DiCoBench: Benchmarking Multi-Image Fine-Grained Perception via Differential and Commonality Visual Cues
Pith reviewed 2026-06-26 05:15 UTC · model grok-4.3
The pith
DiCoBench reveals multimodal models lag far behind humans on autonomous high-resolution multi-image perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
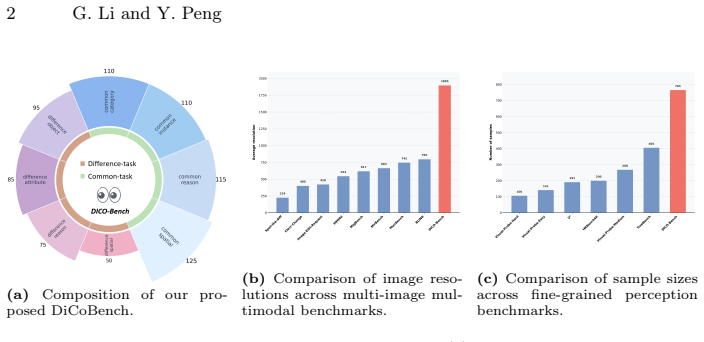
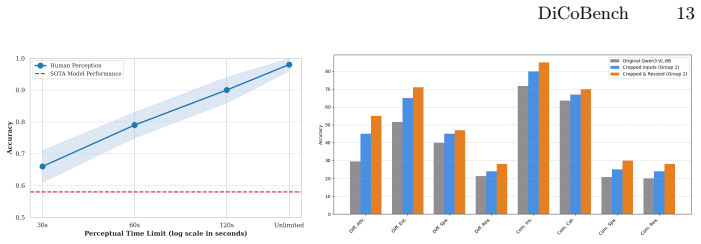
DiCoBench consists of 765 high-resolution multi-image samples split into two progressive tracks of differential and commonality visual cues across eight perception tasks. Formulated as multiple-choice questions, it shows that eighteen evaluated MLLMs achieve substantially lower accuracy than humans at 98.3 percent, with top models struggling most on micro-scale detail capture. This gap is presented as evidence that current models cannot yet perform autonomous perception of implicit cues in high-resolution settings.
What carries the argument
DiCoBench benchmark with its Differential Visual Cues and Commonality Visual Cues tracks, using high-resolution inputs and multiple-choice questions to isolate autonomous cross-image perception.
If this is right
- MLLMs require targeted advances to capture micro-scale details across multiple high-resolution images.
- The benchmark supplies a standardized test for measuring progress in autonomous multi-image perception.
- Future models will need mechanisms that compare implicit cues between images without external prompts.
- Performance on DiCoBench can serve as an indicator of readiness for tasks demanding cross-image detail analysis.
Where Pith is reading between the lines
- Similar gaps may appear in single-image high-resolution settings if tested with the same implicit-cue constraints.
- Training regimes that emphasize cross-image comparison without text hints could narrow the observed gap.
- The two-track design implies that commonality detection and difference detection may expose distinct model weaknesses.
Load-bearing premise
The 765 samples were curated to test autonomous perception of implicit visual cues without textual or resolution biases, and the multiple-choice format fully removes evaluation metric bias.
What would settle it
Demonstrating that a model reaches near 98.3 percent accuracy on the benchmark or finding unintended textual cues in the samples that guide correct answers would undermine the reported performance gap.
Figures




read the original abstract
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive fine-grained perception capabilities. However, existing benchmarks predominantly rely on explicit textual cues or low-resolution inputs, failing to evaluate a model's ability to autonomously perceive implicit visual cues in high-resolution. To bridge this gap, we introduce DiCoBench, a comprehensive, multi-image high-resolution benchmark designed for cross-image fine-grained perception. DiCoBench consists of 765 meticulously curated samples categorized into two progressive tracks: Differential Visual Cues and Commonality Visual Cues, covering 8 distinct perception tasks. By formulating the benchmark as a multiple-choice question task and utilizing high-resolution imagery (approaching 2K), we eliminate evaluation metric bias and pose a substantial challenge to current state-of-the-art MLLMs. Our extensive evaluation of 18 diverse MLLMs reveals a striking performance gap compared to human accuracy (98.3\%), with top-performing models struggling significantly with micro-scale detail capture. We believe DiCoBench will serve as a challenging testbed to drive future research in autonomous, high-resolution multi-image perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiCoBench, a benchmark of 765 high-resolution (~2K) multi-image samples divided into Differential Visual Cues and Commonality Visual Cues tracks across 8 perception tasks. Formulated as multiple-choice questions, it evaluates 18 MLLMs and reports a large gap to human performance (98.3%), attributing the gap to models' difficulty with autonomous perception of implicit micro-scale visual cues.
Significance. If the curation process can be shown to avoid selection biases and textual/resolution artifacts, DiCoBench would offer a useful addition to existing MLLM benchmarks by targeting implicit cross-image cues at high resolution. The scale of the evaluation (18 models) and the explicit human baseline provide a concrete starting point for future work on fine-grained multi-image perception.
major comments (3)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): The central claim of a 'striking performance gap' between models and the 98.3% human baseline depends on the 765 samples genuinely testing implicit cue perception without curation artifacts. However, the manuscript provides no description of source image selection criteria, filtering steps, annotation protocol, inter-annotator agreement, or controls against textual leakage and option imbalance.
- [§4] §4 (Experiments): No statistical tests, confidence intervals, or per-task error analysis are reported for the model results, and the criteria used to select the 18 MLLMs are not stated. These omissions make it impossible to assess whether the reported gap is robust or could be explained by sampling variance or model choice.
- [Human evaluation] Human evaluation paragraph: The 98.3% human accuracy figure is presented without the number of annotators, their expertise level, agreement statistics, or the exact protocol used to obtain the baseline, rendering the model-human comparison difficult to interpret.
minor comments (2)
- [§3] A summary table listing the 8 tasks, their distribution across the two tracks, and sample counts per task would improve readability of the benchmark description.
- [Abstract] The abstract states 'approaching 2K' resolution; the exact pixel dimensions or range used for the images should be stated explicitly in the benchmark section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on DiCoBench. We address each major comment point by point below. We will revise the manuscript to incorporate additional details and analyses where the comments identify omissions, thereby improving the transparency and rigor of the benchmark presentation.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): The central claim of a 'striking performance gap' between models and the 98.3% human baseline depends on the 765 samples genuinely testing implicit cue perception without curation artifacts. However, the manuscript provides no description of source image selection criteria, filtering steps, annotation protocol, inter-annotator agreement, or controls against textual leakage and option imbalance.
Authors: We agree that explicit documentation of the curation process is required to substantiate the absence of artifacts. In the revised manuscript we will expand §3 with a dedicated subsection detailing source image selection criteria, filtering steps, the full annotation protocol, inter-annotator agreement statistics, and the specific controls applied against textual leakage and option imbalance. These additions will directly support the claim that the samples evaluate implicit cross-image cue perception. revision: yes
-
Referee: [§4] §4 (Experiments): No statistical tests, confidence intervals, or per-task error analysis are reported for the model results, and the criteria used to select the 18 MLLMs are not stated. These omissions make it impossible to assess whether the reported gap is robust or could be explained by sampling variance or model choice.
Authors: We concur that statistical rigor and transparency in model selection strengthen the evaluation. The revised §4 will include appropriate statistical tests, confidence intervals around reported accuracies, and a per-task error breakdown. We will also state the explicit selection criteria for the 18 MLLMs, emphasizing architectural diversity and coverage of leading open- and closed-source models. revision: yes
-
Referee: [Human evaluation] Human evaluation paragraph: The 98.3% human accuracy figure is presented without the number of annotators, their expertise level, agreement statistics, or the exact protocol used to obtain the baseline, rendering the model-human comparison difficult to interpret.
Authors: We acknowledge that additional information is needed to interpret the human baseline. In the revised manuscript we will expand the human-evaluation paragraph to report the number of annotators, their expertise level, inter-annotator agreement statistics, and the precise protocol followed to obtain the 98.3% figure. revision: yes
Circularity Check
No circularity: empirical benchmark without derivations or fitted predictions
full rationale
The paper introduces DiCoBench as a new dataset of 765 curated samples for evaluating MLLMs on multi-image perception tasks. The abstract and provided text contain no equations, parameter fitting, self-citations used as load-bearing premises, or any derivation chain. Claims about performance gaps (e.g., models vs. 98.3% human accuracy) are direct empirical results from running models on the benchmark, not quantities that reduce to the curation process by construction. No steps match the enumerated circularity patterns. This is a standard empirical contribution with independent content in the benchmark design and evaluation protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-resolution multi-image inputs and multiple-choice format are appropriate and unbiased for measuring autonomous fine-grained perception.
Reference graph
Works this paper leans on
-
[1]
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., Wu, C., Tan, H., Li, C., Yang, J., Yu, J., Wang, X., Qin, B., Wang, Y., Yan, Z., Feng, Z., Liu, Z., Li, B., Deng, J.: Llava-onevision-1.5: Fully open framework for democratized multimodal training (2025),https://arxiv. org/abs/2509.23661
Pith/arXiv arXiv 2025
-
[2]
Advances in Neural Information Processing Systems37, 107795– 107829 (2024)
Awal, R., Ahmadi, S., Zhang, L., Agrawal, A.: Vismin: Visual minimal-change understanding. Advances in Neural Information Processing Systems37, 107795– 107829 (2024)
2024
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
Pith/arXiv arXiv 2025
-
[5]
Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal modelswith open-source suites.ScienceChina InformationSciences67(12),220101 (2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Di, Z., Shi, J., Fan, Y., Tan, H., Black, A., Collomosse, J., Liu, Y.: Difftell: A high-quality dataset for describing image manipulation changes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24580–24590 (2025)
2025
-
[7]
arXiv preprint arXiv:2509.17040 (2025)
Du, H., Zhang, J., Nan, G., Deng, W., Chen, Z., Zhang, C., Xiao, W., Huang, S., Pan, Y., Qi, T., Leng, S.: From easy to hard: The mir benchmark for progressive interleaved multi-image reasoning. arXiv preprint arXiv:2509.17040 (2025)
arXiv 2025
-
[8]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al.: Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11198–11201 (2024)
2024
-
[9]
arXiv preprint arXiv:2404.12390 (2024)
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. arXiv preprint arXiv:2404.12390 (2024)
Pith/arXiv arXiv 2024
-
[10]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, 16 G
Guo, Z., Sun, J., Wang, T.J.J., Radman, A., Pehlivan, S., Cao, M., Laaksonen, J.: Learning to describe implicit changes: Noise-robust pre-training for image dif- ference captioning. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, 16 G. Li and Y. Peng V. (eds.) Findings of the Association for Computational Linguistics: EMNLP
-
[11]
pp. 10125–10145. Association for Computational Linguistics, Suzhou, China (Nov 2025).https://doi.org/10.18653/v1/2025.findings-emnlp.537,https: //aclanthology.org/2025.findings-emnlp.537/
-
[12]
Hong, J., Zhao, C., Zhu, C., Lu, W., Xu, G., Yu, X.: Deepeyesv2: Toward agentic multimodal model (2026),https://arxiv.org/abs/2511.05271
Pith/arXiv arXiv 2026
-
[13]
In: Proceedings of the Asian Conference on Computer Vision
Hu, E., Guo, L., Yue, T., Zhao, Z., Xue, S., Liu, J.: Onediff: A generalist model for image difference captioning. In: Proceedings of the Asian Conference on Computer Vision. pp. 2439–2455 (2024)
2024
-
[14]
arXiv preprint arXiv:1808.10584 (2018)
Jhamtani, H., Berg-Kirkpatrick, T.: Learning to describe differences between pairs of similar images. arXiv preprint arXiv:1808.10584 (2018)
Pith/arXiv arXiv 2018
-
[15]
Advances in Neural Information Processing Systems37, 28798–28827 (2024)
Kil, J., Mai, Z., Lee, J., Chowdhury, A., Wang, Z., Cheng, K., Wang, L., Liu, Y., Chao, W.L.H.: Mllm-compbench: A comparative reasoning benchmark for multi- modal llms. Advances in Neural Information Processing Systems37, 28798–28827 (2024)
2024
-
[16]
arXiv preprint arXiv:2509.07969 (2025)
Lai, X., Li, J., Li, W., Liu, T., Li, T., Zhao, H.: Mini-o3: Scaling up reasoning patterns and interaction turns for visual search. arXiv preprint arXiv:2509.07969 (2025)
Pith/arXiv arXiv 2025
-
[17]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, J., Wu, M., Jin, Z., Chen, H., Ji, J., Sun, X., Cao, L., Ji, R.: Mihbench: Bench- marking and mitigating multi-image hallucinations in multimodal large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 3143–3152 (2025)
2025
-
[18]
Li, Y., Tu, Y., Li, L., Su, L., Huang, Q.: Change entity-guided heterogeneous repre- sentation disentangling for change captioning. In: Che, W., Nabende, J., Shutova, E.,Pilehvar,M.T.(eds.)FindingsoftheAssociationforComputationalLinguistics: ACL 2025. pp. 17050–17060. Association for Computational Linguistics, Vienna, Austria (Jul 2025).https://doi.org/10...
-
[19]
arXiv preprint arXiv:2501.05767 (2025)
Li, Y., Huang, H., Chen, C., Huang, K., Huang, C., Guo, Z., Liu, Z., Xu, J., Li, Y., Li, R., et al.: Migician: Revealing the magic of free-form multi-image grounding in multimodal large language models. arXiv preprint arXiv:2501.05767 (2025)
arXiv 2025
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, Y., Hou, S., Hou, S., Du, J., Meng, S., Huang, Y.: Omnidiff: A comprehensive benchmark for fine-grained image difference captioning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21440–21449 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Park, D.H., Darrell, T., Rohrbach, A.: Robust change captioning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4624–4633 (2019)
2019
-
[22]
arXiv preprint arXiv:2404.18532 (2024)
Song, D., Chen, S., Chen, G.H., Yu, F., Wan, X., Wang, B.: Milebench: Bench- marking mllms in long context. arXiv preprint arXiv:2404.18532 (2024)
arXiv 2024
-
[23]
In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Tan, H., Dernoncourt, F., Lin, Z., Bui, T., Bansal, M.: Expressing visual relation- ships via language. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 1873–1883 (2019)
2019
-
[24]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-Fekete, R., Feng, A., Sachdeva, N., Cole...
Pith/arXiv arXiv 2025
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tong,T.C.,He,S.,Shao,Z.,Yeung,D.Y.:G-veval:Aversatilemetricforevaluating image and video captions using gpt-4o. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7419–7427 (2025)
2025
-
[26]
arXiv preprint arXiv:2406.09411 (2024)
Wang, F., Fu, X., Huang, J.Y., Li, Z., Liu, Q., Liu, X., Ma, M.D., Xu, N., Zhou, W., Zhang, K., et al.: Muirbench: A comprehensive benchmark for robust multi-image understanding. arXiv preprint arXiv:2406.09411 (2024)
Pith/arXiv arXiv 2024
-
[27]
arXiv preprint arXiv:2507.07999 (2025)
Wang, H., Li, X., Huang, Z., Wang, A., Wang, J., Zhang, T., Zheng, J., Bai, S., Kang, Z., Feng, J., et al.: Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology. arXiv preprint arXiv:2507.07999 (2025)
arXiv 2025
-
[28]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[29]
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hou, Z., Hao, H., Zhang, T., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He,...
Pith/arXiv arXiv 2025
-
[30]
In: AAAI
Wang, W., Ding, L., Zeng, M., Zhou, X., Shen, L., Luo, Y., Yu, W., Tao, D.: Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. In: AAAI. vol. 39, pp. 7907–7915 (2025)
2025
-
[31]
Wei, K., Hu, B., Cao, J., Chen, X., Lu, Z., Xia, W., Xu, W., Wu, J., He, J., Jia, M., et al.:m3−verse: A" spot the difference" challenge for large multimodal models. arXiv preprint arXiv:2512.18735 (2025)
Pith/arXiv arXiv 2025
-
[32]
In: CVPR
Wu, P., Xie, S.: V*: Guided visual search as a core mechanism in multimodal llms. In: CVPR. pp. 13084–13094 (2024)
2024
-
[33]
In: CVPR (2024)
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal under- standing and reasoning benchmark for expert agi. In: CVPR (2024)
2024
-
[34]
In: ACM Multimedia 2024 (2024),https://openreview.net/forum?id=eiGs5VCsYM
Zhang, X., Wen, H., Wu, J., Qin, P., Xue’, H., Nie, L.: Differential-perceptive and retrieval-augmented MLLM for change captioning. In: ACM Multimedia 2024 (2024),https://openreview.net/forum?id=eiGs5VCsYM
2024
-
[35]
Zhang, Y.F., Lu, X., Yin, S., Fu, C., Chen, W., Hu, X., Wen, B., Jiang, K., Liu, C., Zhang, T., Fan, H., Chen, K., Chen, J., Ding, H., Tang, K., Zhang, Z., Wang, L., Yang, F., Gao, T., Zhou, G.: Thyme: Think beyond images (2025),https: //arxiv.org/abs/2508.11630
Pith/arXiv arXiv 2025
-
[36]
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., Yu, X.: Deepeyes: Incentivizing" thinking with images" via reinforcement learning. arXiv preprint arXiv:2505.14362 (2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.