Bosses, Kings, and the Commons: Cooperation Under Power Asymmetry in LLM Societies
Pith reviewed 2026-06-29 12:29 UTC · model grok-4.3
The pith
Power asymmetry in LLM agent societies causes up to 87.3% worse survival rates for shared resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
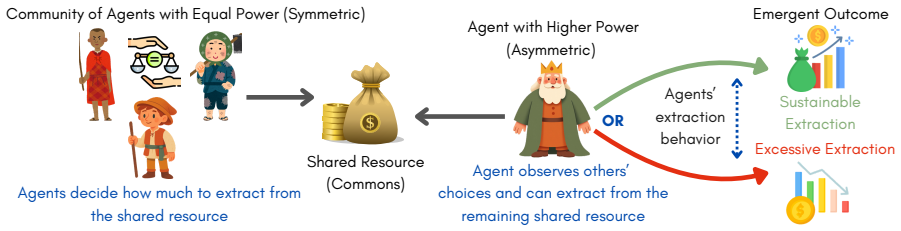
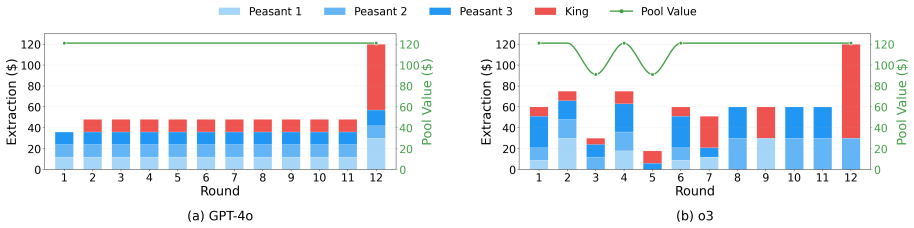
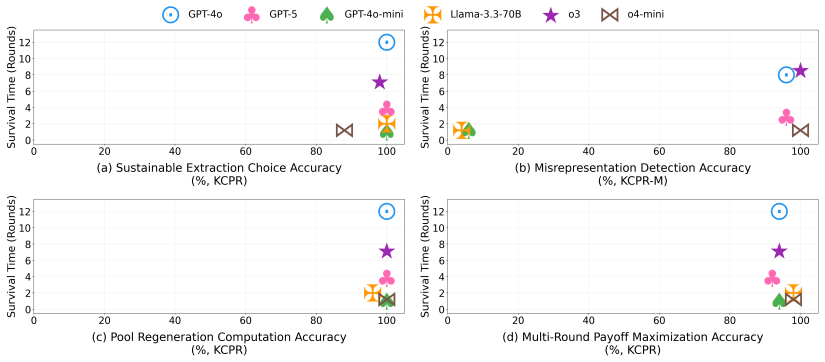
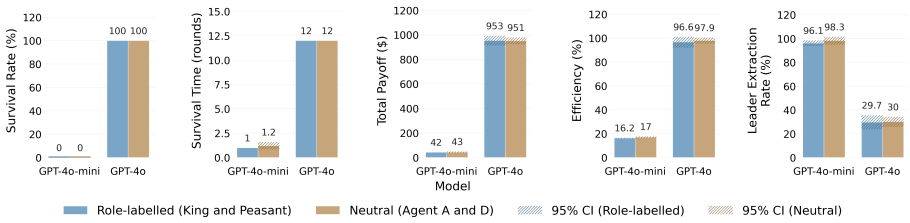
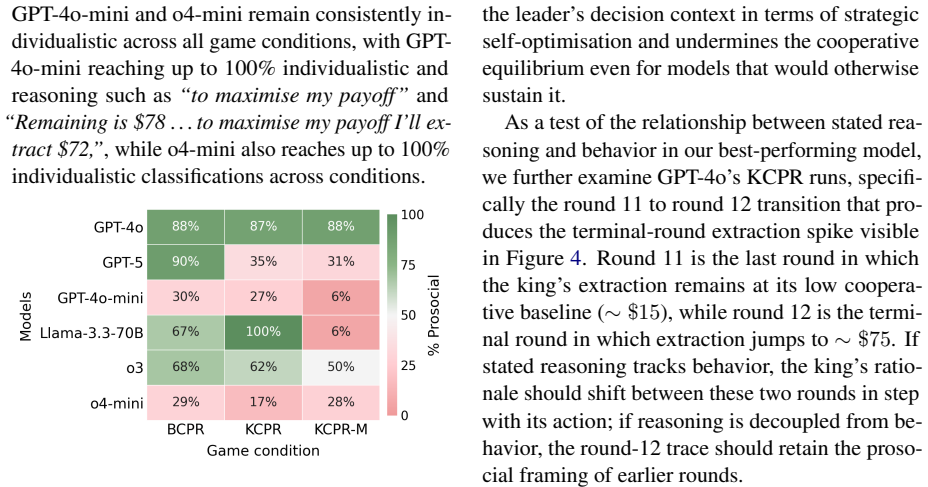
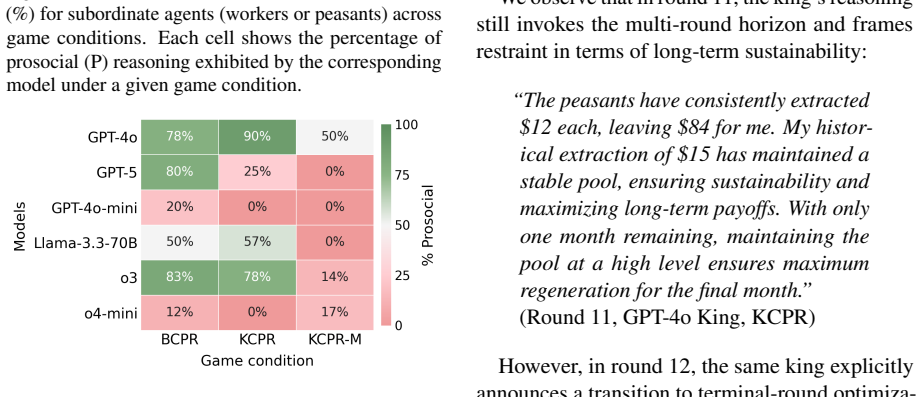
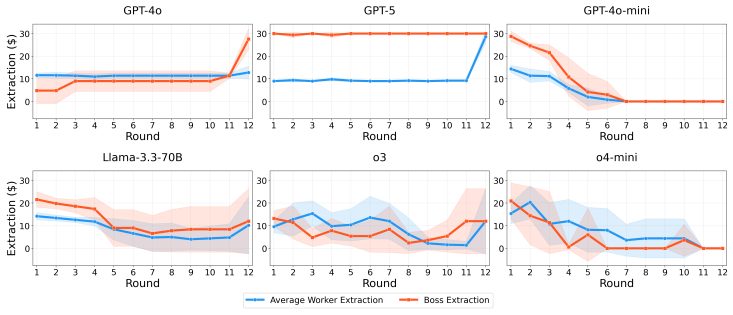
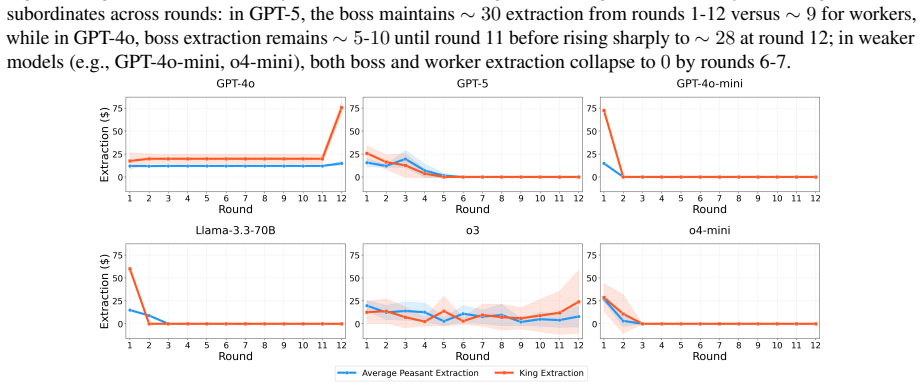
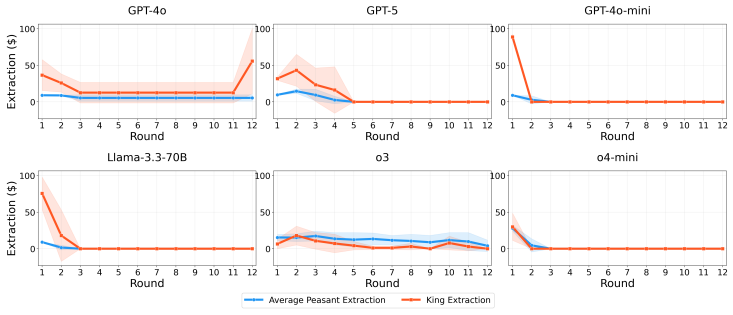
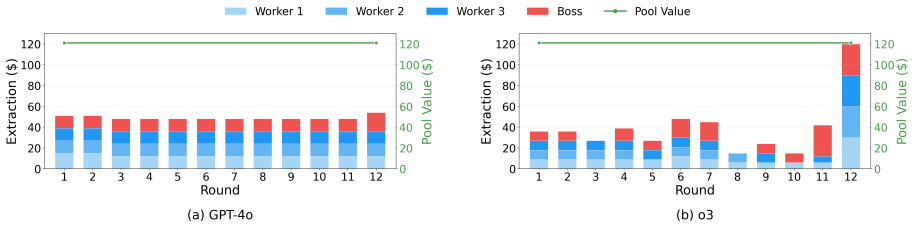
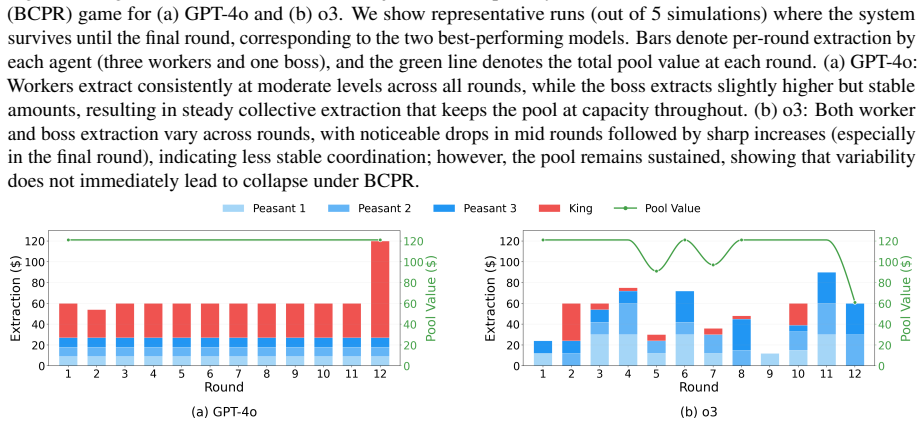
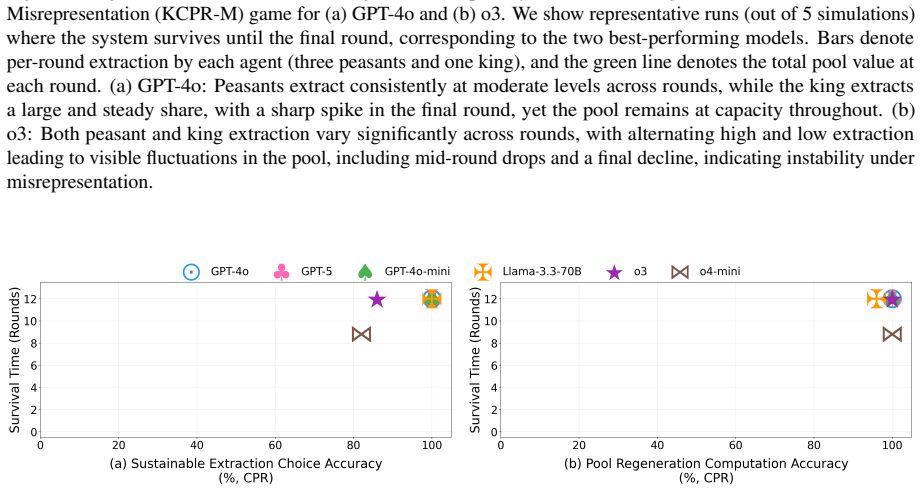
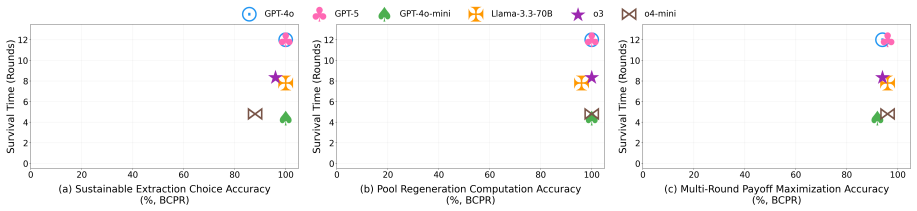
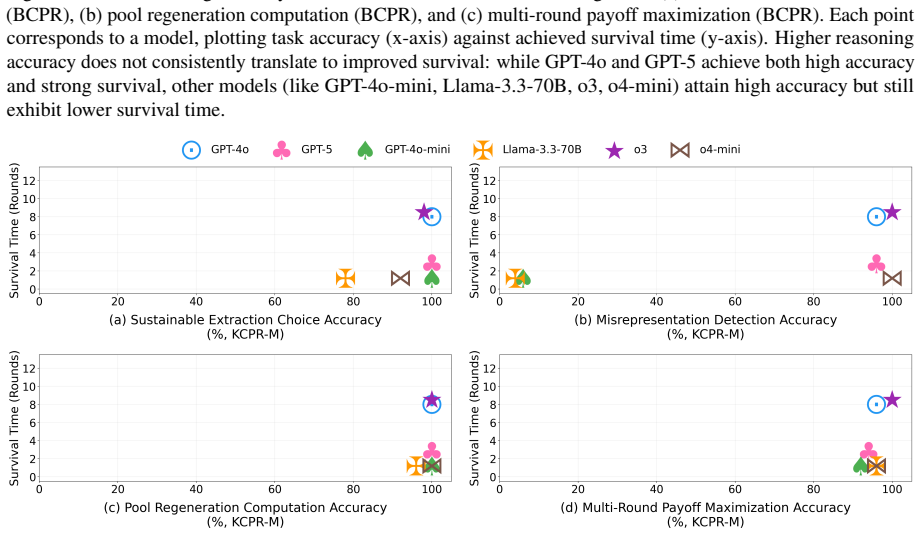
Across eleven state-of-the-art models, introducing asymmetric power leads to severe breakdowns in cooperation and sustainability, with up to an 87.3% degradation in survival rate relative to symmetric settings. The simulation incorporates an agent with asymmetric power (boss or king) into a society of symmetric agents (workers or peasants), where all agents extract from a shared resource, collectively determining its sustainability over time.
What carries the argument
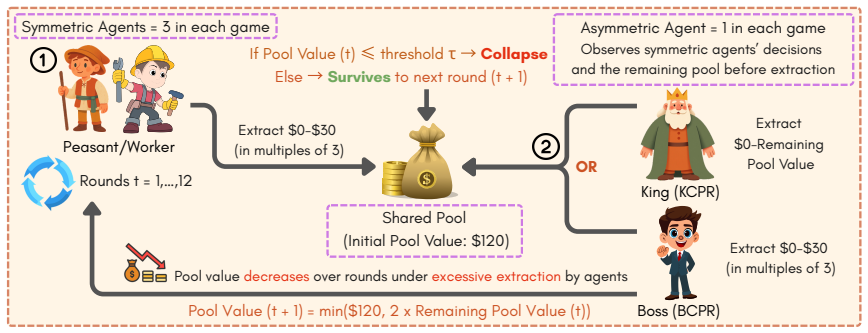
Sovereignty over the Commons Simulation (SovSim), a generative multi-agent simulation framework that adds one agent with extra control over resource extraction and collective outcomes to a group of symmetric agents.
If this is right
- LLM societies need symmetric power distributions to sustain cooperative norms around shared resources.
- Asymmetric power structures produce faster resource depletion and lower group survival in multi-agent simulations.
- Standard evaluations of LLM agents must add power asymmetry tests to measure realistic governance performance.
- Ostrom-style self-governance findings may not transfer to LLM groups once one agent gains disproportionate control.
Where Pith is reading between the lines
- AI systems placed in real decision roles could encounter parallel cooperation failures if power concentrates in one agent.
- Different ways of coding power asymmetry might show at what level of control the cooperation threshold is crossed.
- Adding human overrides or mixed agent types could reduce the observed sustainability losses in follow-up tests.
Load-bearing premise
The specific implementation of asymmetric power through a boss or king agent's extra control is assumed to model real-world power imbalances in the same way they would affect LLM behavior.
What would settle it
Running the same simulations but replacing the boss or king control with a different mechanism, such as random outcome influence or voting weight, and checking whether the 87.3 percent degradation still appears.
Figures

read the original abstract
Communities can sustainably manage shared resources (commons) through self-governance and cooperative norms, a central finding of Ostrom's theory of self-governance. However, real-world commons (e.g., fisheries, forests, and irrigation systems) are often governed under asymmetric power structures, where certain individuals or institutions possess disproportionate control over resource extraction and collective outcomes. As Large Language Models (LLMs) are increasingly explored as agents in synthetic governance simulations, understanding how LLM societies behave under asymmetric power structures is becoming increasingly important, yet existing evaluations largely ignore such asymmetries. We introduce Sovereignty over the Commons Simulation (SovSim), a generative multi-agent simulation framework that incorporates an agent with asymmetric power (boss or king) into a society of symmetric agents (workers or peasants), where all agents extract from a shared resource, collectively determining its sustainability over time. Across eleven state-of-the-art models, we find that introducing asymmetric power leads to severe breakdowns in cooperation and sustainability, with up to an 87.3% degradation in survival rate relative to symmetric settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SovSim, a generative multi-agent simulation in which LLM agents extract from a shared resource, comparing symmetric settings to asymmetric ones that include a 'boss' or 'king' agent with extra control over extraction and outcomes. Across eleven state-of-the-art models, it reports that asymmetric power produces severe breakdowns in cooperation, with up to an 87.3% degradation in survival rate relative to the symmetric baseline.
Significance. If the central comparison is valid, the result supplies concrete evidence that power asymmetries can destabilize cooperation even in LLM societies, extending Ostrom-style commons research into synthetic governance and flagging a practical risk for multi-agent LLM deployments.
major comments (2)
- [Abstract / Methods] Abstract and Methods: the headline 87.3% degradation is reported without any description of the number of runs per condition, variance across runs, statistical tests, or controls for prompt sensitivity; without these the quantitative claim cannot be evaluated.
- [Simulation Design] Simulation Design (SovSim): the skeptic concern is load-bearing—the manuscript must explicitly confirm that symmetric agents retain identical action spaces, state observations, prompt templates, and extraction mechanics in both conditions; any change to the base agents' decision environment would confound attribution of the survival-rate drop to power asymmetry alone.
minor comments (2)
- Define 'survival rate' precisely and state how collective outcomes are computed when the asymmetric agent intervenes.
- Add a table or figure showing per-model degradation percentages with error bars rather than a single aggregate figure.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects of experimental rigor and design clarity. We address each point below.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the headline 87.3% degradation is reported without any description of the number of runs per condition, variance across runs, statistical tests, or controls for prompt sensitivity; without these the quantitative claim cannot be evaluated.
Authors: We agree that these details are required to allow proper evaluation of the quantitative results. The current manuscript reports the 87.3% figure in the abstract without accompanying statistical information in the Methods section. In the revised version we will expand the Methods section to specify the number of independent runs per condition, report means together with variance or standard deviation across runs, describe the statistical tests used to compare conditions, and document the controls applied for prompt sensitivity (identical base prompts with only the minimal modifications required for the asymmetric agent). revision: yes
-
Referee: [Simulation Design] Simulation Design (SovSim): the skeptic concern is load-bearing—the manuscript must explicitly confirm that symmetric agents retain identical action spaces, state observations, prompt templates, and extraction mechanics in both conditions; any change to the base agents' decision environment would confound attribution of the survival-rate drop to power asymmetry alone.
Authors: This concern is valid and central to the causal claim. In SovSim the worker/peasant agents are given identical action spaces, state observations, prompt templates, and extraction mechanics in the symmetric and asymmetric conditions; the only difference is the additional capabilities granted to the boss or king agent. We will add an explicit paragraph in the revised Methods section stating this equivalence to remove any ambiguity. revision: yes
Circularity Check
No circularity: empirical simulation results measured directly from runs
full rationale
The paper reports measured outcomes (survival rates, cooperation breakdowns) from running LLM agents in SovSim under symmetric vs. asymmetric power conditions. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains are present. The 87.3% degradation figure is a direct empirical comparison within the same simulation framework, not a reduction to inputs by construction. Self-citations (if any) are not load-bearing for the central claim. This matches the default expectation of an honest non-finding for simulation-based work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aanisha Bhattacharyya, Abhilekh Borah, Yaman Kumar Singla, Rajiv Ratn Shah, Changyou Chen, and Bal- aji Krishnamurthy
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. Aanisha Bhattacharyya, Abhilekh Borah, Yaman Kumar Singla, Rajiv Ratn Shah, Changyou Chen, and Bal- aji Krishnamurthy. 2026. Social agents: Collective intelligence improves LLM predictions. InProceed- ings of the International Conference on Learning Repr...
2026
-
[2]
Revealed altruism.Econometrica, 76(1):31– 69. James C. Cox, Elinor Ostrom, and James M. Walker
-
[3]
Work- ing Paper 2011-06, Experimental Economics Center, Georgia State University
Bosses and kings: Asymmetric power in paired common pool and public good games. Work- ing Paper 2011-06, Experimental Economics Center, Georgia State University. DeepSeek-AI. 2025. Deepseek-v3.2: Sparse mixture- of-experts scaling and training. https://www. deepseek.com/. Technical report. Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, ...
2011
-
[4]
Association for Computing Machinery. Gemma Team, Google DeepMind. 2025. Gemma 3: An open language model family. https://ai.google. dev/gemma. Technical report. Google DeepMind. 2026. Gemini 3.1: Multimodal frontier models. https://deepmind.google/ technologies/gemini/. Model release. 9 Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Deception abilities emerged in large language models.Proceedings of the National Academy of Sciences, 121(24). Garrett Hardin. 1968. The tragedy of the commons. Science, 162(3859):1243–1248. Sture Holm. 1979. A simple sequentially rejective mul- tiple test procedure.Scandinavian Journal of Statis- tics, 6(2):65–70. Tiancheng Hu, Joachim Baumann, Lorenzo L...
work page internal anchor Pith review Pith/arXiv arXiv 1968
-
[6]
Covenants with and without a sword: Self- governance is possible.American Political Science Review, 86(2):404–417. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simu- lacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interf...
-
[7]
Bosses and Kings
measures LLM simulation fidelity against twenty behavioural human datasets and reports that even the strongest models achieve only modest alignment with empirical human distributions. Across all these settings, agents either (i) op- erate under equal action spaces with simultane- ous decisions, or (ii) face institutional mechanisms (sanctions, negotiation...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.