AutoTrainess: Teaching Language Models to Improve Language Models Autonomously
Pith reviewed 2026-07-01 05:37 UTC · model grok-4.3
The pith
AutoTrainess lets language models autonomously post-train other models by replacing raw command lines with explicit workflows and interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
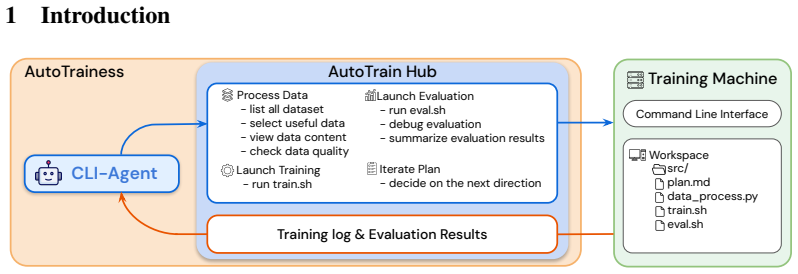
AutoTrainess is an LM agent that exposes post-training operations as a repository of agent-computer interfaces for planning, data preparation, training, evaluation, and logging; rather than operating in an underspecified CLI environment, it externalizes prior human experience as explicit workflows, rules, and execution constraints that guide the agent toward reliable training behavior.
What carries the argument
AutoTrainess, the system of agent-computer interfaces and guiding workflows that externalizes human post-training experience into structured operations for the LM agent.
If this is right
- AutoTrainess raises PostTrainBench average scores above CLI-only baselines for GPT-5.4 (Codex) and DeepSeek-V4-Flash.
- The same structured interfaces improve results across different language models and training harnesses.
- Encoding human workflows as explicit constraints makes long-horizon autonomous training more stable and repeatable.
- The agent can now carry out the full cycle of planning, data construction, training, and evaluation without constant human oversight.
Where Pith is reading between the lines
- If the interfaces generalize, teams could run overnight training experiments with far less expert supervision.
- The same pattern of externalizing domain workflows might apply to other long-horizon agent tasks such as scientific data pipelines.
- Success here suggests that future agents may need rich, task-specific interface layers rather than only raw tool access.
Load-bearing premise
Benchmark score differences between AutoTrainess and CLI baselines reflect real gains in autonomous training ability rather than artifacts of the particular test setup.
What would settle it
A controlled run on a fresh model and benchmark where AutoTrainess produces no higher scores or fewer successful training jobs than a plain CLI agent would falsify the central claim.
Figures


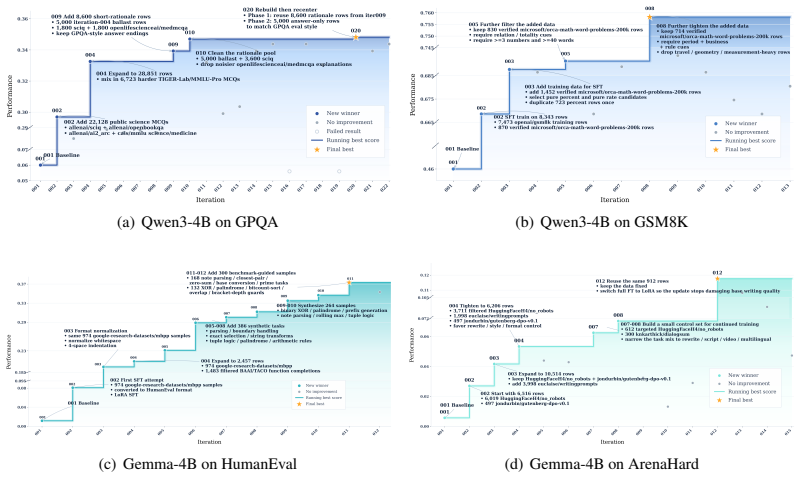
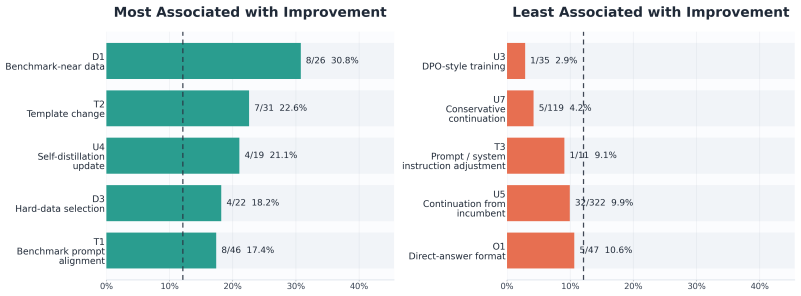

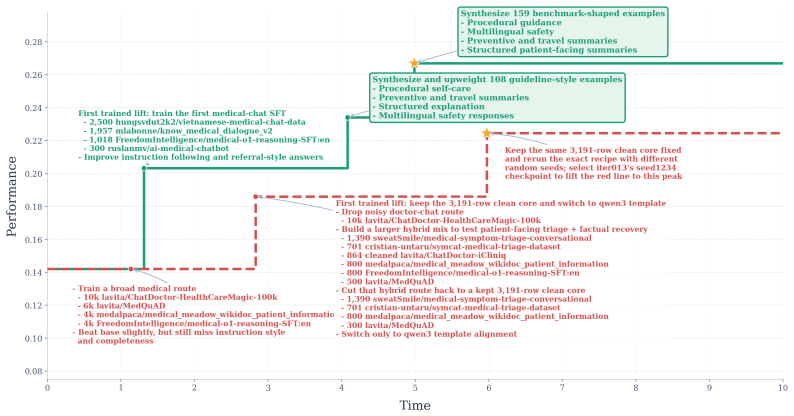










read the original abstract
Training language models (LMs) remains a highly human-intensive process, even as frontier language model agents become increasingly capable at software engineering and other long-horizon tasks. A central challenge is that autonomous post-training is not just a coding problem: it requires the agent to repeatedly plan iterations, construct benchmark-aligned data, run stable training jobs, evaluate checkpoints, and preserve experiment state across many hours of interaction. We present AutoTrainess, a LM agent that exposes these operations as a repository of agent-computer interfaces for planning, data preparation, training, evaluation, and logging. Rather than leaving the agent to operate in a raw CLI environment with an underspecified action space, AutoTrainess externalizes prior human experience as explicit workflows, rules, and execution constraints that guide the agent toward effective and reliable training behavior. On PostTrainBench, AutoTrainess consistently outperforms CLI-only baselines, achieving 26.94 average score with GPT-5.4 (Codex) versus 23.21 for CLI-only. It also generalizes across models and harnesses, improving DeepSeek-V4-Flash (OpenCode) from 12.13 to 19.58.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoTrainess, an LM agent for autonomous post-training of language models. It exposes operations for planning, data preparation, training, evaluation, and logging as agent-computer interfaces, externalizing human experience via explicit workflows, rules, and execution constraints rather than raw CLI. The central empirical claim is that this yields consistent gains on PostTrainBench: 26.94 average score with GPT-5.4 (Codex) versus 23.21 for CLI-only, and generalization to DeepSeek-V4-Flash (OpenCode) from 12.13 to 19.58.
Significance. If the reported gains prove robust to controls, variance, and equivalent baselines, the work could meaningfully advance autonomous ML operations by demonstrating the value of structured interfaces for long-horizon training tasks. The approach of codifying prior human workflows into agent-accessible constraints is a concrete contribution that could reduce reliance on manual intervention, provided the benchmark results generalize beyond the specific harness.
major comments (3)
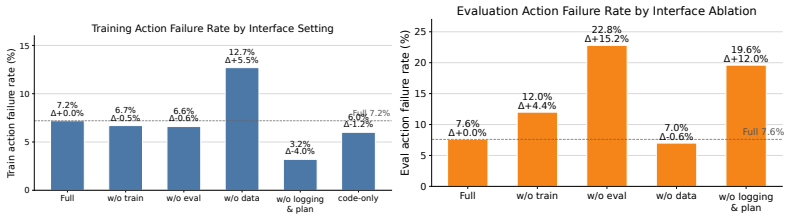
- [Abstract] Abstract: the 3.73-point (GPT-5.4) and 7.45-point (DeepSeek) gains are presented as evidence that exposed interfaces outperform raw CLI, yet no information is supplied on task distribution within PostTrainBench, number of runs, variance, or statistical significance; without these, it is impossible to rule out that the differences are artifacts of the specific setup rather than general capability gains.
- [Abstract] Abstract: the CLI-only baseline is asserted to be inferior, but the text supplies no description of its action space, state-tracking mechanism, or whether it receives equivalent information to AutoTrainess; this equivalence is load-bearing for the central claim that the improvement stems from the explicit workflows and constraints rather than from differences in available tools.
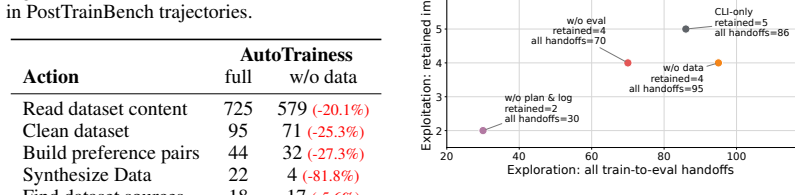
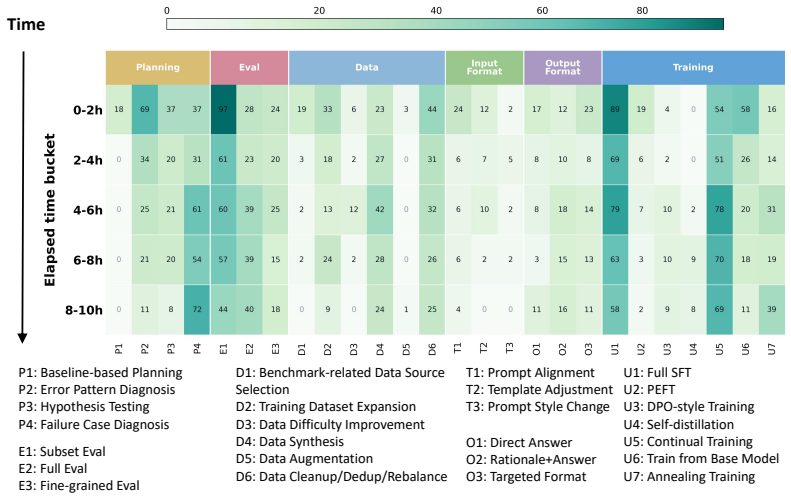
- [Abstract] Abstract: the generalization claim across models and harnesses is stated without any detail on the concrete workflows, rules, or execution constraints that were implemented, leaving open whether the measured improvement is due to the interface design or to unstated implementation choices that may not transfer.
minor comments (1)
- [Abstract] Abstract: model identifiers such as 'GPT-5.4 (Codex)' and 'DeepSeek-V4-Flash (OpenCode)' are non-standard and should be clarified with references to exact versions or citations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that will strengthen the clarity and rigor of the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 3.73-point (GPT-5.4) and 7.45-point (DeepSeek) gains are presented as evidence that exposed interfaces outperform raw CLI, yet no information is supplied on task distribution within PostTrainBench, number of runs, variance, or statistical significance; without these, it is impossible to rule out that the differences are artifacts of the specific setup rather than general capability gains.
Authors: We agree that the abstract should include or reference these details to allow readers to assess robustness. The full manuscript reports results aggregated over multiple runs on PostTrainBench; in the revision we will explicitly state the number of runs, report variance or standard deviation, note any statistical tests, and summarize the task distribution within the benchmark. revision: yes
-
Referee: [Abstract] Abstract: the CLI-only baseline is asserted to be inferior, but the text supplies no description of its action space, state-tracking mechanism, or whether it receives equivalent information to AutoTrainess; this equivalence is load-bearing for the central claim that the improvement stems from the explicit workflows and constraints rather than from differences in available tools.
Authors: The CLI-only baseline operates in the same underlying environment but lacks the structured workflows, rules, and constraints provided by AutoTrainess. To make this equivalence explicit, the revision will add a dedicated paragraph describing the action space, state representation, and information available to the CLI-only agent. revision: yes
-
Referee: [Abstract] Abstract: the generalization claim across models and harnesses is stated without any detail on the concrete workflows, rules, or execution constraints that were implemented, leaving open whether the measured improvement is due to the interface design or to unstated implementation choices that may not transfer.
Authors: We will expand the methods section with concrete descriptions and examples of the workflows, rules, and execution constraints used for each model/harness pair. This will allow readers to evaluate transferability of the interface design. revision: yes
Circularity Check
No circularity: empirical system comparison with no derivation chain
full rationale
The paper presents an agent system (AutoTrainess) and reports direct empirical scores on PostTrainBench against CLI baselines. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The performance claims (e.g., 26.94 vs 23.21) are presented as measured outcomes rather than derived quantities that reduce to their own inputs by construction. This is standard empirical reporting with no identifiable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[2]
Mlagentbench: Evaluating language agents on machine learning experimentation
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty- first International Conference on Machine Learning, ICML 2024, Vienna, Austria,...
2024
-
[3]
Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algori...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Alpharesearch: Accelerating new algorithm discovery with language models.CoRR, abs/2511.08522, 2025
Zhaojian Yu, Kaiyue Feng, Yilun Zhao, Shilin He, Xiao-Ping Zhang, and Arman Co- han. Alpharesearch: Accelerating new algorithm discovery with language models.CoRR, abs/2511.08522, 2025
-
[5]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[6]
Posttrainbench: Can llm agents automate llm post- training?arXiv preprint arXiv:2603.08640, 2026
Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andriushchenko. Posttrainbench: Can LLM agents automate LLM post-training? CoRR, abs/2603.08640, 2026
-
[7]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Yixin Cao, Yang Feng, and Deyi Xiong, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), ACL 2024, Bangkok, Thailand, August 11-16, 202...
2024
-
[8]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second Interna...
2025
-
[9]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): from tool use to agentic evaluation of large language models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, ed...
2025
-
[10]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.CoRR, abs/2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference o...
2023
-
[15]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents.CoRR, abs/2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.CoRR, abs/2404.07972, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Riosworld: Benchmarking the risk of multimodal computer-use agents.CoRR, abs/2506.00618, 2025
Jingyi Yang, Shuai Shao, Dongrui Liu, and Jing Shao. Riosworld: Benchmarking the risk of multimodal computer-use agents.CoRR, abs/2506.00618, 2025
-
[19]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob N. Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery.CoRR, abs/2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Openresearcher: Unleashing AI for accelerated scientific research
Yuxiang Zheng, Shichao Sun, Lin Qiu, Dongyu Ru, Cheng Jiayang, Xuefeng Li, Jifan Lin, Binjie Wang, Yun Luo, Renjie Pan, Yang Xu, Qingkai Min, Zizhao Zhang, Yiwen Wang, Wenjie Li, and Pengfei Liu. Openresearcher: Unleashing AI for accelerated scientific research. In Delia Irazú Hernández Farías, Tom Hope, and Manling Li, editors,Proceedings of the 2024 Con...
2024
-
[21]
Zhuofeng Li, Dongfu Jiang, Xueguang Ma, Haoxiang Zhang, Ping Nie, Yuyu Zhang, Kai Zou, Jianwen Xie, Yu Zhang, and Wenhu Chen. Openresearcher: A fully open pipeline for long-horizon deep research trajectory synthesis.CoRR, abs/2603.20278, 2026
-
[22]
Juraj Gottweis, Wei-Hung Weng, Alexander N. Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. Core- bench: Fostering the credibility of published research through a computational reproducibility agent benchmark.Trans. Mach. Learn. Res., 2024, 2024
2024
-
[24]
Mle-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. Mle-bench: Evaluating machine learning agents on machine learning engineering. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 2...
2025
-
[25]
Paperbench: Evaluating ai’s ability to replicate AI research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate AI research. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Mahara...
2025
-
[26]
Tianshi Zheng, Kelvin Kiu-Wai Tam, Newt Hue-Nam K. Nguyen, Baixuan Xu, Zhaowei Wang, Jiayang Cheng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, Yangqiu Song, Ginny Y . Wong, and Simon See. Newtonbench: Benchmarking generalizable scientific law discovery in LLM agents.CoRR, abs/2510.07172, 2025
-
[27]
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Lei Xiong, Kun Luo, Ziyi Xia, Wenbo Zhang, Jin-Ge Yao, Zheng Liu, Jingying Shao, Jianlyu Chen, Hongjin Qian, Xi Yang, Qian Yu, Hao Li, Chen Yue, Xiaan Du, Yuyang Wang, Yesheng Liu, Haiyu Xu, and Zhicheng Dou. Autoresearchbench: Benchmarking AI agents on complex scientific literature discovery.CoRR, abs/2604.25256, 2026. 12 A Case Study on the Effects of D...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Prepare the current base model for evaluation
-
[29]
Run the real benchmark evaluation
-
[30]
Record the evaluation setup and result. Decision rules: - If an explicit target exists and the base model already reaches the target, stop.,→ - If evaluation fails because of an engineering or environment issue, fix the issue and repeat Stage 1. Otherwise, enter Stage 2.,→ ### Stage 2: Local Diagnosis and Optimization Run local iterations to establish a r...
-
[31]
Review previous experiment results and identify the main problems
-
[32]
Decide what the current iteration is mainly trying to improve
-
[33]
Define the main changes to make in this iteration
-
[34]
State what outcome will count as success for this iteration
-
[35]
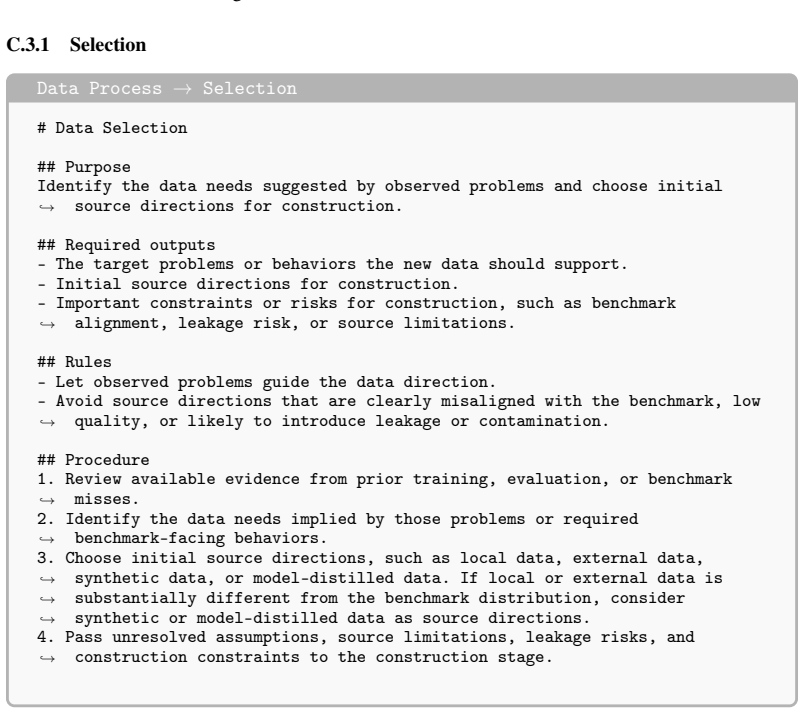
Figure 12: Instruction ofPlanskill
Provide concise guidance for downstream data and training work. Figure 12: Instruction ofPlanskill. C.3 Data Process Data Process --- name: data description: Use when preparing training data. metadata: short-description: Prepare training data --- # data ## Purpose Prepare training data that addresses real problems exposed by previous training or evaluatio...
-
[36]
Read [shared/conventions.md](./shared/conventions.md) for shared rules
-
[37]
Run [selection/stage.md](./selection/stage.md) to identify target data needs and initial source directions.,→
-
[38]
Run [construction/stage.md](./construction/stage.md) to turn those needs and directions into a benchmark-aligned training dataset.,→
-
[39]
Run [validation/stage.md](./validation/stage.md) for data validation before training.,→
-
[40]
If validation finds target-need or source-direction issues, return to selection
If validation finds construction issues, return to construction. If validation finds target-need or source-direction issues, return to selection. ,→ ,→ ## Required outputs - A final training dataset ready for downstream training. 19 - A concise dataset description covering target problems, data sources, sample format, known limitations, and validation sta...
-
[41]
Review available evidence from prior training, evaluation, or benchmark misses.,→
-
[42]
Identify the data needs implied by those problems or required benchmark-facing behaviors.,→
-
[43]
If local or external data is substantially different from the benchmark distribution, consider synthetic or model-distilled data as source directions
Choose initial source directions, such as local data, external data, synthetic data, or model-distilled data. If local or external data is substantially different from the benchmark distribution, consider synthetic or model-distilled data as source directions. ,→ ,→ ,→
-
[44]
Pass unresolved assumptions, source limitations, leakage risks, and construction constraints to the construction stage.,→ Figure 14: Instruction ofSelectioninData Processskill. C.3.2 Construction AGENTS # Data Construction ## Purpose Turn the selected data needs and initial source directions into a benchmark-aligned training dataset.,→ ## Required outputs...
-
[45]
Review the target problems, source directions, constraints, and risks passed from selection.,→
-
[46]
Inspect the benchmark evaluation path and render or reconstruct several evaluation-style examples when possible.,→
-
[47]
Decide the target training sample format from the observed model-facing input, expected output form, answer boundary, and final-answer location.,→
-
[48]
If they are viable, continue construction; if not, return to selection
Inspect candidate sources and decide whether they can support the target data needs. If they are viable, continue construction; if not, return to selection. ,→ ,→
-
[49]
Extract, clean, rewrite, restructure, synthesize, or distill samples as needed.,→
-
[50]
Filter out broken, unreadable, empty, duplicated, misaligned, or clearly low-value samples, then reduce redundant or weakly relevant samples to keep the dataset focused. ,→ ,→
-
[51]
Produce the final dataset and dataset description. ## Decision standard The stage is complete when the dataset is usable for training, aligned with the benchmark-facing task, and described well enough for validation.,→ Figure 15: Instruction ofConstructioninData Processskill. C.3.3 Validation Data Process→Validation # Data Validation ## Purpose Validate t...
-
[52]
Inspect the constructed dataset and dataset description
-
[53]
Check structural correctness, including schema, required fields, encoding, and malformed samples.,→
-
[54]
Compare several constructed training samples against the rendered evaluation-style examples.,→
-
[55]
Check whether the dataset matches the benchmark evaluation interface and target behaviors.,→
-
[56]
Review sample quality and look for garbage, corruption, duplication, leakage risk, or unrealistic synthesis.,→
-
[57]
Decide whether any detected problem belongs to construction or selection
-
[58]
Produce one of three decisions: - approve for training - return to construction - return to selection ## Decision standard The stage is complete when the dataset is approved for training or sent back with a clear reason and return target.,→ 22 Figure 16: Instruction ofValidationinData Processskill. C.4 Training Training --- name: train description: Use wh...
-
[59]
Read [shared/llamafactory.md](./shared/llamafactory.md)
-
[60]
Decide whether the current stage requires [sft/stage.md](./sft/stage.md) or [rl/stage.md](./rl/stage.md).,→
-
[61]
Follow the selected stage document
-
[62]
Run training through the provided script in`scripts/`
-
[63]
Figure 17: Instruction ofTrainingskill
Export`final_model/`for evaluation. Figure 17: Instruction ofTrainingskill. C.4.1 SFT Training→SFT # SFT Stage ## Purpose Run the minimum valid supervised fine-tuning workflow for the current stage with LlamaFactory.,→ ## Inputs - The training dataset prepared by the data workflow. 23 - The benchmark-facing sample format or schema. - A valid base model pa...
-
[64]
Review the prepared training data and its benchmark-facing format
-
[66]
Prepare the minimum SFT dataset assets and verify the LlamaFactory config using`shared/llamafactory.md`.,→
-
[67]
Run a small validation training with`scripts/run_llamafactory.sh`
-
[68]
If the validation run is usable, continue the intended SFT run
-
[69]
## Decision standard The stage is complete only when the SFT run is reproducible, the exported model is evaluation-ready, and the result is not justified by training loss alone
Export`final_model/`and leave it ready for evaluation. ## Decision standard The stage is complete only when the SFT run is reproducible, the exported model is evaluation-ready, and the result is not justified by training loss alone. ,→ ,→ Figure 18: Instruction ofSFTinTrainingskill. C.4.2 RL Training→RL # RL Stage ## Purpose Run the minimum valid RL workf...
-
[70]
Review the latest evaluation evidence and confirm that RL is justified
-
[71]
Read`shared/llamafactory.md`and confirm that LlamaFactory is usable
-
[72]
Prepare the minimum reward setup or RL data, and verify the LlamaFactory config using`shared/llamafactory.md`.,→
-
[73]
Run a small validation RL run with`scripts/run_llamafactory.sh`
-
[74]
If the validation run is usable, continue the intended RL run
-
[75]
Export`final_model/`and leave it ready for evaluation. ## Decision standard 24 The stage is complete only when RL is justified by current evidence, the run is reproducible, and the exported model is ready for real evaluation.,→ Figure 19: Instruction ofRLinTrainingskill. C.4.3 Shared Instruction Training→Shared # LlamaFactory Workflow ## Purpose Define th...
-
[76]
Locate the canonical evaluation entrypoint
-
[77]
If using a limited evaluation, determine the benchmark sample count and choose a limit that satisfies the sample-floor rule.,→
-
[78]
Run evaluation on`final_model/`
-
[79]
Save raw outputs, commands, the sample count or limit used, and a concise metrics summary under`eval_results/`.,→
-
[80]
If evaluation fails, debug it inside the benchmark's real evaluation workflow, then retry with the minimum necessary fix.,→
-
[81]
Use `skills/eval/scripts/summarize_eval_samples.py`when compatible `inspect_ai`logs are available; otherwise, add the minimum benchmark-specific script or logging needed
Generate`eval_results/sample_summary.md`with 15 random samples including score, input, target, and model output. Use `skills/eval/scripts/summarize_eval_samples.py`when compatible `inspect_ai`logs are available; otherwise, add the minimum benchmark-specific script or logging needed. ,→ ,→ ,→ ,→
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.