LLMs can construct powerful representations and streamline sample-efficient supervised learning
Pith reviewed 2026-05-22 10:47 UTC · model grok-4.3
The pith
An LLM synthesizes global rubrics from small example subsets to standardize clinical inputs and outperform larger pretrained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
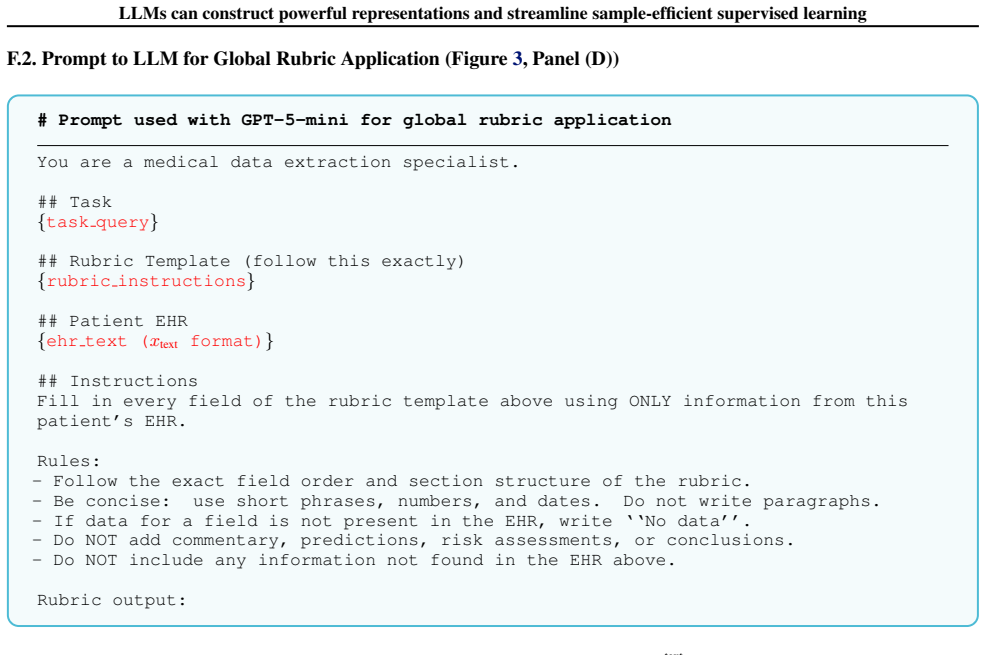
The central claim is that an LLM can analyze a small but diverse subset of text-serialized input examples to synthesize a global rubric, which then transforms naive text serializations into standardized evidence-organized formats, enabling downstream supervised models to achieve significantly higher performance on clinical tasks than count-feature baselines, naive LLM approaches, or large pretrained clinical models.
What carries the argument
The global rubric, a programmatic specification synthesized by the LLM for extracting and organizing task-relevant evidence from text-serialized inputs.
If this is right
- Rubric-transformed inputs allow supervised models to reach higher accuracy on multimodal clinical data without requiring custom feature engineering by domain experts.
- The method delivers better results than naive LLM prompting or simple count features on the tested tasks.
- Rubrics support conversion of complex records into tabular representations for use with standard machine learning pipelines.
- Local rubrics provide additional task-conditioned interpretive summaries that complement the global approach.
- The pipeline offers practical gains in auditability and cost at scale compared to retraining large foundation models.
Where Pith is reading between the lines
- The rubric technique could apply to other domains with heterogeneous records, such as legal documents or financial time series, to reduce reliance on expert-designed features.
- By enabling strong performance from small curated subsets, the method might decrease dependence on massive pretraining datasets for specialized prediction problems.
- Standardized rubric outputs could integrate more easily with regulatory review processes in high-stakes settings like medicine.
- Combining global and local rubrics might create hybrid systems that balance broad consistency with task-specific adaptability.
Load-bearing premise
The LLM can synthesize a global rubric from a small diverse subset of examples that captures all task-relevant evidence without introducing systematic bias or information loss when applied to the full dataset.
What would settle it
If models trained on rubric-transformed features show no performance gain or underperform compared to count-feature models across the 15 EHRSHOT clinical tasks, the central claim of advantage would be falsified.
Figures
















read the original abstract
As real-world datasets become more complex and heterogeneous, supervised learning is often bottlenecked by input representation design. Modeling multimodal data, such as time-series, free text, and structured records, often requires non-trivial domain expertise. We propose an agentic pipeline to streamline this process. First, an LLM analyzes a small but diverse subset of text-serialized input examples in-context to synthesize a global rubric, which acts as a programmatic specification for extracting and organizing evidence. This rubric is then used to transform naive text-serializations of inputs into a more standardized format for downstream models. We also describe local rubrics, which are task-conditioned interpretive summaries generated by an LLM. Across 15 clinical tasks from the EHRSHOT benchmark, our rubric approaches significantly outperform count-feature models, naive LLM baselines, and a clinical foundation model pretrained on orders of magnitude more data. Beyond performance, rubrics offer operational advantages such as being easy to audit, cost-effectiveness at scale, and facilitating tabular representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic LLM pipeline that first synthesizes a global rubric from a small diverse subset of text-serialized multimodal examples (time-series, free text, structured records) and then applies this rubric to produce standardized representations for downstream supervised models. Local rubrics are also introduced as task-conditioned summaries. On 15 clinical tasks from the EHRSHOT benchmark the rubric-based approaches are reported to outperform count-feature baselines, naive LLM prompting, and a large clinical foundation model pretrained on far more data, while offering auditability and cost advantages.
Significance. If the performance claims and the assumption that a single global rubric derived from a modest subset can reliably capture all task-relevant evidence hold, the work would provide a practical route to reducing domain-expertise requirements in representation engineering for heterogeneous real-world data. The emphasis on programmatic, auditable rubrics and tabular outputs is a concrete operational strength that could aid deployment and debugging.
major comments (3)
- [§4] §4 (Results) and the methods description of global-rubric synthesis: the central claim that the rubric extracts 'all task-relevant evidence' without systematic omission is load-bearing, yet the manuscript supplies no quantitative characterization of subset size, diversity sampling procedure, or coverage of low-frequency clinical patterns (e.g., rare lab trajectories). This directly engages the weakest assumption identified in the stress test and leaves open the possibility that reported gains are sensitive to the particular subset chosen.
- [Table 2] Table 2 (or equivalent results table): performance numbers are presented without error bars, statistical tests, or ablation on rubric components (global vs. local, subset size). Without these, it is impossible to judge whether the outperformance over the clinical foundation model is robust or could be explained by post-hoc rubric tuning or benchmark-specific confounds.
- [§3.1] §3.1 (Pipeline description): the transformation step that converts naive text-serializations into rubric-specified format is described at a high level; no formal specification or pseudocode is given for how the rubric is executed on the full dataset, making reproducibility and error analysis difficult.
minor comments (2)
- [Abstract] The abstract states 'significantly outperform' but the main text should explicitly define the statistical criterion used for significance.
- [§3] Notation for 'local rubrics' versus 'global rubrics' is introduced without a clear contrast table or running example that would help readers distinguish their roles.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the presentation of our methods and results. We have revised the manuscript to incorporate additional details on subset sampling, statistical analysis, and pipeline specification. Our responses to the major comments are provided below.
read point-by-point responses
-
Referee: [§4] §4 (Results) and the methods description of global-rubric synthesis: the central claim that the rubric extracts 'all task-relevant evidence' without systematic omission is load-bearing, yet the manuscript supplies no quantitative characterization of subset size, diversity sampling procedure, or coverage of low-frequency clinical patterns (e.g., rare lab trajectories). This directly engages the weakest assumption identified in the stress test and leaves open the possibility that reported gains are sensitive to the particular subset chosen.
Authors: We agree that a more quantitative characterization of the subset would strengthen the claims. The original manuscript describes the subset as 'small but diverse' but does not detail the procedure. In revision we have expanded the methods section to specify that examples were clustered via embedding similarity and one representative was drawn from each of the top-k clusters (k=20) to promote coverage of common patterns; we also report results for subset sizes of 20, 50, and 100 examples showing that performance stabilizes beyond 50. We do not claim the rubric captures literally every low-frequency pattern; rather, it extracts the evidence types that the LLM identifies as generally relevant across the sampled examples. Task-specific rare events can be further handled by the local rubrics. These clarifications and the new sensitivity analysis have been added to §4. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): performance numbers are presented without error bars, statistical tests, or ablation on rubric components (global vs. local, subset size). Without these, it is impossible to judge whether the outperformance over the clinical foundation model is robust or could be explained by post-hoc rubric tuning or benchmark-specific confounds.
Authors: We accept this criticism. The original Table 2 reported point estimates only. In the revised manuscript we have added standard-error bars computed over five independent runs of the downstream supervised models (different random seeds), performed paired t-tests against each baseline, and included new ablation rows for global-only, local-only, and varying subset sizes. The updated table shows that the reported gains remain statistically significant (p<0.05) and that performance improves monotonically with subset size before plateauing. These additions address concerns about robustness and potential confounds. revision: yes
-
Referee: [§3.1] §3.1 (Pipeline description): the transformation step that converts naive text-serializations into rubric-specified format is described at a high level; no formal specification or pseudocode is given for how the rubric is executed on the full dataset, making reproducibility and error analysis difficult.
Authors: We thank the referee for noting this gap. The original description was intentionally high-level to focus on the conceptual contribution. In revision we have inserted both a formal specification of a rubric (as an ordered list of extraction rules with output schema) and Algorithm 1 (pseudocode) that details the three-stage process: (1) LLM parsing of the rubric into executable instructions, (2) per-example application with structured output validation, and (3) aggregation into a tabular feature matrix. This addition directly improves reproducibility and enables future error analysis. revision: yes
Circularity Check
No significant circularity; evaluation relies on external benchmark and independent baselines
full rationale
The paper presents an empirical method for rubric synthesis via LLM on a small subset of EHRSHOT data, followed by application to the full dataset and comparison against count-feature models, naive LLM baselines, and a pretrained clinical foundation model. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs; performance claims are externally validated on a public benchmark without self-referential definitions or load-bearing self-citations. The derivation chain remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can synthesize accurate global rubrics from small diverse text-serialized subsets that generalize to full datasets
Forward citations
Cited by 1 Pith paper
-
Mitigating Label Bias with Interpretable Rubric Embeddings
Rubric embeddings from expert criteria mitigate label bias in models trained on historical evaluations, reducing group disparities while improving cohort quality on a master's program dataset.
Reference graph
Works this paper leans on
-
[1]
**Be data-driven and discriminative. ** Identify which features, patterns, and interactions actually separate the positive and negative cases. The rubric should capture not just obvious indicators but also subtler or compound features you notice. At the same time, do not overfit to these 40 cases -- use your clinical knowledge to include factors that are ...
-
[2]
** Every rubricified output must follow the same field names and order
**Be structured and consistent. ** Every rubricified output must follow the same field names and order. For each field, specify what to extract from the EHR and how to format it. Specify what to write when data is absent
-
[3]
** The evaluator filling in the rubric must extract and organize information from the EHR
**Extract facts only. ** The evaluator filling in the rubric must extract and organize information from the EHR. It must NOT make predictions, assign risk levels, or draw conclusions
-
[4]
** The rubric should focus on extracting information that is relevant to the task
**Be concise. ** The rubric should focus on extracting information that is relevant to the task. It should not ask the evaluator to reproduce the entire EHR. ## Positive Examples (Ground Truth: Yes) {NaiveText EHR serializations of 20 positive examples concatenated (x text format)} ## Negative Examples (Ground Truth: No) {NaiveText EHR serializations of 2...
-
[5]
The raw naive text EHR serialization
-
[6]
Use these paired examples to understand the extraction mapping precisely
The LLM-produced rubric fill for that exact patient --- showing you how the fields should be extracted from the raw text. Use these paired examples to understand the extraction mapping precisely. {40 paired examples of naive text serializations (x text) and LLM-filled rubric text serializations (x rubric).} ## Required Script Interface The generated script must:
-
[7]
Accept the following command-line arguments via argparse: - ‘--input dir‘ : root directory of naivetext serializations - ‘--output dir‘ : root directory for llmrubric-parser outputs - ‘--task‘ : task name - ‘--splits‘ : one or more of ‘train val test‘
-
[8]
For each split, read ‘{{input dir}}/{{task}}/{{split}}.json‘ --- a JSON array where each element has: - ‘patient id‘ (int) - ‘prediction time‘ (ISO datetime string) - ‘task‘ (str) - ‘split‘ (str) - ‘label‘ (bool) - ‘serialization‘ (str)←the EHR text to parse
-
[9]
For each patient call ‘fill rubric(serialization: str) -> str‘, which: - Extracts all rubric fields from the EHR text using regex and string operations - Returns a filled-in rubric string that follows the exact field names, order, and format from the rubric template above - Writes "NA" for any field whose data is absent from the EHR
-
[10]
Write output to ‘{{output dir}}/{{task}}/{{split}}.json‘ --- a JSON array where each element has: - ‘patient id‘ (int) - ‘prediction time‘ (str) - ‘task‘ (str) - ‘split‘ (str) - ‘label‘ (bool) - ‘rubricified text‘ (str)←output of fill rubric()
-
[11]
Create output directories as needed (parents=True, exist ok=True)
-
[12]
## Constraints - Use only Python standard library plus ‘re‘, ‘json‘, ‘argparse‘, ‘pathlib‘, ‘sys‘
Print progress to stdout: total patients processed per split. ## Constraints - Use only Python standard library plus ‘re‘, ‘json‘, ‘argparse‘, ‘pathlib‘, ‘sys‘. No third-party packages. - No LLM API calls, network requests, external tools. - The ‘fill rubric‘ function must be deterministic and handle missing data gracefully (write "NA" rather than raising...
-
[13]
Accept CLI arguments via argparse: - ‘--input dir‘ - ‘--output dir‘ - ‘--task‘ - ‘--splits‘
-
[14]
For each split, read ‘{{input dir}}/{{split}}/{{task}}.json‘ | a JSON array where each element has: - ‘patient id‘ (int) - ‘label time‘ (ISO datetime string) - ‘label value‘ (bool) - ‘conversations‘ (list) | rubric text is in ‘conversations[1]["content"]‘ between ‘--- Patient EHR ---‘ and ‘--- End of EHR ---‘
-
[15]
Implement ‘def extract features(rubric text: str) -> dict[str, float]‘: - Parse every rubric field from the text - Return a flat dict mapping feature name→float value - For **numeric fields **: extract the number; if missing/NA write ‘0.0‘ and set ‘{{field}} missing = 1.0‘ - For **categorical / Yes/No fields **: one-hot encode all known values; unknown/NA...
-
[16]
name"‘: feature name (matches key in extract features output) - ‘
Define ‘SCHEMA: list[dict]‘ at module level | one entry per feature with keys: - ‘"name"‘: feature name (matches key in extract features output) - ‘"type"‘: ‘"numeric"‘, ‘"binary"‘, or ‘"categorical"‘ - ‘"description"‘: short human-readable description - ‘"possible values"‘: list of string values for categorical/binary fields, omit for numeric 38 LLMs can...
-
[17]
For each split, build an N×F float32 matrix from ‘extract features‘, save as: - ‘{{output dir}}/{{task}}/{{split}}.npz‘ with numpy keys: - ‘embeddings‘: shape (N, F) float32 - ‘labels‘: shape (N,) int32 - ‘patient ids‘: shape (N,) int64 - ‘prediction times‘: shape (N,) object (strings)
-
[18]
Save ‘{{output dir}}/{{task}}/feature schema.json‘ once (after processing the first split): ‘‘‘json {{"task": "{task}", "task query": "{task query}", "num features": <F>, "features": <SCHEMA list> }} ‘‘‘
-
[19]
Create output directories as needed. Print progress to stdout. ## Constraints - Use only Python standard library plus ‘re‘, ‘json‘, ‘numpy‘, ‘argparse‘, ‘pathlib‘, ‘sys‘. No third-party packages beyond numpy. - No LLM API calls, no network requests. - ‘extract features‘ must be deterministic and never raise exceptions on any input (catch all errors, defau...
-
[20]
Define the prediction window: ‘‘next year’’ relative to the EHR reference date and time
-
[21]
Define time windows to extract: - Very recent: last 30 days - Recent: 31--180 days - Baseline/remote:>180 days up to available history
-
[22]
Standardize units and formats: - Blood pressure: mmHg (systolic/diastolic) - Weight: kg or oz→convert to kg if numeric calculations needed - Height: cm or in→convert to meters - Labs: use usual clinical units (creatinine mg/dL, A1c %, etc.)
-
[23]
Log data sources (vitals, problem list, medications, laboratory, procedures, notes) and timestamp of extraction. B. Step-by-step extraction & transformation procedure Step 1 --- Demographics and baseline context - Extract: - Age (years) - Sex / gender - Race / ethnicity (if available) - Relevant social history: tobacco (current/former/never), alcohol (hea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.