FD-Bench: A Modular and Fair Benchmark for Data-driven Fluid Simulation
Pith reviewed 2026-05-22 12:55 UTC · model grok-4.3
The pith
FD-Bench supplies a modular benchmark that ranks 85 data-driven fluid models across 10 scenarios with standardized protocols.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
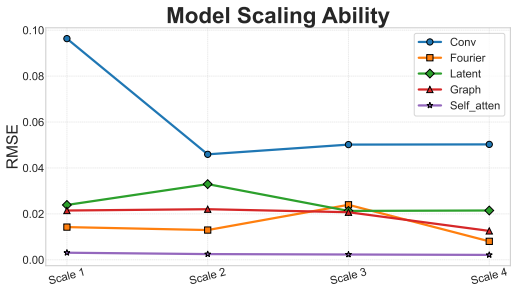
FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides a modular design that enables fair comparisons across spatial, temporal, and loss function modules, the first systematic framework for direct comparison with traditional numerical solvers, fine-grained generalization analysis across resolutions, initial conditions, and temporal windows, and a user-friendly extensible codebase.
What carries the argument
The modular design that separates spatial, temporal, and loss modules together with ten representative flow scenarios under one experimental protocol.
If this is right
- Model developers can isolate the effect of any single module without setup differences confounding the results.
- The leaderboard supplies the first consistent ordering of architectures that can be compared directly to classical solvers.
- Generalization tests across resolution and time window reveal which models remain stable when conditions change.
- The open codebase lets researchers add new models or scenarios without rebuilding the evaluation stack.
- Future work can extend the same modular protocol to three-dimensional or multi-physics problems.
Where Pith is reading between the lines
- The benchmark could serve as a template for standardized testing in related areas such as solid mechanics or combustion modeling.
- Hybrid neural-numerical solvers might be ranked more reliably once the same modular splits are applied to them.
- Engineering teams could use the leaderboard to select models for real-time control tasks where both accuracy and speed matter.
- Community extensions might add uncertainty quantification or inverse-problem benchmarks on top of the existing structure.
Load-bearing premise
The ten chosen flow scenarios and the splits between spatial, temporal, and loss modules are enough to produce rankings that reflect real performance differences outside the tested cases.
What would settle it
A previously unseen flow scenario or a shift in initial conditions in which currently lower-ranked models outperform the current leaders would show that the benchmark rankings do not generalize.
Figures
















read the original abstract
Data-driven modeling of fluid dynamics has advanced rapidly with neural PDE solvers, yet a fair and strong benchmark remains fragmented due to the absence of unified PDE datasets and standardized evaluation protocols. Although architectural innovations are abundant, fair assessment is further impeded by the lack of clear disentanglement between spatial, temporal and loss modules. In this paper, we introduce FD-Bench, the first fair, modular, comprehensive and reproducible benchmark for data-driven fluid simulation. FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides four key contributions: (1) a modular design enabling fair comparisons across spatial, temporal, and loss function modules; (2) the first systematic framework for direct comparison with traditional numerical solvers; (3) fine-grained generalization analysis across resolutions, initial conditions, and temporal windows; and (4) a user-friendly, extensible codebase to support future research. Through rigorous empirical studies, FD-Bench establishes the most comprehensive leaderboard to date, resolving long-standing issues in reproducibility and comparability, and laying a foundation for robust evaluation of future data-driven fluid models. The code is open-sourced at https://github.com/WillDreamer/FD-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FD-Bench, a modular benchmark for data-driven fluid simulation. It evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup, with contributions including a design that disentangles spatial, temporal, and loss modules; direct comparisons to traditional numerical solvers; generalization tests across resolutions, initial conditions, and temporal windows; and an open-source extensible codebase. The central claim is that this framework resolves long-standing reproducibility and comparability issues and establishes the most comprehensive leaderboard to date.
Significance. If the 10 scenarios and modular protocol produce rankings that reflect intrinsic model differences rather than benchmark-specific choices, FD-Bench would provide a useful standardized platform for the community and support more reliable evaluation of neural PDE solvers. The open code release is a clear strength that aids reproducibility. The significance is tempered by the need to verify that performance differences generalize beyond the selected flows and module combinations.
major comments (3)
- [Section 4.1] Section 4.1 and Table 1: The ten flow scenarios are presented as representative, but the manuscript lacks quantitative coverage analysis (e.g., range of Reynolds numbers, dimensionality, or boundary complexity). This is load-bearing for the claim that the leaderboard rankings are generalizable and resolve comparability issues.
- [Section 5.3] Section 5.3: The generalization analysis reports metrics across resolutions and initial conditions but omits statistical significance tests, error bars from multiple runs, or cross-validation details. Without these, it is difficult to assess whether observed differences are robust or could be artifacts of the specific data splits.
- [Section 3.2] Section 3.2: The modular framework is described as enabling fair isolation of spatial, temporal, and loss modules, yet the reported experiments do not include full ablations or interaction tests. This weakens the assertion that rankings reflect disentangled module contributions rather than combined effects.
minor comments (3)
- [Figure 2] Figure 2: The modular architecture diagram would benefit from explicit labels on data flow between spatial and temporal modules to improve readability.
- [Introduction] The abstract and introduction cite the absence of unified datasets, but a brief comparison table to prior fluid benchmarks (e.g., in related work) would strengthen the novelty claim.
- [Appendix A] Appendix A: Hyperparameter ranges and exact data preprocessing steps should be listed explicitly to complement the open-source code.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, clarifying our approach and noting the revisions incorporated to improve the manuscript.
read point-by-point responses
-
Referee: [Section 4.1] Section 4.1 and Table 1: The ten flow scenarios are presented as representative, but the manuscript lacks quantitative coverage analysis (e.g., range of Reynolds numbers, dimensionality, or boundary complexity). This is load-bearing for the claim that the leaderboard rankings are generalizable and resolve comparability issues.
Authors: We agree that explicit quantitative coverage metrics would strengthen the justification for the selected scenarios. In the revised manuscript we have expanded Section 4.1 with a new table (Table 2) that reports the Reynolds-number range (10^0 to 10^6), dimensionality (2-D and 3-D), and boundary-condition types (periodic, no-slip, inflow/outflow) for each of the ten flows. This analysis shows that the benchmark spans laminar-to-turbulent regimes and a variety of boundary complexities, thereby supporting the generalizability of the reported rankings. revision: yes
-
Referee: [Section 5.3] Section 5.3: The generalization analysis reports metrics across resolutions and initial conditions but omits statistical significance tests, error bars from multiple runs, or cross-validation details. Without these, it is difficult to assess whether observed differences are robust or could be artifacts of the specific data splits.
Authors: We acknowledge the value of statistical rigor. The revised Section 5.3 now includes error bars computed from five independent runs that differ in random seeds for data splitting and initialization. We have also added a 3-fold cross-validation over initial conditions and temporal windows, together with paired Wilcoxon signed-rank tests. The tests confirm that the performance gaps between leading models remain statistically significant (p < 0.01), reducing the likelihood that the observed trends are artifacts of particular splits. revision: yes
-
Referee: [Section 3.2] Section 3.2: The modular framework is described as enabling fair isolation of spatial, temporal, and loss modules, yet the reported experiments do not include full ablations or interaction tests. This weakens the assertion that rankings reflect disentangled module contributions rather than combined effects.
Authors: The referee is correct that the primary experiments emphasize end-to-end leaderboard construction rather than exhaustive module ablations. To address this concern we have added a new Section 5.4 that presents systematic one-at-a-time ablations (fixing two modules while varying the third) on a representative subset of scenarios, together with an analysis of pairwise interaction effects. The results indicate that module contributions are largely additive, with only modest interactions in a few cases; these findings are now reported to support the claim that the modular design enables disentangled evaluation. revision: yes
Circularity Check
No circularity: empirical benchmark with direct experimental rankings
full rationale
The paper introduces FD-Bench as an empirical evaluation framework that runs 85 models on 10 fixed flow scenarios under a unified modular protocol for spatial, temporal, and loss components. Leaderboard rankings arise from direct execution on provided datasets and open-sourced code rather than any derivation, first-principles prediction, or fitted parameter that reduces to the paper's own inputs by construction. No equations, uniqueness theorems, or self-citation chains appear in the load-bearing claims; the work is self-contained against external reproduction and does not rename known results or smuggle ansatzes. This matches the default expectation for non-derivational benchmark papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The ten chosen flow scenarios are representative of the broader class of fluid dynamics problems.
- domain assumption Modular separation of spatial, temporal, and loss modules allows fair attribution of performance differences.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.lean (or Cost/FunctionalEquation.lean)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup... modular design enabling fair comparisons across spatial, temporal, and loss function modules
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Universal physics transformers: A framework for efficiently scaling neural operators
Benedikt Alkin, Andreas Fürst, Simon Lucas Schmid, Lukas Gruber, Markus Holzleitner, and Johannes Brandstetter. Universal physics transformers: A framework for efficiently scaling neural operators. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[2]
Physics-informed diffusion models
Jan-Hendrik Bastek, WaiChing Sun, and Dennis Kochmann. Physics-informed diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[3]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3d neural networks.Nature, 619(7970):533– 538, 2023
work page 2023
-
[4]
Enhancing the inductive biases of graph neural ODE for modeling physical systems
Suresh Bishnoi, Ravinder Bhattoo, Jayadeva Jayadeva, Sayan Ranu, and N M Anoop Krishnan. Enhancing the inductive biases of graph neural ODE for modeling physical systems. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[5]
Oussama Boussif, Yoshua Bengio, Loubna Benabbou, and Dan Assouline. Magnet: Mesh agnostic neural pde solver.Advances in Neural Information Processing Systems, 35:31972– 31985, 2022
work page 2022
-
[6]
Envisioning better benchmarks for machine learning pde solvers
Johannes Brandstetter. Envisioning better benchmarks for machine learning pde solvers. Nature Machine Intelligence, 7(1):2–3, 2025
work page 2025
-
[7]
Clifford neural layers for PDE modeling
Johannes Brandstetter, Rianne van den Berg, et al. Clifford neural layers for PDE modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[8]
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural PDE solvers. InInternational Conference on Learning Representations, 2022
work page 2022
-
[9]
HAMLET: Graph transformer neural operator for partial differential equations
Andrey Bryutkin, Jiahao Huang, Zhongying Deng, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. HAMLET: Graph transformer neural operator for partial differential equations. InInternational Conference on Machine Learning, 2024
work page 2024
-
[10]
Yousuff Hussaini, Alfio Quarteroni, and Thomas A
Claudio Canuto, M. Yousuff Hussaini, Alfio Quarteroni, and Thomas A. Zang.Spectral Methods in Fluid Dynamics. Springer-Verlag, Berlin, Heidelberg, 1988
work page 1988
-
[11]
Lno: Laplace neural operator for solving differential equations.Arxiv, 2023
Qianying Cao, Somdatta Goswami, and George Em Karniadakis. Lno: Laplace neural operator for solving differential equations.Arxiv, 2023
work page 2023
-
[12]
Choose a transformer: Fourier or galerkin
Shuhao Cao. Choose a transformer: Fourier or galerkin. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
work page 2021
-
[13]
Spectral-refiner: Accurate fine-tuning of spatiotemporal fourier neural operator for turbulent flows
Shuhao Cao, Francesco Brarda, Ruipeng Li, and Yuanzhe Xi. Spectral-refiner: Accurate fine-tuning of spatiotemporal fourier neural operator for turbulent flows. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[14]
Yadi Cao, Menglei Chai, Minchen Li, and Chenfanfu Jiang. Efficient learning of mesh- based physical simulation with bi-stride multi-scale graph neural network. InInternational Conference on Machine Learning, pages 3541–3558. PMLR, 2023
work page 2023
-
[15]
A liquid plug moving in an annular pipe–heat transfer analysis
Yadi Cao, Xuan Gao, and Ri Li. A liquid plug moving in an annular pipe–heat transfer analysis. International Journal of Heat and Mass Transfer, 139:1065–1076, 2019
work page 2019
-
[16]
A liquid plug moving in an annular pipe—flow analysis.Physics of Fluids, 30(9), 2018
Yadi Cao and Ri Li. A liquid plug moving in an annular pipe—flow analysis.Physics of Fluids, 30(9), 2018
work page 2018
-
[17]
Implicit neural spatial representations for time-dependent pdes
Honglin Chen, Rundi Wu, Eitan Grinspun, Changxi Zheng, and Peter Yichen Chen. Implicit neural spatial representations for time-dependent pdes. InInternational Conference on Machine Learning, pages 5162–5177. PMLR, 2023
work page 2023
-
[18]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018. 10
work page 2018
-
[19]
Zhao Chen, Yang Liu, and Hao Sun. Physics-informed learning of governing equations from scarce data.Nature communications, 12(1):6136, 2021
work page 2021
-
[20]
Abouzar Choubineh, Jie Chen, David A Wood, Frans Coenen, and Fei Ma. Fourier neural operator for fluid flow in small-shape 2d simulated porous media dataset.Algorithms, 16(1):24, 2023
work page 2023
-
[21]
Zhiwen Deng, Jing Wang, Hongsheng Liu, Hairun Xie, BoKai Li, Miao Zhang, Tingmeng Jia, Yi Zhang, Zidong Wang, and Bin Dong. Prediction of transonic flow over supercritical airfoils using geometric-encoding and deep-learning strategies.Physics of Fluids, 35(7), 2023
work page 2023
-
[22]
Multiscale meshgraphnets.Arxiv, 2022
Meire Fortunato, Tobias Pfaff, Peter Wirnsberger, Alexander Pritzel, and Peter Battaglia. Multiscale meshgraphnets.Arxiv, 2022
work page 2022
-
[23]
Transformers for modeling physical systems.Neural Networks, 146:272–289, 2022
Nicholas Geneva and Nicholas Zabaras. Transformers for modeling physical systems.Neural Networks, 146:272–289, 2022
work page 2022
-
[24]
Learning physics informed neural odes with partial measurements
Paul Ghanem, Ahmet Demirkaya, Tales Imbiriba, Alireza Ramezani, Zachary Danziger, and Deniz Erdogmus. Learning physics informed neural odes with partial measurements. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16799–16807, 2025
work page 2025
-
[25]
R.A. Gingold and J.J. Monaghan. Smoothed particle hydrodynamics: theory and application to non-spherical stars.Monthly Notices of the Royal Astronomical Society, 181(3):375–389, 1977
work page 1977
-
[26]
Efficient token mixing for transformers via adaptive fourier neural operators
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, Anima Anandkumar, and Bryan Catanzaro. Efficient token mixing for transformers via adaptive fourier neural operators. In International conference on learning representations, 2021
work page 2021
-
[27]
Multiwavelet-based operator learning for differential equations
Gaurav Gupta, Xiongye Xiao, and Paul Bogdan. Multiwavelet-based operator learning for differential equations. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
work page 2021
-
[28]
Brainode: Dynamic brain signal analysis via graph-aided neural ordinary differential equations
Kaiqiao Han, Yi Yang, Zijie Huang, Xuan Kan, Ying Guo, Yang Yang, Lifang He, Liang Zhan, Yizhou Sun, Wei Wang, et al. Brainode: Dynamic brain signal analysis via graph-aided neural ordinary differential equations. In2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), pages 1–8. IEEE, 2024
work page 2024
-
[29]
Predicting physics in mesh-reduced space with temporal attention
XU HAN, Han Gao, Tobias Pfaff, Jian-Xun Wang, and Liping Liu. Predicting physics in mesh-reduced space with temporal attention. InInternational Conference on Learning Representations, 2022
work page 2022
-
[30]
Dpot: Auto-regressive denoising operator transformer for large-scale pde pre-training.ICML, 2024
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. Dpot: Auto-regressive denoising operator transformer for large-scale pde pre-training.ICML, 2024
work page 2024
-
[31]
Gnot: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. Gnot: A general neural operator transformer for operator learning. InInternational Conference on Machine Learning, pages 12556–12569. PMLR, 2023
work page 2023
-
[32]
Zhongkai Hao, Jiachen Yao, Chang Su, Hang Su, Ziao Wang, Fanzhi Lu, Zeyu Xia, Yichi Zhang, Songming Liu, Lu Lu, et al. Pinnacle: A comprehensive benchmark of physics- informed neural networks for solving pdes.Arxiv, 2023
work page 2023
-
[33]
Xiaodong He, Yinan Wang, and Juan Li. Flow completion network: Inferring the fluid dynamics from incomplete flow information using graph neural networks.Physics of Fluids, 34(8), 2022
work page 2022
-
[34]
Group equivariant fourier neural operators for partial differential equations.ICML, 2023
Jacob Helwig, Xuan Zhang, Cong Fu, Jerry Kurtin, Stephan Wojtowytsch, and Shuiwang Ji. Group equivariant fourier neural operators for partial differential equations.ICML, 2023. 11
work page 2023
-
[35]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raonic, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel de Bézenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. Advances in Neural Information Processing Systems, 37:72525–72624, 2024
work page 2024
-
[36]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[37]
DiffusionPDE: Generative PDE-solving under partial observation
Jiahe Huang, Guandao Yang, Zichen Wang, and Jeong Joon Park. DiffusionPDE: Generative PDE-solving under partial observation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[38]
Xiang Huang, Zhanhong Ye, Hongsheng Liu, Shi Ji, Zidong Wang, Kang Yang, Yang Li, Min Wang, Haotian Chu, Fan Yu, et al. Meta-auto-decoder for solving parametric partial differential equations.Advances in Neural Information Processing Systems, 35:23426–23438, 2022
work page 2022
-
[39]
Learning continuous system dynamics from irregularly-sampled partial observations
Zijie Huang, Yizhou Sun, and Wei Wang. Learning continuous system dynamics from irregularly-sampled partial observations. InAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[40]
Physics-informed regularization for domain-agnostic dynamical system modeling, 2024
Zijie Huang, Wanjia Zhao, Jingdong Gao, Ziniu Hu, Xiao Luo, Yadi Cao, Yuanzhou Chen, Yizhou Sun, and Wei Wang. Physics-informed regularization for domain-agnostic dynamical system modeling, 2024
work page 2024
-
[41]
Jinsung Jeon, Hyundong Jin, Jonghyun Choi, Sanghyun Hong, Dongeun Lee, Kookjin Lee, and Noseong Park. Pac-fno: Parallel-structured all-component fourier neural operators for recognizing low-quality images.Arxiv, 2024
work page 2024
-
[42]
Zhongyi Jiang, Min Zhu, and Lu Lu. Fourier-mionet: Fourier-enhanced multiple-input neural operators for multiphase modeling of geological carbon sequestration.Reliability Engineering & System Safety, 251:110392, 2024
work page 2024
-
[43]
Pengzhan Jin, Shuai Meng, and Lu Lu. Mionet: Learning multiple-input operators via tensor product.SIAM Journal on Scientific Computing, 44(6):A3490–A3514, 2022
work page 2022
-
[44]
Xiaowei Jin, Shengze Cai, Hui Li, and George Em Karniadakis. Nsfnets (navier-stokes flow nets): Physics-informed neural networks for the incompressible navier-stokes equations. Journal of Computational Physics, 426:109951, 2021
work page 2021
-
[45]
G.A. Klaasen and W.C. Troy. Stationary wave solutions of a system of reaction-diffusion equations derived from the fitzhugh–nagumo equations.SIAM Journal on Applied Mathematics, 44(1):96–110, 1984
work page 1984
-
[46]
Georg Kohl, Li-Wei Chen, and Nils Thuerey. Benchmarking autoregressive conditional diffusion models for turbulent flow simulation.arXiv preprint arXiv:2309.01745, 2023
-
[47]
Learning in latent spaces improves the predictive accuracy of deep neural operators.Arxiv, 2023
Katiana Kontolati, Somdatta Goswami, George Em Karniadakis, and Michael D Shields. Learning in latent spaces improves the predictive accuracy of deep neural operators.Arxiv, 2023
work page 2023
-
[48]
Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
work page 2023
-
[49]
Jae Yong Lee, SungWoong CHO, and Hyung Ju Hwang. HyperdeepONet: learning operator with complex target function space using the limited resources via hypernetwork. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[50]
Sangseung Lee and Donghyun You. Data-driven prediction of unsteady flow over a circular cylinder using deep learning.Journal of Fluid Mechanics, 879:217–254, 2019
work page 2019
-
[51]
Jiequan Li. Two-stage fourth order: temporal-spatial coupling in computational fluid dynamics (cfd).Advances in Aerodynamics, 1:1–36, 2019. 12
work page 2019
-
[52]
Tianyi Li, Luca Biferale, Fabio Bonaccorso, Martino Andrea Scarpolini, and Michele Buzzi- cotti. Synthetic lagrangian turbulence by generative diffusion models.Nature Machine Intelligence, pages 1–11, 2024
work page 2024
-
[53]
Zijie Li and Amir Barati Farimani. Graph neural network-accelerated lagrangian fluid simula- tion.Computers & Graphics, 103:201–211, 2022
work page 2022
-
[54]
Scalable transformer for pde surrogate modeling
Zijie Li, Dule Shu, and Amir Barati Farimani. Scalable transformer for pde surrogate modeling. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[55]
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
work page 2023
-
[56]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew Stuart, Kaushik Bhattacharya, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations.Advances in Neural Information Processing Systems, 33:6755–6766, 2020
work page 2020
-
[57]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, Anima Anandkumar, et al. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations
-
[58]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, et al. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[59]
Geometry-informed neural operator for large- scale 3d PDEs
Zongyi Li, Nikola Borislavov Kovachki, et al. Geometry-informed neural operator for large- scale 3d PDEs. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[60]
Physics-informed neural operator for learning partial differential equations.Arxiv, 2021
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.Arxiv, 2021
work page 2021
-
[61]
Guang Lin, Christian Moya, and Zecheng Zhang. B-deeponet: An enhanced bayesian deep- onet for solving noisy parametric pdes using accelerated replica exchange sgld.Journal of Computational Physics, 473:111713, 2023
work page 2023
-
[62]
Mario Lino, Stathi Fotiadis, Anil A Bharath, and Chris D Cantwell. Multi-scale rotation- equivariant graph neural networks for unsteady eulerian fluid dynamics.Physics of Fluids, 34(8), 2022
work page 2022
-
[63]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Fast fluid simulation via dynamic multi-scale gridding
Jinxian Liu, Ye Chen, Bingbing Ni, Wei Ren, Zhenbo Yu, and Xiaoyang Huang. Fast fluid simulation via dynamic multi-scale gridding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 1675–1682, 2023
work page 2023
-
[65]
Domain agnostic fourier neural operators
Ning Liu, Siavash Jafarzadeh, and Yue Yu. Domain agnostic fourier neural operators. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[66]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
work page 2021
-
[67]
Pgode: Towards high-quality system dynamics modeling, 2024
Xiao Luo, Yiyang Gu, Huiyu Jiang, Hang Zhou, Jinsheng Huang, Wei Ju, Zhiping Xiao, Ming Zhang, and Yizhou Sun. Pgode: Towards high-quality system dynamics modeling, 2024
work page 2024
-
[68]
Care: Modeling interacting dynamics under temporal environmental variation
Xiao Luo, Haixin Wang, Zijie Huang, Huiyu Jiang, Abhijeet Sadashiv Gangan, Song Jiang, and Yizhou Sun. Care: Modeling interacting dynamics under temporal environmental variation. InThirty-seventh Conference on Neural Information Processing Systems, 2023. 13
work page 2023
-
[69]
HOPE: High-order graph ODE for modeling interacting dynamics
Xiao Luo, Jingyang Yuan, Zijie Huang, Huiyu Jiang, Yifang Qin, Wei Ju, Ming Zhang, and Yizhou Sun. HOPE: High-order graph ODE for modeling interacting dynamics. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ...
work page 2023
-
[70]
Cfdbench: A comprehensive benchmark for machine learning methods in fluid dynamics.Arxiv, 2023
Yining Luo, Yingfa Chen, and Zhen Zhang. Cfdbench: A comprehensive benchmark for machine learning methods in fluid dynamics.Arxiv, 2023
work page 2023
-
[71]
V orticity and incompressible flow
Andrew J Majda, Andrea L Bertozzi, and A Ogawa. V orticity and incompressible flow. cambridge texts in applied mathematics.Appl. Mech. Rev., 55(4):B77–B78, 2002
work page 2002
-
[72]
Nick McGreivy and Ammar Hakim. Weak baselines and reporting biases lead to overoptimism in machine learning for fluid-related partial differential equations.Nature Machine Intelligence, 6(10):1256–1269, 2024
work page 2024
-
[73]
R. Mikulevicius and B. L. Rozovskii. Stochastic navier–stokes equations for turbulent flows. SIAM Journal on Mathematical Analysis, 35(5):1250–1310, 2004
work page 2004
-
[74]
F. Moukalled, L. Mangani, and M. Darwish.The Finite Volume Method in Computational Fluid Dynamics. Springer, 1 edition, 2016
work page 2016
-
[75]
Bilal Mufti, Anindya Bhaduri, Sayan Ghosh, Liping Wang, and Dimitri N Mavris. Shock wave prediction in transonic flow fields using domain-informed probabilistic deep learning.Physics of Fluids, 36(1), 2024
work page 2024
-
[76]
Particle-based fluid simulation for inter- active applications
Matthias Müller, David Charypar, and Markus Gross. Particle-based fluid simulation for inter- active applications. InProceedings of the 2003 ACM SIGGRAPH/Eurographics symposium on Computer animation, pages 154–159. Citeseer, 2003
work page 2003
-
[77]
Ruben Ohana, Michael McCabe, Lucas Meyer, Rudy Morel, Fruzsina Agocs, Miguel Beneitez, Marsha Berger, Blakesly Burkhart, Stuart Dalziel, Drummond Fielding, et al. The well: a large-scale collection of diverse physics simulations for machine learning.Advances in Neural Information Processing Systems, 37:44989–45037, 2024
work page 2024
-
[78]
Neural-fly enables rapid learning for agile flight in strong winds.Science Robotics, 7(66), 2022
Michael O’Connell, Guanya Shi, Xichen Shi, et al. Neural-fly enables rapid learning for agile flight in strong winds.Science Robotics, 7(66), 2022
work page 2022
-
[79]
Jaideep Pathak, Shashank Subramanian, et al. Fourcastnet: A global data-driven high- resolution weather model using adaptive fourier neural operators.Arxiv, 2022
work page 2022
-
[80]
Learning mesh-based simulation with graph networks
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter Battaglia. Learning mesh-based simulation with graph networks. InInternational Conference on Learning Repre- sentations, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.