Information-Theoretic Classifier-Free Guidance with Adaptive Schedule Optimization
Pith reviewed 2026-06-26 01:05 UTC · model grok-4.3
The pith
An information-theoretic framework optimizes classifier-free guidance schedules in diffusion models to better balance consistency and coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
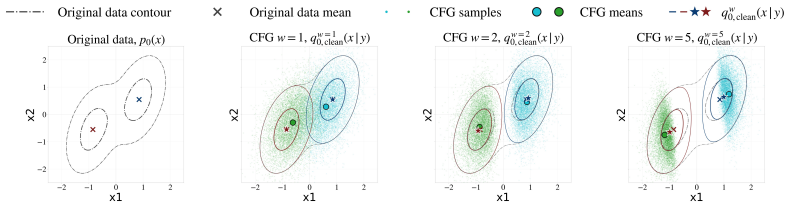
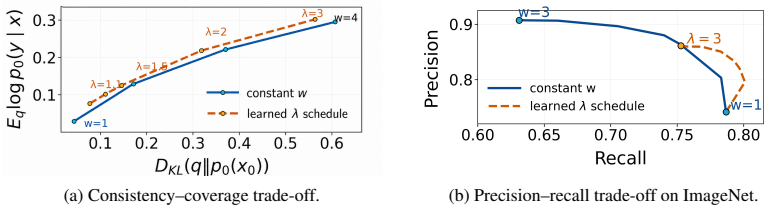
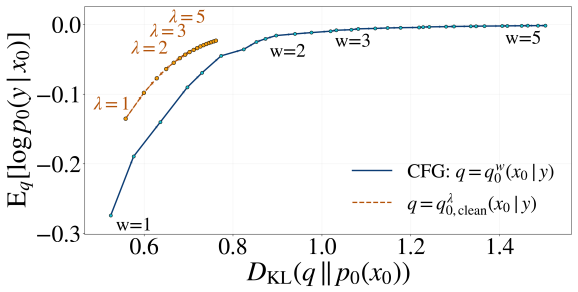
We propose an information-theoretic framework for CFG schedule optimization. Our approach uses a clean endpoint reference to specify the desired consistency-coverage trade-off, while optimizing the actual distribution induced by the guided sampler toward this reference. We derive trajectory-level formulas to estimate the objective from samples and score evaluations, avoiding explicit density estimation. On ImageNet-512 with EDM-XXL and COCO with SD-XL, the learned schedules achieve competitive or improved trade-offs over constant guidance and allocate guidance selectively across noise levels.
What carries the argument
Information-theoretic objective that matches the guided sampler's induced distribution to a clean-endpoint reference consistency-coverage trade-off, estimated via trajectory-level formulas from samples and score evaluations.
If this is right
- Learned schedules achieve competitive or improved trade-offs over constant guidance on ImageNet-512 with EDM-XXL and COCO with SD-XL.
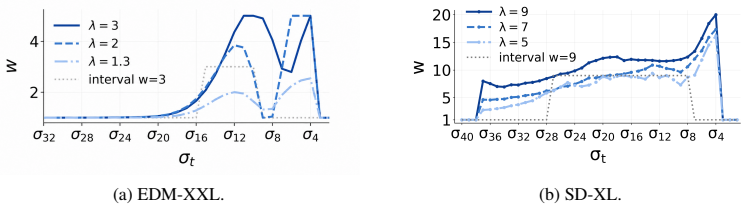
- Guidance weights are allocated selectively across noise levels instead of remaining constant.
- The objective can be estimated from samples and score evaluations without explicit density estimation.
- The framework directly targets the distribution induced by the full guided sampler rather than a per-step tilt.
Where Pith is reading between the lines
- The selective allocation pattern may indicate which parts of the denoising process most benefit from strong conditioning.
- The same reference-based objective could be applied to other conditional generation domains such as video or 3D.
- If the trajectory formulas remain tractable, the method offers a way to adapt guidance without retraining the underlying diffusion model.
Load-bearing premise
The actual distribution induced by the guided sampler can be optimized toward a clean-endpoint reference consistency-coverage trade-off using trajectory-level formulas estimated from samples and score evaluations.
What would settle it
Running the learned schedules on EDM-XXL for ImageNet-512 and finding that they produce strictly worse consistency-coverage metrics than the best constant guidance schedule would falsify the optimization claim.
Figures



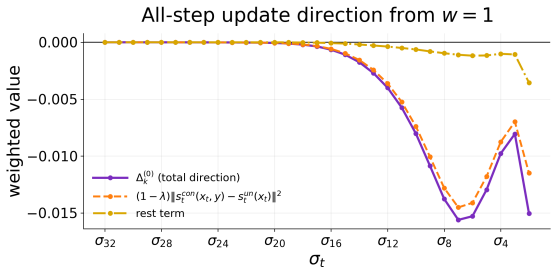
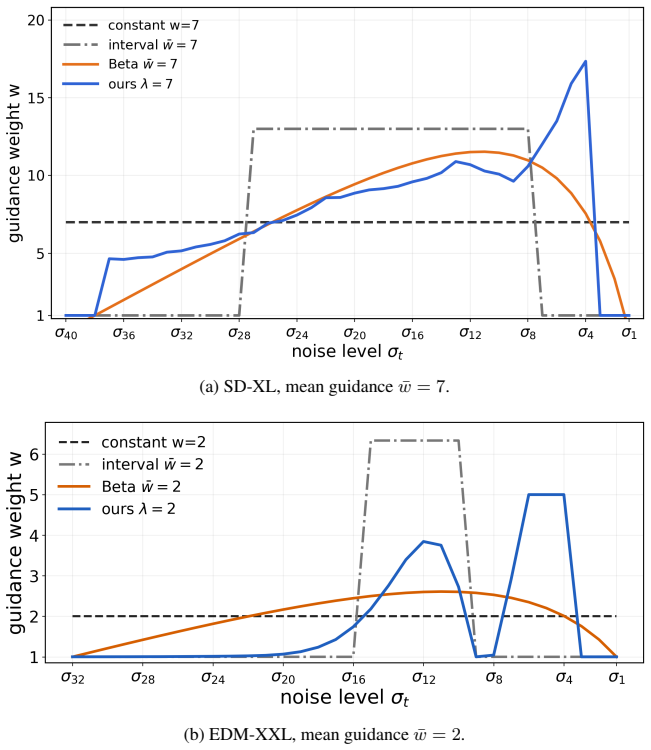


read the original abstract
Diffusion models have achieved strong performance in image, text-to-image, and video generation, where conditional generation is often controlled by classifier-free guidance (CFG). CFG improves condition consistency by increasing a guidance weight, but stronger guidance typically reduces diversity and distributional coverage. It remains unclear how this consistency-coverage trade-off should be controlled across the reverse trajectory, since the distribution induced by CFG is not simply the fixed-time tilted distribution given by the guided score field. To address this issue, we propose an information-theoretic framework for CFG schedule optimization. Our approach uses a clean endpoint reference to specify the desired consistency-coverage trade-off, while optimizing the actual distribution induced by the guided sampler toward this reference. We derive trajectory-level formulas to estimate the objective from samples and score evaluations, avoiding explicit density estimation. On ImageNet-512 with EDM-XXL and COCO with SD-XL, the learned schedules achieve competitive or improved trade-offs over constant guidance and allocate guidance selectively across noise levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an information-theoretic framework for optimizing classifier-free guidance (CFG) schedules in diffusion models. It specifies a desired consistency-coverage trade-off via a clean-endpoint reference distribution and derives trajectory-level formulas to optimize the actual distribution induced by the guided sampler toward this reference. These formulas are estimated from samples and score evaluations without explicit density estimation. Experiments on ImageNet-512 using EDM-XXL and on COCO using SD-XL report that the learned adaptive schedules achieve competitive or improved trade-offs relative to constant guidance while allocating guidance selectively across noise levels.
Significance. If the central derivation and empirical results hold, the work provides a principled, adaptive alternative to fixed-weight CFG that is widely used in conditional diffusion models. The trajectory-level estimation approach, which avoids explicit density estimation, is a notable technical contribution if the formulas are shown to be non-circular. The selective allocation of guidance across noise levels could improve practical generation quality in image and text-to-image tasks.
major comments (1)
- [Abstract / §3] The abstract states that the objective is optimized toward a clean-endpoint reference that encodes the desired consistency-coverage trade-off. Without the explicit trajectory-level formulas (presumably in §3 or §4), it remains unclear whether the resulting objective is independent of the reference or reduces to a fitted quantity by construction; a concrete counter-example or independence proof would address this.
minor comments (2)
- [Abstract] The abstract claims 'competitive or improved trade-offs' on ImageNet-512 and COCO; the main text should report the precise metrics (e.g., FID, CLIP score, coverage) and the exact constant-guidance baselines used for comparison.
- [§3] Notation for the trajectory-level estimators (samples vs. score evaluations) should be introduced with explicit definitions to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / §3] The abstract states that the objective is optimized toward a clean-endpoint reference that encodes the desired consistency-coverage trade-off. Without the explicit trajectory-level formulas (presumably in §3 or §4), it remains unclear whether the resulting objective is independent of the reference or reduces to a fitted quantity by construction; a concrete counter-example or independence proof would address this.
Authors: The objective is the KL divergence between the law of trajectories produced by the CFG-guided reverse process and the fixed clean-endpoint reference distribution chosen to encode the target consistency-coverage trade-off. The reference is specified independently of the schedule (e.g., as a convex combination of conditional and unconditional endpoint measures). Section 3 derives the trajectory-level expression for this KL by applying the chain rule for the diffusion path measure and substituting the guided score; the resulting estimator depends only on samples drawn from the guided process and on score evaluations, without ever requiring the reference density. Because the reference is held fixed while the schedule is varied, the objective is not tautological. A simple counter-example is the case in which the reference coincides with the unconditional endpoint distribution: the derived objective is then minimized by the zero-guidance schedule, which is recovered by the optimization procedure. We will insert a short paragraph containing this argument and the counter-example into the revised §3. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives trajectory-level formulas for an information-theoretic objective estimated from samples and score evaluations, then optimizes CFG schedules on EDM-XXL and SD-XL models with empirical results on ImageNet-512 and COCO. The clean-endpoint reference is an explicit design choice specifying the target trade-off rather than a fitted quantity renamed as prediction. No self-definitional reductions, load-bearing self-citations, or ansatz smuggling appear in the provided description or abstract. The central claims rest on independent empirical outcomes of the optimization procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inProceedings of the 32nd International Conference on Machine Learning, pp. 2256–2265, 2015
2015
-
[2]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020
2020
-
[3]
Generative modeling by estimating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[4]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021
2021
-
[5]
High-resolution image synthe- sis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthe- sis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695, 2022
2022
-
[6]
SDXL: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rom- bach, “SDXL: Improving latent diffusion models for high-resolution image synthesis,” in International Conference on Learning Representations, 2024
2024
-
[7]
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models,
J. Zhang, Q. Huang, J. Liu, X. Guo, and D. Huang, “Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23464–23473, 2025
2025
-
[8]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, S. K. S. Ghasemipour, R. Gon- tijo Lopes, B. K. Ayan, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding,” inAdvances in Neural Information Processing Systems, vol. 35, pp. 36479–36494, 2022
2022
-
[9]
Hierarchical text-conditional image generation with CLIP latents,
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,”arXiv preprint arXiv:2204.06125, 2022
Pith/arXiv arXiv 2022
-
[10]
Video diffusion models,
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,” inAdvances in Neural Information Processing Systems, vol. 35, pp. 8633–8646, 2022
2022
-
[11]
Imagen video: High definition video generation with diffusion models,
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet, and T. Salimans, “Imagen video: High definition video generation with diffusion models,”arXiv preprint arXiv:2210.02303, 2022
Pith/arXiv arXiv 2022
-
[12]
Structured denoising diffusion models in discrete state-spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. van den Berg, “Structured denoising diffusion models in discrete state-spaces,” inAdvances in Neural Information Processing Systems, vol. 34, pp. 17981–17993, 2021
2021
-
[13]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” 2022
2022
-
[14]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems, vol. 34, pp. 8780–8794, 2021
2021
-
[15]
T. Kynkäänniemi, M. Aittala, T. Karras, S. Laine, T. Aila, and J. Lehtinen, “Applying guidance in a limited interval improves sample and distribution quality in diffusion models,”arXiv preprint arXiv:2404.07724, 2024
arXiv 2024
-
[16]
Classifier-free guidance with adaptive scaling,
D. Malarz, A. Kasymov, M. Zi˛ eba, J. Tabor, and P. Spurek, “Classifier-free guidance with adaptive scaling,” 2025
2025
-
[17]
Learn to guide your diffusion model,
A. Galashov, V . De Bortoli, J. S. Guntupalli, G.-H. Zhou, K. Murphy, A. Gretton, and A. Doucet, “Learn to guide your diffusion model,”arXiv preprint arXiv:2510.00815, 2025
arXiv 2025
-
[18]
Stage-wise dynamics of classifier-free guidance in diffusion models,
C. Jin, Q. Shi, and Y . Gu, “Stage-wise dynamics of classifier-free guidance in diffusion models,” arXiv preprint arXiv:2509.22007, 2025. 11
arXiv 2025
-
[19]
Guiding a diffusion model with a bad version of itself,
T. Karras, M. Aittala, T. Kynkäänniemi, J. Lehtinen, T. Aila, and S. Laine, “Guiding a diffusion model with a bad version of itself,”Advances in Neural Information Processing Systems, vol. 37, pp. 52996–53021, 2024
2024
-
[20]
Classifier-free guidance is a predictor-corrector,
A. Bradley and P. Nakkiran, “Classifier-free guidance is a predictor-corrector,” 2024
2024
-
[21]
What does guidance do? a fine- grained analysis in a simple setting,
M. Chidambaram, K. Gatmiry, S. Chen, H. Lee, and J. Lu, “What does guidance do? a fine- grained analysis in a simple setting,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[22]
Conditional diffusion models with classifier-free gibbs-like guidance,
B. Moufad, Y . Janati, A. Durmus, A. Ghorbel, E. Moulines, and J. Olsson, “Conditional diffusion models with classifier-free gibbs-like guidance,”arXiv preprint arXiv:2505.21101, 2025
arXiv 2025
-
[23]
T. M. Cover and J. A. Thomas,Elements of Information Theory. Wiley, 2006
2006
-
[24]
Maximum likelihood training of score-based diffusion models,
Y . Song, C. Durkan, I. Murray, and S. Ermon, “Maximum likelihood training of score-based diffusion models,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[25]
A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines,
M. F. Hutchinson, “A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines,”Communications in Statistics - Simulation and Computation, vol. 19, no. 2, pp. 433–450, 1990
1990
-
[26]
FFJORD: Free-form continuous dynamics for scalable reversible generative models,
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud, “FFJORD: Free-form continuous dynamics for scalable reversible generative models,” inInternational Conference on Learning Representations, 2019
2019
-
[27]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” inAdvances in Neural Information Processing Systems, vol. 35, pp. 26565– 26577, 2022
2022
-
[28]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[29]
Improved precision and recall metric for assessing generative models,
T. Kynkäänniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila, “Improved precision and recall metric for assessing generative models,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[30]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning, 2021
2021
-
[31]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[32]
Variational diffusion models,
D. P. Kingma, T. Salimans, B. Poole, and J. Ho, “Variational diffusion models,” inAdvances in Neural Information Processing Systems, vol. 34, pp. 21696–21707, 2021
2021
-
[33]
Perception prioritized training of diffusion models,
J. Choi, J. Lee, C. Shin, S. Kim, H. J. Kim, and S. Yoon, “Perception prioritized training of diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11472–11481, 2022
2022
-
[34]
Efficient diffusion training via min-snr weighting strategy,
T. Hang, S. Gu, C. Li, J. Bao, D. Chen, H. Hu, X. Geng, and B. Guo, “Efficient diffusion training via min-snr weighting strategy,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7441–7451, 2023
2023
-
[35]
Critical windows: Non-asymptotic theory for feature emergence in diffusion models,
M. Li and S. Chen, “Critical windows: Non-asymptotic theory for feature emergence in diffusion models,” inProceedings of the 41st International Conference on Machine Learning, vol. 235 of Proceedings of Machine Learning Research, pp. 27474–27498, PMLR, 2024
2024
-
[36]
Spontaneous symmetry breaking in generative diffusion models,
G. Raya and L. Ambrogioni, “Spontaneous symmetry breaking in generative diffusion models,” inAdvances in Neural Information Processing Systems, 2023. 12
2023
-
[37]
Dynamical regimes of diffusion models,
G. Biroli, T. Bonnaire, V . de Bortoli, and M. Mézard, “Dynamical regimes of diffusion models,” Nature Communications, vol. 15, no. 1, p. 9957, 2024
2024
-
[38]
Measuring semantic information production in generative diffusion models,
F. Handke, F. Koulischer, G. Raya, and L. Ambrogioni, “Measuring semantic information production in generative diffusion models,” inICLR 2025 Workshop on Deep Generative Models in Machine Learning: Theory, Principle and Efficacy, 2025
2025
-
[39]
Emergence and evolution of interpretable concepts in diffusion models,
B. Tinaz, Z. Fabian, and M. Soltanolkotabi, “Emergence and evolution of interpretable concepts in diffusion models,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[40]
Revelio: Interpreting and leveraging semantic information in diffusion models,
D. Kim, X. Thomas, and D. Ghadiyaram, “Revelio: Interpreting and leveraging semantic information in diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[41]
Information-theoretic diffusion,
X. Kong, R. Brekelmans, and G. Ver Steeg, “Information-theoretic diffusion,” inInternational Conference on Learning Representations, 2023
2023
-
[42]
A variational perspective on accelerated methods in optimization,
A. Wibisono, A. C. Wilson, and M. I. Jordan, “A variational perspective on accelerated methods in optimization,”proceedings of the National Academy of Sciences, vol. 113, no. 47, pp. E7351– E7358, 2016. 13 A Limitations and Broader Impacts Limitations.Our method is developed under the VE probability-flow formulation and relies on score evaluations from pr...
2016
-
[43]
A man is in a kitchen making pizzas
Compared with w= 1 , stronger guidance improves class consistency and visual sharpness. Compared with constant w= 3 , the optimized schedule preserves similar semantic consistency while maintaining more seed-level variation in pose, background, and composition. Figure 12: Seed-matched qualitative comparison on the COCO prompt “A man is in a kitchen making...
2025
-
[44]
Justification: The paper does not involve human subjects, user studies, or crowdsourced data collection
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.