TRACE: State-Aware Query Processing over Temporal Evidence Graphs for Conversational Data
Pith reviewed 2026-07-02 13:47 UTC · model grok-4.3
The pith
TRACE models conversations as hierarchical temporal evidence graphs with validity annotations to enable state-aware query processing over evolving data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
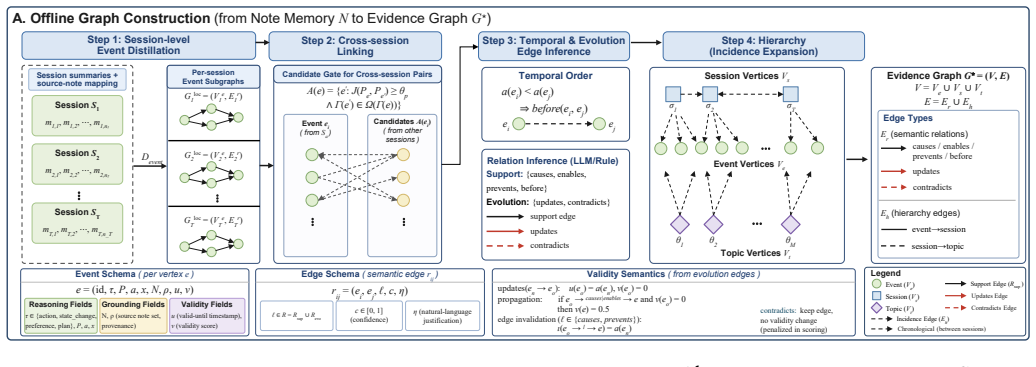
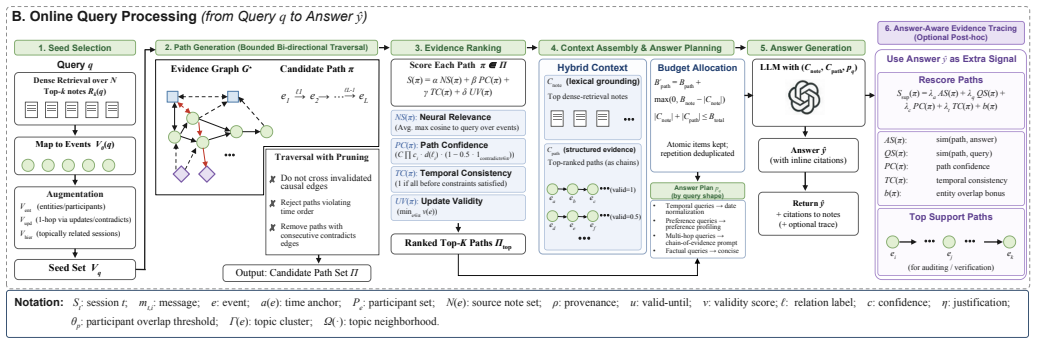
TRACE is a query processing framework that represents conversational histories as hierarchical graphs enriched with typed temporal, causal, update, and contradiction relations plus validity annotations, enabling bounded, state-aware reasoning by separating lexical recall from evidence reconstruction via a hybrid vector-graph search that generates validity-aware support paths.
What carries the argument
The temporal evidence graph: a hierarchical structure over events, sessions, and topics carrying typed relations and validity annotations that track which facts remain current.
If this is right
- Improves temporal and multi-hop reasoning on long-conversation QA benchmarks.
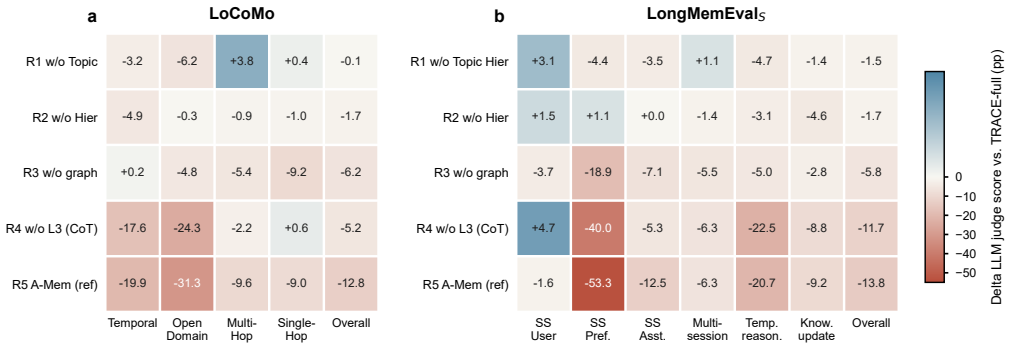
- Hierarchy, update-aware seeding, and path-grounded evidence each contribute measurably, as shown by ablations.
- Validity annotations let obsolete facts remain accessible for historical queries while being discounted for current-state answers.
- Bounded query-time reasoning over long histories is achieved by separating lexical recall from evidence reconstruction.
Where Pith is reading between the lines
- The same graph-plus-validity design could be applied to other evolving personal or institutional records such as medical timelines or legal case files.
- Performance will be sensitive to the quality of the upstream relation-extraction and validity-labeling steps, suggesting a natural next target for improvement.
- Explicit modeling of contradictions and updates may reduce drift in long-running agents even when the downstream generator is unchanged.
Load-bearing premise
Conversations can be reliably decomposed into a hierarchical graph with accurately typed temporal, causal, update, and contradiction relations and validity annotations without substantial extraction errors that would invalidate the state-aware paths.
What would settle it
A controlled test on a long-conversation QA benchmark in which the automatic graph-construction step is replaced by noisy or randomly typed relations, after which TRACE shows no improvement or clear degradation relative to pure vector baselines.
Figures
read the original abstract
Conversational data is increasingly used as a persistent source of user state for long-running assistants and AI agents. However, querying this data remains challenging because conversations naturally evolve: plans are revised, preferences change, and later messages frequently supersede or contradict earlier information. Existing long-memory pipelines largely treat memories as independent text or vector objects. This approach often retrieves semantically similar but stale evidence, offering limited support for state-aware reasoning. To address this problem, we present TRACE, a query processing framework over temporal evidence graphs for evolving conversational data. TRACE models conversations as a hierarchical graph spanning events, sessions, and topics, enriched with typed temporal, causal, update, and contradiction relations. Crucially, the framework maintains validity annotations so obsolete facts remain accessible for historical queries but are discounted for current-state answers. At query time, TRACE combines vector-based note retrieval with graph-guided evidence search, generating validity-aware support paths and a hybrid context for answer generation. This design separates lexical recall from evidence reconstruction, enabling bounded query-time reasoning over long conversational histories. Experiments on long-conversation query-answering (QA) benchmarks show that TRACE improves temporal and multi-hop reasoning, with ablations highlighting the importance of hierarchy, update-aware seeding, and path-grounded evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a query processing framework over temporal evidence graphs for evolving conversational data. Conversations are modeled as hierarchical graphs (events/sessions/topics) with typed temporal, causal, update, and contradiction relations plus validity annotations. At query time, vector-based note retrieval is combined with graph-guided search to produce validity-aware support paths and hybrid context for answer generation. The design claims to enable bounded reasoning over long histories and is evaluated on long-conversation QA benchmarks, with reported gains in temporal and multi-hop reasoning plus ablations on hierarchy, update-aware seeding, and path-grounded evidence.
Significance. If the empirical gains hold and graph construction proves reliable, the separation of lexical recall from evidence reconstruction could meaningfully advance state-aware reasoning in long-running conversational agents, addressing the staleness problem in existing memory pipelines. The validity annotations for historical vs. current-state queries represent a practical contribution.
major comments (2)
- [§3] §3 (Graph Construction and Relation Typing): The central claim that state-aware paths and validity discounting improve QA rests on accurate automatic extraction of typed relations and validity labels, yet no error analysis, inter-annotator agreement, or validation metrics against gold decompositions are provided; non-negligible extraction errors would directly corrupt support paths and undermine benchmark gains.
- [Experiments] Experiments section (benchmark results and ablations): The abstract and methods assert improvements on temporal/multi-hop QA benchmarks and highlight specific ablations, but without quantitative tables, baseline comparisons, dataset statistics, or error bars, it is impossible to assess whether gains are attributable to the proposed hierarchy and path-grounding or to other factors.
minor comments (2)
- [Abstract] The abstract is unusually long and contains forward references to experimental outcomes without any supporting numbers; consider moving quantitative highlights to a dedicated results paragraph.
- [§3.2] Notation for validity annotations and path discounting is introduced without a compact formal definition or pseudocode; a small equation or algorithm box would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of TRACE to advance state-aware reasoning in conversational agents. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Graph Construction and Relation Typing): The central claim that state-aware paths and validity discounting improve QA rests on accurate automatic extraction of typed relations and validity labels, yet no error analysis, inter-annotator agreement, or validation metrics against gold decompositions are provided; non-negligible extraction errors would directly corrupt support paths and undermine benchmark gains.
Authors: We agree that the reliability of automatic relation extraction and validity labeling is central to the framework's claims. The current manuscript does not include quantitative validation of the extraction process. In the revised version, we will add an error analysis subsection under §3 that reports precision and recall on a manually annotated subset of conversations, along with a discussion of how extraction errors propagate to support paths and query results. revision: yes
-
Referee: [Experiments] Experiments section (benchmark results and ablations): The abstract and methods assert improvements on temporal/multi-hop QA benchmarks and highlight specific ablations, but without quantitative tables, baseline comparisons, dataset statistics, or error bars, it is impossible to assess whether gains are attributable to the proposed hierarchy and path-grounding or to other factors.
Authors: The referee correctly notes that the experimental presentation must enable readers to evaluate the source of reported gains. While the manuscript describes benchmark results and ablations at a high level, we will expand the Experiments section to include full quantitative tables with baseline comparisons, dataset statistics, and error bars computed over multiple runs. These additions will isolate the contributions of hierarchy, update-aware seeding, and path-grounded evidence. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a system framework (TRACE) for state-aware query processing over hierarchical temporal evidence graphs, with claims resting on experimental results and ablations rather than any mathematical derivation chain. No equations, fitted parameters, predictions, or self-citations appear in the abstract or description that would reduce outputs to inputs by construction. The design choices (hierarchy, validity annotations, graph-guided search) are presented as engineering decisions supported by benchmark gains, with no self-definitional, fitted-input, or uniqueness-imported patterns visible. This is the common case of a self-contained applied systems paper whose central claims do not reduce to circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Memorybank: En- hancing large language models with long-term memory,
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “Memorybank: En- hancing large language models with long-term memory,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 17, 2024, pp. 19 724–19 731
2024
-
[2]
Beyond goldfish memory: Long-term open-domain conversation,
J. Xu, A. Szlam, and J. Weston, “Beyond goldfish memory: Long-term open-domain conversation,” inProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), 2022, pp. 5180–5197
2022
-
[3]
Evaluating very long-term conversational memory of llm agents,
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y . Fang, “Evaluating very long-term conversational memory of llm agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 13 851– 13 870
2024
-
[4]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
D. Wu, H. Wang, W. Yu, Y . Zhang, K.-W. Chang, and D. Yu, “Longmemeval: Benchmarking chat assistants on long-term interactive memory,”arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Models and issues in data stream systems,
B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom, “Models and issues in data stream systems,” inProceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, 2002, pp. 1–16
2002
-
[6]
The cql continuous query language: semantic foundations and query execution,
A. Arasu, S. Babu, and J. Widom, “The cql continuous query language: semantic foundations and query execution,”The VLDB Journal, vol. 15, no. 2, pp. 121–142, 2006
2006
-
[7]
A consensus glossary of temporal database concepts,
C. Dyreson, F. Grandi, W. K¨afer, N. Kline, N. Lorentzos, Y . Mitsopoulos, A. Montanari, D. Nonen, E. Peressi, B. Perniciet al., “A consensus glossary of temporal database concepts,”ACM Sigmod Record, vol. 23, no. 1, pp. 52–64, 1994
1994
-
[8]
R. T. Snodgrass,The TSQL2 temporal query language. Springer Science & Business Media, 2012, vol. 330
2012
-
[9]
Access path selection in a relational database management system,
P. G. Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, and T. G. Price, “Access path selection in a relational database management system,” inProceedings of the 1979 ACM SIGMOD international conference on Management of data, 1979, pp. 23–34
1979
-
[10]
The volcano optimizer generator: Exten- sibility and efficient search,
G. Graefe and W. J. McKenna, “The volcano optimizer generator: Exten- sibility and efficient search,” inProceedings of IEEE 9th international conference on data engineering. IEEE, 1993, pp. 209–218
1993
-
[11]
Consistent query answers in inconsistent databases,
M. Arenas, L. Bertossi, and J. Chomicki, “Consistent query answers in inconsistent databases,” inProceedings of the eighteenth ACM SIGMOD- SIGACT-SIGART symposium on Principles of database systems, 1999, pp. 68–79
1999
-
[12]
Why and where: A characterization of data provenance,
P. Buneman, S. Khanna, and T. Wang-Chiew, “Why and where: A characterization of data provenance,” inInternational conference on database theory. Springer, 2001, pp. 316–330
2001
-
[13]
Provenance semirings,
T. J. Green, G. Karvounarakis, and V . Tannen, “Provenance semirings,” inProceedings of the twenty-sixth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, 2007, pp. 31–40
2007
-
[14]
Data fusion: resolving conflicts from multiple sources,
X. L. Dong, L. Berti-Equille, and D. Srivastava, “Data fusion: resolving conflicts from multiple sources,” inHandbook of Data Quality: Research and Practice. Springer, 2013, pp. 293–318
2013
-
[15]
Truth discovery with multiple conflicting information providers on the web,
X. Yin, J. Han, and P. S. Yu, “Truth discovery with multiple conflicting information providers on the web,” inProceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, 2007, pp. 1048–1052
2007
-
[16]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2020, pp. 6769–6781
2020
-
[17]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[18]
Timer4: Time-aware retrieval-augmented large language models for temporal knowledge graph question answering,
X. Qian, Y . Zhang, Y . Zhao, B. Zhou, X. Sui, L. Zhang, and K. Song, “Timer4: Time-aware retrieval-augmented large language models for temporal knowledge graph question answering,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 6942–6952
2024
-
[19]
Graphreader: Building graph-based agent to enhance long-context abilities of large language models,
S. Li, Y . He, H. Guo, X. Bu, G. Bai, J. Liu, J. Liu, X. Qu, Y . Li, W. Ouyanget al., “Graphreader: Building graph-based agent to enhance long-context abilities of large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 12 758–12 786
2024
-
[20]
Blinks: ranked keyword searches on graphs,
H. He, H. Wang, J. Yang, and P. S. Yu, “Blinks: ranked keyword searches on graphs,” inProceedings of the 2007 ACM SIGMOD international conference on Management of data, 2007, pp. 305–316
2007
-
[21]
Keyword search on structured and semi-structured data,
Y . Chen, W. Wang, Z. Liu, and X. Lin, “Keyword search on structured and semi-structured data,” inProceedings of the 2009 ACM SIGMOD International Conference on Management of data, 2009, pp. 1005–1010
2009
-
[22]
Top-k exploration of query candidates for efficient keyword search on graph-shaped (rdf) data,
T. Tran, H. Wang, S. Rudolph, and P. Cimiano, “Top-k exploration of query candidates for efficient keyword search on graph-shaped (rdf) data,” in2009 IEEE 25th International Conference on Data Engineering. IEEE, 2009, pp. 405–416
2009
-
[23]
Rdf-3x: a risc-style engine for rdf,
T. Neumann and G. Weikum, “Rdf-3x: a risc-style engine for rdf,” Proceedings of the VLDB Endowment, vol. 1, no. 1, pp. 647–659, 2008
2008
-
[24]
gstore: answering sparql queries via subgraph matching,
L. Zou, J. Mo, L. Chen, M. T. ¨Ozsu, and D. Zhao, “gstore: answering sparql queries via subgraph matching,”Proceedings of the VLDB Endowment, vol. 4, no. 8, pp. 482–493, 2011
2011
-
[25]
Querying graphs with data,
L. Libkin, W. Martens, and D. Vrgo ˇc, “Querying graphs with data,” Journal of the ACM (JACM), vol. 63, no. 2, pp. 1–53, 2016
2016
-
[26]
Uldbs: Databases with uncertainty and lineage,
O. Benjelloun, A. D. Sarma, A. Halevy, and J. Widom, “Uldbs: Databases with uncertainty and lineage,” inVLDB, vol. 6, 2006, pp. 953–964
2006
-
[27]
Provenance in databases: Why, how, and where,
J. Cheney, L. Chiticariu, and W.-C. Tan, “Provenance in databases: Why, how, and where,”Foundations and trends in databases, vol. 1, no. 4, pp. 379–474, 2009
2009
-
[28]
Eddies: Continuously adaptive query processing,
R. Avnur and J. M. Hellerstein, “Eddies: Continuously adaptive query processing,” inProceedings of the 2000 ACM SIGMOD international conference on Management of data, 2000, pp. 261–272
2000
-
[29]
Adaptive query processing: A survey,
A. Gounaris, N. W. Paton, A. A. Fernandes, and R. Sakellariou, “Adaptive query processing: A survey,” inBritish National Conference on Databases. Springer, 2002, pp. 11–25
2002
-
[30]
Langmem: Long-term memory for llm agents,
LangChain AI, “Langmem: Long-term memory for llm agents,” 2026, accessed: 2026-06-01. [Online]. Available: https://github.com/langchain- ai/langmem
2026
-
[31]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building production-ready ai agents with scalable long-term memory,” arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
J. Nan, W. Ma, W. Wu, and Y . Chen, “Nemori: Self-organizing agent memory inspired by cognitive science,”arXiv preprint arXiv:2508.03341, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
P. Rasmussen, P. Paliychuk, T. Beauvais, J. Ryan, and D. Chalef, “Zep: a temporal knowledge graph architecture for agent memory,”arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
A-mem: Agentic memory for llm agents,
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang, “A-mem: Agentic memory for llm agents,”Advances in Neural Information Processing Systems, vol. 38, pp. 17 577–17 604, 2026
2026
-
[35]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[36]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
-
[37]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,”Advances in neural information processing systems, vol. 33, pp. 5776–5788, 2020
2020
-
[38]
Dbxplorer: enabling keyword search over relational databases,
S. Agrawal, S. Chaudhuri, and G. Das, “Dbxplorer: enabling keyword search over relational databases,” inProceedings of the 2002 ACM SIGMOD international conference on Management of data, 2002, pp. 627–627
2002
-
[39]
Keyword searching and browsing in databases using banks,
G. Bhalotia, A. Hulgeri, C. Nakhe, S. Chakrabarti, and S. Sudarshan, “Keyword searching and browsing in databases using banks,” inProceed- ings 18th international conference on data engineering. IEEE, 2002, pp. 431–440
2002
-
[40]
Discover: Keyword search in relational databases,
V . Hristidis and Y . Papakonstantinou, “Discover: Keyword search in relational databases,” inVLDB’02: Proceedings of the 28th International Conference on Very Large Databases. Elsevier, 2002, pp. 670–681
2002
-
[41]
Deshpande, Z
A. Deshpande, Z. Ives, and V . Raman,Adaptive query processing. Now Publishers Inc, 2007
2007
-
[42]
Niagaracq: A scalable continuous query system for internet databases,
J. Chen, D. J. DeWitt, F. Tian, and Y . Wang, “Niagaracq: A scalable continuous query system for internet databases,” inProceedings of the 2000 ACM SIGMOD international conference on Management of data, 2000, pp. 379–390
2000
-
[43]
Continuously adaptive continuous queries over streams,
S. Madden, M. Shah, J. M. Hellerstein, and V . Raman, “Continuously adaptive continuous queries over streams,” inProceedings of the 2002 ACM SIGMOD international conference on Management of data, 2002, pp. 49–60
2002
-
[44]
Efficiently updating materialized views,
J. A. Blakeley, P.-A. Larson, and F. W. Tompa, “Efficiently updating materialized views,”ACM SIGMOD Record, vol. 15, no. 2, pp. 61–71, 1986
1986
-
[45]
Incremental maintenance for non-distributive aggregate functions,
T. Palpanas, R. Sidle, R. Cochrane, and H. Pirahesh, “Incremental maintenance for non-distributive aggregate functions,” inVLDB’02: Proceedings of the 28th International Conference on Very Large Databases. Elsevier, 2002, pp. 802–813
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.