Near-Exponential Convergence Rates for kNN Classification based on Boltzmann Margin
Pith reviewed 2026-06-27 11:58 UTC · model grok-4.3
The pith
kNN classifiers achieve near-exponential convergence rates under the Boltzmann margin condition on data distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Boltzmann margin condition bridges Tsybakov and Massart margins and is used to prove the first near-exponential convergence rates for kNN classification, together with several extensions of the main result.
What carries the argument
Boltzmann margin condition, a new assumption on the data distribution that quantifies the separation of the regression function from one-half and enables the faster rates.
If this is right
- kNN excess risk converges near-exponentially with sample size under the Boltzmann margin.
- The Boltzmann margin implies many properties previously known only for Tsybakov or Massart margins when parameters are chosen appropriately.
- The main theorem extends to additional settings and variants of kNN.
- Numerical simulations on synthetic data confirm the near-exponential decay predicted by the theory.
Where Pith is reading between the lines
- The same margin condition could be applied to derive improved rates for other nonparametric classifiers such as kernel methods or trees.
- In applied work, empirical checks for Boltzmann margin on a given dataset could indicate whether kNN is likely to exhibit fast convergence.
- A continuous family of margin conditions might interpolate between polynomial and exponential rates and unify existing analyses.
Load-bearing premise
The underlying data distribution must satisfy the Boltzmann margin condition.
What would settle it
Generate a synthetic distribution that obeys the Boltzmann margin but not Massart margin, train kNN classifiers on increasing sample sizes drawn from it, and check whether the observed excess risk decays near-exponentially rather than polynomially.
Figures
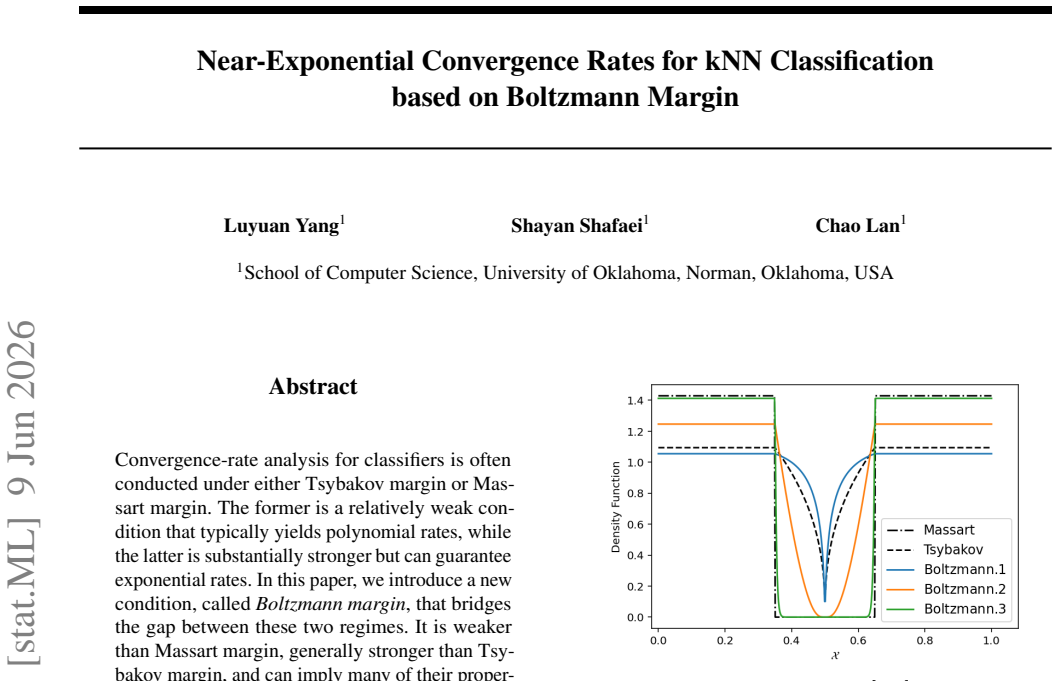


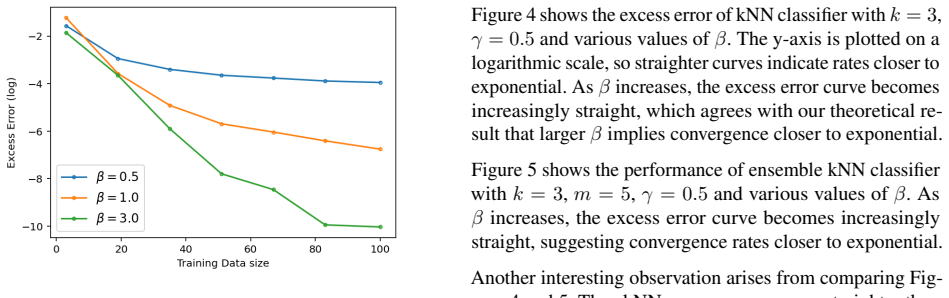
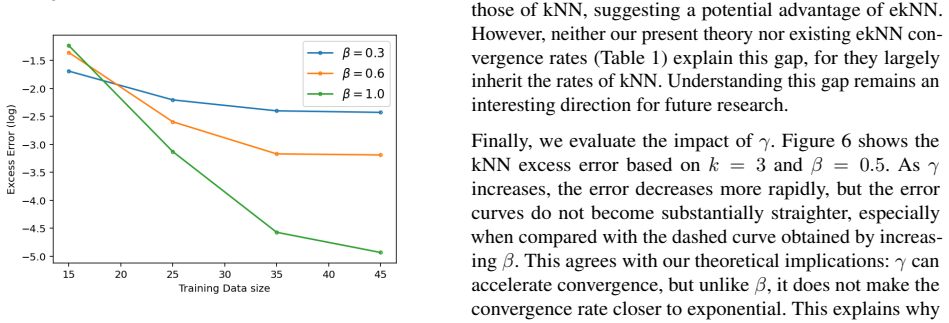
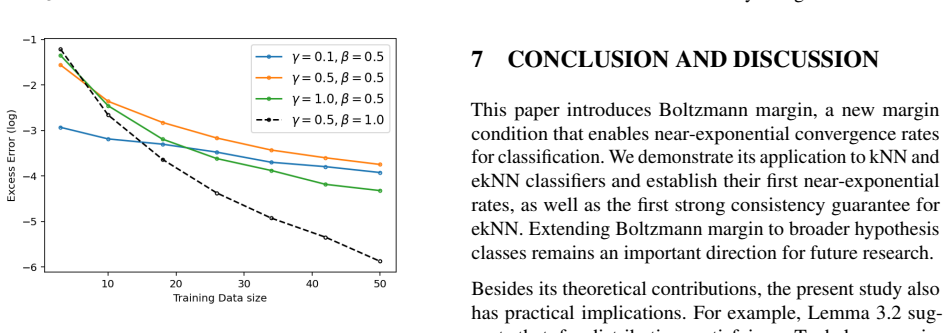
read the original abstract
Convergence-rate analysis for classifiers is often conducted under either Tsybakov margin or Massart margin. The former is a relatively weak condition that typically yields polynomial rates, while the latter is substantially stronger but can guarantee exponential rates. In this paper, we introduce a new condition, called Boltzmann margin, that bridges the gap between these two regimes. It is weaker than Massart margin, generally stronger than Tsybakov margin, and can imply many of their properties under suitable conditions. We apply Boltzmann margin to the analysis of kNN classifiers and establish the first near-exponential convergence rates for kNN classification. We also present extensions of the main results and provide numerical evidence supporting the main theoretical implications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Boltzmann margin condition, positioned as weaker than Massart margin yet generally stronger than Tsybakov margin, and applies it to derive the first near-exponential convergence rates for kNN classification. It includes extensions of the main results and numerical experiments supporting the theoretical claims.
Significance. If the derivations hold, the work provides a useful intermediate margin regime that yields faster-than-polynomial rates for a standard nonparametric classifier without invoking the strongest margin assumptions. The numerical evidence is noted as corroborating the theory, which strengthens the potential impact in statistical learning theory.
minor comments (3)
- The abstract claims 'first near-exponential convergence rates for kNN'; the introduction or related-work section should explicitly contrast with prior polynomial-rate results under Tsybakov (e.g., citing specific theorems) to substantiate novelty.
- Notation for the Boltzmann margin parameter (likely introduced in §2 or §3) should be cross-referenced consistently when stating the rate in the main theorem; unclear notation is a minor clarity issue.
- Figure captions for the numerical experiments should include the exact parameter settings (k, n, margin parameter values) used to generate the plots so readers can reproduce the observed near-exponential behavior.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the accurate summary of the Boltzmann margin contribution, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation self-contained under independent margin condition
full rationale
The paper defines Boltzmann margin as a new, independent condition (weaker than Massart, generally stronger than Tsybakov) and derives the claimed near-exponential kNN rates directly from it via standard analysis. No equation reduces to a fitted input renamed as prediction, no self-citation chain bears the central load, and the margin itself is not defined in terms of the target rates. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Boltzmann margin condition is weaker than Massart margin and generally stronger than Tsybakov margin
invented entities (1)
-
Boltzmann margin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence Review , volume=
Explainable artificial intelligence: a comprehensive review , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[2]
Advances in Neural Information Processing Systems , volume=
Distributionally robust weighted k-nearest neighbors , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
International Conference on Machine Learning , pages=
A two-stage active learning algorithm for k-nearest neighbors , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[4]
Proceedings of the 30th ACM international conference on information & knowledge management , pages=
Towards self-explainable graph neural network , author=. Proceedings of the 30th ACM international conference on information & knowledge management , pages=
-
[5]
arXiv preprint arXiv:2010.09030 , year=
Explaining and improving model behavior with k nearest neighbor representations , author=. arXiv preprint arXiv:2010.09030 , year=
arXiv 2010
-
[6]
Advances in Neural Information Processing Systems , volume=
Nearest neighbor speculative decoding for llm generation and attribution , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Artificial Intelligence and Statistics , pages=
Efficient data shapley for weighted nearest neighbor algorithms , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[8]
Advances in Neural Information Processing Systems , volume=
KFNN: K-free nearest neighbor for crowdsourcing , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the 41st International Conference on Machine Learning , pages=
Weighted distance nearest neighbor condensing , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[10]
The 40th Conference on Uncertainty in Artificial Intelligence , year=
Learning from crowds with dual-view K-nearest neighbor , author=. The 40th Conference on Uncertainty in Artificial Intelligence , year=
-
[11]
Forty-second International Conference on Machine Learning , year=
Kona: An Efficient Privacy-Preservation Framework for KNN Classification by Communication Optimization , author=. Forty-second International Conference on Machine Learning , year=
-
[12]
International Conference on Learning Representations , year=
Generalization through Memorization: Nearest Neighbor Language Models , author=. International Conference on Learning Representations , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Revisiting Nearest Neighbor for Tabular Data: A Deep Tabular Baseline Two Decades Later , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
The Annals of Statistics , volume=
Risk Bounds for Statistical Learning , author=. The Annals of Statistics , volume=
-
[15]
International Conference on Artificial Intelligence and Statistics , pages=
Fast and Bayes-consistent nearest neighbors , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[16]
IEEE Transactions on Information Theory , volume=
Minimax rate optimal adaptive nearest neighbor classification and regression , author=. IEEE Transactions on Information Theory , volume=. 2021 , publisher=
2021
-
[17]
The Annals of statistics , volume=
On the Bayes-risk consistency of regularized boosting methods , author=. The Annals of statistics , volume=. 2004 , publisher=
2004
-
[18]
arXiv preprint arXiv:2505.08262 , year=
Super-fast rates of convergence for Neural Networks Classifiers under the Hard Margin Condition , author=. arXiv preprint arXiv:2505.08262 , year=
-
[19]
International Conference on Artificial Intelligence and Statistics , pages=
A case of exponential convergence rates for svm , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[20]
International Conference on Machine Learning , pages=
Multiclass learning with margin: exponential rates with no bias-variance trade-off , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dataset Efficient Training with Model Ensembling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
2006 , publisher=
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
2006
-
[23]
Proceedings of the 27th International Database Engineered Applications Symposium , pages=
Condensed Nearest Neighbour Rules for Multi-Label Datasets , author=. Proceedings of the 27th International Database Engineered Applications Symposium , pages=
-
[24]
IEEE transactions on information theory , volume=
The condensed nearest neighbor rule (corresp.) , author=. IEEE transactions on information theory , volume=. 1968 , publisher=
1968
-
[25]
, author=
Combining Nearest Neighbor Classifiers Through Multiple Feature Subsets. , author=. ICML , volume=. 1998 , organization=
1998
-
[26]
Artificial Intelligence Review , volume=
Voting over multiple condensed nearest neighbors , author=. Artificial Intelligence Review , volume=. 1997 , publisher=
1997
-
[27]
IEEE Access , volume=
A Weighted k-Nearest Neighbours Ensemble With Added Accuracy and Diversity , author=. IEEE Access , volume=. 2022 , publisher=
2022
-
[28]
Information fusion , volume=
Fusion of multiple approximate nearest neighbor classifiers for fast and efficient classification , author=. Information fusion , volume=. 2004 , publisher=
2004
-
[29]
arXiv preprint arXiv:2303.12210 , year=
A Random Projection k Nearest Neighbours Ensemble for Classification via Extended Neighbourhood Rule , author=. arXiv preprint arXiv:2303.12210 , year=
-
[30]
2005 International Conference on Machine Learning and Cybernetics , volume=
GA-based feature subset clustering for combination of multiple nearest neighbors classifiers , author=. 2005 International Conference on Machine Learning and Cybernetics , volume=. 2005 , organization=
2005
-
[31]
International Conference on Intelligent Data Engineering and Automated Learning , pages=
A randomized sphere cover classifier , author=. International Conference on Intelligent Data Engineering and Automated Learning , pages=. 2010 , organization=
2010
-
[32]
Modern problems of radio engineering, telecommunications and computer science (IEEE Cat
Voting over multiple k-nn classifiers , author=. Modern problems of radio engineering, telecommunications and computer science (IEEE Cat. No. 02EX542) , pages=. 2002 , organization=
2002
-
[33]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages=
Semi-supervised condensed nearest neighbor for part-of-speech tagging , author=. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages=
-
[34]
International Journal of Advanced Computer Science and Applications , volume=
Survey of nearest neighbor condensing techniques , author=. International Journal of Advanced Computer Science and Applications , volume=. 2011 , publisher=
2011
-
[35]
International Journal of Intelligent Engineering and Systems , volume=
Adaptive condensed nearest neighbor for imbalance data classification , author=. International Journal of Intelligent Engineering and Systems , volume=
-
[36]
arXiv preprint arXiv:1007.0085 , year=
Survey of nearest neighbor techniques , author=. arXiv preprint arXiv:1007.0085 , year=
-
[37]
Advances in neural information processing systems , volume=
Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning , author=. Advances in neural information processing systems , volume=
-
[38]
Concentration Inequalities: A Nonasymptotic Theory of Independence. Univ. Press , author=. 2013 , publisher=
2013
-
[39]
IEEE Transactions on Knowledge and Data Engineering , volume=
Challenges in KNN classification , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2021 , publisher=
2021
-
[40]
SIAM review , volume=
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
2018
-
[41]
EURASIP Journal on Advances in Signal Processing , volume=
A survey of machine learning for big data processing , author=. EURASIP Journal on Advances in Signal Processing , volume=. 2016 , publisher=
2016
-
[42]
Knowledge and information systems , volume=
Top 10 algorithms in data mining , author=. Knowledge and information systems , volume=. 2008 , publisher=
2008
-
[43]
2018 , publisher=
Foundations of machine learning , author=. 2018 , publisher=
2018
-
[44]
Concentration inequalities for dependent random variables via the martingale method , author=
-
[45]
Computational optimization and applications , volume=
Accurate solution to overdetermined linear equations with errors using L1 norm minimization , author=. Computational optimization and applications , volume=. 2000 , publisher=
2000
-
[46]
2006 , publisher=
Pattern recognition and machine learning , author=. 2006 , publisher=
2006
-
[47]
Proceedings of International Conference on Neural Networks (ICNN'96) , volume=
Generalization error of ensemble estimators , author=. Proceedings of International Conference on Neural Networks (ICNN'96) , volume=. 1996 , organization=
1996
-
[48]
Advances in Neural Information Processing Systems , volume=
Rates of convergence for nearest neighbor classification , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Artificial Intelligence Review , volume=
Voting over Multiple Condensed Nearest Neighbors , author=. Artificial Intelligence Review , volume=
-
[50]
IEEE Transactions on Information Theory , volume=
An algorithm for a selective nearest neighbor decision rule (corresp.) , author=. IEEE Transactions on Information Theory , volume=. 1975 , publisher=
1975
-
[51]
2025 , publisher=
Ensemble methods: foundations and algorithms , author=. 2025 , publisher=
2025
-
[52]
International Journal of Pattern Recognition and Artificial Intelligence , volume=
Decision boundary preserving prototype selection for nearest neighbor classification , author=. International Journal of Pattern Recognition and Artificial Intelligence , volume=. 2005 , publisher=
2005
-
[53]
Pattern Recognition , volume=
An incremental prototype set building technique , author=. Pattern Recognition , volume=. 2002 , publisher=
2002
-
[54]
International Conference on Artificial Intelligence and Statistics , pages=
Achieving the time of 1-NN, but the accuracy of k-NN , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[55]
Journal of Machine Learning Research , volume=
Universal consistency and rates of convergence of multiclass prototype algorithms in metric spaces , author=. Journal of Machine Learning Research , volume=
-
[56]
Information and Inference: A Journal of the IMA , volume=
Fast classification rates without standard margin assumptions , author=. Information and Inference: A Journal of the IMA , volume=. 2021 , publisher=
2021
-
[57]
arXiv preprint arXiv:2506.09348 , year=
Adversarial Surrogate Risk Bounds for Binary Classification , author=. arXiv preprint arXiv:2506.09348 , year=
-
[58]
arXiv preprint arXiv:2506.00316 , year=
Active Learning via Regression Beyond Realizability , author=. arXiv preprint arXiv:2506.00316 , year=
-
[59]
Conference on Learning Theory , pages=
Efficient learning of linear separators under bounded noise , author=. Conference on Learning Theory , pages=. 2015 , organization=
2015
-
[60]
Pattern Recognition , volume=
Risk bounds for cart classifiers under a margin condition , author=. Pattern Recognition , volume=. 2012 , publisher=
2012
-
[61]
International workshop on multiple classifier systems , pages=
Ensemble methods in machine learning , author=. International workshop on multiple classifier systems , pages=. 2000 , organization=
2000
-
[62]
2013 , publisher=
A probabilistic theory of pattern recognition , author=. 2013 , publisher=
2013
-
[63]
Random Structures & Algorithms , volume=
Large deviations for sums of partly dependent random variables , author=. Random Structures & Algorithms , volume=. 2004 , publisher=
2004
-
[64]
Foundations and Trends
Explaining the success of nearest neighbor methods in prediction , author=. Foundations and Trends. 2018 , publisher=
2018
-
[65]
IEEE transactions on information theory , volume=
Nearest neighbor pattern classification , author=. IEEE transactions on information theory , volume=. 1967 , publisher=
1967
-
[66]
The L\_1 View , year=
Nonparametric density estimation , author=. The L\_1 View , year=
-
[67]
The annals of statistics , pages=
Consistent nonparametric regression , author=. The annals of statistics , pages=. 1977 , publisher=
1977
-
[68]
Machine learning , volume=
Reduction techniques for instance-based learning algorithms , author=. Machine learning , volume=. 2000 , publisher=
2000
-
[69]
International conference on machine learning , pages=
Stochastic neighbor compression , author=. International conference on machine learning , pages=. 2014 , organization=
2014
-
[70]
Advances in Neural Information Processing Systems , volume=
Near-optimal sample compression for nearest neighbors , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
ACM Transactions on Internet of Things , volume=
On lightweight privacy-preserving collaborative learning for internet of things by independent random projections , author=. ACM Transactions on Internet of Things , volume=. 2021 , publisher=
2021
-
[72]
International Conference on Machine Learning , pages=
Stability and hypothesis transfer learning , author=. International Conference on Machine Learning , pages=. 2013 , organization=
2013
-
[73]
Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems , pages=
Cloud-enabled privacy-preserving collaborative learning for mobile sensing , author=. Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems , pages=
-
[74]
IEEE Transactions on knowledge and data engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on knowledge and data engineering , volume=. 2009 , publisher=
2009
-
[75]
Advances in neural information processing systems , volume=
Co-training and expansion: Towards bridging theory and practice , author=. Advances in neural information processing systems , volume=
-
[76]
Proceedings of Machine Learning Research vol , volume=
Fast and Multiphase Rates for Nearest Neighbor Classifiers , author=. Proceedings of Machine Learning Research vol , volume=
-
[77]
International Conference on Machine Learning , pages=
Fast rates for a kNN classifier robust to unknown asymmetric label noise , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[78]
Journal of machine learning research , volume=
Under-bagging nearest neighbors for imbalanced classification , author=. Journal of machine learning research , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
On convergence of nearest neighbor classifiers over feature transformations , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
IEEE transactions on information theory , volume=
On the rate of convergence of local averaging plug-in classification rules under a margin condition , author=. IEEE transactions on information theory , volume=. 2007 , publisher=
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.