CurvSegFlow: Time-Conditioned Flow Matching for Robust Segmentation of Curvilinear Structures in Noisy Biomedical Images
Pith reviewed 2026-06-26 14:39 UTC · model grok-4.3
The pith
Time-conditioned flow matching refines noisy initial masks into accurate curvilinear segmentations through a learned velocity field.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
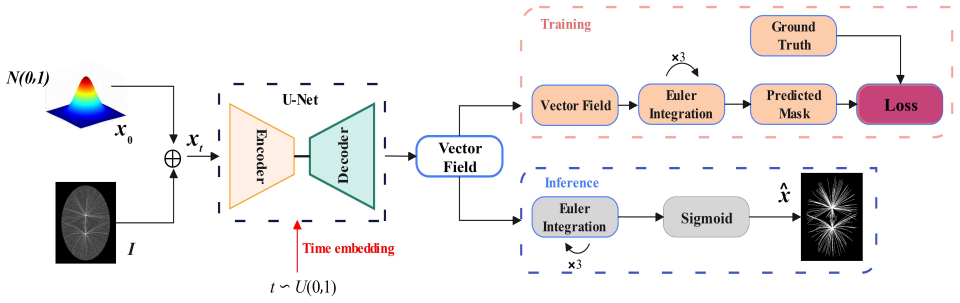
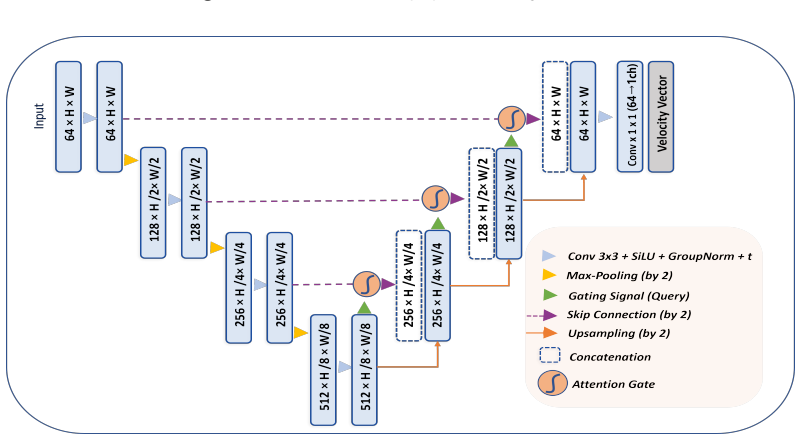
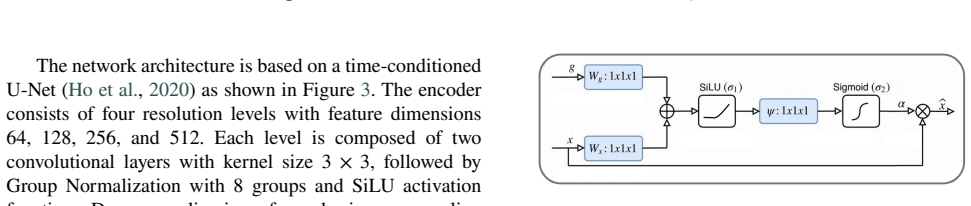
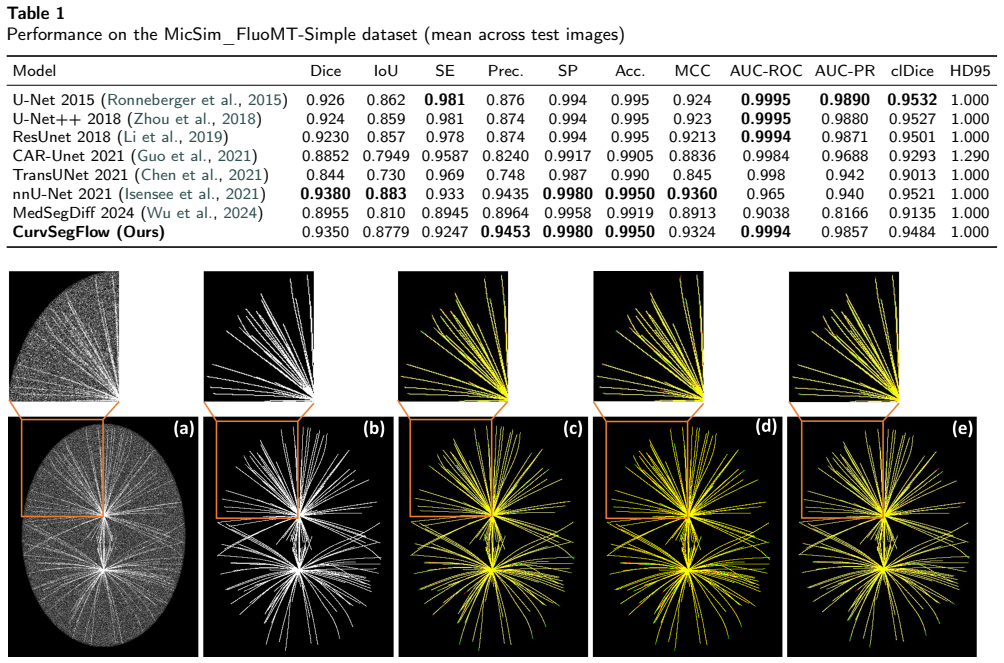
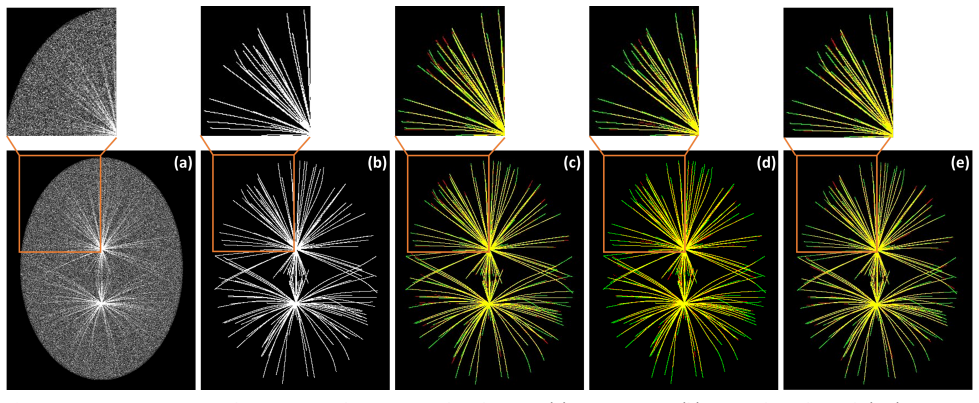
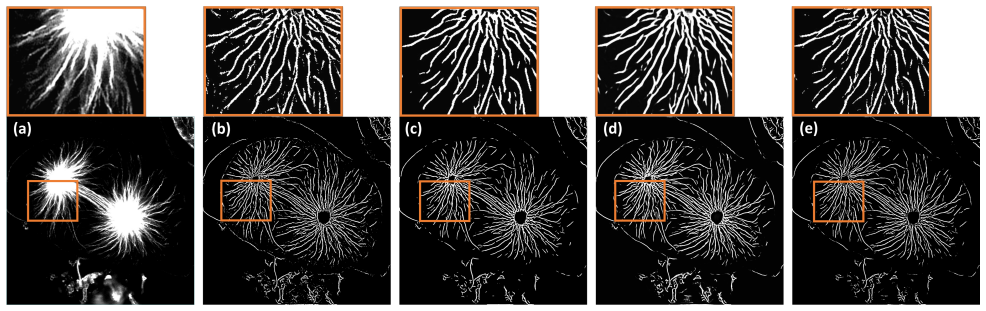
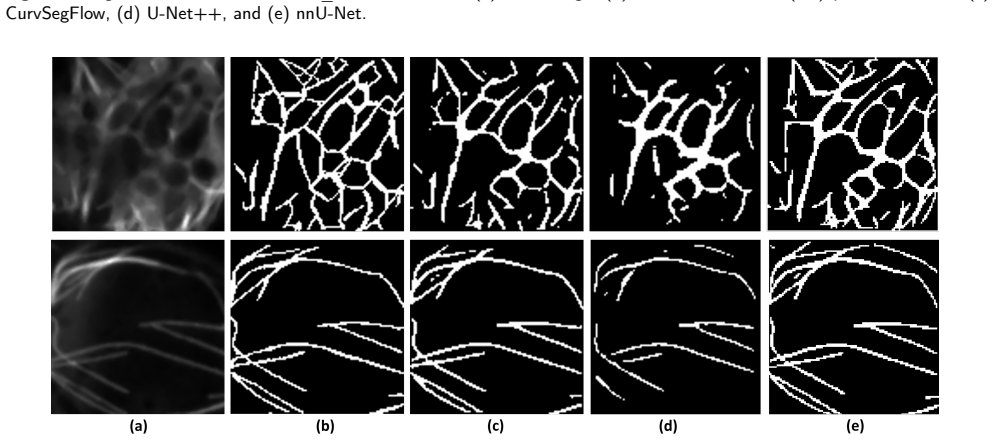
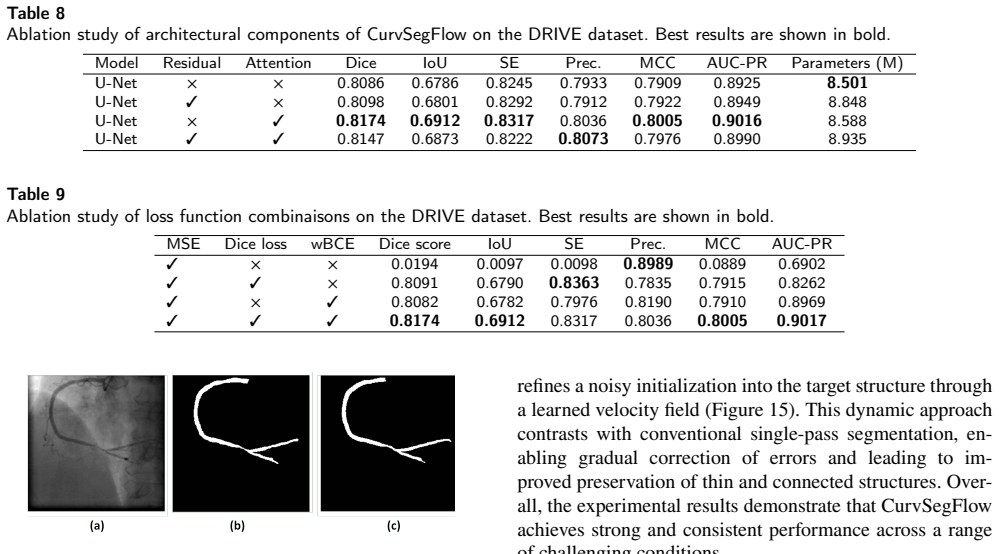
CurvSegFlow models segmentation as a dynamic process in which a learned velocity field, conditioned on a time parameter, progressively transforms a noisy initialization into the target curvilinear mask. A U-Net backbone supplied with temporal embeddings and trained under a triple-term loss produces the velocity field that drives this refinement across stages. The resulting framework is evaluated on multiple synthetic and real microtubule datasets together with public benchmarks of retinal vessels, corneal nerves, and coronary arteries, where it delivers competitive or superior performance with particular gains in structural continuity under low signal-to-noise conditions.
What carries the argument
time-conditioned flow matching, which defines a velocity field that maps a noisy initial mask to the target segmentation over a continuous time interval
If this is right
- The method produces consistent gains in precision and structural continuity on microtubule, retinal vessel, corneal nerve, and coronary artery images.
- Iterative refinement reduces fragmentation at filament crossings and under low signal-to-noise ratios.
- The same architecture generalizes across imaging modalities without modification.
- Gradual error correction improves continuity of thin structures that single-pass predictors typically break.
Where Pith is reading between the lines
- The same flow-matching formulation could be tested on other elongated structures such as neuronal processes or plant vasculature without retraining the core components.
- Because the velocity field operates continuously in time, the approach might support progressive refinement of live or time-lapse sequences where an initial guess improves as more frames arrive.
- If the learned velocity field truly encodes general error-correction dynamics, the framework may lower the volume of labeled data needed by allowing the model to correct its own early mistakes.
Load-bearing premise
A U-Net backbone with temporal embeddings and a triple-term loss can learn a velocity field that reliably corrects errors across refinement stages without any dataset-specific post-hoc tuning.
What would settle it
Performance on a new dataset with previously unseen noise statistics falls below standard single-pass baselines unless the model receives additional fine-tuning or architectural adjustment.
Figures
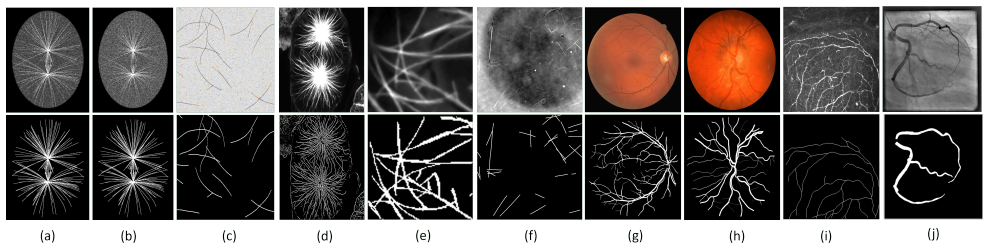

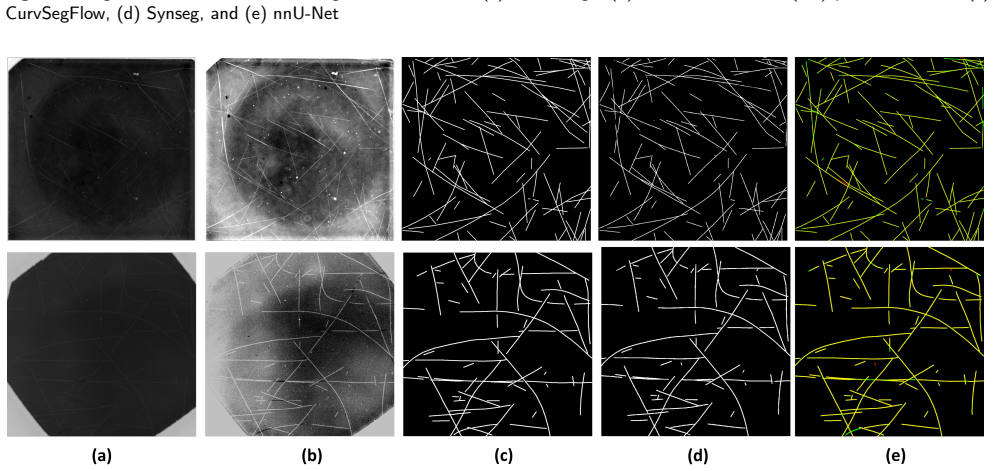
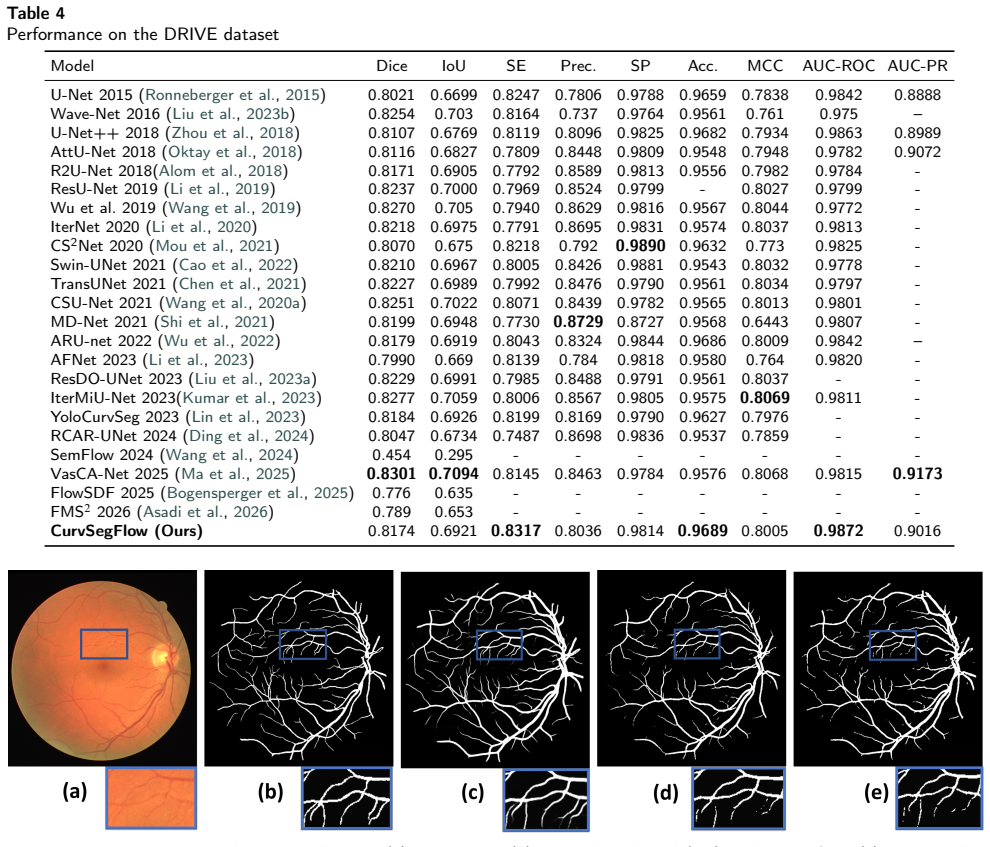
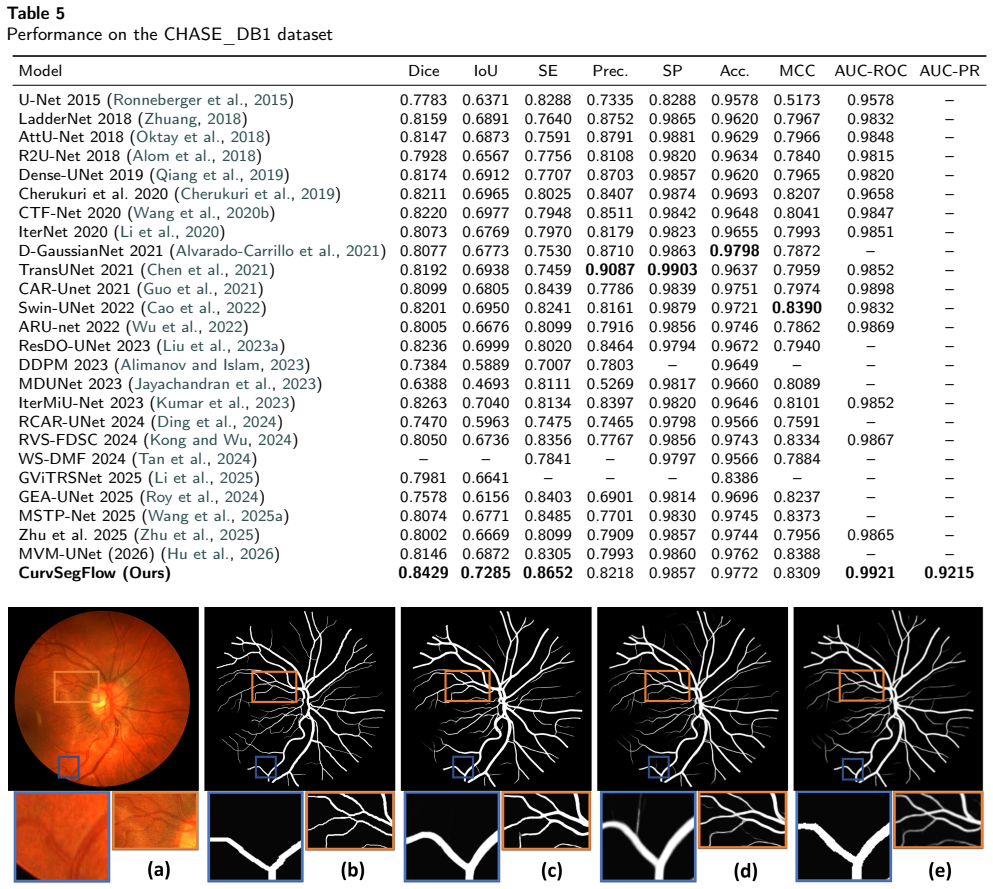
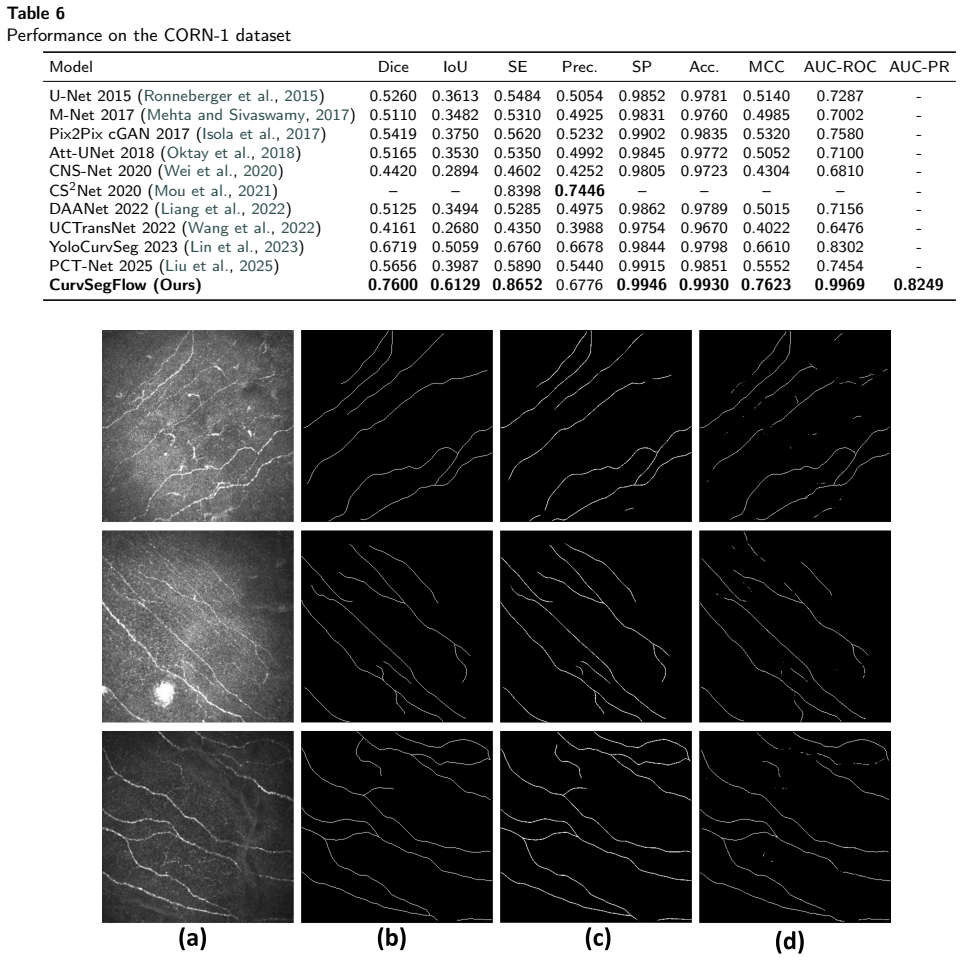

read the original abstract
Accurate segmentation of curvilinear structures remains challenging in biomedical imaging due to their thin geometry, complex topology, and sensitivity to noise. This is particularly critical for microscopy images of cytoskeletal network, where low signal-to-noise ratios and dense filament crossings often lead to fragmented or inaccurate segmentation. In this work, we propose CurvSegFlow, a segmentation framework based on time-conditioned flow matching. Instead of predicting a segmentation mask in a single pass, the method models segmentation as a dynamic process that progressively refines a noisy initialization into the target structure through a learned velocity field. The proposed model combines a U-Net backbone with triple-term loss function and temporal embeddings to guide the refinement process across reconstruction stages. This formulation enables gradual error correction and improves the continuity of thin structures. CurvSegFlow is evaluated on multiple synthetic and real microtubule datasets, as well as on public benchmarks of retinal vessels, corneal nerves and coronary arteries. Across datasets, the method achieves competitive or superior performance compared to established segmentation models, with consistent improvements in precision and structural continuity, particularly under low signal-to-noise conditions. These results show that flow-based iterative refinement provides a robust and general framework for curvilinear structure segmentation. Overall, the proposed approach improves segmentation quality in challenging imaging conditions and generalizes effectively across modalities without architectural changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CurvSegFlow, a segmentation framework that models curvilinear structure segmentation as a dynamic, time-conditioned flow matching process. A U-Net backbone augmented with temporal embeddings and a triple-term loss learns a velocity field that iteratively refines a noisy initialization into the target mask. The method is evaluated on synthetic and real microtubule datasets plus public benchmarks for retinal vessels, corneal nerves, and coronary arteries, with claims of competitive or superior performance in precision and structural continuity, especially under low SNR, and effective generalization across modalities without architectural changes.
Significance. If the experimental results, ablations, and visualizations hold, the work provides a generalizable iterative refinement strategy for thin-structure segmentation in noisy biomedical images. The flow-matching formulation for progressive error correction on curvilinear topologies could be of interest to the biomedical CV community as an alternative to single-pass or post-processing-heavy approaches.
minor comments (2)
- [Abstract] Abstract: the triple-term loss is described only at a high level; a brief enumeration of the three terms (or reference to the equation that defines them) would improve readability for readers who encounter the abstract first.
- [Abstract] The claim that the framework 'generalizes effectively across modalities without architectural changes' would be strengthened by an explicit statement of the training protocol (e.g., whether the same hyper-parameters and temporal embedding schedule are used on all datasets).
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description of the method and results is accurate.
Circularity Check
No significant circularity
full rationale
The abstract and visible description present CurvSegFlow as a modeling choice: a U-Net backbone augmented with temporal embeddings and a triple-term loss to learn a time-conditioned velocity field that iteratively refines an initial noisy mask. No equations, fitted parameters, self-citations, or derivation steps are supplied that reduce any claimed prediction or uniqueness result to the inputs by construction. The central claim of flow-based iterative refinement therefore remains an independent architectural proposal rather than a tautological restatement of fitted quantities or prior self-referential results. This is the expected non-finding for a high-level methods description lacking explicit mathematical reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2012 , journal=
Cytoskeleton , author=. 2012 , journal=
2012
-
[2]
Journal of microscopy , volume=
Important factors determining the nanoscale tracking precision of dynamic microtubule ends , author=. Journal of microscopy , volume=. 2016 , publisher=
2016
-
[3]
arXiv preprint arXiv:2504.14485 , year=
Conditional flow matching for generative modeling of near-wall turbulence with quantified uncertainty , author=. arXiv preprint arXiv:2504.14485 , year=
-
[4]
SoftwareX , volume=
ConfocalGN: A minimalistic confocal image generator , author=. SoftwareX , volume=. 2017 , publisher=
2017
-
[5]
Beber, A. and Braun, M. and Lansky, Z. , title =. 2026 , publisher =. doi:10.5281/zenodo.20597919 , url =
-
[6]
New Journal of Physics , volume=
Collective Langevin dynamics of flexible cytoskeletal fibers , author=. New Journal of Physics , volume=
-
[7]
2026 IEEE 23rd International Symposium on Biomedical Imaging (ISBI) , pages=
MTFlow: Time-Conditioned Flow Matching for Microtubule Segmentation in Noisy Microscopy Images , author=. 2026 IEEE 23rd International Symposium on Biomedical Imaging (ISBI) , pages=. 2026 , organization=
2026
-
[8]
doi:10.5281/zenodo.12776091 , url =
CORN: Corneal nerve fiber dataset , month = jul, year = 2024, publisher =. doi:10.5281/zenodo.12776091 , url =
-
[9]
IEEE transactions on medical imaging , volume=
Ridge-based vessel segmentation in color images of the retina , author=. IEEE transactions on medical imaging , volume=. 2004 , publisher=
2004
-
[10]
2025 , publisher=
MicReal\_FluoMT: A dataset of microscopy images with stained microtubules (Ait Laydi et al., 2025) , author=. 2025 , publisher=
2025
-
[11]
2025 , publisher=
MicSim\_FluoMT: Two synthetic datasets of images of fluorescent microtubules (Ait Laydi et al., 2025) , author=. 2025 , publisher=
2025
-
[12]
arXiv preprint arXiv:2102.04306 , year=
Transunet: Transformers make strong encoders for medical image segmentation , author=. arXiv preprint arXiv:2102.04306 , year=
-
[13]
ICASSP 2021-2021 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Channel attention residual u-net for retinal vessel segmentation , author=. ICASSP 2021-2021 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2021 , organization=
2021
-
[14]
IEEE Geoscience and Remote Sensing Letters , volume=
Road extraction by deep residual u-net , author=. IEEE Geoscience and Remote Sensing Letters , volume=. 2018 , publisher=
2018
-
[15]
IEEE transactions on medical imaging , volume=
Missformer: An effective transformer for 2d medical image segmentation , author=. IEEE transactions on medical imaging , volume=. 2022 , publisher=
2022
-
[16]
2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
Malunet: A multi-attention and light-weight unet for skin lesion segmentation , author=. 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2022 , organization=
2022
-
[17]
Medical Physics , volume=
Deep learning model for coronary artery segmentation and quantitative stenosis detection in angiographic images , author=. Medical Physics , volume=. 2025 , publisher=
2025
-
[18]
Scientific data , volume=
Dataset for automatic region-based coronary artery disease diagnostics using X-ray angiography images , author=. Scientific data , volume=. 2024 , publisher=
2024
-
[19]
International workshop on deep learning in medical image analysis , pages=
Unet++: A nested u-net architecture for medical image segmentation , author=. International workshop on deep learning in medical image analysis , pages=. 2018 , organization=
2018
-
[20]
arXiv preprint arXiv:2603.21717 , year=
Uncertainty Quantification for Distribution-to-Distribution Flow Matching in Scientific Imaging , author=. arXiv preprint arXiv:2603.21717 , year=
-
[21]
Journal of Fluid Mechanics , volume=
Conditional flow matching for generative modelling of near-wall turbulence with quantified uncertainty , author=. Journal of Fluid Mechanics , volume=. 2026 , publisher=
2026
-
[22]
Consistency models , author=
-
[23]
Computer graphics forum , volume=
State of the art on diffusion models for visual computing , author=. Computer graphics forum , volume=. 2024 , organization=
2024
-
[24]
arXiv preprint arXiv:1810.01367 , year=
Ffjord: Free-form continuous dynamics for scalable reversible generative models , author=. arXiv preprint arXiv:1810.01367 , year=
-
[25]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in neural information processing systems , volume=
Topology-preserving deep image segmentation , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2502.19037 , year=
PolypFlow: Reinforcing Polyp Segmentation with Flow-Driven Dynamics , author=. arXiv preprint arXiv:2502.19037 , year=
-
[30]
International Journal of Computer Vision , pages=
FlowSDF: Flow matching for medical image segmentation using distance transforms , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[31]
Medical Image Analysis , volume=
Advances in medical image analysis with vision transformers: a comprehensive review , author=. Medical Image Analysis , volume=. 2024 , publisher=
2024
-
[32]
Frontiers in Pharmacology , volume=
The microtubule cytoskeleton: An old validated target for novel therapeutic drugs , author=. Frontiers in Pharmacology , volume=. 2022 , publisher=
2022
-
[33]
Neurobiology of disease , volume=
Altered microtubule dynamics in neurodegenerative disease: Therapeutic potential of microtubule-stabilizing drugs , author=. Neurobiology of disease , volume=. 2017 , publisher=
2017
-
[34]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[35]
International conference on medical image computing and computer-assisted intervention , pages=
Multiscale vessel enhancement filtering , author=. International conference on medical image computing and computer-assisted intervention , pages=. 1998 , organization=
1998
-
[36]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[37]
Engineering Applications of Artificial Intelligence , volume=
A review of retinal vessel segmentation for fundus image analysis , author=. Engineering Applications of Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[38]
Advances in Neural Information Processing Systems , volume=
Semflow: Binding semantic segmentation and image synthesis via rectified flow , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Diff2flow: Training flow matching models via diffusion model alignment , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Proceedings of the European Conference on Computer Vision (ECCV) Workshops , pages=
Densely connected stacked u-network for filament segmentation in microscopy images , author=. Proceedings of the European Conference on Computer Vision (ECCV) Workshops , pages=
-
[41]
Asadi, Babak and Wu, Peiyang and Golparvar-Fard, Mani and Shah, Viraj and Hajj, Ramez , journal=. FMS ^
-
[42]
Journal of Cell Science , pages=
FAST: Filamentous Actin Segmentation Tool for quantifying cytoskeletal organization , author=. Journal of Cell Science , pages=. 2026 , publisher=
2026
-
[43]
Medical image analysis , volume=
Diffusion models in medical imaging: A comprehensive survey , author=. Medical image analysis , volume=. 2023 , publisher=
2023
-
[44]
Pattern Recognition , volume=
Pa-net: A hybrid architecture for retinal vessel segmentation , author=. Pattern Recognition , volume=. 2025 , publisher=
2025
-
[45]
Medical imaging with deep learning , pages=
Medsegdiff: Medical image segmentation with diffusion probabilistic model , author=. Medical imaging with deep learning , pages=. 2024 , organization=
2024
-
[46]
arXiv preprint arXiv:2601.14841 , year=
MTFlow: Time-Conditioned Flow Matching for Microtubule Segmentation in Noisy Microscopy Images , author=. arXiv preprint arXiv:2601.14841 , year=
-
[47]
Translational vision science & technology , volume=
A deep learning model for automated sub-basal corneal nerve segmentation and evaluation using in vivo confocal microscopy , author=. Translational vision science & technology , volume=. 2020 , publisher=
2020
-
[48]
2017 IEEE 14th international symposium on biomedical imaging (ISBI 2017) , pages=
M-net: A convolutional neural network for deep brain structure segmentation , author=. 2017 IEEE 14th international symposium on biomedical imaging (ISBI 2017) , pages=. 2017 , organization=
2017
-
[49]
Journal of the Optical Society of America A , volume=
Fusion network based on the dual attention mechanism and atrous spatial pyramid pooling for automatic segmentation in retinal vessel images , author=. Journal of the Optical Society of America A , volume=. 2022 , publisher=
2022
-
[50]
Proceedings of the AAAI conference on artificial intelligence , volume=
Uctransnet: rethinking the skip connections in u-net from a channel-wise perspective with transformer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[51]
Computers in Biology and Medicine , volume=
A lightweight PCT-Net for segmenting neural fibers in low-quality CCM images , author=. Computers in Biology and Medicine , volume=. 2025 , publisher=
2025
-
[52]
ACM Transactions on Multimedia Computing, Communications and Applications , year=
Vm-unet: Vision mamba unet for medical image segmentation , author=. ACM Transactions on Multimedia Computing, Communications and Applications , year=
-
[53]
Nature methods , volume=
nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation , author=. Nature methods , volume=. 2021 , publisher=
2021
-
[54]
Nature chemical biology , volume=
Microtubule lattice spacing governs cohesive envelope formation of tau family proteins , author=. Nature chemical biology , volume=. 2022 , publisher=
2022
-
[55]
Plos one , volume=
Automated segmentation of retinal vessel using HarDNet fully convolutional networks , author=. Plos one , volume=. 2025 , publisher=
2025
-
[56]
IEEE Transactions on Image Processing , volume=
Deep retinal image segmentation with regularization under geometric priors , author=. IEEE Transactions on Image Processing , volume=. 2019 , publisher=
2019
-
[57]
Measurement , volume=
Multi-Scale Three-Path Network (MSTP-Net): A new architecture for retinal vessel segmentation , author=. Measurement , volume=. 2025 , publisher=
2025
-
[58]
International symposium on geometry and vision , pages=
D-GaussianNet: Adaptive distorted Gaussian matched filter with convolutional neural network for retinal vessel segmentation , author=. International symposium on geometry and vision , pages=. 2021 , organization=
2021
-
[59]
2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI) , pages=
Ctf-net: Retinal vessel segmentation via deep coarse-to-fine supervision network , author=. 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI) , pages=. 2020 , organization=
2020
-
[60]
Biomedical Signal Processing and Control , volume=
Multi-scale vision Mamba-UNet: A Mamba-based method for retinal vessel segmentation , author=. Biomedical Signal Processing and Control , volume=. 2026 , publisher=
2026
-
[61]
International Conference on Pattern Recognition , pages=
A New Attention Based UNet and Gated Edge Attention Network for Retinal Vessel Segmentation , author=. International Conference on Pattern Recognition , pages=. 2024 , organization=
2024
-
[62]
Pattern Recognition Letters , volume=
GViT-RSNet: A retinal vessel segmentation network using graph convolutional attention and multi-scale vision transformer , author=. Pattern Recognition Letters , volume=. 2025 , publisher=
2025
-
[63]
Knowledge-Based Systems , volume=
Deep matched filtering for retinal vessel segmentation , author=. Knowledge-Based Systems , volume=. 2024 , publisher=
2024
-
[64]
Multimedia Tools and Applications , volume=
Multi-dimensional cascades neural network models for the segmentation of retinal vessels in colour fundus images , author=. Multimedia Tools and Applications , volume=. 2023 , publisher=
2023
-
[65]
2023 IEEE international conference on computational photography (ICCP) , pages=
Denoising diffusion probabilistic model for retinal image generation and segmentation , author=. 2023 IEEE international conference on computational photography (ICCP) , pages=. 2023 , organization=
2023
-
[66]
Biomedical Signal Processing and Control , volume=
RVS-FDSC: A retinal vessel segmentation method with four-directional strip convolution to enhance feature extraction , author=. Biomedical Signal Processing and Control , volume=. 2024 , publisher=
2024
-
[67]
arXiv preprint arXiv:1810.07810 , year=
LadderNet: Multi-path networks based on U-Net for medical image segmentation , author=. arXiv preprint arXiv:1810.07810 , year=
-
[68]
International conference on intelligent science and big data engineering , pages=
A k-dense-UNet for biomedical image segmentation , author=. International conference on intelligent science and big data engineering , pages=. 2019 , organization=
2019
-
[69]
Journal of Cell Biology , volume=
SynSeg: A synthetic data-driven approach for robust subcellular structure segmentation , author=. Journal of Cell Biology , volume=. 2025 , publisher=
2025
-
[70]
bioRxiv , pages=
Deep learning-based cytoskeleton segmentation for accurate high-throughput measurement of cytoskeleton density , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[71]
PLoS One , volume=
Atrous residual convolutional neural network based on U-Net for retinal vessel segmentation , author=. PLoS One , volume=. 2022 , publisher=
2022
-
[72]
arXiv preprint arXiv:2403.16732 , year=
Enabling uncertainty estimation in iterative neural networks , author=. arXiv preprint arXiv:2403.16732 , year=
-
[73]
PLOS Computational Biology , volume=
Synthetic data enables human-grade microtubule analysis with foundation models for segmentation , author=. PLOS Computational Biology , volume=. 2026 , publisher=
2026
-
[74]
IEEE Transactions on Biomedical Engineering , volume=
An ensemble classification-based approach applied to retinal blood vessel segmentation , author=. IEEE Transactions on Biomedical Engineering , volume=. 2012 , publisher=
2012
-
[75]
Medical image analysis , volume=
YoloCurvSeg: You only label one noisy skeleton for vessel-style curvilinear structure segmentation , author=. Medical image analysis , volume=. 2023 , publisher=
2023
-
[76]
European conference on computer vision , pages=
Swin-unet: Unet-like pure transformer for medical image segmentation , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[77]
arXiv preprint arXiv:1804.03999 , year=
Attention u-net: Learning where to look for the pancreas , author=. arXiv preprint arXiv:1804.03999 , year=
-
[78]
The Visual Computer , volume=
Retinal vessel segmentation by using AFNet , author=. The Visual Computer , volume=. 2023 , publisher=
2023
-
[79]
Computers in biology and medicine , volume=
Wave-Net: A lightweight deep network for retinal vessel segmentation from fundus images , author=. Computers in biology and medicine , volume=. 2023 , publisher=
2023
-
[80]
arXiv preprint arXiv:2512.04821 , year=
LatentFM: A Latent Flow Matching Approach for Generative Medical Image Segmentation , author=. arXiv preprint arXiv:2512.04821 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.