicit information inference. Benchmarking MLLMs and memory systems reveals persistent gaps in cross-modal grounding, cross session reasoning, and the efficiency cost of accumulating multimodal context. We further propose M$^3$Proctor, a multimodal memory method that detects query modality bias and consumes raw visual sources only on demand, improving accuracy by 13% while cutting index-construction time and retrieved tokens by over 70%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces M³Exam, a query-centric multimodal conversational memory benchmark built from realistic user-agent interactions that include multimodal files and concealed user information. It evaluates MLLMs and memory systems on cross-modal grounding, cross-session reasoning, and efficiency, identifies persistent gaps, and proposes M³Proctor, which detects query modality bias and consumes raw visuals on demand, reporting a 13% accuracy improvement and over 70% reduction in index-construction time and retrieved tokens.
Significance. If the benchmark construction and evaluation hold, the work provides a more realistic testbed for multimodal agent memory than existing human-human sparse-visual benchmarks, and the on-demand processing approach in M³Proctor offers a concrete efficiency mechanism that could influence practical memory system design.
major comments (2)
- [Benchmark construction section] Benchmark construction section: the central claim that M³Exam captures 'realistic user-agent interaction' with concealed information and authentic multimodal file use (as opposed to sparse human-human forms) is load-bearing for all downstream results, yet the manuscript provides no explicit validation against real interaction logs, inter-annotator agreement on concealment, or quantitative comparison showing reduced sparsity relative to prior benchmarks.
- [Experimental results] Experimental results (accuracy and efficiency claims): the reported 13% accuracy gain and >70% reductions in index-construction time/retrieved tokens are presented without error bars, number of runs, statistical tests, or ablation on the modality-bias detection component, making it impossible to determine whether the gains are robust or sensitive to post-hoc choices.
minor comments (2)
- [Abstract] Abstract and introduction: the acronym M³Proctor is used before its expansion or high-level description is given.
- [Evaluation metrics] Notation: 'cross-modal grounding' and 'implicit information inference' are used as evaluation dimensions without a precise definition or example query in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Benchmark construction section] Benchmark construction section: the central claim that M³Exam captures 'realistic user-agent interaction' with concealed information and authentic multimodal file use (as opposed to sparse human-human forms) is load-bearing for all downstream results, yet the manuscript provides no explicit validation against real interaction logs, inter-annotator agreement on concealment, or quantitative comparison showing reduced sparsity relative to prior benchmarks.
Authors: The referee correctly identifies that the manuscript lacks explicit validation against real interaction logs and does not report inter-annotator agreement. Section 3 describes a query-centric construction process that simulates user-agent interactions with multimodal files and concealed information drawn from typical real-world patterns. In revision we will add a table with quantitative sparsity metrics (visual elements per turn and concealment rate) comparing M³Exam to prior human-human benchmarks. We will also clarify that concealment follows deterministic rules rather than subjective judgments, rendering inter-annotator agreement inapplicable. Direct validation against real logs is not feasible because the benchmark uses simulated interactions and we do not have access to proprietary real-world logs. revision: partial
-
Referee: [Experimental results] Experimental results (accuracy and efficiency claims): the reported 13% accuracy gain and >70% reductions in index-construction time/retrieved tokens are presented without error bars, number of runs, statistical tests, or ablation on the modality-bias detection component, making it impossible to determine whether the gains are robust or sensitive to post-hoc choices.
Authors: We agree that the experimental presentation would be strengthened by additional statistical detail. The revised manuscript will report all accuracy and efficiency numbers as means over five independent runs with standard error bars, include paired statistical significance tests for the 13% accuracy improvement, and add an ablation isolating the modality-bias detection component of M³Proctor. These additions will demonstrate that the reported gains are robust rather than sensitive to post-hoc choices. revision: yes
- Direct validation against real interaction logs
Circularity Check
No significant circularity; benchmark and method are empirically grounded without derivations or self-referential reductions.
full rationale
The paper introduces M³Exam as a new benchmark for multimodal memory in user-agent interactions and proposes M³Proctor as an on-demand retrieval method. No equations, derivations, or parameter-fitting steps are present in the abstract or described methodology. Claims rest on empirical accuracy/efficiency gains (13% accuracy, 70% token reduction) measured against the introduced benchmark, without any self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. The construction of the benchmark is presented as an independent contribution rather than derived from prior fitted results. This is a standard empirical benchmark paper with no internal reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[8]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
-
[9]
Making the
Goyal, Yash and Khot, Tejas and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , booktitle =. Making the
-
[10]
Marino, Kenneth and Rastegari, Mohammad and Farhadi, Ali and Mottaghi, Roozbeh , booktitle =
-
[11]
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul , booktitle =
-
[12]
and Kumar, Pratyush , booktitle =
Methani, Nitesh and Ganguly, Pritha and Khapra, Mitesh M. and Kumar, Pratyush , booktitle =
-
[13]
arXiv preprint arXiv:1710.07300 , year =
Kahou, Samira Ebrahimi and Michalski, Vincent and Atkinson, Adam and K. arXiv preprint arXiv:1710.07300 , year =
-
[14]
Kafle, Kushal and Price, Brian and Cohen, Scott and Kanan, Christopher , booktitle =
-
[15]
Proceedings of the European Conference on Computer Vision (ECCV) , year =
A Diagram Is Worth a Dozen Images , author =. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[16]
Mathew, Minesh and Karatzas, Dimosthenis and Jawahar, C. V. , booktitle =
-
[17]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
Mathew, Minesh and Bagal, Viraj and Tito, Rub. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
-
[18]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Image-Chat: Engaging Grounded Conversations , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[19]
Zang, Xiaoxue and Liu, Lijuan and Wang, Maria and Song, Yang and Zhang, Hao and Chen, Jindong , booktitle =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
Feng, Jiazhan and Sun, Qingfeng and Xu, Can and Zhao, Pu and Yang, Yaming and Tao, Chongyang and Zhao, Dongyan and Lin, Qingwei , booktitle =
-
[22]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Beyond Goldfish Memory: Long-Term Open-Domain Conversation , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[23]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of
-
[24]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[25]
, year =
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , year =. Stanford
-
[26]
Findings of the Association for Computational Linguistics: NAACL 2024 , year =
Faithful Persona-based Conversational Dataset Generation with Large Language Models , author =. Findings of the Association for Computational Linguistics: NAACL 2024 , year =
2024
-
[27]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[28]
Han, Yucheng and Zhang, Chi and Chen, Xin and Yang, Xu and Wang, Zhibin and Yu, Gang and Fu, Bin and Zhang, Hanwang , booktitle =
-
[29]
2023 , howpublished =
2023
-
[30]
arXiv preprint arXiv:2502.13923 , year=
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[31]
2024 , url=
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , author=. 2024 , url=
2024
-
[32]
arXiv preprint arXiv:2403.05530 , year=
Gemini 1.5: Unlocking Multimodal Understanding across Millions of Tokens of Context , author=. arXiv preprint arXiv:2403.05530 , year=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Towards Building Large Scale Multimodal Domain-Aware Conversation Systems , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[34]
Xue, Haochen and Tang, Feilong and Hu, Ming and Liu, Yexin and Huang, Qidong and Li, Yulong and Liu, Chengzhi and Xu, Zhongxing and Zhang, Chong and Feng, Chun-Mei and Xie, Yutong and Razzak, Imran and Ge, Zongyuan and Su, Jionglong and He, Junjun and Qiao, Yu , journal =
-
[35]
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , booktitle =
-
[36]
Mem0: Building Production-Ready
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , journal =. Mem0: Building Production-Ready
-
[37]
Li, Zhiyu and Xi, Chenyang and Li, Chunyu and Chen, Ding and Chen, Boyu and Song, Shichao and Niu, Simin and Wang, Hanyu and Yang, Jiawei and Tang, Chen and Yu, Qingchen and Zhao, Jihao and Wang, Yezhaohui and Liu, Peng and Lin, Zehao and Wang, Pengyuan and Huo, Jiahao and Chen, Tianyi and Chen, Kai and Li, Kehang and Tao, Zhen and Lai, Huayi and Wu, Hao ...
-
[38]
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle =
-
[39]
Chen, Zhiyu and Li, Shiyang and Smiley, Charese and Ma, Zhiqiang and Shah, Sameena and Wang, William Yang , booktitle =
-
[40]
Feng, Song and Wan, Hui and Gunasekara, Chulaka and Patel, Siva and Joshi, Sachindra and Lastras, Luis , booktitle =
-
[41]
Feng, Song and Patel, Siva and Wan, Hui and Joshi, Sachindra , booktitle =
-
[42]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and others , journal =
-
[43]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and others , journal =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[45]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[46]
Yeo, Woongyeong and Kim, Kangsan and Jeong, Soyeong and Baek, Jinheon and Hwang, Sung Ju , journal =
-
[47]
arXiv preprint arXiv:2510.12323 , year =
RAG-Anything: All-in-One RAG Framework , author =. arXiv preprint arXiv:2510.12323 , year =
-
[48]
arXiv preprint arXiv:2512.03627 , year =
MemVerse: Multimodal Memory for Lifelong Learning Agents , author =. arXiv preprint arXiv:2512.03627 , year =
-
[49]
Neural Graph Memory: A Structured Approach to Long-Term Memory in Multimodal Agents , author =
-
[50]
arXiv preprint arXiv:2507.07957 , year =
MIRIX: Multi-Agent Memory System for LLM-Based Agents , author =. arXiv preprint arXiv:2507.07957 , year =
-
[51]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , booktitle =
-
[52]
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =
-
[53]
Introduction to Information Retrieval , author =
-
[54]
arXiv preprint arXiv:2510.13291 , year=
Higher Satisfaction, Lower Cost: A Technical Report on How LLMs Revolutionize Meituan's Intelligent Interaction Systems , author=. arXiv preprint arXiv:2510.13291 , year=
-
[55]
arXiv preprint arXiv:2602.16313 , year=
Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks , author=. arXiv preprint arXiv:2602.16313 , year=
-
[56]
arXiv preprint arXiv:2601.03515 , year=
Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents , author=. arXiv preprint arXiv:2601.03515 , year=
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Slidevqa: A dataset for document visual question answering on multiple images , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[60]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , booktitle =
-
[61]
Liu, Ziyu and Chu, Tao and Zang, Yuhang and Wei, Xilin and Dong, Xiaoyi and Zhang, Pan and Liang, Zijian and Xiong, Yuanjun and Qiao, Yu and Lin, Dahua and Wang, Jiaqi , journal =
-
[62]
Hu, Yuanzhe and others , journal =
-
[63]
arXiv preprint arXiv:2507.05257 , year=
Evaluating memory in llm agents via incremental multi-turn interactions , author=. arXiv preprint arXiv:2507.05257 , year=
-
[64]
2026 , month =
Introducing. 2026 , month =
2026
-
[65]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Memory os of ai agent , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.