ActMVS: Active Scene Reconstruction with Monocular Multi-View Stereo
Pith reviewed 2026-06-28 16:51 UTC · model grok-4.3
The pith
ActMVS uses a monocular camera to build view factor graphs and optimize depth for online consistent maps that support collision-free navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
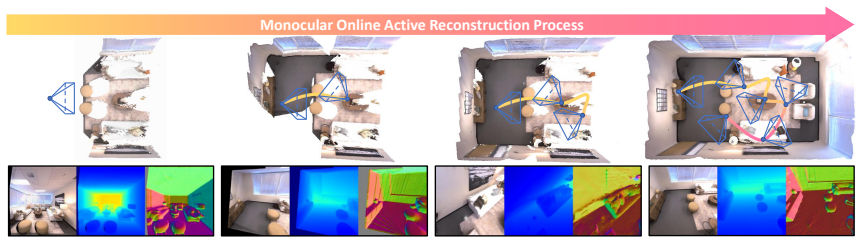
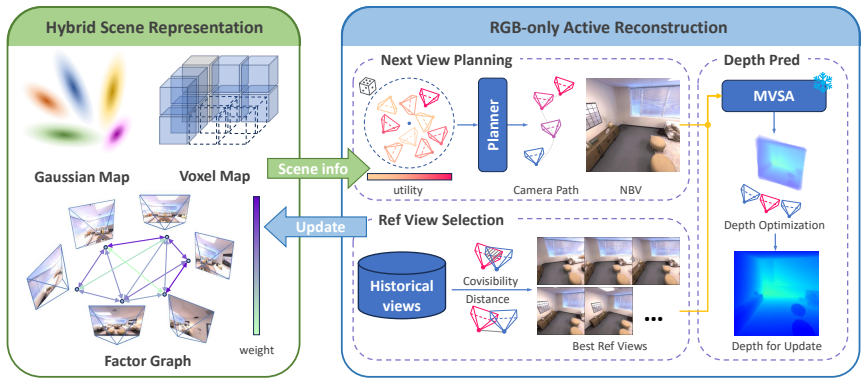
ActMVS integrates view factor graph construction for informed Multi-View Stereo depth prediction along with global depth optimization to enable the online generation of high-quality, globally consistent dense depth maps from monocular input alone, allowing robots and UAVs to maintain reliable occupancy maps for collision-free navigation during active reconstruction.
What carries the argument
View factor graph construction for informed Multi-View Stereo depth prediction combined with global depth optimization.
If this is right
- Monocular platforms can perform active reconstruction without added depth-sensor hardware.
- Occupancy maps become available online from vision input alone.
- Trajectory planning can remain safe using only the produced depth maps.
- Performance reaches levels comparable to RGB-D systems on standard datasets.
Where Pith is reading between the lines
- The same graph-and-optimization structure might extend to other single-camera tasks such as object tracking in motion.
- If frame-rate limits are met, the method could lower the minimum sensor payload for small UAVs.
- Failure modes would likely appear first in scenes with rapid lighting changes or repetitive textures.
Load-bearing premise
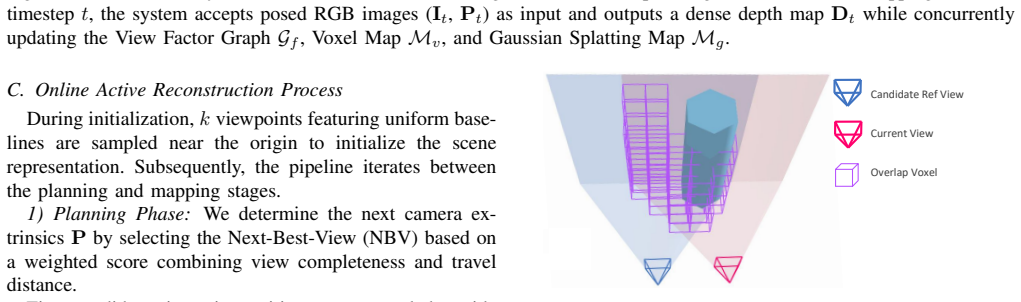
The view factor graph and global depth optimization produce reliable occupancy maps at frame rates sufficient for collision-free navigation without any depth sensor input.
What would settle it
A real-time robot navigation trial in which the generated occupancy maps cause a collision or cannot update fast enough to prevent one.
Figures

read the original abstract
Active scene reconstruction enables robots/UAVs to autonomously plan trajectories and reconstruct environments without costly manual data acquisition. Unlike passive methods, active reconstruction requires real-time construction of high-confidence occupancy maps for collision-free navigation. Existing approaches rely on depth sensors for occupancy map updates, increasing platform cost and weight. To advance spatial intelligence, we aim for a vision-only monocular solution. However, current monocular scene reconstruction methods operate offline and fail to deliver globally consistent dense depth at the frame rates required for robots/UAVs navigation. To bridge this gap, we introduce ActMVS, the first framework for monocular active reconstruction. Our framework integrates a view factor graph construction for informed Multi-View Stereo depth prediction, along with a global depth optimization, to enable the online generation of high-quality, globally consistent dense depth maps. This enables monocular robots/UAVs to maintain reliable occupancy maps for safe trajectory planning during reconstruction. Experiments on Replica datasets demonstrate performance competitive with RGB-D methods. Our code and data are available at https://github.com/TrickyGo/ActMVS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActMVS as the first monocular framework for active scene reconstruction. It constructs a view factor graph to inform Multi-View Stereo depth prediction, applies global depth optimization to produce online, globally consistent dense depth maps, and claims this enables reliable occupancy maps for collision-free navigation on monocular robots/UAVs without depth sensors. Experiments on Replica datasets report depth quality competitive with RGB-D baselines; code is released.
Significance. If the central claims hold, the work would represent a meaningful step toward vision-only active reconstruction, lowering platform cost and weight for robots. Releasing code strengthens reproducibility. However, the significance is limited by the gap between reported depth metrics and the untested navigation-safety claims.
major comments (3)
- [Experiments] Experiments section: depth-map metrics (e.g., on Replica) are reported as competitive with RGB-D, but the load-bearing claim that the view factor graph + global optimization produce occupancy maps reliable for collision-free trajectory planning is unsupported; no collision rates, trajectory success rates, timing benchmarks for map updates, or navigation trials are described.
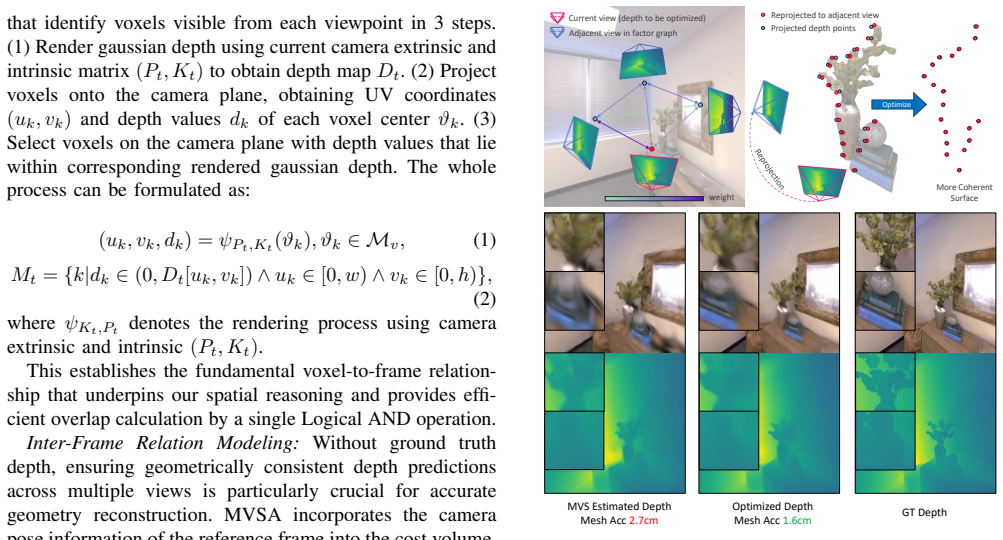
- [§3] §3 (framework description): the transition from per-frame depth maps to globally consistent occupancy maps suitable for real-time collision avoidance is asserted but not quantified; no analysis of map update latency, occupancy threshold sensitivity, or failure modes under monocular scale ambiguity is provided.
- [Abstract, §4] Abstract and §4: the claim of 'performance competitive with RGB-D methods' for active reconstruction is not accompanied by error bars, statistical tests, or explicit baseline implementations; the evaluation appears limited to passive depth quality rather than active planning loops.
minor comments (2)
- [§3] Notation for the view factor graph (e.g., edge weights, factor definitions) should be introduced with a clear diagram or pseudocode to aid reproducibility.
- [§4] The Replica experiment protocol (sequence selection, termination criteria, exclusion rules) is not detailed; add a table or paragraph specifying these choices.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback highlighting the need for stronger links between depth reconstruction quality and navigation performance. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experiments section: depth-map metrics (e.g., on Replica) are reported as competitive with RGB-D, but the load-bearing claim that the view factor graph + global optimization produce occupancy maps reliable for collision-free trajectory planning is unsupported; no collision rates, trajectory success rates, timing benchmarks for map updates, or navigation trials are described.
Authors: The primary contribution and evaluation of ActMVS center on producing high-quality, globally consistent monocular depth maps, with quantitative results on Replica showing competitiveness to RGB-D baselines. These depth maps directly enable occupancy map construction via standard projection and thresholding. We acknowledge that explicit navigation trials (collision rates, success rates, timing) are absent, as the work focuses on the reconstruction pipeline rather than full planning integration. In revision we will add a dedicated discussion subsection relating depth metrics to expected occupancy reliability and explicitly note the lack of end-to-end navigation experiments as a limitation. revision: partial
-
Referee: [§3] §3 (framework description): the transition from per-frame depth maps to globally consistent occupancy maps suitable for real-time collision avoidance is asserted but not quantified; no analysis of map update latency, occupancy threshold sensitivity, or failure modes under monocular scale ambiguity is provided.
Authors: Section 3 details the view factor graph and global optimization steps that produce consistent depth. Occupancy maps are obtained by back-projecting the optimized depth with a fixed threshold. We agree that latency, threshold sensitivity, and scale-ambiguity failure modes merit explicit treatment. We will expand §3 with a new paragraph providing timing estimates derived from the optimization solver, a brief sensitivity study on the occupancy threshold, and discussion of how the factor-graph scale anchoring mitigates monocular drift. revision: yes
-
Referee: [Abstract, §4] Abstract and §4: the claim of 'performance competitive with RGB-D methods' for active reconstruction is not accompanied by error bars, statistical tests, or explicit baseline implementations; the evaluation appears limited to passive depth quality rather than active planning loops.
Authors: Comparisons in §4 follow standard depth metrics and baseline implementations reported in the cited RGB-D literature on Replica. We will revise the tables and figures to include per-metric standard deviations (error bars) and add a short paragraph clarifying exact baseline code references. The evaluation targets depth quality because it is the enabling component for active reconstruction; full closed-loop planning experiments lie outside the current scope but are directly supported by the produced depth maps. revision: yes
- Quantitative end-to-end navigation experiments (collision rates, trajectory success rates, map-update timing) on physical or simulated monocular platforms, which were not performed in the original work.
Circularity Check
Framework construction is self-contained with no load-bearing reductions to inputs or self-citations
full rationale
The paper presents ActMVS as a novel integration of view factor graph construction for MVS depth prediction and global depth optimization to produce online dense depth maps from monocular input. No equations, derivations, or predictions are shown that reduce by construction to fitted parameters, prior self-citations, or renamed known results. The central claims rest on the independent engineering of these components and their empirical validation on Replica against RGB-D baselines, without any self-referential loops or uniqueness theorems imported from the authors' prior work. This is the standard case of a self-contained systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Active vision in robotic systems: A survey of recent developments,
S. Chen, Y . Li, and N. M. Kwok, “Active vision in robotic systems: A survey of recent developments,”The International Journal of Robotics Research, vol. 30, no. 11, pp. 1343–1377, 2011
2011
-
[2]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4104–4113
2016
-
[3]
Orb-slam: A versatile and accurate monocular slam system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: A versatile and accurate monocular slam system,”IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[4]
An informa- tion gain formulation for active volumetric 3d reconstruction,
S. Isler, R. Sabzevari, J. Delmerico, and D. Scaramuzza, “An informa- tion gain formulation for active volumetric 3d reconstruction,” in2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 3477–3484
2016
-
[5]
Receding horizon
A. Bircher, M. Kamel, K. Alexis, H. Oleynikova, and R. Siegwart, “Receding horizon” next-best-view” planner for 3d exploration,” in 2016 IEEE international conference on robotics and automation (ICRA). IEEE, 2016, pp. 1462–1468
2016
-
[6]
Naruto: Neural active reconstruction from uncertain target observations,
Z. Feng, H. Zhan, Z. Chen, Q. Yan, X. Xu, C. Cai, B. Li, Q. Zhu, and Y . Xu, “Naruto: Neural active reconstruction from uncertain target observations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 572–21 583
2024
-
[7]
Gs-planner: A gaussian-splatting-based planning framework for active high-fidelity reconstruction,
R. Jin, Y . Gao, Y . Wang, Y . Wu, H. Lu, C. Xu, and F. Gao, “Gs-planner: A gaussian-splatting-based planning framework for active high-fidelity reconstruction,” in2024 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS). IEEE, 2024, pp. 11 202–11 209
2024
-
[8]
Z. Xu, R. Jin, K. Wu, Y . Zhao, Z. Zhang, J. Zhao, F. Gao, Z. Gan, and W. Ding, “Hgs-planner: Hierarchical planning framework for active scene reconstruction using 3d gaussian splatting,”arXiv preprint arXiv:2409.17624, 2024
-
[9]
Ac- tivesplat: High-fidelity scene reconstruction through active gaussian splatting,
Y . Li, Z. Kuang, T. Li, Q. Hao, Z. Yan, G. Zhou, and S. Zhang, “Ac- tivesplat: High-fidelity scene reconstruction through active gaussian splatting,”IEEE Robotics and Automation Letters, 2025
2025
-
[10]
Fisherrf: Active view selection and mapping with radiance fields using fisher information,
W. Jiang, B. Lei, and K. Daniilidis, “Fisherrf: Active view selection and mapping with radiance fields using fisher information,” inEuro- pean Conference on Computer Vision. Springer, 2024, pp. 422–440
2024
-
[11]
Activegs: Active scene reconstruction using gaussian splatting,
L. Jin, X. Zhong, Y . Pan, J. Behley, C. Stachniss, and M. Popovi ´c, “Activegs: Active scene reconstruction using gaussian splatting,”IEEE Robotics and Automation Letters, 2025
2025
-
[12]
A volumetric method for building complex models from range images,
B. Curless and M. Levoy, “A volumetric method for building complex models from range images,” inProceedings of the 23rd annual conference on Computer graphics and interactive techniques, 1996, pp. 303–312
1996
-
[13]
Octomap: An efficient probabilistic 3d mapping framework based on octrees,
A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Bur- gard, “Octomap: An efficient probabilistic 3d mapping framework based on octrees,”Autonomous robots, vol. 34, no. 3, pp. 189–206, 2013
2013
-
[14]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
2021
-
[15]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Systems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[16]
Simplerecon: 3d reconstruction without 3d convolutions,
M. Sayed, J. Gibson, J. Watson, V . Prisacariu, M. Firman, and C. Godard, “Simplerecon: 3d reconstruction without 3d convolutions,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 1– 19
2022
-
[17]
Mvsanywhere: Zero-shot multi-view stereo,
S. Izquierdo, M. Sayed, M. Firman, G. Garcia-Hernando, D. Tur- mukhambetov, J. Civera, O. Mac Aodha, G. Brostow, and J. Watson, “Mvsanywhere: Zero-shot multi-view stereo,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 493–11 504
2025
-
[18]
Openmvg: Open multiple view geometry,
P. Moulon, P. Monasse, R. Perrot, and R. Marlet, “Openmvg: Open multiple view geometry,” inInternational Workshop on Reproducible Research in Pattern Recognition. Springer, 2016, pp. 60–74
2016
-
[19]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236
2018
-
[20]
Su- perglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Su- perglue: Learning feature matching with graph neural networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4938–4947
2020
-
[21]
Dsac-differentiable ransac for camera localization,
E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, “Dsac-differentiable ransac for camera localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6684–6692
2017
-
[22]
Triangulation,
R. I. Hartley and P. Sturm, “Triangulation,”Computer vision and image understanding, vol. 68, no. 2, pp. 146–157, 1997
1997
-
[23]
Bundle adjustment in the large,
S. Agarwal, N. Snavely, S. M. Seitz, and R. Szeliski, “Bundle adjustment in the large,” inEuropean conference on computer vision. Springer, 2010, pp. 29–42
2010
-
[24]
Structslam: Visual slam with building structure lines,
H. Zhou, D. Zou, L. Pei, R. Ying, P. Liu, and W. Yu, “Structslam: Visual slam with building structure lines,”IEEE Transactions on V ehicular Technology, vol. 64, no. 4, pp. 1364–1375, 2015
2015
-
[25]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[26]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard ´os, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE transactions on robotics, vol. 37, no. 6, pp. 1874–1890, 2021
2021
-
[27]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[28]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[29]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 697–20 709
2024
-
[30]
Must3r: Multi-view network for stereo 3d reconstruc- tion,
Y . Cabon, L. Stoffl, L. Antsfeld, G. Csurka, B. Chidlovskii, J. Revaud, and V . Leroy, “Must3r: Multi-view network for stereo 3d reconstruc- tion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1050–1060
2025
-
[31]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli, “Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 924–21 935
2025
-
[32]
Mast3r-sfm: A fully-integrated solution for unconstrained structure-from-motion,
B. Duisterhof, L. Zust, P. Weinzaepfel, V . Leroy, Y . Cabon, and J. Revaud, “Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion,”arXiv preprint arXiv:2409.19152, 2024
-
[33]
Vggsfm: Visual geometry grounded deep structure from motion,
J. Wang, N. Karaev, C. Rupprecht, and D. Novotny, “Vggsfm: Visual geometry grounded deep structure from motion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 21 686–21 697
2024
-
[34]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294–5306
2025
-
[35]
Sinmpi: Novel view synthesis from a single image with expanded multiplane images,
G. Pu, P.-S. Wang, and Z. Lian, “Sinmpi: Novel view synthesis from a single image with expanded multiplane images,” inSIGGRAPH Asia 2023 Conference Papers, 2023, pp. 1–10
2023
-
[36]
Wonderland: Navigating 3d scenes from a single image,
H. Liang, J. Cao, V . Goel, G. Qian, S. Korolev, D. Terzopoulos, K. N. Plataniotis, S. Tulyakov, and J. Ren, “Wonderland: Navigating 3d scenes from a single image,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 798–810
2025
-
[37]
Pano2room: Novel view synthesis from a single indoor panorama,
G. Pu, Y . Zhao, and Z. Lian, “Pano2room: Novel view synthesis from a single indoor panorama,” inSIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1–11
2024
-
[38]
Midi: Multi-instance diffusion for single image to 3d scene generation,
Z. Huang, Y .-C. Guo, X. An, Y . Yang, Y . Li, Z.-X. Zou, D. Liang, X. Liu, Y .-P. Cao, and L. Sheng, “Midi: Multi-instance diffusion for single image to 3d scene generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 23 646–23 657
2025
-
[39]
Neural collapse with normalized features: A geometric analysis over the Riemannian manifold
K. Yao, L. Zhang, X. Yan, Y . Zeng, Q. Zhang, W. Yang, L. Xu, J. Gu, and J. Yu, “Cast: Component-aligned 3d scene reconstruction from an rgb image,”arXiv preprint arXiv:2502.12894, 2025
-
[40]
Learning-based multi-view stereo: A survey,
F. Wang, Q. Zhu, D. Chang, Q. Gao, J. Han, T. Zhang, R. Hartley, and M. Pollefeys, “Learning-based multi-view stereo: A survey,”arXiv preprint arXiv:2408.15235, 2024
-
[41]
A comparison and evaluation of multi-view stereo reconstruction algorithms,
S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, and R. Szeliski, “A comparison and evaluation of multi-view stereo reconstruction algorithms,” in2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), vol. 1. IEEE, 2006, pp. 519–528
2006
-
[42]
Mvsnet: Depth inference for unstructured multi-view stereo,
Y . Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “Mvsnet: Depth inference for unstructured multi-view stereo,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 767–783
2018
-
[43]
Patch- matchnet: Learned multi-view patchmatch stereo,
F. Wang, S. Galliani, C. V ogel, P. Speciale, and M. Pollefeys, “Patch- matchnet: Learned multi-view patchmatch stereo,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 194–14 203
2021
-
[44]
High-quality surface reconstruction using gaussian surfels,
P. Dai, J. Xu, W. Xie, X. Liu, H. Wang, and W. Xu, “High-quality surface reconstruction using gaussian surfels,” inACM SIGGRAPH 2024 conference papers, 2024, pp. 1–11
2024
-
[45]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[46]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik,et al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
2019
-
[47]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma,et al., “The replica dataset: A digital replica of indoor spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[48]
Ego-planner: An esdf- free gradient-based local planner for quadrotors,
X. Zhou, Z. Wang, H. Ye, C. Xu, and F. Gao, “Ego-planner: An esdf- free gradient-based local planner for quadrotors,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 478–485, 2020. Camera Path GT ActiveGS NARUTO Ours w/o OPT w/o REF w/o MVS Our Mesh Fig. 6: Qualitative comparison on Replica scenes showcase the camera path and the reconstructed mes...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.