SA-VIS: Sparse frame Annotations for training Video Instance Segmentation
Pith reviewed 2026-06-30 10:43 UTC · model grok-4.3
The pith
A simple feature propagation module trains video instance segmentation on one-fifth the labels with only a 0.4 percent accuracy drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
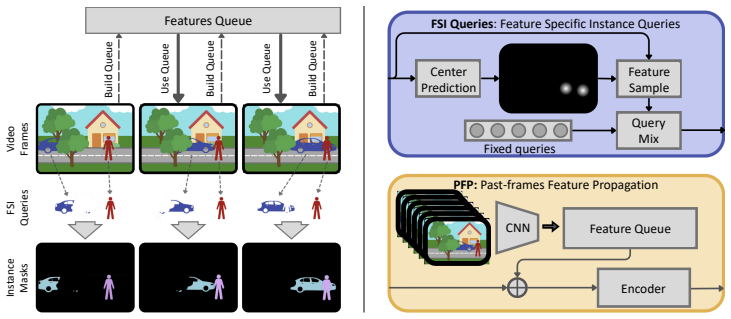
The Past-frames Feature Propagation module aggregates low-dimensional features across multiple past frames inside the image encoder, supplying temporal context that lets the model learn instance motion and identity from sparse video labels. When paired with frame-specific Instance Queries, this yields end-to-end training whose accuracy on YouTube-VIS and OVIS falls only 0.4 percent below the same architecture trained on fully dense annotations.
What carries the argument
Past-frames Feature Propagation (PFP) module, which aggregates low-dimensional features from the image encoder of multiple frames to supply temporal context for instance modeling.
If this is right
- SA-VIS raises accuracy over its baseline on YouTube-VIS 2019/2021/2022 and on OVIS.
- In low-annotation regimes the method improves AP by more than 1 percent over prior state-of-the-art.
- The same architecture trained on 20 percent of frames retains nearly all accuracy of its dense counterpart.
- No additional temporal modeling components are required once the propagation module is added.
Where Pith is reading between the lines
- The result implies that many video tasks may tolerate far sparser supervision once simple feature reuse is introduced.
- Extending the propagation window to longer sequences could test whether the low-dimensional cue remains sufficient.
- The same module might reduce labeling needs in related tasks such as video object tracking.
Load-bearing premise
Low-dimensional features from sparsely labeled past frames are enough to capture how instances move and stay distinct without dense labels or extra temporal networks.
What would settle it
Train SA-VIS on 1/5 annotations and measure AP on YouTube-VIS 2019; if the drop versus the dense version exceeds 2 percent, the core claim fails.
Figures

read the original abstract
Recent online video instance segmentation (VIS) methods have achieved impressive results, thus becoming the preferred approach to segment instances in videos. Despite the resurgence of impressive single image models, the online (or semi-online) VIS approaches outperform single-image models (e.g., based on SAM) by using long sequences of densely annotated frames during training. However,such a training setup of VIS is expensive in the sense of compute as well as dense annotations required. In order to solve these major flaws, we argue that the effective modeling of the instances and their evolution in videos do not require densely annotated frames. To that end, we propose a simple and effective module, called Past-frames Feature Propagation (PFP) which aggregates low-dimensional features from the image encoder of multiple frames. This simple low-compute module provides tremendous learning capability in using sparse video frame labels for end-to-end training. Combined with a light-weight frame-specific Instance Queries, our Sparse frame Annotation VIS (SA-VIS) significantly improves performance over its baseline. Most interestingly, our simple design that avoids complexities effectively bridges the gap in accuracy between training on sparsely and densely annotated video sequences. This translates to a mere 0.4% drop in performance of SA-VIS when using annotations for only 1/5 of the images in the dataset. Empirically, SA-VIS shows strong improvements over the baseline on YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS) and an over 1% improvement in AP on the state-of-the-art in a limited annotations scenario.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SA-VIS for online video instance segmentation, introducing a Past-frames Feature Propagation (PFP) module that aggregates low-dimensional features from the image encoder across multiple (sparsely annotated) frames, combined with lightweight frame-specific instance queries. The central empirical claim is that this simple design bridges the performance gap between sparse and dense annotation regimes, yielding only a 0.4% AP drop when training on annotations for 1/5 of the frames versus full dense supervision, while also outperforming baselines and prior SOTA by over 1% AP in the limited-annotation setting on YouTube-VIS 2019/2021/2022 and OVIS.
Significance. If the reported numbers hold after verification, the result would be significant for reducing the annotation and compute burden of VIS training. The approach demonstrates that low-dimensional feature aggregation plus per-frame queries can nearly close the dense-vs-sparse gap without extra temporal modules. Credit is given for evaluating on multiple standard benchmarks (YouTube-VIS 2019/2021/2022 and OVIS) and for the reproducible experimental setup implied by the benchmark comparisons.
major comments (2)
- [Abstract] Abstract: the central claim of a 'mere 0.4% drop' when using annotations for only 1/5 of the images is presented without error bars, number of runs, statistical significance tests, or explicit baseline definitions (dense vs. sparse SA-VIS), which is load-bearing for the assertion that the gap is effectively bridged.
- [§4] §4 (Experiments): the reported gains over baselines and SOTA in the sparse regime lack details on ablation controls isolating PFP from the frame-specific queries, as well as variance across runs, undermining verification of the 0.4% claim and the 'simple design' sufficiency argument.
minor comments (2)
- [Abstract] Abstract: missing space after the comma in 'However,such a training setup'.
- [Abstract] Abstract: 'an over 1% improvement' appears to be a typographical error and should read 'and over 1% improvement'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying the empirical claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 'mere 0.4% drop' when using annotations for only 1/5 of the images is presented without error bars, number of runs, statistical significance tests, or explicit baseline definitions (dense vs. sparse SA-VIS), which is load-bearing for the assertion that the gap is effectively bridged.
Authors: We agree the abstract would benefit from explicit context. In revision we will define the dense vs. sparse SA-VIS comparison (same architecture and training protocol, differing only in annotation density) and report error bars plus number of runs. The 0.4% figure is the direct AP difference on YouTube-VIS between full dense supervision and 1/5-frame annotations for the identical SA-VIS model. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains over baselines and SOTA in the sparse regime lack details on ablation controls isolating PFP from the frame-specific queries, as well as variance across runs, undermining verification of the 0.4% claim and the 'simple design' sufficiency argument.
Authors: We will add the requested ablation controls that isolate PFP from frame-specific queries and will report standard deviation across multiple runs in the revised §4. These additions will allow direct verification of the 0.4% gap and the contribution of each component. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes an empirical architecture (PFP module for aggregating low-dimensional encoder features plus frame-specific queries) and reports benchmark results on YouTube-VIS and OVIS. No derivation chain, equations, or first-principles claims exist that reduce by construction to fitted inputs or self-citations. Performance numbers (e.g., 0.4% AP drop on 1/5 annotations) are external comparisons against baselines and prior SOTA; the central claim is falsifiable on held-out data and does not rely on self-referential definitions or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16
Cao, J., Anwer, R.M., Cholakkal, H., Khan, F.S., Pang, Y ., Shao, L.: Sipmask: Spatial information preservation for fast image and video instance segmentation. In: Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. pp. 1–18. Springer (2020)
2020
-
[2]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[3]
ArXivabs/2112.10764(2021), https://api
Cheng, B., Choudhuri, A., Misra, I., Kirillov, A., Girdhar, R., Schwing, A.G.: Mask2former for video instance segmentation. ArXivabs/2112.10764(2021), https://api. semanticscholar.org/CorpusID:245335013
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Cheng, B., Collins, M.D., Zhu, Y ., Liu, T., Huang, T.S., Adam, H., Chen, L.C.: Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[5]
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask trans- former for universal image segmentation (2022)
2022
-
[6]
Cheng, B., Schwing, A.G., Kirillov, A.: Per-pixel classification is not all you need for semantic segmentation (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Choudhuri, A., Chowdhary, G., Schwing, A.G.: Context-aware relative object queries to unify video instance and panoptic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6377–6386 (June 2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Choudhuri, A., Chowdhary, G., Schwing, A.G.: Context-aware relative object queries to unify video instance and panoptic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6377–6386 (2023)
2023
-
[9]
IEEE Transactions on Circuits and Systems for Video Technology pp
Fang, H., Zhang, T., Zhou, X., Zhang, X.: Learning better video query with sam for video instance segmentation. IEEE Transactions on Circuits and Systems for Video Technology pp. 1–1 (2024). https://doi.org/10.1109/TCSVT.2024.3361076
-
[10]
Fischer, T., Huang, T.E., Pang, J., Qiu, L., Chen, H., Darrell, T., Yu, F.: Qdtrack: Quasi-dense similarity learning for appearance-only multiple object tracking (2023)
2023
-
[11]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fu, Y ., Yang, L., Liu, D., Huang, T.S., Shi, H.: Compfeat: Comprehensive feature aggrega- tion for video instance segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 1361–1369 (2021)
2021
-
[12]
In: Proceedings of the IEEE International Conference on Computer Vision
Gadde, R., Jampani, V ., Gehler, P.V .: Semantic video cnns through representation warping. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 4453–4462 (2017)
2017
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Han, S.H., Hwang, S., Oh, S.W., Park, Y ., Kim, H., Kim, M.J., Kim, S.J.: Visolo: Grid-based space-time aggregation for efficient online video instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2896–2905 (2022)
2022
-
[14]
arXiv preprint arXiv:2305.17096 (2023)
Hannan, T., Koner, R., Bernhard, M., Shit, S., Menze, B., Tresp, V ., Schubert, M., Seidl, T.: Gratt-vis: Gated residual attention for auto rectifying video instance segmentation. arXiv preprint arXiv:2305.17096 (2023)
-
[15]
Advances in Neural Information Processing Systems35, 19370–19383 (2022)
He, F., Zhang, H., Gao, N., Jia, J., Shan, Y ., Zhao, X., Huang, K.: Inspro: Propagating instance query and proposal for online video instance segmentation. Advances in Neural Information Processing Systems35, 19370–19383 (2022)
2022
-
[16]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
He, K., Gkioxari, G., Dollar, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
2017
-
[17]
In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
2016
-
[18]
In: CVPR (2023)
Heo, M., Hwang, S., Hyun, J., Kim, H., Oh, S.W., Lee, J.Y ., Kim, S.J.: A generalized framework for video instance segmentation. In: CVPR (2023)
2023
-
[19]
In: Advances in Neural Information Processing Systems (2022) 10
Heo, M., Hwang, S., Oh, S.W., Lee, J.Y ., Kim, S.J.: Vita: Video instance segmentation via object token association. In: Advances in Neural Information Processing Systems (2022) 10
2022
-
[20]
Huang, D.A., Yu, Z., Anandkumar, A.: Minvis: A minimal video instance segmentation framework without video-based training (2022)
2022
-
[21]
Advances in Neural Information Processing Systems34, 13352– 13363 (2021)
Hwang, S., Heo, M., Oh, S.W., Kim, S.J.: Video instance segmentation using inter-frame communication transformers. Advances in Neural Information Processing Systems34, 13352– 13363 (2021)
2021
-
[22]
In: Computer Vision – ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IV (2023)
Jiang, Z., Gu, Z., Peng, J., Zhou, H., Liu, L., Wang, Y ., Tai, Y ., Wang, C., Zhang, L.: Stc: Spatio-temporal contrastive learning for video instance segmentation. In: Computer Vision – ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IV (2023)
2022
-
[23]
In: Proceedings of the IEEE International Conference on Computer Vision
Jin, X., Li, X., Xiao, H., Shen, X., Lin, Z., Yang, J., Chen, Y ., Dong, J., Liu, L., Jie, Z., et al.: Video scene parsing with predictive feature learning. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5580–5588 (2017)
2017
-
[24]
In: CVPR (2023)
Ke, L., Danelljan, M., Ding, H., Tai, Y .W., Tang, C.K., Yu, F.: Mask-free video instance segmentation. In: CVPR (2023)
2023
-
[25]
arXiv preprint arXiv:2208.10547 (2022)
Koner, R., Hannan, T., Shit, S., Sharifzadeh, S., Schubert, M., Seidl, T., Tresp, V .: Instance- former: An online video instance segmentation framework. arXiv preprint arXiv:2208.10547 (2022)
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lin, C.C., Hung, Y ., Feris, R., He, L.: Video instance segmentation tracking with a modified vae architecture. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13147–13157 (2020)
2020
-
[27]
In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13
Lin, T.Y ., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. pp. 740–755. Springer (2014)
2014
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, D., Cui, Y ., Tan, W., Chen, Y .: Sg-net: Spatial granularity network for one-stage video instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9816–9825 (2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, Z., Lin, Y ., Cao, Y ., Hu, H., Wei, Y ., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Nilsson, D., Sminchisescu, C.: Semantic video segmentation by gated recurrent flow propaga- tion. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6819–6828 (2018)
2018
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Porzi, L., Hofinger, M., Ruiz, I., Serrat, J., Bulo, S.R., Kontschieder, P.: Learning multi-object tracking and segmentation from automatic annotations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6846–6855 (2020)
2020
-
[32]
In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round
Qi, J., Gao, Y ., Hu, Y ., Wang, X., Liu, X., Bai, X., Belongie, S., Yuille, A., Torr, P., Bai, S.: Occluded video instance segmentation: Dataset and ICCV 2021 challenge. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round
2021
-
[33]
(2021),https://openreview.net/forum?id=IfzTefIU_3j
2021
-
[34]
In: Com- puter Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16
Tian, Z., Shen, C., Chen, H.: Conditional convolutions for instance segmentation. In: Com- puter Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. pp. 282–298. Springer (2020)
2020
-
[35]
In: Guyon, I., Luxburg, U.V ., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V ., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Process- ing Systems. vol. 30. Curran Associates, Inc. (2017), https://proceedings.neur...
2017
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
V oigtlaender, P., Krause, M., Osep, A., Luiten, J., Sekar, B.B.G., Geiger, A., Leibe, B.: Mots: Multi-object tracking and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[37]
In: Proc
Wang, Y ., Xu, Z., Wang, X., Shen, C., Cheng, B., Shen, H., Xia, H.: End-to-end video instance segmentation with transformers. In: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR) (2021) 11
2021
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, D., Wang, T., Zhang, Y ., Zhang, X., Shen, J.: Onlinerefer: A simple online baseline for referring video object segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2761–2770 (2023)
2023
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, J., Cao, J., Song, L., Wang, Y ., Yang, M., Yuan, J.: Track to detect and segment: An online multi-object tracker. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12352–12361 (2021)
2021
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, J., Yarram, S., Liang, H., Lan, T., Yuan, J., Eledath, J., Medioni, G.: Efficient video instance segmentation via tracklet query and proposal. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 959–968 (2022)
2022
-
[41]
arXiv preprint arXiv:2112.08275 (2021)
Wu, J., Jiang, Y ., Zhang, W., Bai, X., Bai, S.: Seqformer: a frustratingly simple model for video instance segmentation. arXiv preprint arXiv:2112.08275 (2021)
-
[42]
In: ECCV (2022)
Wu, J., Liu, Q., Jiang, Y ., Bai, S., Yuille, A., Bai, X.: In defense of online models for video instance segmentation. In: ECCV (2022)
2022
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Yang, L., Fan, Y ., Xu, N.: Video instance segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[44]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Yang, S., Fang, Y ., Wang, X., Li, Y ., Fang, C., Shan, Y ., Feng, B., Liu, W.: Crossover learning for fast online video instance segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8043–8052 (October 2021)
2021
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, S., Wang, X., Li, Y ., Fang, Y ., Fang, J., Liu, W., Zhao, X., Shan, Y .: Temporally efficient vision transformer for video instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2885–2895 (2022)
2022
-
[46]
Advances in Neural Information Processing Systems35, 36324–36336 (2022)
Yang, Z., Yang, Y .: Decoupling features in hierarchical propagation for video object segmenta- tion. Advances in Neural Information Processing Systems35, 36324–36336 (2022)
2022
-
[47]
Ying, K., Zhong, Q., Mao, W., Wang, Z., Chen, H., Wu, L.Y ., Liu, Y ., Fan, C., Zhuge, Y ., Shen, C.: CTVIS: Consistent Training for Online Video Instance Segmentation (2023)
2023
-
[48]
arXiv preprint arXiv:2211.09108 (2022)
Zhan, Z., McKee, D., Lazebnik, S.: Robust online video instance segmentation with track queries. arXiv preprint arXiv:2211.09108 (2022)
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhang, T., Tian, X., Wu, Y ., Ji, S., Wang, X., Zhang, Y ., Wan, P.: Dvis: Decoupled video instance segmentation framework. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1282–1291 (October 2023)
2023
-
[50]
In: MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, South Korea, January 5–8, 2020, Proceedings, Part I 26
Zhang, X., Han, G., He, W.: Unsupervised feature propagation for fast video object detection using generative adversarial networks. In: MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, South Korea, January 5–8, 2020, Proceedings, Part I 26. pp. 617–627. Springer (2020)
2020
-
[51]
In: International Conference on Learning Representations (2021),https://openreview.net/forum?id=gZ9hCDWe6ke 12
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable {detr}: Deformable transformers for end-to-end object detection. In: International Conference on Learning Representations (2021),https://openreview.net/forum?id=gZ9hCDWe6ke 12
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.