Reducing the GPU Memory Bottleneck with Lossless Compression for ML -- Extended
Pith reviewed 2026-06-28 23:29 UTC · model grok-4.3
The pith
Invariant Bit Packing removes constant bits from ML tensors to cut PCIe transfer times without losing accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
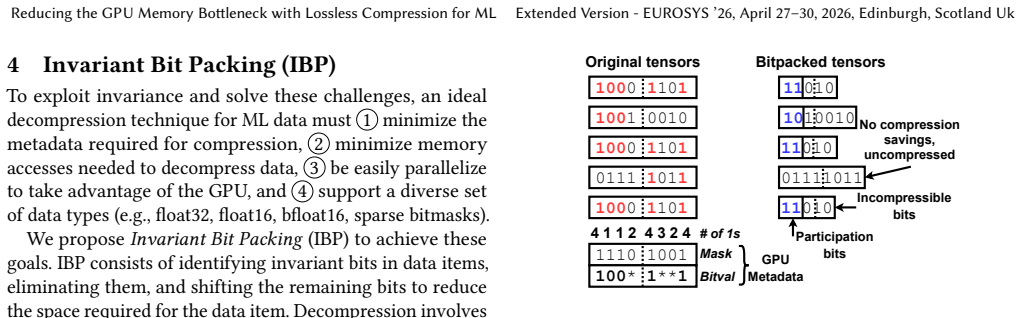
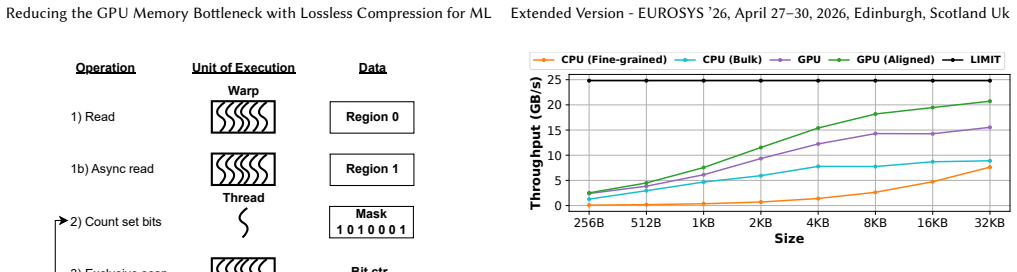
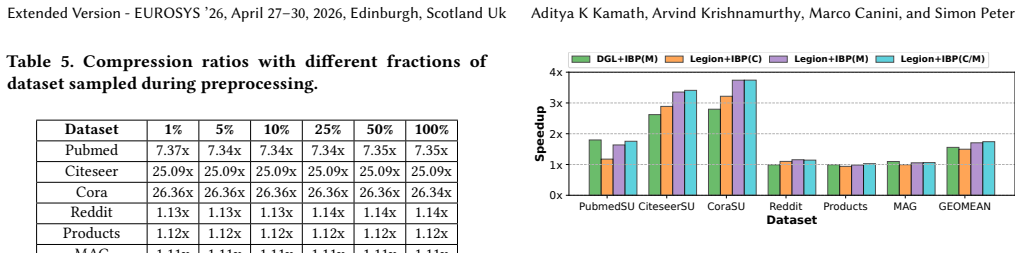
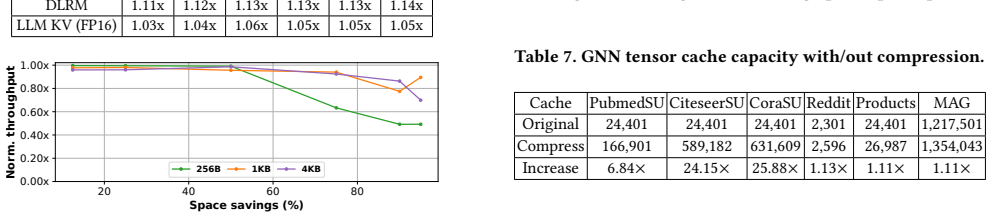
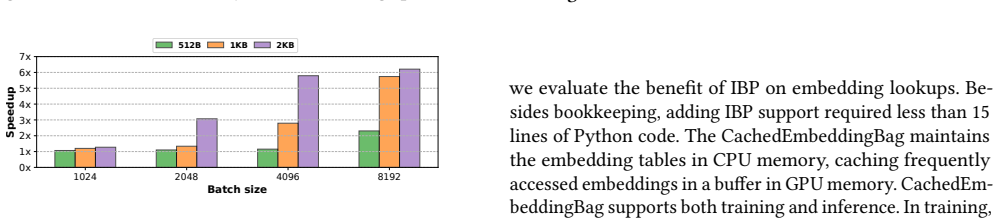
IBP identifies and eliminates invariant bits across groups of tensors, improving throughput through GPU-optimized decompression that leverages warp parallelism, low-overhead bit operations, and asynchronous PCIe transfers. We provide easy-to-use APIs, showcasing them by adding IBP support to GNN training, as well as DLRM and LLM inference frameworks. IBP achieves, on average, 74% faster GNN training, 180% faster DLRM embedding lookup, and 24% faster LLM inference.
What carries the argument
Invariant Bit Packing (IBP), which finds invariant bits across tensor groups and uses warp-parallel GPU decompression to minimize transfer overhead.
If this is right
- 74% faster GNN training on average
- 180% faster DLRM embedding lookup
- 24% faster LLM inference
- Integration into existing ML frameworks via simple APIs without changing model accuracy
Where Pith is reading between the lines
- Similar bit-invariance patterns might appear in other high-throughput data pipelines beyond ML, such as scientific simulations.
- Reducing transfer volume could lower power consumption on systems where PCIe links dominate energy use.
- The approach might combine with existing memory management techniques to support even larger models.
Load-bearing premise
ML tensors contain enough invariant bits across groups to yield meaningful compression ratios while decompression overhead remains low enough not to offset the transfer savings.
What would settle it
Running IBP on a dataset of random or highly variable tensors and measuring if the net time savings become negative or zero would disprove the practical benefit.
Figures






read the original abstract
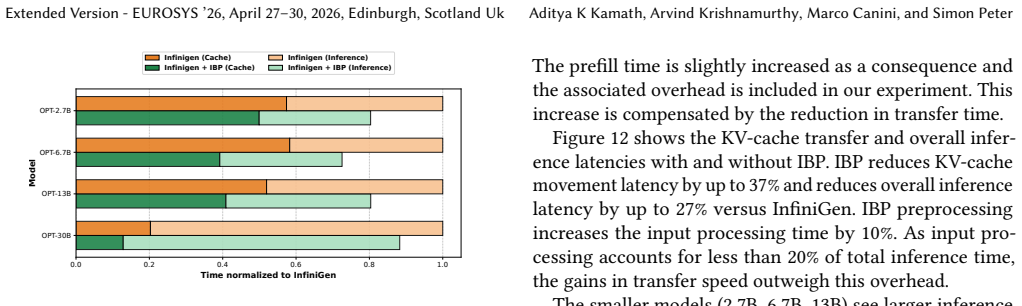
Machine learning (ML) training and inference often process data sets far exceeding GPU memory capacity, forcing them to rely on PCIe for on-demand tensor transfers, causing critical transfer bottlenecks. Lossy compression has been proposed to relieve bottlenecks but introduces workload-dependent accuracy loss, making it complex or even prohibitive to use in existing ML deployments. We explore lossless compression as an alternative that avoids this deployment complexity. We identify where lossless compression can be integrated into ML pipelines while minimizing interference with GPU execution. Based on our findings, we introduce Invariant Bit Packing (IBP), a novel lossless compression algorithm designed to minimize data transfer time for ML. IBP identifies and eliminates invariant bits across groups of tensors, improving throughput through GPU-optimized decompression that leverages warp parallelism, low-overhead bit operations, and asynchronous PCIe transfers. We provide easy-to-use APIs, showcasing them by adding IBP support to GNN training, as well as DLRM and LLM inference frameworks. IBP achieves, on average, 74% faster GNN training, 180% faster DLRM embedding lookup, and 24% faster LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Invariant Bit Packing (IBP), a lossless compression algorithm that identifies and eliminates invariant bits across groups of ML tensors to reduce PCIe transfer bottlenecks when datasets exceed GPU memory. It integrates IBP into GNN training, DLRM, and LLM inference frameworks via GPU-optimized decompression leveraging warp parallelism and asynchronous transfers, and reports average speedups of 74% for GNN training, 180% for DLRM embedding lookup, and 24% for LLM inference.
Significance. If the empirical results hold after providing the necessary supporting measurements, this could be a significant contribution to memory-constrained ML systems by offering a deployable lossless alternative that avoids the accuracy and complexity issues of lossy compression. The provision of easy-to-use APIs and concrete framework integrations is a clear strength.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): The central performance claims (74% GNN, 180% DLRM, 24% LLM) rest on IBP producing compression ratios whose PCIe savings exceed decompression overhead, yet no measured compression ratios, per-tensor-group invariant-bit statistics, or latency breakdown (decompression time vs. transfer savings) are supplied, so the core assumption cannot be verified for the reported workloads.
- [§4] §4 (Evaluation): No baselines, run-to-run variance, or workload descriptions are provided for the speedups, which are load-bearing for assessing whether the results generalize or are driven by atypical tensors.
minor comments (1)
- [§3] The description of warp-level bit operations in the decompression kernel could include a small code snippet or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in the supporting measurements and experimental details needed to substantiate the reported speedups. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): The central performance claims (74% GNN, 180% DLRM, 24% LLM) rest on IBP producing compression ratios whose PCIe savings exceed decompression overhead, yet no measured compression ratios, per-tensor-group invariant-bit statistics, or latency breakdown (decompression time vs. transfer savings) are supplied, so the core assumption cannot be verified for the reported workloads.
Authors: We agree that the core assumption requires explicit verification. In the revised manuscript we will add a dedicated subsection (or table) in §4 reporting: average compression ratios per workload, per-tensor-group invariant-bit counts (mean and distribution), and a latency breakdown separating decompression time from PCIe transfer savings. These data will confirm that net PCIe savings exceed overhead for the evaluated cases. revision: yes
-
Referee: [§4] §4 (Evaluation): No baselines, run-to-run variance, or workload descriptions are provided for the speedups, which are load-bearing for assessing whether the results generalize or are driven by atypical tensors.
Authors: We acknowledge the omission. The revised §4 will include: (i) uncompressed PCIe transfer baselines, (ii) standard deviations from multiple runs (minimum 5), and (iii) expanded workload descriptions covering dataset sizes, model dimensions, tensor shapes, and hardware configuration. This will allow readers to evaluate generalizability. revision: yes
Circularity Check
No circularity; claims are empirical measurements of a compression algorithm
full rationale
The paper presents IBP as a new lossless compression method that packs invariant bits across tensor groups and evaluates it via runtime measurements on GNN training, DLRM lookup, and LLM inference. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. All headline speedups (74% GNN, 180% DLRM, 24% LLM) are reported as direct experimental outcomes rather than derived quantities that reduce to the input data by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https: //docs.nvidia.com/cuda/cuda-c-programming-guide#compressible- memory
Cuda c++ programming guide: Compressible memory. https: //docs.nvidia.com/cuda/cuda-c-programming-guide#compressible- memory
-
[2]
https://docs.nvidia.com/cuda/cuda-c-programming-guide/#device- memory-accesses
Cuda c++ programming guide: Device memory accesses. https://docs.nvidia.com/cuda/cuda-c-programming-guide/#device- memory-accesses
-
[3]
https://docs.nvidia.com/cuda/cuda-c-programming- guide/#hardware-implementation
Cuda c++ programming guide: Hardware implementa- tion. https://docs.nvidia.com/cuda/cuda-c-programming- guide/#hardware-implementation
-
[4]
https://docs.nvidia
Cuda c++ programming guide: Mapped memory. https://docs.nvidia. com/cuda/cuda-c-programming-guide/#mapped-memory
-
[5]
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ dle/models/dlrm_base_tf2_ckpt_ds-criteo-fl15
Dlrm checkpoint. https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ dle/models/dlrm_base_tf2_ckpt_ds-criteo-fl15
-
[6]
https:// developer.nvidia.com/nvcomp
nvcomp: High-speed data compression using nvidia gpus. https:// developer.nvidia.com/nvcomp
-
[7]
Nvidia a100 tensor core gpu.https://www.nvidia.com/content/dam/en- zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us- nvidia-1758950-r4-web.pdf
-
[8]
https://resources.nvidia.com/en-us- tensor-core/nvidia-tensor-core-gpu-datasheet
Nvidia h100 tensor core gpu. https://resources.nvidia.com/en-us- tensor-core/nvidia-tensor-core-gpu-datasheet
-
[9]
https://images.nvidia.com/content/ technologies/volta/pdf/volta-v100-datasheet-update-us-1165301- r5.pdf
Nvidia v100 tensor core gpu. https://images.nvidia.com/content/ technologies/volta/pdf/volta-v100-datasheet-update-us-1165301- r5.pdf
-
[10]
https://www.nvidia.com/en-in/data-center/ nvlink/
Nvlink and nvlink switch. https://www.nvidia.com/en-in/data-center/ nvlink/
-
[11]
https://labs.criteo.com/2013/12/download- terabyte-click-logs-2/
Terabyte click logs. https://labs.criteo.com/2013/12/download- terabyte-click-logs-2/
2013
-
[12]
Understanding training efficiency of deep learning recommendation models at scale
Bilge Acun, Matthew Murphy, Xiaodong Wang, Jade Nie, Carole-Jean Wu, and Kim Hazelwood. Understanding training efficiency of deep learning recommendation models at scale. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 802–814, 2021
2021
-
[13]
Accelerating gpu data processing using fastlanes compression
Azim Afroozeh, Lotte Felius, and Peter Boncz. Accelerating gpu data processing using fastlanes compression. In Proceedings of the 20th In- ternational Workshop on Data Management on New Hardware , DaMoN ’24, New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[14]
Bagpipe: Accelerating deep recommendation model training
Saurabh Agarwal, Chengpo Yan, Ziyi Zhang, and Shivaram Venkatara- man. Bagpipe: Accelerating deep recommendation model training. In Proceedings of the 29th Symposium on Operating Systems Principles , SOSP ’23, page 348–363, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[15]
Graph neural network training systems: A performance comparison of full-graph and mini-batch
Saurabh Bajaj, Hojae Son, Juelin Liu, Hui Guan, and Marco Serafini. Graph neural network training systems: A performance comparison of full-graph and mini-batch. In Proceedings of the VLDB Endowment , volume 18, page 1196–1209. VLDB Endowment, December 2024
2024
-
[16]
Aware: Workload-aware, redundancy-exploiting linear algebra
Sebastian Baunsgaard and Matthias Boehm. Aware: Workload-aware, redundancy-exploiting linear algebra. In Proceedings of the ACM on Management of Data, volume 1, New York, NY, USA, May 2023. Asso- ciation for Computing Machinery
2023
-
[17]
Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking
Aleksandar Bojchevski and Stephan Günnemann. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. In International Conference on Learning Representations , 2018
2018
-
[18]
Molecular generative graph neural networks for drug discovery.Neurocomputing, 450:242–252, 2021
Pietro Bongini, Monica Bianchini, and Franco Scarselli. Molecular generative graph neural networks for drug discovery.Neurocomputing, 450:242–252, 2021
2021
-
[19]
Fcbench: Cross-domain benchmarking of lossless compression for floating-point data
Xinyu Chen, Jiannan Tian, Ian Beaver, Cynthia Freeman, Yan Yan, Jian- guo Wang, and Dingwen Tao. Fcbench: Cross-domain benchmarking of lossless compression for floating-point data. In Proceedings of the VLDB Endowment, volume 17, page 1418–1431. VLDB Endowment, may 2024
2024
-
[20]
Learned image compression with discretized gaussian mixture likeli- hoods and attention modules
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto. Learned image compression with discretized gaussian mixture likeli- hoods and attention modules. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , June 2020
2020
-
[21]
The trade-offs of model size in large recommendation models : 100gb to 10mb criteo-tb dlrm model
Aditya Desai and Anshumali Shrivastava. The trade-offs of model size in large recommendation models : 100gb to 10mb criteo-tb dlrm model. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages 33961–33972. Curran Associates, Inc., 2022
2022
-
[22]
Gpt3.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3.int8(): 8-bit matrix multiplication for transformers at scale. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages 30318–30332. Curran Associates, Inc., 2022
2022
-
[23]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 10088–10115. Curran Associates, Inc., 2023. 16 Reducing the GPU Memory Bottleneck with Lossl...
2023
-
[24]
Accuracy is not all you need
Abhinav Dutta, Sanjeev Krishnan, Nipun Kwatra, and Ramachandran Ramjee. Accuracy is not all you need. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems , volume 37, pages 124347–124390. Curran Associates, Inc., 2024
2024
-
[25]
Haas, Frederick R
Ahmed Elgohary, Matthias Boehm, Peter J. Haas, Frederick R. Reiss, and Berthold Reinwald. Compressed linear algebra for large-scale machine learning. In Proceedings of the VLDB Endowment , volume 9, page 960–971. VLDB Endowment, August 2016
2016
-
[26]
Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression
Ruibo Fan, Xiangrui Yu, Xinglin Pan, Zeyu Li, Weile Luo, Qiang Wang, Wei Wang, and Xiaowen Chu. Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’26, page 2264–2280, Ne...
2026
-
[27]
A frequency-aware software cache for large recommendation system embeddings
Jiarui Fang, Geng Zhang, Jiatong Han, Shenggui Li, Zhengda Bian, Yongbin Li, Jin Liu, and Yang You. A frequency-aware software cache for large recommendation system embeddings. arXiv preprint arXiv:2208.05321, 2022
-
[28]
Sahu, Marco Canini, and Amedeo Sapio
Jiawei Fei, Chen-Yu Ho, Atal N. Sahu, Marco Canini, and Amedeo Sapio. Efficient sparse collective communication and its application to accelerate distributed deep learning. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, SIGCOMM ’21, page 676–691, New York, NY, USA, 2021. Association for Computing Machinery
2021
-
[29]
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Hao Feng, Boyuan Zhang, Fanjiang Ye, Min Si, Ching-Hsiang Chu, Jiannan Tian, Chunxing Yin, Summer Deng, Yuchen Hao, Pavan Balaji, Tong Geng, and Dingwen Tao. Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression . In 2024 SC24: International Conference for High Performance Computing, Networkin...
2024
-
[30]
Mahoney, and Kurt Keutzer
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W. Mahoney, and Kurt Keutzer. Ai and memory wall.IEEE Micro, 44(3):33– 39, 2024
2024
-
[31]
Lee, David Brooks, and Carole- Jean Wu
Udit Gupta, Samuel Hsia, Vikram Saraph, Xiaodong Wang, Brandon Reagen, Gu-Yeon Wei, Hsien-Hsin S. Lee, David Brooks, and Carole- Jean Wu. Deeprecsys: A system for optimizing end-to-end at-scale neural recommendation inference. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA) , pages 982– 995, 2020
2020
-
[32]
Inductive representa- tion learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representa- tion learning on large graphs. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Ad- vances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017
2017
-
[33]
How to optimize data transfers in cuda c/c++
Mark Harris. How to optimize data transfers in cuda c/c++. https: //developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
-
[34]
Natural compression for distributed deep learning
Samuel Horvóth, Chen-Yu Ho, Ludovit Horvath, Atal Narayan Sahu, Marco Canini, and Peter Richtarik. Natural compression for distributed deep learning. In Proceedings of Mathematical and Scientific Machine Learning, volume 190 of Proceedings of Machine Learning Research , pages 129–141. PMLR, 15–17 Aug 2022
2022
-
[35]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 22118–22133. Curran Associates, Inc., 2020
2020
-
[36]
David A. Huffman. A method for the construction of minimum- redundancy codes. In Proceedings of the IRE , volume 40, pages 1098– 1101, 1952
1952
-
[37]
Grow: A row-stationary sparse-dense gemm accelerator for memory-efficient graph convolutional neural networks
Ranggi Hwang, Minhoo Kang, Jiwon Lee, Dongyun Kam, Youngjoo Lee, and Minsoo Rhu. Grow: A row-stationary sparse-dense gemm accelerator for memory-efficient graph convolutional neural networks. In 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 42–55, 2023
2023
-
[38]
An extended compression format for the optimization of sparse matrix-vector multiplication.IEEE Trans- actions on Parallel and Distributed Systems , 24(10):1930–1940, October 2013
Vasileios Karakasis, Theodoros Gkountouvas, Kornilios Kourtis, Geor- gios Goumas, and Nectarios Koziris. An extended compression format for the optimization of sparse matrix-vector multiplication.IEEE Trans- actions on Parallel and Distributed Systems , 24(10):1930–1940, October 2013
1930
-
[39]
Tensorfloat-32 in the a100 gpu accelerates ai training, hpc up to 20x
Paresh Kharya. Tensorfloat-32 in the a100 gpu accelerates ai training, hpc up to 20x. https://blogs.nvidia.com/blog/tensorfloat-32-precision- format/
-
[40]
Datasets for benchmarking floating-point compressors, 2020
Fabian Knorr, Peter Thoman, and Thomas Fahringer. Datasets for benchmarking floating-point compressors, 2020
2020
-
[41]
ndzip-gpu: ef- ficient lossless compression of scientific floating-point data on gpus
Fabian Knorr, Peter Thoman, and Thomas Fahringer. ndzip-gpu: ef- ficient lossless compression of scientific floating-point data on gpus. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , SC ’21, New York, NY, USA, 2021. Association for Computing Machinery
2021
-
[42]
Webb, Xin Wang, Marcel Nassar, Arjun K
Urs Köster, Tristan J. Webb, Xin Wang, Marcel Nassar, Arjun K. Bansal, William H. Constable, Oğuz H. Elibol, Scott Gray, Stewart Hall, Luke Hornof, Amir Khosrowshahi, Carey Kloss, Ruby J. Pai, and Naveen Rao. Flexpoint: an adaptive numerical format for efficient training of deep neural networks. In Proceedings of the 31st International Conference on Neura...
2017
-
[43]
Splitrpc: A Control + Data path splitting rpc stack for ml inference serving
Adithya Kumar, Anand Sivasubramaniam, and Timothy Zhu. Splitrpc: A Control + Data path splitting rpc stack for ml inference serving. SIGMETRICS Perform. Eval. Rev., 51(1):13–14, June 2023
2023
-
[44]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[45]
InfiniGen: Efficient generative inference of large language models with dynamic KV cache management
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages 155–172, Santa Clara, CA, July 2024. USENIX Association
2024
-
[46]
Naughton, and Jignesh M
Fengan Li, Lingjiao Chen, Yijing Zeng, Arun Kumar, Xi Wu, Jeffrey F. Naughton, and Jignesh M. Patel. Tuple-oriented compression for large- scale mini-batch stochastic gradient descent. In Proceedings of the 2019 International Conference on Management of Data , SIGMOD ’19, page 1517–1534, New York, NY, USA, 2019. Association for Computing Machinery
2019
-
[47]
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Minghao Li, Ran Ben Basat, Shay Vargaftik, ChonLam Lao, Kevin Xu, Michael Mitzenmacher, and Minlan Yu. THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression. In USENIX Symposium on Networked Systems Design and Implementation (NSDI) , 2024
2024
-
[48]
Colossal-ai: A unified deep learning system for large-scale parallel training
Shenggui Li, Hongxin Liu, Zhengda Bian, Jiarui Fang, Haichen Huang, Yuliang Liu, Boxiang Wang, and Yang You. Colossal-ai: A unified deep learning system for large-scale parallel training. In Proceedings of the 52nd International Conference on Parallel Processing , ICPP ’23, page 766–775, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[49]
Yinan Li and Jignesh M. Patel. Bitweaving: fast scans for main memory data processing. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data , SIGMOD ’13, page 289–300, New York, NY, USA, 2013. Association for Computing Machinery
2013
-
[50]
Recoil: Parallel rans decoding with decoder-adaptive scalability
Fangzheng Lin, Kasidis Arunruangsirilert, Heming Sun, and Jiro Katto. Recoil: Parallel rans decoding with decoder-adaptive scalability. In 17 Extended Version - EUROSYS ’26, April 27–30, 2026, Edinburgh, Scotland Uk Aditya K Kamath, Arvind Krishnamurthy, Marco Canini, and Simon Peter Proceedings of the 52nd International Conference on Parallel Process- in...
2026
-
[51]
Using cuda warp-level primitives
Yuan Lin and Vinod Grover. Using cuda warp-level primitives. https: //developer.nvidia.com/blog/using-cuda-warp-level-primitives/
-
[52]
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William Dally. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. In International Conference on Learning Repre- sentations, 2018
2018
-
[53]
Pa- graph: Scaling gnn training on large graphs via computation-aware caching
Zhiqi Lin, Cheng Li, Youshan Miao, Yunxin Liu, and Yinlong Xu. Pa- graph: Scaling gnn training on large graphs via computation-aware caching. In Proceedings of the 11th ACM Symposium on Cloud Comput- ing, SoCC ’20, page 401–415, New York, NY, USA, 2020. Association for Computing Machinery
2020
-
[54]
Indigo: Gnn-based inductive knowledge graph completion using pair-wise encoding
Shuwen Liu, Bernardo Grau, Ian Horrocks, and Egor Kostylev. Indigo: Gnn-based inductive knowledge graph completion using pair-wise encoding. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 2034–2045. Curran Associates, Inc., 2021
2034
-
[55]
BGL: GPU-Efficient GNN training by optimizing graph data I/O and preprocessing
Tianfeng Liu, Yangrui Chen, Dan Li, Chuan Wu, Yibo Zhu, Jun He, Yanghua Peng, Hongzheng Chen, Hongzhi Chen, and Chuanxiong Guo. BGL: GPU-Efficient GNN training by optimizing graph data I/O and preprocessing. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) , pages 103–118, Boston, MA, April 2023. USENIX Association
2023
-
[56]
Pick and choose: A gnn-based imbalanced learning approach for fraud detection
Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. Pick and choose: A gnn-based imbalanced learning approach for fraud detection. InProceedings of the Web Conference 2021, WWW ’21, page 3168–3177, New York, NY, USA, 2021. Association for Computing Machinery
2021
-
[57]
Cachegen: Kv cache compression and streaming for fast large language model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. Cachegen: Kv cache compression and streaming for fast large language model serving. In Proceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, page...
2024
-
[59]
Dvc: An end-to-end deep video compression framework
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. Dvc: An end-to-end deep video compression framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[60]
Eliminating data processing bottlenecks in gnn training over large graphs via two-level feature compression
Yuxin Ma, Ping Gong, Tianming Wu, Jiawei Yi, Chengru Yang, Cheng Li, Qirong Peng, Guiming Xie, Yongcheng Bao, Haifeng Liu, and Yin- long Xu. Eliminating data processing bottlenecks in gnn training over large graphs via two-level feature compression. In Proceedings of the VLDB Endowment, volume 17, page 2854–2866. VLDB Endowment, August 2024
2024
-
[61]
Bifeat: Supercharge gnn training via graph feature quantization
Yuxin Ma, Ping Gong, Jun Yi, Zhewei Yao, Cheng Li, Yuxiong He, and Feng Yan. Bifeat: Supercharge gnn training via graph feature quantization. arXiv preprint arXiv:2207.14696, 2023
-
[62]
Emogi: efficient memory- access for out-of-memory graph-traversal in gpus
Seung Won Min, Vikram Sharma Mailthody, Zaid Qureshi, Jinjun Xiong, Eiman Ebrahimi, and Wen-mei Hwu. Emogi: efficient memory- access for out-of-memory graph-traversal in gpus. In Proceedings of the VLDB Endowment, volume 14, page 114–127. VLDB Endowment, October 2020
2020
-
[63]
Dheevatsa Mudigere, Yuchen Hao, Jianyu Huang, Zhihao Jia, Andrew Tulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jade Nie, Jongsoo Park, Liang Luo, Jie (Amy) Yang, Leon Gao, Dmytro Ivchenko, Aarti Basant, Yuxi Hu, Jiyan Yang, Ehsan K. Ardestani, Xiaodong Wang, Rakesh Komuravelli, Ching-Hsiang Chu, Serhat Yilmaz, Huayu Li, Jiyuan Qian, Zhuobo Feng, Y...
-
[64]
Association for Computing Machinery
-
[65]
Query-driven active surveying for collective classification
Galileo Mark Namata, Ben London, Lise Getoor, and Bert Huang. Query-driven active surveying for collective classification. In Work- shop on Mining and Learning with Graphs , 2012
2012
-
[66]
Patel, Yao Zhang, Jason Mak, Andrew Davidson, and John D
Ritesh A. Patel, Yao Zhang, Jason Mak, Andrew Davidson, and John D. Owens. Parallel lossless data compression on the gpu. In 2012 Innova- tive Parallel Computing (InPar), pages 1–9, 2012
2012
-
[67]
Gpu-initiated on-demand high-throughput storage access in the BaM system architecture
Zaid Qureshi, Vikram Sharma Mailthody, Isaac Gelado, Seung Won Min, Amna Masood, Jeongmin Park, Jinjun Xiong, CJ Newburn, Dmitri Vainbrand, I-Hsin Chung, Michael Garland, William Dally, and Wen- mei Hwu. Gpu-initiated on-demand high-throughput storage access in the BaM system architecture. In Proceedings of the Twenty-Eigth International Conference on Arc...
2023
-
[68]
Real-time adaptive image com- pression
Oren Rippel and Lubomir Bourdev. Real-time adaptive image com- pression. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning , volume 70 of Proceedings of Machine Learning Research , pages 2922–2930. PMLR, 06–11 Aug 2017
2017
-
[69]
Faster across the pcie bus: a gpu library for lightweight decompression: including support for patched compression schemes
Eyal Rozenberg and Peter Boncz. Faster across the pcie bus: a gpu library for lightweight decompression: including support for patched compression schemes. InProceedings of the 13th International Workshop on Data Management on New Hardware , DAMON ’17, New York, NY, USA, 2017. Association for Computing Machinery
2017
-
[70]
Collective classification in network data
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI Magazine, 29(3):93, Sep. 2008
2008
-
[71]
Scalable graph neural network training: The case for sampling
Marco Serafini and Hui Guan. Scalable graph neural network training: The case for sampling. SIGOPS Oper. Syst. Rev., 55(1), 2021
2021
-
[72]
Yogatama, Xiangyao Yu, and Samuel Madden
Anil Shanbhag, Bobbi W. Yogatama, Xiangyao Yu, and Samuel Madden. Tile-based lightweight integer compression in gpu. In Proceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, page 1390–1403, New York, NY, USA, 2022. Association for Computing Machinery
2022
-
[73]
FlexGen: High-throughput generative inference of large language mod- els with a single GPU
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Re, Ion Stoica, and Ce Zhang. FlexGen: High-throughput generative inference of large language mod- els with a single GPU. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of ...
2023
-
[74]
Ugache: A unified gpu cache for embedding-based deep learning
Xiaoniu Song, Yiwen Zhang, Rong Chen, and Haibo Chen. Ugache: A unified gpu cache for embedding-based deep learning. In Proceed- ings of the 29th Symposium on Operating Systems Principles , SOSP ’23, page 627–641, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[75]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568(C), February 2024
2024
-
[76]
Legion: Automatically pushing the envelope of Multi-GPU system for Billion- Scale GNN training
Jie Sun, Li Su, Zuocheng Shi, Wenting Shen, Zeke Wang, Lei Wang, Jie Zhang, Yong Li, Wenyuan Yu, Jingren Zhou, and Fei Wu. Legion: Automatically pushing the envelope of Multi-GPU system for Billion- Scale GNN training. In 2023 USENIX Annual Technical Conference (USENIX ATC 23) , pages 165–179, Boston, MA, July 2023. USENIX Association. 18 Reducing the GPU...
2023
-
[77]
Controlling data move- ment to boost performance on the nvidia ampere architec- ture
Matthieu Tardy and Carter Edwards. Controlling data move- ment to boost performance on the nvidia ampere architec- ture. https://developer.nvidia.com/blog/controlling-data-movement- to-boost-performance-on-ampere-architecture/
-
[78]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Léonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Amélie Héliou, Andrea Tacchetti, Anna Bulanova, Anto...
2024
-
[79]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017
2017
-
[80]
Mariusgnn: Resource-efficient out-of-core training of graph neural networks
Roger Waleffe, Jason Mohoney, Theodoros Rekatsinas, and Shivaram Venkataraman. Mariusgnn: Resource-efficient out-of-core training of graph neural networks. In Proceedings of the Eighteenth European Conference on Computer Systems, EuroSys ’23, page 144–161, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[81]
ZeRO++: Extremely Efficient Collective Communication for Large Model Training
Guanhua Wang, Heyang Qin, Sam Ade Jacobs, Xiaoxia Wu, Connor Holmes, Zhewei Yao, Samyam Rajbhandari, Olatunji Ruwase, Feng Yan, Lei Yang, and Yuxiong He. ZeRO++: Extremely Efficient Collective Communication for Large Model Training. In International Conference on Learning Representations, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.