Bridge the Gaps: Heterogeneous Attributed Graph Clustering via Quaternion Representation Learning
Pith reviewed 2026-06-26 08:37 UTC · model grok-4.3
The pith
AGREE clusters heterogeneous attributed graphs by unifying mixed attributes through alignment, applying quaternion convolutions to reduce topology dominance, and using shallow layers to avoid over-smoothing, all optimized jointly without pr
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
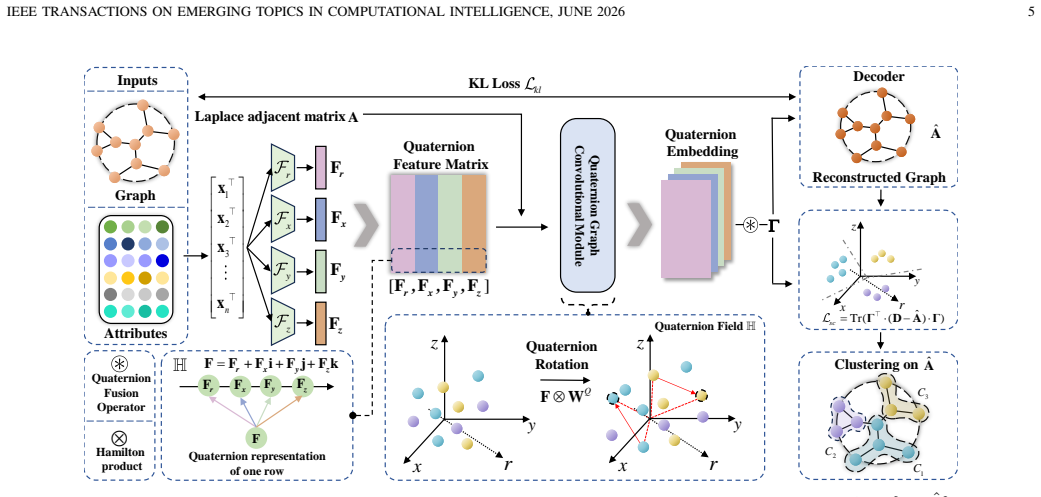
The central claim is that quaternion-based graph convolution in shallow architectures, paired with multi-level alignment for any-type attributes and similarity-driven graph construction, produces clustering-friendly embeddings by directly mitigating over-dominating and over-smoothing, with the model optimized end-to-end for both reconstruction and clustering without predefined cluster numbers.
What carries the argument
Quaternion-based graph convolution that strengthens attribute interaction to alleviate the over-dominating effect of topology while operating in shallow layers to relieve over-smoothing.
If this is right
- The framework processes numerical and categorical attributes uniformly without separate pipelines.
- Clustering proceeds without any need to pre-specify the number of clusters during training.
- Joint reconstruction and clustering objectives produce embeddings that respect both attribute and topology information.
- Shallow quaternion layers preserve discriminative signals that deeper standard convolutions would erase.
- The approach extends to any-type attributed data beyond strictly graph-structured inputs.
Where Pith is reading between the lines
- The design points toward using similar alignment steps for other graph tasks that mix discrete and continuous features, such as link prediction.
- If quaternion representations prove stable under attribute noise, the method could be tested on real-world datasets with missing or corrupted entries.
- The separation of over-dominating and over-smoothing remedies suggests experiments that swap in other interaction mechanisms while keeping the shallow constraint fixed.
Load-bearing premise
The assumption that quaternion-based graph convolution strengthens attribute interaction to alleviate the over-dominating effect and that shallow architectures relieve over-smoothing.
What would settle it
Running AGREE on a heterogeneous-attribute benchmark and finding that clustering accuracy does not exceed standard GCN baselines while node embeddings still exhibit high similarity or loss of attribute discriminability would falsify the central claim.
Figures

read the original abstract
Attributed graph clustering partitions nodes by jointly exploiting node attributes and graph topology. It remains challenging due to attribute heterogeneity and representation degradation during graph learning. Real-world datasets often contain heterogeneous attributes, i.e., numerical and categorical attributes, complicating unified representation learning. This challenge becomes more complex in attributed graphs, where constructing a clustering-friendly graph structure from attributes and topology remains difficult. Under deep graph architectures, repeated graph propagation causes node embeddings to become overly similar, leading to the over-smoothing (OS) effect. Meanwhile, graph representation learning amplifies topological influence, making discriminative attribute information harder to exploit for clustering, an effect we refer to as over-dominating (OD). To bridge these gaps, an end-to-end framework, Any-type attributed Graph REpresentation lEarning (AGREE), is proposed. It unifies attributed graphs and any-type attributed data through multi-level alignment and similarity-based graph construction. Quaternion-based graph convolution strengthens attribute interaction to alleviate OD, while shallow graph architectures help relieve OS. The learned embeddings are jointly optimized for graph reconstruction and clustering, without requiring a predefined number of clusters during training. Experiments on diverse benchmarks show that AGREE achieves strong overall performance in accuracy, robustness, and adaptability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AGREE, an end-to-end framework for heterogeneous attributed graph clustering. It unifies any-type attributed data via multi-level alignment and similarity-based graph construction, employs quaternion-based graph convolution to strengthen attribute interactions and alleviate the over-dominating (OD) effect, uses shallow architectures to mitigate over-smoothing (OS), and jointly optimizes embeddings for graph reconstruction and clustering without a predefined cluster count. Experiments on diverse benchmarks are reported to demonstrate strong performance in accuracy, robustness, and adaptability.
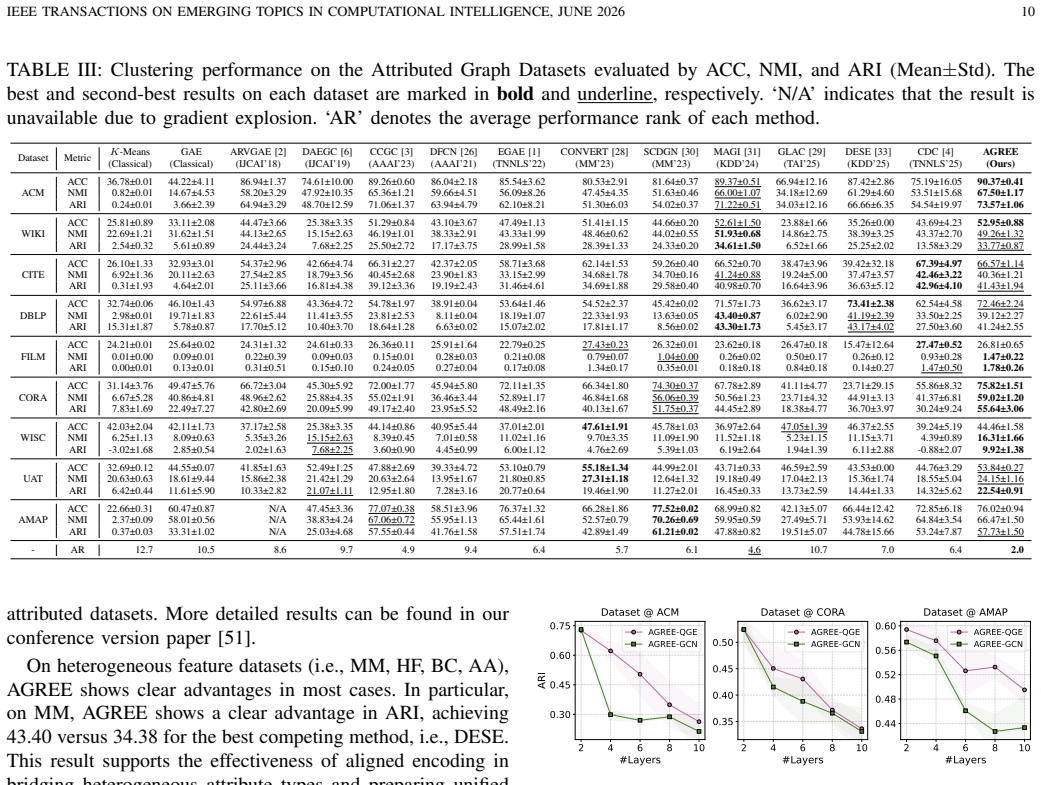
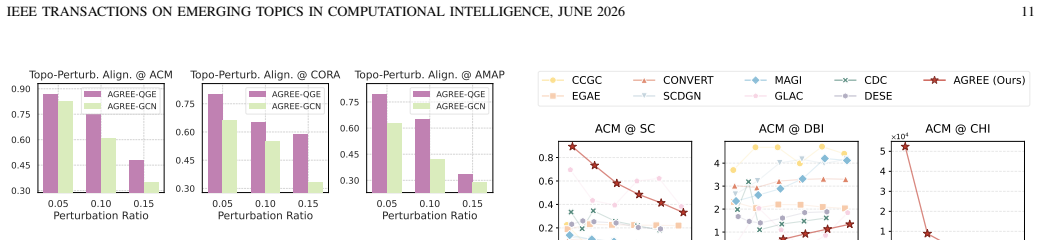
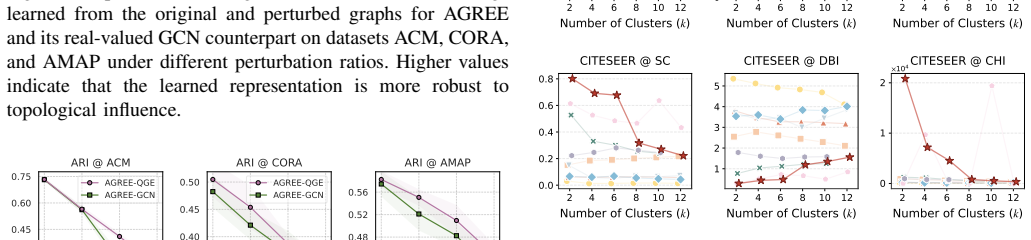
Significance. If the experimental claims hold, the work addresses practically relevant challenges in attributed graph clustering by targeting OD and OS with quaternion representations and shallow layers. The end-to-end design without requiring a preset number of clusters and the handling of heterogeneous (numerical/categorical) attributes are useful contributions. The reported gains on multiple benchmarks, if reproducible and properly controlled, would position the method as a competitive baseline in the graph clustering literature.
minor comments (2)
- [Abstract] Abstract: the claim of 'strong overall performance' is stated without any quantitative metrics, baselines, or effect sizes; adding 1-2 key numbers (e.g., average NMI improvement) would make the summary more informative.
- [Abstract] The description of quaternion convolution 'strengthening attribute interaction' and shallow layers 'relieving OS' is presented at a high level; a brief concrete illustration (e.g., how the quaternion multiplication differs from real-valued GCN in the first layer) would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The summary correctly identifies the core challenges addressed by AGREE (heterogeneous attributes, over-smoothing, and over-dominating effects) and the technical choices (quaternion convolutions, shallow architectures, joint reconstruction-clustering optimization, and no preset cluster count). As the report lists no specific major comments, we have no point-by-point responses to provide.
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context describe the AGREE framework's use of multi-level alignment, similarity-based graph construction, quaternion-based graph convolution for attribute interaction, and shallow architectures to address over-dominating and over-smoothing effects, with joint optimization for reconstruction and clustering. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are quoted that would reduce any claimed prediction or result to its inputs by construction. The derivation chain remains self-contained against external benchmarks, with performance claims resting on experimental validation rather than definitional equivalence or fitted renamings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Embedding graph auto-encoder for graph clustering,
H. Zhang, P. Li, R. Zhang, and X. Li, “Embedding graph auto-encoder for graph clustering,”IEEE Transactions on Neural Networks and Learning Systems, 2022
2022
-
[2]
Adversarially regularized graph autoencoder for graph embedding,
S. Pan, R. Hu, G. Long, J. Jiang, L. Yao, and C. Zhang, “Adversarially regularized graph autoencoder for graph embedding,” inProceedings of the International Joint Conference on Artificial Intelligence, pp. 2609– 2615, 2018
2018
-
[3]
Cluster-guided contrastive graph clustering network,
X. Yang, Y . Liu, S. Zhou, S. Wang, W. Tu, Q. Zheng, X. Liu, L. Fang, and E. Zhu, “Cluster-guided contrastive graph clustering network,” inProceedings of the AAAI Conference on Artificial Intelligence, pp. 10834–10842, 2023
2023
-
[4]
CDC: A simple framework for complex data clustering,
Z. Kang, X. Xie, B. Li, and E. Pan, “CDC: A simple framework for complex data clustering,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 13177–13188, 2025
2025
-
[5]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inProceedings of the International Conference on Learning Representations, 2017. IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTATIONAL INTELLIGENCE, JUNE 2026 14
2017
-
[6]
Attributed graph clustering: A deep attentional embedding approach,
C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed graph clustering: A deep attentional embedding approach,” inProceed- ings of the International Joint Conference on Artificial Intelligence, pp. 3670–3676, 2019
2019
-
[7]
When heterophily meets heterogeneous graphs: Latent graphs guided unsupervised representation learning,
Z. Shen and Z. Kang, “When heterophily meets heterogeneous graphs: Latent graphs guided unsupervised representation learning,”IEEE Trans- actions on Neural Networks and Learning Systems, vol. 36, no. 6, pp. 10283–10296, 2025
2025
-
[8]
Adaptive micro partition and hierarchical merging for accurate mixed data clustering,
Y . Zhang, R. Zou, Y . Zhang, Y . Zhang, Y .-M. Cheung, and K. Li, “Adaptive micro partition and hierarchical merging for accurate mixed data clustering,”Complex & Intelligent Systems, vol. 11, no. 1, pp. 1–14, 2025
2025
-
[9]
Batagelj, H.-H
V . Batagelj, H.-H. Bock, A. Ferligoj, and A. ˇZiberna, eds.,Data Science and Classification. Studies in Classification, Data Analysis, and Knowledge Organization, Springer, 2006
2006
-
[10]
Graph-based dissimilarity measurement for cluster analysis of any-type-attributed data,
Y . Zhang and Y .-M. Cheung, “Graph-based dissimilarity measurement for cluster analysis of any-type-attributed data,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 9, pp. 6530–6544, 2023
2023
-
[11]
Het2Hom: Representation of heterogeneous attributes into homogeneous concept spaces for categorical-and-numerical-attribute data clustering,
Y . Zhang, Y .-M. Cheung, and A. Zeng, “Het2Hom: Representation of heterogeneous attributes into homogeneous concept spaces for categorical-and-numerical-attribute data clustering,” inProceedings of the International Joint Conference on Artificial Intelligence, pp. 3758– 3765, 2022
2022
-
[12]
A unified entropy-based distance metric for ordinal-and-nominal-attribute data clustering,
Y . Zhang, Y .-M. Cheung, and K. C. Tan, “A unified entropy-based distance metric for ordinal-and-nominal-attribute data clustering,”IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 1, pp. 39–52, 2020
2020
-
[13]
Unsupervised heterogeneous coupling learning for categorical representation,
C. Zhu, L. Cao, and J. Yin, “Unsupervised heterogeneous coupling learning for categorical representation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 1, pp. 533–549, 2022
2022
-
[14]
A survey of quaternion neural networks,
T. Parcollet, M. Morchid, and G. Linar `es, “A survey of quaternion neural networks,”Artificial Intelligence Review, vol. 53, pp. 2957–2982, 2020
2020
-
[15]
Break the tie: Learning cluster-customized category relationships for categorical data clustering,
M. Zhao, Z. Huang, Y . Lu, M. Li, Y . Zhang, W. Su, and Y .-M. Cheung, “Break the tie: Learning cluster-customized category relationships for categorical data clustering,” inProceedings of the AAAI Conference on Artificial Intelligence, pp. 28715–28723, 2026
2026
-
[16]
An ordinal data clustering algorithm with automated distance learning,
Y . Zhang and Y .-M. Cheung, “An ordinal data clustering algorithm with automated distance learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 6869–6876, 2020
2020
-
[17]
Learnable weighting of intra-attribute distances for categorical data clustering with nominal and ordinal attributes,
Y . Zhang and Y .-M. Cheung, “Learnable weighting of intra-attribute distances for categorical data clustering with nominal and ordinal attributes,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 44, no. 7, pp. 3560–3576, 2022
2022
-
[18]
Learning order forest for qualitative-attribute data clustering,
M. Zhao, S. Feng, Y . Zhang, M. Li, Y . Lu, and Y .-M. Cheung, “Learning order forest for qualitative-attribute data clustering,” inProceedings of the European Conference on Artificial Intelligence, pp. 1943–1950, 2024
1943
-
[19]
Categorical data clustering via value order estimated distance metric learning,
Y . Zhang, M. Zhao, H. Jia, M. Li, Y . Lu, and Y .-M. Cheung, “Categorical data clustering via value order estimated distance metric learning,” Proceedings of the ACM on Management of Data, vol. 3, no. 6, pp. 1–24, 2025
2025
-
[20]
Robust cat- egorical data clustering guided by multi-granular competitive learning,
S. Cai, Y . Zhang, X. Luo, Y .-M. Cheung, H. Jia, and P. Liu, “Robust cat- egorical data clustering guided by multi-granular competitive learning,” inProceedings of the IEEE International Conference on Distributed Computing Systems, pp. 288–299, 2024
2024
-
[21]
Learning unified distance metric for heterogeneous attribute data clustering,
Y . Zhang, M. Zhao, Y . Chen, Y . Lu, and Y .-M. Cheung, “Learning unified distance metric for heterogeneous attribute data clustering,” Expert Systems with Applications, vol. 273, p. 126738, 2025
2025
-
[22]
Semi-supervised adaptive symmetric nonnegative matrix factoriza- tion for multi-view clustering,
M. Mohammadi, K. Berahmand, S. Azizi, R. Sheikhpour, and H. Khos- ravi, “Semi-supervised adaptive symmetric nonnegative matrix factoriza- tion for multi-view clustering,”IEEE Transactions on Network Science and Engineering, vol. 12, no. 6, pp. 4967–4981, 2025
2025
-
[23]
FMvPCI: A multiview fusion neural network for identifying protein complex via fuzzy clustering,
Y . Yang, L. Hu, G. Li, D. Li, P. Hu, and X. Luo, “FMvPCI: A multiview fusion neural network for identifying protein complex via fuzzy clustering,”IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 55, no. 9, pp. 6189–6202, 2025
2025
-
[24]
Unified representation learning for multi-view clustering by between/within view deep majorization,
Y . Zhang, S. Wang, W. Huang, C.-D. Wang, and D. Huang, “Unified representation learning for multi-view clustering by between/within view deep majorization,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 1, pp. 615–626, 2024
2024
-
[25]
Sparse graph tensor learning for multi-view spectral clustering,
M.-S. Chen, Z.-Y . Li, J.-Q. Lin, C.-D. Wang, and D. Huang, “Sparse graph tensor learning for multi-view spectral clustering,”IEEE Transac- tions on Emerging Topics in Computational Intelligence, vol. 8, no. 5, pp. 3534–3543, 2024
2024
-
[26]
Deep fusion clustering network,
W. Tu, S. Zhou, X. Liu, X. Guo, Z. Cai, E. Zhu, and J. Cheng, “Deep fusion clustering network,” inProceedings of the AAAI Conference on Artificial Intelligence, pp. 9978–9987, 2021
2021
-
[27]
HyReaL: Clustering attributed graph via hyper-complex space representation learning,
J. Chen, Y . Lu, M. Li, C. Yang, Y . Zhang, and Y .-M. Cheung, “HyReaL: Clustering attributed graph via hyper-complex space representation learning,” inProceedings of the International Conference on Database Systems for Advanced Applications, 2026
2026
-
[28]
CONVERT: Contrastive graph clustering with reliable augmentation,
X. Yang, C. Tan, Y . Liu, K. Liang, S. Wang, S. Zhou, J. Xia, S. Z. Li, X. Liu, and E. Zhu, “CONVERT: Contrastive graph clustering with reliable augmentation,” inProceedings of the ACM International Conference on Multimedia, pp. 319–327, 2023
2023
-
[29]
GLAC-GCN: Global and local topology-aware contrastive graph clustering network,
Y . Xu, D. Huang, C. Wang, and J. Lai, “GLAC-GCN: Global and local topology-aware contrastive graph clustering network,”IEEE Transac- tions on Artificial Intelligence, vol. 6, no. 6, pp. 1448–1459, 2025
2025
-
[30]
Self-contrastive graph diffusion network,
Y . Ma and K. Zhan, “Self-contrastive graph diffusion network,” inPro- ceedings of the ACM International Conference on Multimedia, pp. 3857– 3865, 2023
2023
-
[31]
Revisiting modularity maximization for graph clustering: A contrastive learning perspective,
Y . Liu, J. Li, Y . Chen, R. Wu, E. Wang, J. Zhou, S. Tian, S. Shen, X. Fu, C. Meng, W. Wang, and L. Chen, “Revisiting modularity maximization for graph clustering: A contrastive learning perspective,” inProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 1968–1979, 2024
1968
-
[32]
Node clustering on attributed graph using anchor sampling strategy and debiasing strategy,
Q. Tang, W. Zhang, Y . Wang, Y . Yang, and Z. Lu, “Node clustering on attributed graph using anchor sampling strategy and debiasing strategy,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 4, pp. 3017–3028, 2024
2024
-
[33]
Unsupervised graph clustering with deep structural entropy,
J. Zhang, H. Peng, L. Sun, G. Wu, C. Liu, and Z. Yu, “Unsupervised graph clustering with deep structural entropy,” inProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ACM, 2025
2025
-
[34]
Link-based attributed graph clustering via approximate generative bayesian learning,
Y . Yang, L. Hu, G. Li, D. Li, P. Hu, and X. Luo, “Link-based attributed graph clustering via approximate generative bayesian learning,”IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 55, no. 8, pp. 5730–5743, 2025
2025
-
[35]
Dual-view entropy-regularized nonnegative matrix factor- ization for attributed graph clustering,
M. Mohammadi, K. Berahmand, S. Forouzandeh, X. Zhou, and H. Khosravi, “Dual-view entropy-regularized nonnegative matrix factor- ization for attributed graph clustering,”Information Sciences, vol. 721, p. 122566, 2025
2025
-
[36]
Relative entropy-based regularized non-negative matrix factorization for attributed graph clustering,
K. Berahmand, M. Mohammadi, R. Sheikhpour, M. Jalili, R. Nayak, and H. Khosravi, “Relative entropy-based regularized non-negative matrix factorization for attributed graph clustering,”ACM Transactions on Knowledge Discovery from Data, vol. 19, no. 9, pp. 1–28, 2025
2025
-
[37]
Quaternions and matrices of quaternions,
F. Zhang, “Quaternions and matrices of quaternions,”Linear Algebra and its Applications, vol. 251, pp. 21–57, 1997
1997
-
[38]
Quaternion knowledge graph embeddings,
S. Zhang, Y . Tay, L. Yao, and Q. Liu, “Quaternion knowledge graph embeddings,” inAdvances in Neural Information Processing Systems, pp. 2731–2741, 2019
2019
-
[39]
Graph neural networks exponentially lose expressive power for node classification,
K. Oono and T. Suzuki, “Graph neural networks exponentially lose expressive power for node classification,” inProceedings of the Inter- national Conference on Learning Representations, 2020
2020
-
[40]
Lightweight and efficient neural natural language processing with quaternion networks,
Y . Tay, S. Zhang, M. Dehghani, C. S. Ong, D. Bahri, and D. Metzler, “Lightweight and efficient neural natural language processing with quaternion networks,” inProceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 1498–1508, 2019
2019
-
[41]
Structural deep clustering network,
D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural deep clustering network,” inProceedings of the Web Conference, pp. 1400– 1410, 2020
2020
-
[42]
Network representation learning with rich text information,
C. Yang, Z. Liu, D. Zhao, M. Sun, and E. Y . Chang, “Network representation learning with rich text information,” inProceedings of the International Joint Conference on Artificial Intelligence, pp. 2111– 2117, 2015
2015
-
[43]
Collective classification in network data,
P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Gallagher, and T. Eliassi- Rad, “Collective classification in network data,”AI Magazine, vol. 29, no. 3, pp. 93–106, 2008
2008
-
[44]
Geom-GCN: Geomet- ric graph convolutional networks,
H. Pei, B. Wei, K. C. Chang, Y . Lei, and B. Yang, “Geom-GCN: Geomet- ric graph convolutional networks,” inProceedings of the International Conference on Learning Representations, 2020
2020
-
[45]
A survey of deep graph clustering: Taxonomy, challenge, application, and open resource,
Y . Liu, J. Xia, S. Zhou, X. Yang, K. Liang, C. Fan, Y . Zhuang, S. Z. Li, X. Liu, and K. He, “A survey of deep graph clustering: Taxonomy, challenge, application, and open resource,”arXiv preprint arXiv:2211.12875, 2023
-
[46]
The uci machine learning repository
M. Kelly, R. Longjohn, and K. Nottingham, “The uci machine learning repository.” https://archive.ics.uci.edu, 2023
2023
-
[47]
A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions,
S. Zhou, H. Xu, Z. Zheng, J. Chen, Z. Li, J. Bu, J. Wu, X. Wang, W. Zhu, and M. Ester, “A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions,”CoRR, vol. abs/2206.07579, 2022. IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTATIONAL INTELLIGENCE, JUNE 2026 15
-
[48]
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,”Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987
1987
-
[49]
A cluster separation measure,
D. L. Davies and D. W. Bouldin, “A cluster separation measure,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 1, no. 2, pp. 224–227, 1979
1979
-
[50]
A dendrite method for cluster analysis,
T. Cali ´nski and J. Harabasz, “A dendrite method for cluster analysis,” Communications in Statistics, vol. 3, no. 1, pp. 1–27, 1974
1974
-
[51]
QGRL: Quaternion graph representation learning for heterogeneous feature data clustering,
J. Chen, Y . Ji, R. Zou, Y . Zhang, and Y .-M. Cheung, “QGRL: Quaternion graph representation learning for heterogeneous feature data clustering,” inProceedings of the ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining, pp. 297–306, 2024
2024
-
[52]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inProceedings of the International Conference on Machine Learning, pp. 3519–3529, 2019
2019
-
[53]
Open Graph Benchmark: Datasets for machine learning on graphs,
W. Hu, M. Fey, M. Zitnik, Y . Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open Graph Benchmark: Datasets for machine learning on graphs,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[54]
Visualizing data using t-SNE,
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of Machine Learning Research, vol. 9, no. 11, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.