PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
Pith reviewed 2026-06-29 03:51 UTC · model grok-4.3
The pith
PerceptionRubrics uses gated scoring on atomic rubrics to align multimodal evaluation more closely with human perception than conventional benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
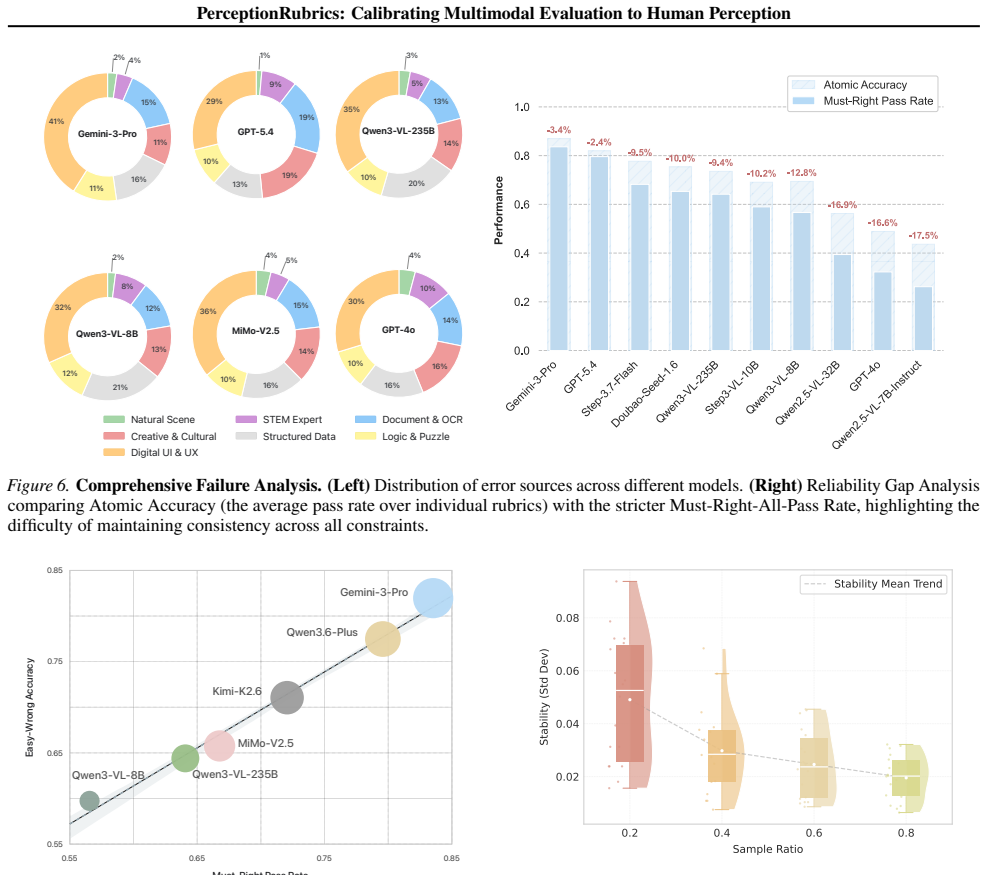
PerceptionRubrics shows that models frequently succeed on fragmented elements but fail strict conjunctive constraints, that an 8 percent perception gap persists between open-source and proprietary systems, and that gated metrics achieve stronger human alignment by treating strict perceptual fidelity as a prerequisite for reliable generation.
What carries the argument
The Gated Scoring mechanism, which imposes binary penalties on failures in Must-Right rubrics while allowing separate assessment of Easy-Wrong details.
If this is right
- Models must satisfy every essential visual fact to receive high scores rather than compensating through partial credit.
- A consistent perception deficit of roughly 8 percent separates open-source models from proprietary ones even on dense scenes.
- Reliable generation requires strict perceptual fidelity as a foundation rather than relying on average-case semantic overlap.
Where Pith is reading between the lines
- Training pipelines could incorporate similar conjunctive constraints as auxiliary losses to reduce brittleness on complex images.
- The same gating structure might transfer to video or 3D evaluation where temporal or spatial conjunctions matter.
- Benchmark designers in other modalities could test whether replacing linear averages with mandatory-fact gates improves correlation with human preference data.
Load-bearing premise
The rubrics produced by the circular peer-review pipeline on golden captions accurately capture human perception without systematic bias.
What would settle it
A controlled study in which human raters assign substantially different overall quality rankings to model outputs than the gated rubric scores would falsify the claim of superior alignment.
Figures



read the original abstract
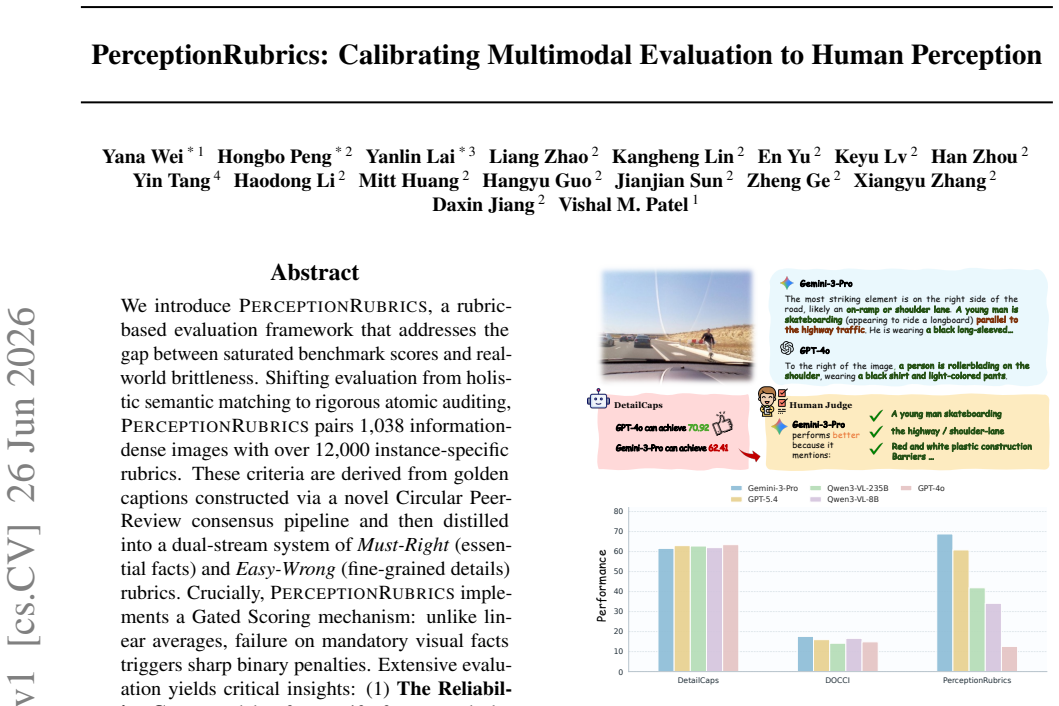
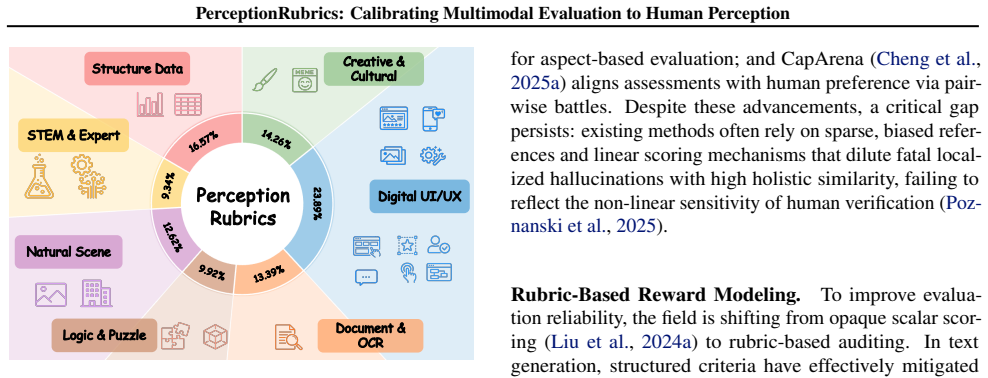
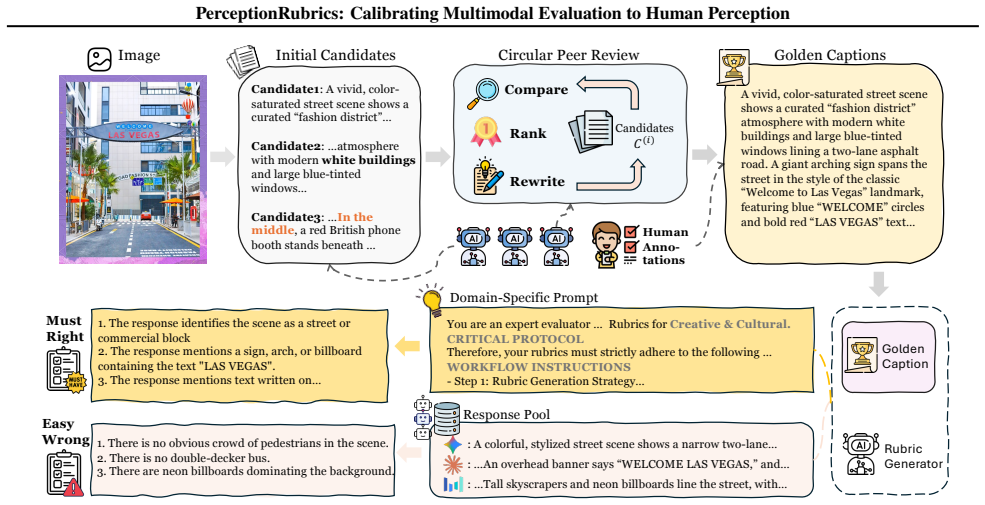
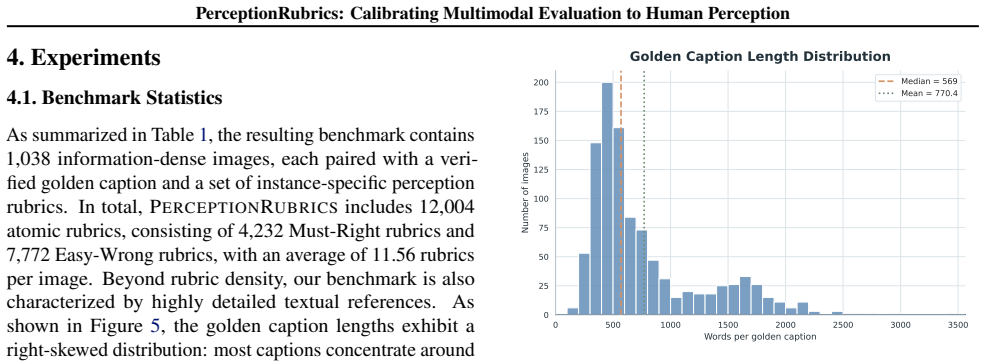
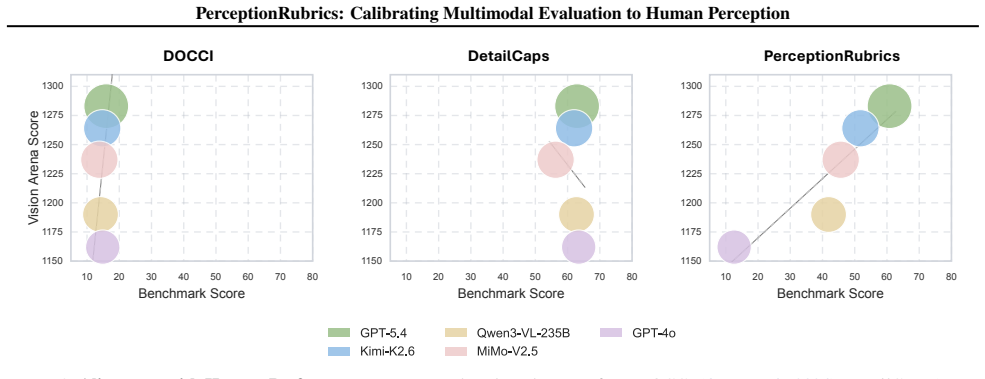
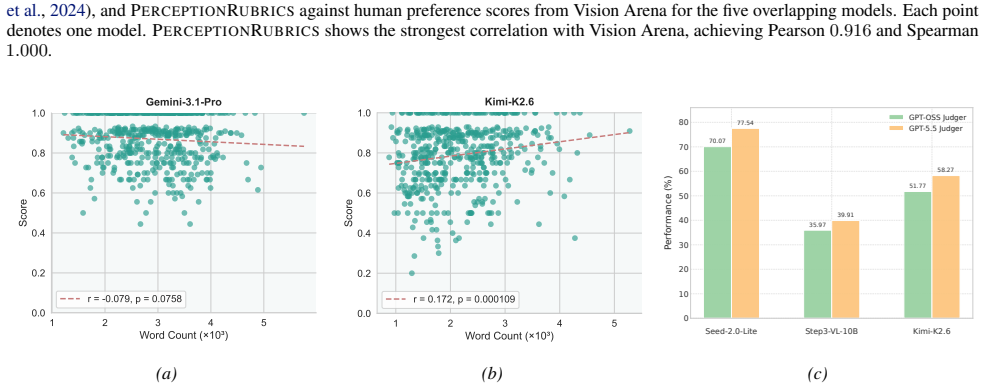
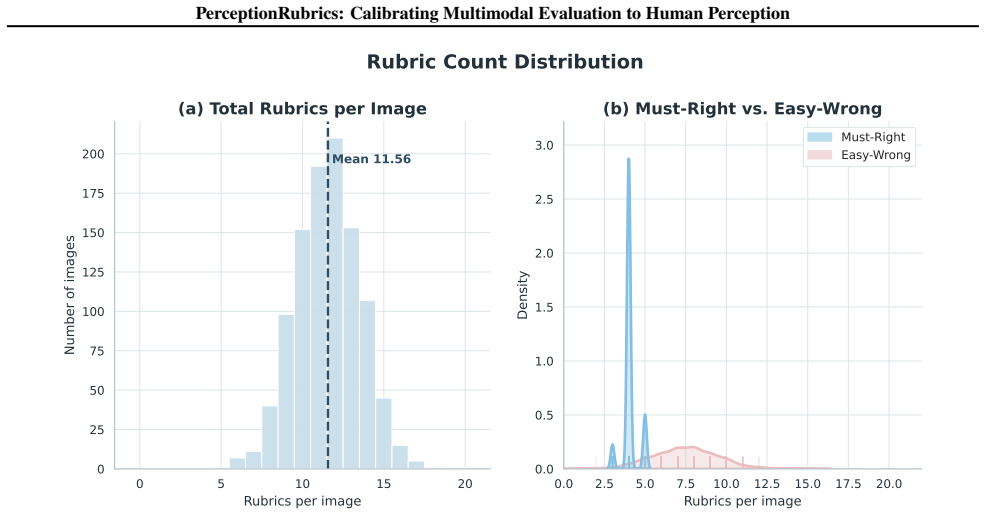
We introduce PerceptionRubrics, a rubric-based evaluation framework that addresses the gap between saturated benchmark scores and real-world brittleness. Shifting evaluation from holistic semantic matching to rigorous atomic auditing, PerceptionRubrics pairs 1,038 information-dense images with over 12,000 instance-specific rubrics. These criteria are derived from golden captions constructed via a novel Circular Peer-Review consensus pipeline and then distilled into a dual-stream system of Must-Right (essential facts) and Easy-Wrong (fine-grained details) rubrics. Crucially, PerceptionRubrics implements a Gated Scoring mechanism: unlike linear averages, failure on mandatory visual facts triggers sharp binary penalties. Extensive evaluation yields critical insights: (1) The Reliability Gap: models often verify fragmented elements correctly yet fail strict conjunctive constraints, exposing brittleness in dense domains; (2) Open-Closed Stratification: contrary to reasoning trends, we reveal a persistent 8% perception deficit between open-source and proprietary frontiers; and (3) Human-Aligned Rigor: our gated metrics substantially out-align conventional benchmarks, validating that strict perceptual fidelity is the prerequisite for reliable generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PerceptionRubrics, a rubric-based evaluation framework for multimodal models that shifts from holistic semantic matching to atomic auditing. It pairs 1,038 information-dense images with over 12,000 instance-specific rubrics derived from golden captions via a novel Circular Peer-Review consensus pipeline; these are distilled into Must-Right (essential facts) and Easy-Wrong (fine-grained details) criteria. The framework uses a Gated Scoring mechanism that applies sharp binary penalties on failure of mandatory visual facts. The authors report three main findings: a reliability gap where models succeed on fragments but fail conjunctive constraints; a persistent 8% perception deficit between open-source and proprietary models; and superior human alignment of the gated metrics relative to conventional benchmarks, validating strict perceptual fidelity as a prerequisite for reliable generation.
Significance. If the results hold after proper validation, the work could meaningfully advance multimodal evaluation by exposing brittleness hidden by saturated benchmarks and by supplying a more perceptually grounded alternative that emphasizes conjunctive constraints over linear averages.
major comments (2)
- [Abstract] Abstract: the abstract asserts strong conclusions on an 8% open-closed deficit, reliability gaps, and superior human alignment of gated metrics, yet supplies no experimental details, statistical tests, model lists, or validation of the consensus pipeline, leaving the central claims unsupported in the available text.
- [Methods (Circular Peer-Review consensus pipeline)] Circular Peer-Review consensus pipeline (methods description): the pipeline for constructing golden captions is presented as model-driven and iterative; without an explicit independent human validation step that directly compares the resulting Must-Right/Easy-Wrong rubrics against fresh human perceptual judgments on the 1,038 images, the reported human-alignment advantage risks circular reinforcement and cannot be treated as independent evidence.
minor comments (1)
- [Abstract] The abstract refers to 'extensive evaluation' and 'conventional benchmarks' without naming the specific models, datasets, or baseline metrics used for the alignment comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts strong conclusions on an 8% open-closed deficit, reliability gaps, and superior human alignment of gated metrics, yet supplies no experimental details, statistical tests, model lists, or validation of the consensus pipeline, leaving the central claims unsupported in the available text.
Authors: The abstract is intended as a concise summary of the key contributions and findings. The experimental details, including model lists, statistical tests, and validation of the consensus pipeline, are fully described in the Methods and Results sections of the manuscript. To strengthen the abstract and better support the claims within it, we will revise the abstract to include brief references to the evaluation scale, the models evaluated, and the nature of the statistical validation. revision: yes
-
Referee: [Methods (Circular Peer-Review consensus pipeline)] Circular Peer-Review consensus pipeline (methods description): the pipeline for constructing golden captions is presented as model-driven and iterative; without an explicit independent human validation step that directly compares the resulting Must-Right/Easy-Wrong rubrics against fresh human perceptual judgments on the 1,038 images, the reported human-alignment advantage risks circular reinforcement and cannot be treated as independent evidence.
Authors: We acknowledge the importance of ensuring the human-alignment validation is independent of the model-driven pipeline. The Circular Peer-Review is used for scalable rubric generation, but the human alignment is assessed via separate experiments involving human judges. To mitigate any perception of circularity, we will revise the Methods section to explicitly detail the independent human validation steps used to verify the rubrics against fresh human perceptual judgments. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PerceptionRubrics as a new framework with rubrics derived from golden captions via a described Circular Peer-Review consensus pipeline. No equations, fitted parameters, or self-citations are shown reducing the central claims (gated metrics out-aligning benchmarks, or perceptual fidelity as prerequisite) to inputs by construction. The pipeline is presented as a novel method for creating evaluation criteria, with the alignment claims resting on the resulting rubrics rather than any self-referential loop or renamed known result. The derivation remains self-contained against external benchmarks as no load-bearing step collapses to a fit or prior author work by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human perception of dense visual scenes can be faithfully represented by instance-specific Must-Right and Easy-Wrong rubrics derived from consensus captions.
Reference graph
Works this paper leans on
-
[1]
Springer, 2024. OpenAI. Hello gpt-4o, 2024. URL https://openai. com/index/hello-gpt-4o/. OpenAI. Introducing gpt-5.2, 2025a. URL https://openai.com/index/ introducing-gpt-5-2/. OpenAI. Gpt-oss-120b and gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025b. URL https:// arxiv.org/abs/2508.10925. OpenAI. Introducing GPT-5.4, 2026a. URL https://opena...
Pith/arXiv arXiv 2024
-
[2]
You must evaluate the **density** and **semantic depth ** of the text
**Do NOT ** give a high score simply because the image contains text. You must evaluate the **density** and **semantic depth ** of the text. 13 PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
-
[3]
**Severely penalize ** low-quality images: images that are blurry, noisy, contain scribbled handwriting, or have excessive empty backgrounds should receive low scores
-
[4]
Please score based on the following strict standards (1-10 points):
If the majority of the image is white space or a single background, the score must be determined by the richness of the subject content, not by the image dimensions. Please score based on the following strict standards (1-10 points):
-
[5]
- **1-3 Points (Low) **: Minimalist composition, massive white space, simple handwriting, single isolated objects, blurry snapshots, low-resolution screenshots
Visual Complexity: - Definition: The quantity of independent visual elements (objects, lines, textures), spatial occupancy, and clarity of details within the image. - **1-3 Points (Low) **: Minimalist composition, massive white space, simple handwriting, single isolated objects, blurry snapshots, low-resolution screenshots. - **4-7 Points (Medium) **: Cle...
-
[6]
a red apple
Informativeness: - Definition: The amount of information when the image is translated into a text description, the richness of context, and its knowledge value. - **1-3 Points (Low) **: Simple mathematical formulas, single words/numbers, scribbles without context, illegible content, generic decorative patterns, extremely low information entropy. - **4-7 P...
-
[7]
**Undeniable Visibility: ** Only select elements that are clearly visible and prominent in the image
-
[8]
Ignore background clutter or minor details
**Essentiality:** Only select elements that are critical to the image’s core meaning. Ignore background clutter or minor details
-
[9]
car" instead of
**Verifiability:** Each rubric must be a binary (Pass/Fail) check. ### WORKFLOW INSTRUCTIONS **Step 1: Rubric Generation Strategy (Semantic Generalization) ** Apply the following abstract rules to ensure the rubrics are robust to varying levels of descriptive detail: * ** Entity Abstraction: ** Identify the fundamental semantic category of the dominant ob...
-
[10]
**Undeniable Visibility: ** Only select elements that are clearly visible and prominent
-
[11]
Submit" button,
**Functional Criticality: ** Only select elements that are essential for operating or navigating the interface (e.g., "Submit" button, "Back" arrow). Ignore decorative banners or ads
-
[12]
The response identifies the magnifying glass as a ’Search’ button/feature
**Verifiability:** Each rubric must be a binary (Pass/Fail) check. ### WORKFLOW INSTRUCTIONS **Step 1: Rubric Generation Strategy (Interaction & Structure) ** Apply the following abstract rules to ensure the rubrics cover the interface’s functionality: * ** Functional Semantics: ** Identify interactive elements by their function, not just their shape. Map...
-
[13]
**Ground Truth Caption (GT): ** A factual, accurate description of the image
-
[14]
These responses may contain hallucinations, perceptual errors, or correct details
**Model Response Pool: ** A collection of captions generated by various VLMs. These responses may contain hallucinations, perceptual errors, or correct details . Your goal is to identify **common or severe perceptual errors ** in the ‘Response Pool‘ by comparing them against the ‘Ground Truth‘, and then formulate strict criteria to penalize these errors. ...
-
[15]
Focus on: * ** Hallucinations:** Objects mentioned in responses but not present in the GT
**Analyze Errors: ** Scan the ‘Model Response Pool‘ to find discrepancies against the ‘Ground Truth‘. Focus on: * ** Hallucinations:** Objects mentioned in responses but not present in the GT . 17 PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception * ** Attribute Errors: ** Wrong colors, shapes, materials, or textures. * ** Counting/Q...
-
[16]
red helmet
**Filter for Perception (Crucial): ** * ** INCLUDE:** Visual perception issues (e.g., calling a "red helmet" a "blue helmet"; seeing "3 people" instead of "4"; reading "STOP" as "SHOP"). * ** EXCLUDE:** Knowledge gaps or Entity linking issues. If the model fails to recognize a specific character (e.g., "Genshin Impact character") but correctly describes t...
-
[17]
The response must NOT
**Formulate Rubrics: ** * Convert the identified high-frequency or severe errors into **Binary Checklists**. * If models frequently hallucinate an object, create a **Negative Constraint ** (e.g., "The response must NOT..."). * If models get an attribute wrong, create a **Positive Constraint ** (e.g., " The response must identify..."). ### Rubric Style Gui...
-
[18]
{response_1} 18 PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
-
[19]
Expert Visual Truth Adjudicator
{response_8} Please generate the perception rubrics based on the analysis of the responses above. C.3. Panel of Judges Prompt To ensure the objectivity and correctness of the generated rubrics, a panel of models (Gemini-3-Pro (Team, 2025) , GPT-5.2 (OpenAI, 2025a) , Seed-1.8 (ByteDance-Seed, 2026b) ) performs a cross-verification using the following promp...
2025
-
[20]
**Factuality:** Are there hallucinations? (e.g., objects, colors, or text that don’t exist)
-
[21]
**Spatial Precision: ** Are positional relationships (left, right, above, behind) accurate?
-
[22]
**Attribute Accuracy: ** Are textures, materials, lighting, and colors correctly identified?
-
[23]
**Detail Density: ** Does the caption capture nuanced elements without being redundant? **Task Workflow: **
-
[24]
**Independent Verification: ** Analyze the image first, then audit each Candidate (1, 2, and 3) individually
-
[25]
Inspect the image to resolve these
**Conflict Resolution: ** Identify discrepancies between candidates (e.g., Candidate 1 says ’vintage’, Candidate 2 says ’modern’). Inspect the image to resolve these
-
[26]
**Ranking:** Select the "Best" baseline based on the highest fidelity to the visual evidence. **Input Candidates: ** [Candidate 1]: {candidate_1_text} [Candidate 2]: {candidate_2_text} [Candidate 3]: {candidate_3_text} **Strict Output Format: ** You must output your response in valid XML format only. No preamble, no markdown formatting outside the XML, an...
-
[27]
**Model Caption: ** The text description generated by the model
-
[28]
bottom-line
**Group A (Critical Rubrics): ** A list of fundamental perception criteria. These are "bottom-line" facts
-
[29]
### Judgment Logic For each rubric in both groups, determine if the **Model Caption ** complies with the requirement
**Group B (Granular Rubrics): ** A list of fine-grained or high-frequency error checks. ### Judgment Logic For each rubric in both groups, determine if the **Model Caption ** complies with the requirement. * ** True (Pass): ** The caption explicitly meets the criteria or implies it without ambiguity. * ** False (Fail): ** The caption contradicts the crite...
-
[30]
Must identify the car as red
**Positive Constraints ** (e.g., "Must identify the car as red"): * Pass: "A red car is parked..." * Fail: "A blue car..." (Contradiction) OR "A car is parked..." (Missing specific detail)
-
[31]
Must NOT mention a dog
**Negative Constraints ** (e.g., "Must NOT mention a dog"): * Pass: "A cat sits on the mat." (No dog mentioned). * Fail: "A dog and a cat..." (Hallucination detected). ### Crucial Requirement You must evaluate **Group A ** and **Group B ** independently and return the results in separate lists. The order of boolean results in the output must strictly matc...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.