How Many Trees in a Random Forest? A Revisited Approach with Plateau Search and Optuna Integration
Pith reviewed 2026-06-28 11:08 UTC · model grok-4.3
The pith
A triplet-based search finds near-minimal tree counts for random forests by tracking relative OOB changes without fixing a search range.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
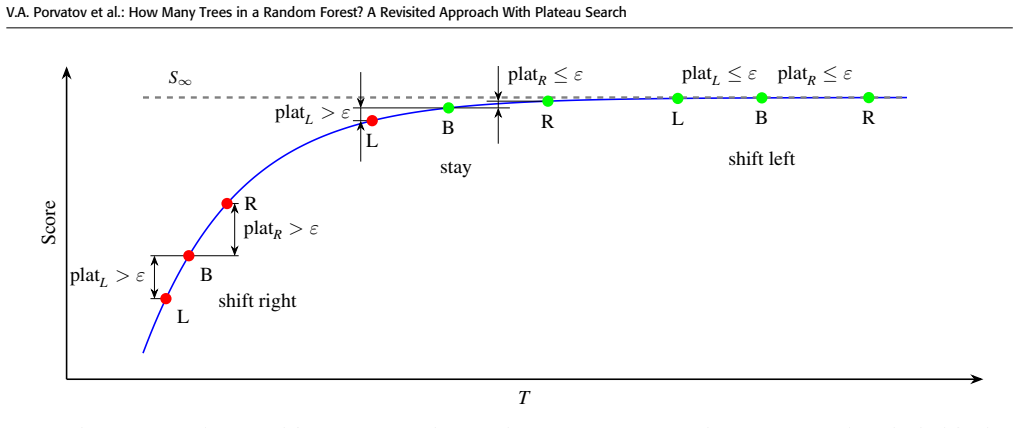
The triplet-based plateau-search algorithm removes the number of trees from the direct TPE search space and adaptively tracks a near-minimal sufficient ensemble size by monitoring relative changes in the out-of-bag score across a triplet of forest sizes and shifting this triplet accordingly, yielding an automated procedure based on a tolerance parameter. The relative OOB-score criterion is related to the gap between the current and limiting scores, with a derived asymptotic variance estimate for the OOB-based absolute relative difference.
What carries the argument
The triplet-based plateau-search algorithm that shifts a triplet of forest sizes based on relative out-of-bag score changes controlled by a tolerance parameter.
If this is right
- The number of trees is removed from the direct TPE search space while still using information accumulated across HPO trials.
- The procedure is automated and user-interpretable based on a single tolerance parameter.
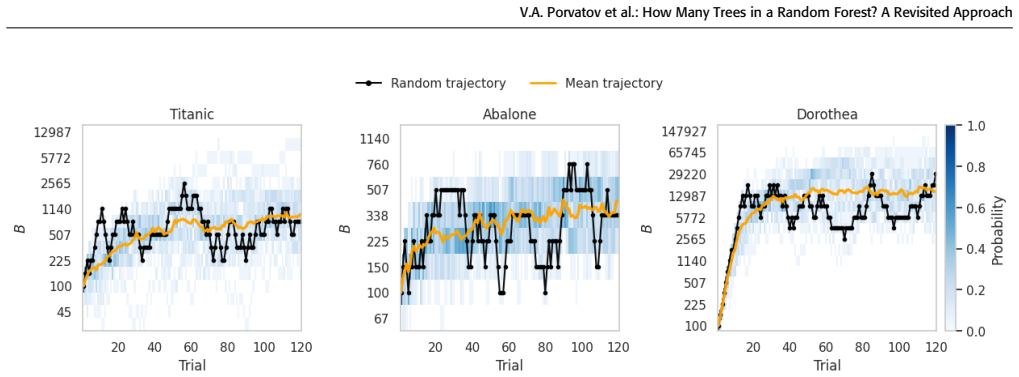
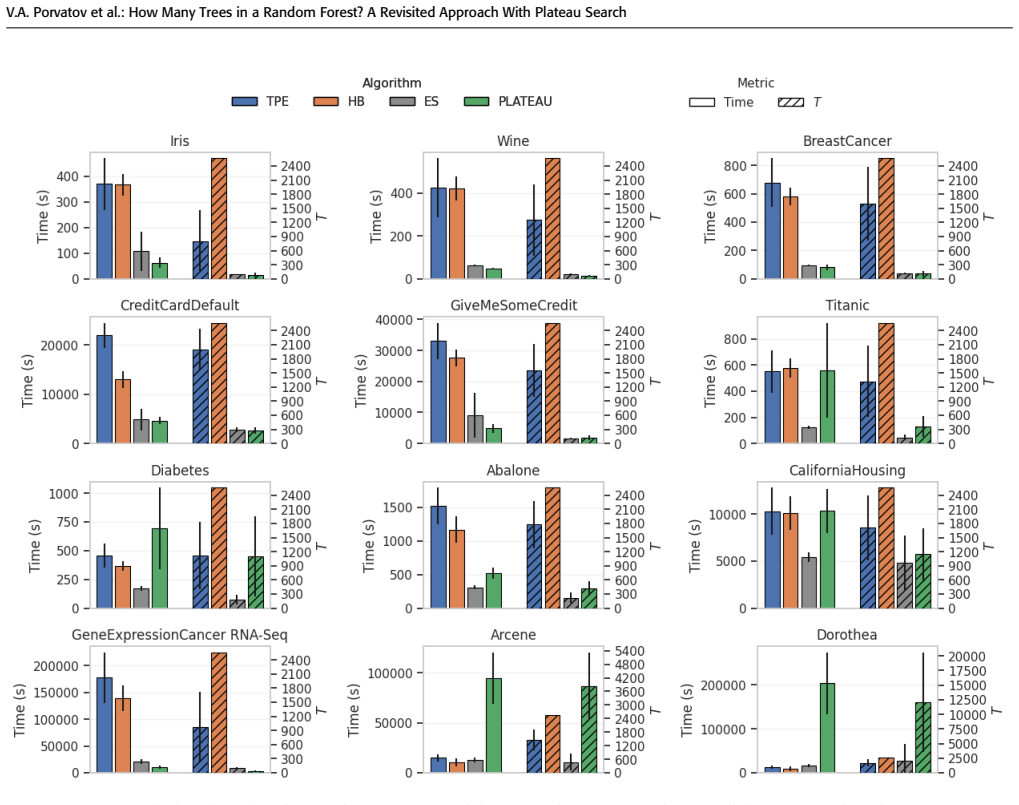
- The selected number of trees differs substantially from the common heuristic, being smaller for most classical benchmark datasets and larger for some high-dimensional bioinformatics datasets.
- The relative OOB-score criterion relates directly to the gap from the limiting score with a derived asymptotic variance estimate.
Where Pith is reading between the lines
- The method could extend to other ensemble models where performance improves monotonically with size.
- It may lower overall computation in hyperparameter optimization by avoiding evaluation of unnecessarily large forests.
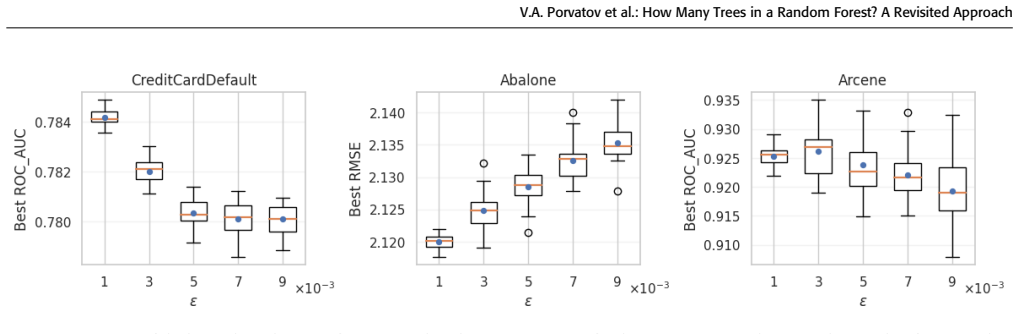
- The tolerance parameter offers a direct way to trade off between ensemble size and expected performance gain.
- Integration with existing HPO libraries makes the approach immediately usable without new search-space definitions.
Load-bearing premise
Relative changes in the out-of-bag score across a moving triplet of forest sizes provide a reliable signal for detecting the plateau without being unduly affected by score noise.
What would settle it
On a dataset where the true out-of-bag score continues to improve substantially past the size chosen by the algorithm, showing the detected plateau was not yet reached.
Figures
read the original abstract
Hyperparameter optimization (HPO) for Random Forest faces a specific difficulty in tuning the number of trees: the predictive score typically improves monotonically with ensemble size, so standard methods such as Tree-structured Parzen Estimator (TPE) and Hyperband require a predefined search range and often drive the estimate toward its right boundary. Early-stopping strategies avoid fixing such a range, but can be sensitive to score noise and prone to premature stopping. To address this, we propose an integrated triplet-based plateau-search algorithm that removes the number of trees from the direct TPE search space and still exploits information accumulated across HPO trials. The method adaptively tracks a near-minimal sufficient ensemble size by monitoring relative changes in the out-of-bag (OOB) score across a triplet of forest sizes and shifting this triplet accordingly. This yields an automated and user-interpretable procedure based on a tolerance parameter. We also provide a theoretical analysis: we relate the proposed relative OOB-score criterion to the gap between the current and limiting scores, and derive an asymptotic variance estimate for the corresponding OOB-based absolute relative difference. Experiments show that the selected number of trees can differ substantially from the common heuristic: for most classical benchmark datasets it is smaller, whereas for some high-dimensional bioinformatics datasets, such as Arcene and Dorothea, it is larger. The source code and reproducible experiments are available at https://github.com/lange-am/rf_plateau_hpo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an integrated triplet-based plateau-search algorithm for determining the number of trees (n_trees) during TPE-based hyperparameter optimization of Random Forests. By monitoring relative changes in out-of-bag (OOB) scores across a moving triplet of forest sizes and shifting the window accordingly, the method removes n_trees from the direct TPE search space while adaptively identifying a near-minimal sufficient ensemble size based on a tolerance parameter. It includes a theoretical analysis relating the relative OOB criterion to the gap versus the limiting score plus an asymptotic variance estimate for the absolute relative difference, and reports experiments on classical benchmarks and high-dimensional bioinformatics datasets (e.g., Arcene, Dorothea) where the selected n_trees often differs from common heuristics. Reproducible code is provided.
Significance. If the central claim holds, the work offers a practical, automated alternative to fixed-range or early-stopping strategies for ensemble size in RF HPO, with potential for more efficient models. The reproducible experiments and code are a clear strength. The theoretical connection between the triplet criterion and the score gap is a positive contribution if the derivations are complete and the finite-sample behavior is addressed.
major comments (2)
- [§3] §3 (theoretical analysis): the derivation relates the proposed relative OOB criterion directly to the limiting score gap using the method's own definitions and supplies an asymptotic variance for the absolute relative difference, but does not address finite-sample OOB variance (e.g., small n, high-dimensional data, or early stopping within forests). This leaves the reliability of the triplet rule under realistic noise unproven, which is load-bearing for the claim that the procedure is automated and reliable without post-hoc adjustments.
- [§4] §4 (algorithm description) and experiments: the triplet rule is presented as detecting the plateau via relative OOB changes with a tolerance parameter, yet no analysis or ablation shows behavior when noise exceeds the tolerance (as flagged by the weakest assumption). If the moving triplet can stop prematurely or continue expanding, the central claim that it yields a near-minimal sufficient size is undermined; a concrete finite-sample bound or simulation under OOB variance would be needed.
minor comments (2)
- [§5] The abstract and §5 mention that selected n_trees differs substantially from heuristics on most datasets but is larger on Arcene/Dorothea; adding a table with exact values, tolerance settings, and variance across runs would improve clarity.
- Notation for the triplet window and relative difference should be defined once with consistent symbols (e.g., avoid re-using OOB without subscript) to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the reproducibility of the code as well as the potential practical value of the approach. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the derivation relates the proposed relative OOB criterion directly to the limiting score gap using the method's own definitions and supplies an asymptotic variance for the absolute relative difference, but does not address finite-sample OOB variance (e.g., small n, high-dimensional data, or early stopping within forests). This leaves the reliability of the triplet rule under realistic noise unproven, which is load-bearing for the claim that the procedure is automated and reliable without post-hoc adjustments.
Authors: We thank the referee for this observation. The analysis in §3 indeed establishes the connection to the limiting score gap and supplies the asymptotic variance of the absolute relative difference, but does not derive finite-sample bounds or explicitly characterize behavior under the OOB variance encountered with small n or high-dimensional data. We agree this is a limitation for the reliability claim. In the revised manuscript we will expand §3 with a dedicated paragraph acknowledging the asymptotic nature of the results and add a short simulation study that injects realistic OOB noise levels to illustrate the triplet rule's sensitivity. revision: yes
-
Referee: [§4] §4 (algorithm description) and experiments: the triplet rule is presented as detecting the plateau via relative OOB changes with a tolerance parameter, yet no analysis or ablation shows behavior when noise exceeds the tolerance (as flagged by the weakest assumption). If the moving triplet can stop prematurely or continue expanding, the central claim that it yields a near-minimal sufficient size is undermined; a concrete finite-sample bound or simulation under OOB variance would be needed.
Authors: We agree that the current version contains no controlled ablation or simulation examining the triplet rule when OOB noise exceeds the tolerance. The reported experiments cover a range of datasets but do not isolate this failure mode. We will revise §4 and the experimental section to include an ablation study that varies noise amplitude and tolerance, documenting cases of premature stopping or continued expansion, together with practical guidance on tolerance selection based on the observed OOB variance. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines a new triplet-based plateau-search procedure that monitors relative OOB-score changes to select n_trees outside the TPE space, then derives an asymptotic variance for its own absolute-relative-difference statistic and relates the criterion to the limiting score gap. These steps follow directly from the algorithm's definitions and standard OOB properties without reducing any claimed result to a fitted input, self-citation chain, or ansatz smuggled from prior work. Experiments on external benchmarks provide independent validation. No load-bearing step collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- tolerance parameter
axioms (1)
- domain assumption Out-of-bag scores improve monotonically with increasing ensemble size up to an asymptotic limit.
Reference graph
Works this paper leans on
-
[1]
Breiman, ‘‘Bagging predictors,’’Machine Learning, vol
L. Breiman, ‘‘Bagging predictors,’’Machine Learning, vol. 24, no. 2, pp. 123–140, 1996
1996
-
[2]
——, ‘‘Random forests,’’Machine Learning, vol. 45, no. 1, pp. 5–32, 2001
2001
-
[3]
Breiman and A
L. Breiman and A. Cutler,Manual—Setting up, using, and understanding random forests V4.0, 2003, [Online]. Available: https://www.stat.berkeley.edu/ breiman/Using_random_forests_v4.0.pdf. Accessed on: Jun. 19, 2026. [Online]. Available: https://www.stat.berkele y.edu/~breiman/Using_random_forests_v4.0.pdf
2003
-
[4]
Biau and E
G. Biau and E. Scornet, ‘‘A random forest guided tour,’’TEST, vol. 25, no. 2, pp. 197–227, Jun. 2016
2016
-
[5]
R. E. Schapire, ‘‘A brief introduction to boosting,’’ inProceedings of the Sixteenth International Joint Conference on Artificial Intelligence. Morgan Kaufmann, 1999, pp. 1401–1406. [Online]. Available: https: //www.ijcai.org/Proceedings/99-2/Papers/103.pdf
1999
-
[6]
J. H. Friedman, ‘‘Greedy function approximation: A gradient boosting machine,’’The Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001
2001
-
[7]
——, ‘‘Stochastic gradient boosting,’’Computational Statistics & Data Analysis, vol. 38, no. 4, pp. 367–378, 2002
2002
-
[8]
Borisov, T
V . Borisov, T. Leemann, K. Seßler, J. Haug, M. Pawelczyk, and G. Kasneci, ‘‘Deep neural networks and tabular data: A survey,’’IEEE Transactions on 21 V.A. Porvatov et al.: How Many Trees in a Random Forest? A Revisited Approach Neural Networks and Learning Systems, vol. 35, no. 6, pp. 7499–7519, 2024
2024
-
[9]
Grinsztajn, E
L. Grinsztajn, E. Oyallon, and G. V aroquaux, ‘‘Why do tree-based models still outperform deep learning on typical tabular data?’’ inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 507–520. [Online]. Available: https://proceedings.neurips.cc/p aper_files/paper/2022/file/0378c7692da36807bdec87ab043cdadc-Paper ...
2022
-
[10]
Shwartz-Ziv and A
R. Shwartz-Ziv and A. Armon, ‘‘Tabular data: Deep learning is not all you need,’’Information Fusion, vol. 81, pp. 84–90, 2022
2022
-
[11]
Chen and C
T. Chen and C. Guestrin, ‘‘Xgboost: A scalable tree boosting system,’’ inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016, pp. 785–794
2016
-
[12]
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Y e, and T.-Y . Liu, ‘‘Lightgbm: A highly efficient gradient boosting decision tree,’’Advances in Neural Information Processing Systems, vol. 30, pp. 3146–3154, 2017. [Online]. Available: https://proceedings.neurips.cc/paper/2017/file/6449 f44a102fde848669bdd9eb6b76fa-Paper.pdf
2017
-
[13]
Prokhorenkova, G
L. Prokhorenkova, G. Gusev, A. V orobev, A. V . Dorogush, and A. Gulin, ‘‘Catboost: unbiased boosting with categorical features,’’ inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neu...
2018
-
[14]
Fernández-Delgado, E
M. Fernández-Delgado, E. Cernadas, S. Barro, and D. Amorim, ‘‘Do we need hundreds of classifiers to solve real world classification problems?’’ Journal of Machine Learning Research, vol. 15, no. 90, pp. 3133–3181,
-
[15]
Available: http://jmlr.org/papers/v15/delgado14a.html
[Online]. Available: http://jmlr.org/papers/v15/delgado14a.html
-
[16]
Kelly, R
M. Kelly, R. Longjohn, and K. Nottingham, ‘‘UCI machine learning repository,’’ University of California, Irvine, 2023, [Online]. Available: https://archive.ics.uci.edu. Accessed on: Jun. 19, 2026
2023
-
[17]
Pedregosa, G
F. Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. Weiss, V . Dubourg, J. V anderplas, A. Pas- sos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, ‘‘Scikit- learn: Machine learning in Python,’’Journal of Machine Learning Re- search, vol. 12, pp. 2825–2830, 2011
2011
-
[18]
Liaw and M
A. Liaw and M. Wiener, ‘‘Classification and regression by randomforest,’’ R News, vol. 2, no. 3, pp. 18–22, 2002. [Online]. Available: https: //CRAN.R-project.org/doc/Rnews/
2002
-
[19]
Hothorn, K
T. Hothorn, K. Hornik, and A. Zeileis, ‘‘Unbiased recursive partitioning: A conditional inference framework,’’Journal of Computational and Graphi- cal Statistics, vol. 15, no. 3, pp. 651–674, 2006
2006
-
[20]
Hothorn and A
T. Hothorn and A. Zeileis, ‘‘partykit: A modular toolkit for recursive partytioning in r,’’Journal of Machine Learning Research, vol. 16, no. 118, pp. 3905–3909, 2015. [Online]. Available: http://jmlr.org/papers/v1 6/hothorn15a.html
2015
-
[21]
M. N. Wright and A. Ziegler, ‘‘ranger: A fast implementation of random forests for high dimensional data in c++ and r,’’Journal of Statistical Software, vol. 77, no. 1, p. 1–17, 2017. [Online]. Available: https://www.jstatsoft.org/index.php/jss/article/view/v077i01
2017
-
[22]
P . Probst, M. Wright, and A.-L. Boulesteix, ‘‘Hyperparameters and tuning strategies for random forest,’’ArXiv preprint arXiv:1804.03515, 2018. [Online]. Available: https://arxiv.org/abs/1804.03515
Pith/arXiv arXiv 2018
-
[23]
P . Probst, M. N. Wright, and A.-L. Boulesteix, ‘‘Hyperparameters and tuning strategies for random forest,’’WIREs Data Mining and Knowledge Discovery, vol. 9, no. 3, p. e1301, 2019. [Online]. Available: https://wires.onlinelibrary.wiley.com/doi/abs/10.1002/widm.1301
-
[24]
T. M. Lange, M. Gültas, A. O. Schmitt, and F. Heinrich, ‘‘optrf: Optimising random forest stability by determining the optimal number of trees,’’ BMC Bioinformatics, vol. 26, no. 1, p. 95, Mar 2025. [Online]. Available: https://doi.org/10.1186/s12859-025-06097-1
-
[25]
Díaz-Uriarte and S
R. Díaz-Uriarte and S. A. de Andrés, ‘‘Gene selection and classification of microarray data using random forest,’’BMC Bioinformatics, vol. 7, p. 3, 2006
2006
-
[26]
B. A. Goldstein, A. E. Hubbard, A. Cutler, and L. F. Barcellos, ‘‘An ap- plication of random forests to a genome-wide association dataset: Method- ological considerations & new findings,’’BMC Genetics, vol. 11, p. 49, 2010
2010
-
[27]
B. A. Goldstein, E. C. Polley, and F. B. S. Briggs, ‘‘Random forests for genetic association studies,’’Statistical Applications in Genetics and Molecular Biology, vol. 10, no. 1, p. 32, 2011
2011
-
[28]
Janitza, E
S. Janitza, E. Celik, and A.-L. Boulesteix, ‘‘A computationally fast variable importance test for random forests for high-dimensional data,’’Advances in Data Analysis and Classification, vol. 12, no. 4, pp. 885–915, 2018
2018
-
[29]
Breiman, J
L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone,Classification and Regression Trees. Boca Raton: Chapman and Hall/CRC, 1984
1984
-
[30]
Louppe, ‘‘Understanding random forests: From theory to practice,’’
G. Louppe, ‘‘Understanding random forests: From theory to practice,’’
-
[31]
Available: https://arxiv.org/abs/1407.7502
[Online]. Available: https://arxiv.org/abs/1407.7502
-
[32]
Guyon, J
I. Guyon, J. Weston, S. Barnhill, and V . V apnik, ‘‘Gene selection for cancer classification using support vector machines,’’Machine Learning, vol. 46, no. 1-3, pp. 389–422, 2002
2002
-
[33]
M. B. Kursa and W. R. Rudnicki, ‘‘Feature selection with the Boruta package,’’Journal of Statistical Software, vol. 36, no. 11, p. 1–13, 2010. [Online]. Available: https://www.jstatsoft.org/index.php/jss/article/view/v 036i11
2010
-
[34]
Marbach, J
D. Marbach, J. C. Costello, R. Küffner, N. M. V ega, R. J. Prill, D. M. Camacho, K. R. Allison, M. Kellis, J. J. Collins, and G. Stolovitzky, ‘‘Wisdom of crowds for robust gene network inference,’’Nature Methods, vol. 9, no. 8, pp. 796–804, Aug. 2012
2012
-
[35]
V . A. Huynh-Thu, A. Irrthum, L. Wehenkel, and P . Geurts, ‘‘Inferring regulatory networks from expression data using tree-based methods,’’PLoS One, vol. 5, no. 9, p. e12776, 2010
2010
-
[36]
Tolosi and T
L. Tolosi and T. Lengauer, ‘‘Classification with correlated features: unre- liability of feature ranking and solutions,’’Bioinformatics, vol. 27, no. 14, pp. 1986–1994, Jul. 2011
1986
-
[37]
Strobl, A.-L
C. Strobl, A.-L. Boulesteix, A. Zeileis, and T. Hothorn, ‘‘Bias in random forest variable importance measures: Illustrations, sources and a solution,’’ BMC Bioinformatics, vol. 8, p. 25, 2007
2007
-
[38]
G. Hooker, L. Mentch, and S. Zhou, ‘‘Unrestricted permutation forces extrapolation: variable importance requires at least one more model, or there is no free variable importance,’’Statistics and Computing, vol. 31, no. 6, p. 82, Oct 2021. [Online]. Available: https://doi.org/10.1007/s112 22-021-10057-z
-
[39]
S. M. Lundberg and S.-I. Lee, ‘‘A unified approach to interpreting model predictions,’’ inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017, pp. 4768–4777. [Online]. Available: https://proceedings.neurips.cc/paper/2017/file/8a20a8621978 632d76c43dfd28b67767-Paper.pdf
2017
-
[40]
Covert, S
I. Covert, S. M. Lundberg, and S.-I. Lee, ‘‘Understanding global feature contributions with additive importance measures,’’ inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 17 212–17 223. [Online]. Available: https://proceedings.neurips.cc/p...
2020
-
[42]
Available: https://arxiv.org/abs/1802.03888
[Online]. Available: https://arxiv.org/abs/1802.03888
-
[43]
S. M. Lundberg, G. Erion, H. Chen, A. DeGrave, J. M. Prutkin, B. Nair, R. Katz, J. Himmelfarb, N. Bansal, and S.-I. Lee, ‘‘From local explanations to global understanding with explainable ai for trees,’’Nature Machine Intelligence, vol. 2, no. 1, pp. 56–67, 2020
2020
-
[44]
M. Sundararajan, A. Taly, and Q. Y an, ‘‘Axiomatic attribution for deep networks,’’Proceedings of the 34th International Conference on Machine Learning (ICML), vol. 70, pp. 3319–3328, 2017. [Online]. Available: https://arxiv.org/abs/1703.01365
Pith/arXiv arXiv 2017
-
[45]
A. Shrikumar, P . Greenside, and A. Kundaje, ‘‘Learning important features through propagating activation differences,’’ inInternational Conference on Machine Learning (ICML), vol. 70, 2017, pp. 3145–3153. [Online]. Available: https://arxiv.org/abs/1704.02685
arXiv 2017
-
[46]
Adebayo, J
J. Adebayo, J. Gilmer, M. Muelly, I. Goodfellow, M. Hardt, and B. Kim, ‘‘Sanity checks for saliency maps,’’ inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31, 2018, pp. 9505–9515. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/201 8/h...
2018
-
[47]
Ghorbani, A
A. Ghorbani, A. Abid, and J. Zou, ‘‘Interpretation of neural networks is fragile,’’ inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 3681–3688
2019
-
[48]
L. Sixt, M. Granz, and T. Landgraf, ‘‘When explanations lie: Why many modified BP attributions fail,’’ inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol
-
[49]
9046–9057
PMLR, 13–18 Jul 2020, pp. 9046–9057. [Online]. Available: https://proceedings.mlr.press/v119/sixt20a.html 22 V.A. Porvatov et al.: How Many Trees in a Random Forest? A Revisited Approach With Plateau Search
2020
-
[50]
Scornet, ‘‘On the asymptotics of random forests,’’Journal of Multivariate Analysis, vol
E. Scornet, ‘‘On the asymptotics of random forests,’’Journal of Multivariate Analysis, vol. 146, pp. 72–83, 2016, special Issue on Statistical Models and Methods for High or Infinite Dimensional Spaces. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0 047259X15001542
2016
-
[51]
Wager, T
S. Wager, T. Hastie, and B. Efron, ‘‘Confidence intervals for random forests: The jackknife and the infinitesimal jackknife,’’Journal of Machine Learning Research, vol. 15, no. 1, pp. 1625–1651, 2014. [Online]. Available: https://www.jmlr.org/papers/volume15/wager14a/wa ger14a.pdf
2014
-
[52]
Bergstra, R
J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl, ‘‘Algorithms for hyper-parameter optimization,’’ inAdvances in Neural Information Processing Systems, J. Shawe-Taylor, R. Zemel, P . Bartlett, F. Pereira, and K. Weinberger, Eds., vol. 24. Curran Associates, Inc., 2011, pp. 2546–2554. [Online]. Available: https://proceedings.neurips.cc/paper_fil es/paper/...
2011
-
[53]
T. M. Oshiro, P . S. Perez, and J. A. Baranauskas, ‘‘How many trees in a random forest?’’ inMachine Learning and Data Mining in Pattern Recognition. Springer Berlin Heidelberg, 2012, pp. 154–168
2012
-
[54]
T. Akiba, S. Sano, T. Y anase, T. Ohta, and M. Koyama, ‘‘Optuna: A next-generation hyperparameter optimization framework,’’ inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New Y ork, NY , USA: Association for Computing Machinery, 2019, p. 2623–2631. [Online]. Available: https://doi.org/10.1...
-
[55]
Strobl and A
C. Strobl and A. Zeileis, ‘‘Danger: High power! ? exploring the statistical properties of a test for random forest variable importance,’’ Ludwig-Maximilians-Universität München, Tech. Rep. 17, 2008. [Online]. Available: https://epub.ub.uni-muenchen.de/2111/
2008
-
[56]
Genuer, J.-M
R. Genuer, J.-M. Poggi, and C. Tuleau-Malot, ‘‘V ariable selection using random forests,’’Pattern Recognition Letters, vol. 31, no. 14, pp. 2225– 2236, 2010
2010
-
[57]
R. Genuer, J.-M. Poggi, and C. Tuleau, ‘‘Random forests: some methodological insights,’’ 2008. [Online]. Available: https://arxiv.org/abs/ 0811.3619
Pith/arXiv arXiv 2008
-
[58]
Cuzzocrea, S
A. Cuzzocrea, S. L. Francis, and M. M. Gaber, ‘‘An information-theoretic approach for setting the optimal number of decision trees in random forests,’’ in2013 IEEE International Conference on Systems, Man, and Cybernetics, 2013, pp. 1013–1019
2013
-
[59]
Probst and A.-L
P . Probst and A.-L. Boulesteix, ‘‘To tune or not to tune the number of trees in random forest,’’Journal of Machine Learning Research, vol. 18, no. 181, pp. 1–18, 2018. [Online]. Available: https://www.jmlr.org/papers/vo lume18/17-269/17-269.pdf
2018
-
[60]
Latinne, O
P . Latinne, O. Debeir, and C. Decaestecker, ‘‘Limiting the number of trees in random forests,’’ inMultiple Classifier Systems, J. Kittler and F. Roli, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2001, pp. 178–187
2001
-
[61]
Hernández-Lobato, G
D. Hernández-Lobato, G. Martínez-Muñoz, and A. Suárez, ‘‘How large should ensembles of classifiers be?’’Pattern Recognition, vol. 46, no. 5, pp. 1323–1336, 2013
2013
-
[62]
M. E. Lopes, ‘‘A sharp bound on the computation-accuracy trade- off for majority voting ensembles (version 2),’’ 2016, arXiv preprint arXiv:1303.0727v2
Pith/arXiv arXiv 2016
-
[63]
——, ‘‘Estimating the algorithmic variance of randomized ensembles via the bootstrap,’’The Annals of Statistics, vol. 47, no. 2, pp. 1088 – 1112,
-
[64]
Available: https://doi.org/10.1214/18-AOS1707
[Online]. Available: https://doi.org/10.1214/18-AOS1707
-
[65]
S. Arlot and R. Genuer, ‘‘Analysis of purely random forests bias,’’arXiv preprint arXiv:1407.3939, 2014
Pith/arXiv arXiv 2014
-
[66]
Demidova and M
L. Demidova and M. Ivkina, ‘‘Approach to determining the boundaries of the search range for the number of trees in the random forest algorithm,’’ in2020 9th Mediterranean Conference on Embedded Computing (MECO), 2020, pp. 1–4
2020
-
[67]
Bernard, L
S. Bernard, L. Heutte, and S. Adam, ‘‘Influence of hyperparameters on ran- dom forest accuracy,’’ inMultiple Classifier Systems, J. A. Benediktsson, J. Kittler, and F. Roli, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 171–180
2009
-
[68]
Scornet, ‘‘Tuning parameters in random forests,’’ESAIM: Procs, vol
E. Scornet, ‘‘Tuning parameters in random forests,’’ESAIM: Procs, vol. 60, pp. 144–162, 2017. [Online]. Available: https://doi.org/10.1051/ proc/201760144
arXiv 2017
-
[69]
M. Feurer and F. Hutter,Hyperparameter Optimization. Cham: Springer International Publishing, 2019, pp. 3–33. [Online]. Available: https: //doi.org/10.1007/978-3-030-05318-5_1
-
[70]
B. Bischl, M. Binder, M. Lang, T. Pielok, J. Richter, S. Coors, J. Thomas, T. Ullmann, M. Becker, A.-L. Boulesteix, D. Deng, and M. Lindauer, ‘‘Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges,’’WIREs Data Mining and Knowledge Discovery, vol. 13, no. 2, p. e1484, 2023. [Online]. Available: https: //wires.onlinelibr...
-
[71]
Bartz, T
E. Bartz, T. Bartz-Beielstein, M. Zaefferer, and O. Mersmann,Hyperpa- rameter tuning for machine and deep learning with R: A practical guide. Springer Nature, 2023
2023
-
[72]
Bergstra and Y
J. Bergstra and Y . Bengio, ‘‘Random search for hyper-parameter optimiza- tion,’’The journal of machine learning research, vol. 13, no. 1, pp. 281– 305, 2012
2012
-
[73]
Probst, A.-L
P . Probst, A.-L. Boulesteix, and B. Bischl, ‘‘Tunability: Importance of hyperparameters of machine learning algorithms,’’Journal of Machine Learning Research, vol. 20, no. 53, pp. 1–32, 2019. [Online]. Available: http://jmlr.org/papers/v20/18-444.html
2019
-
[74]
Snoek, H
J. Snoek, H. Larochelle, and R. P . Adams, ‘‘Practical bayesian optimization of machine learning algorithms,’’ inAdvances in Neural Information Processing Systems, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, Eds., vol. 25. Curran Associates, Inc., 2012, p. 2951–2959. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2012/file/...
2012
-
[75]
Hutter, H
F. Hutter, H. H. Hoos, and K. Leyton-Brown, ‘‘Sequential model-based optimization for general algorithm configuration,’’ inLearning and Intel- ligent Optimization, C. A. C. Coello, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 507–523
2011
-
[76]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar, ‘‘Hyperband: A novel bandit-based approach to hyperparameter optimization,’’Journal of Machine Learning Research, vol. 18, no. 185, pp. 1–52, 2018. [Online]. Available: http://jmlr.org/papers/v18/16-558.html
2018
-
[77]
Falkner, A
S. Falkner, A. Klein, and F. Hutter, ‘‘BOHB: Robust and efficient hyperparameter optimization at scale,’’ inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 2018, pp. 1437–1446. [Online]. Available: https://proceedings.mlr.press/ v80/falkner18a.html
2018
-
[78]
J. Bergstra, B. Komer, C. Eliasmith, D. Y amins, and D. D. Cox, ‘‘Hyperopt: a python library for model selection and hyperparameter optimization,’’ Computational Science and Discovery, vol. 8, no. 1, p. 014008, jul 2015. [Online]. Available: https://doi.org/10.1088/1749-4699/8/1/014008
-
[79]
A. W. v. d. V aart,Delta Method, ser. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 1998, pp. 25– 34
1998
-
[80]
[Online]
Kaggle, ‘‘Kaggle: Y our machine learning and data science community,’’ 2025, accessed: 2025-12-23. [Online]. Available: https://www.kaggle.com
2025
-
[81]
Field,Discovering statistics using IBM SPSS statistics
A. Field,Discovering statistics using IBM SPSS statistics. Sage publica- tions limited, 2024. APPENDIX Proof of Proposition 1.From (8), SB −S ∞ =cB −γ +o(B −γ),(24) and, sinceR=sf·B, we similarly haveS R −S ∞ = csf −γB−γ +o(B −γ). Therefore, SB −S R =c(1−sf −γ)B−γ +o(B −γ).(25) Becausec(1−sf −γ)̸= 0, dividing (24) by (25) yields (9). By reformulating (9) ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.