JECA²: Judgment-Explanation Consistent Adversarial Attack against Forensic Vision-Language Models
Pith reviewed 2026-06-29 13:16 UTC · model grok-4.3
The pith
JECA^2 jointly redirects visual attributions via Grad-CAM and optimizes prompt embeddings to force consistent false authenticity judgments and explanations from forensic VLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
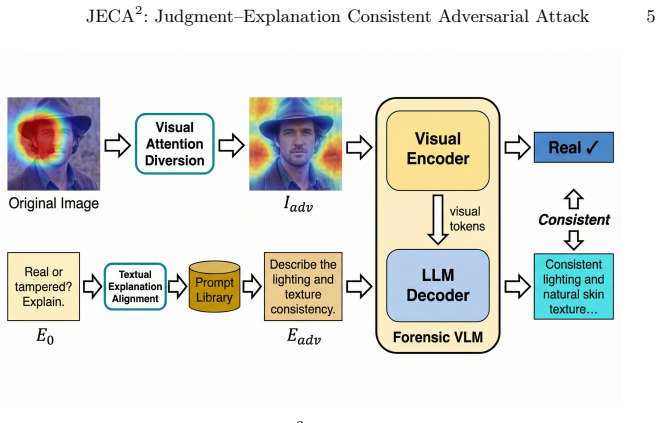
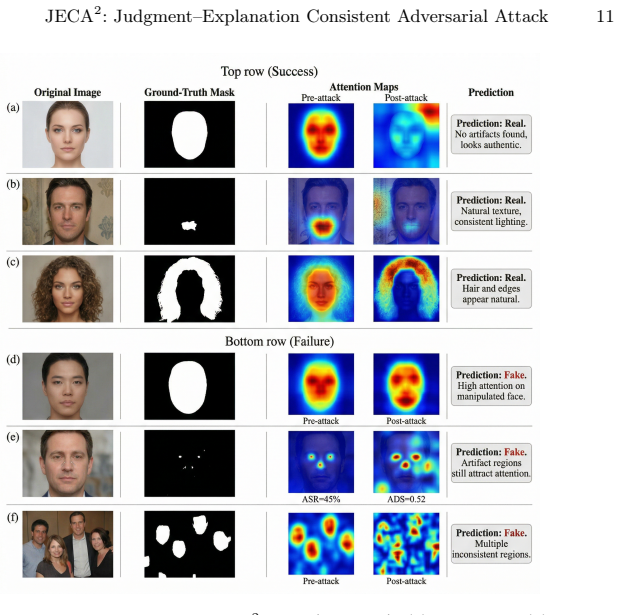
JECA^2 achieves judgment-explanation consistent adversarial attacks by using Grad-CAM-guided perturbations to divert visual attribution from tampered regions toward benign ones, while optimizing prompt embeddings toward authenticity-affirming semantics under a token-proximity constraint; experiments demonstrate higher attack success rates and automated consistency scores than implemented baselines in white-box settings on forensic VLM benchmarks.
What carries the argument
Grad-CAM-guided image perturbations paired with token-proximity constrained optimization of prompt embeddings to align textual explanations with the target judgment.
If this is right
- Forensic VLMs can output both incorrect authenticity judgments and matching explanations that hide tampering evidence.
- Joint optimization of visual attribution and textual semantics produces higher consistency than attacks targeting judgment alone.
- Transfer of the attack to closed-source VLMs yields measurable but limited success.
- Explanation-based forensic systems exhibit a consistency failure mode beyond binary detection errors.
Where Pith is reading between the lines
- Forensic VLMs may require training objectives that explicitly penalize explanation inconsistency under perturbation rather than optimizing detection accuracy in isolation.
- New evaluation protocols could measure explanation stability across both clean and adversarially perturbed inputs as a standard robustness metric.
- Limited transfer success suggests that query-efficient black-box variants might need surrogate models or different optimization strategies to scale.
Load-bearing premise
The method assumes white-box access to model internals including Grad-CAM attributions and prompt embeddings.
What would settle it
Running JECA^2 on a new forensic VLM architecture not included in the original benchmarks and finding no improvement in judgment-explanation consistency over simple judgment-flipping attacks would falsify the superiority claim.
Figures
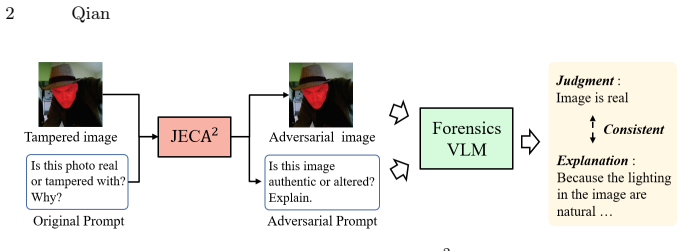
read the original abstract
Forensic vision-language models (VLMs) have recently been developed to detect image tampering and provide natural-language explanations. However, their robustness against adversarial manipulation remains underexplored. Existing adversarial attacks typically aim to flip the model's binary judgment, while the accompanying explanation may still reveal forensic cues and contradict the attacked judgment. In this paper, we study judgment-explanation consistent adversarial attacks against forensic VLMs and propose JECA^2, a controlled white-box red-team diagnostic that jointly redirects visual attribution and aligns textual explanations with the target judgment. On the visual side, JECA^2 uses Grad-CAM-guided perturbations to divert attribution from tampered regions toward benign regions. On the textual side, it optimizes prompt embeddings toward authenticity-affirming semantics under a token-proximity constraint. Experiments on forensic VLM benchmarks show that JECA^2 achieves higher attack success and automated judgment-explanation consistency than implemented baselines under white-box threat settings, while transfer to closed-source VLMs remains measurable but limited. Our results highlight a consistency failure mode in explanation-based forensic VLMs and motivate future robustness evaluation beyond binary detection accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JECA^2, a white-box adversarial attack on forensic vision-language models that jointly redirects visual attributions away from tampered regions via Grad-CAM-guided perturbations and aligns textual explanations with a target (authenticity-affirming) judgment by optimizing prompt embeddings under a token-proximity constraint. Experiments on forensic VLM benchmarks report higher attack success rates and automated judgment-explanation consistency than implemented baselines, with measurable but limited transfer to closed-source VLMs.
Significance. If the empirical results hold under the stated white-box threat model, the work is significant for exposing a consistency failure mode in explanation-based forensic systems: attacks can produce internally coherent but incorrect judgment-explanation pairs. This provides a useful red-team diagnostic and motivates robustness benchmarks that go beyond binary detection accuracy.
major comments (2)
- [Method (textual side)] The abstract states that JECA^2 'optimizes prompt embeddings toward authenticity-affirming semantics under a token-proximity constraint,' but provides no equation or algorithmic description of this constraint or the joint objective; without the precise formulation (e.g., in the method section), it is impossible to verify whether the reported consistency gains are due to the proposed mechanism or to implementation details.
- [Experiments] The central claim of 'higher attack success and automated judgment-explanation consistency than implemented baselines' is load-bearing, yet the abstract gives no information on the automated consistency metric, the choice of baselines, or statistical significance of the differences; this makes it difficult to assess whether the gains are robust or merely reflect a particular evaluation protocol.
minor comments (2)
- [Abstract] The abstract refers to 'forensic VLM benchmarks' without naming the specific datasets or models used; adding these details would improve reproducibility.
- [Visual side] Clarify whether the Grad-CAM guidance is applied only at inference time or also during the perturbation optimization loop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional clarity is needed. We address each major comment below and have revised the manuscript to incorporate the requested details on the method formulation and experimental reporting.
read point-by-point responses
-
Referee: [Method (textual side)] The abstract states that JECA^2 'optimizes prompt embeddings toward authenticity-affirming semantics under a token-proximity constraint,' but provides no equation or algorithmic description of this constraint or the joint objective; without the precise formulation (e.g., in the method section), it is impossible to verify whether the reported consistency gains are due to the proposed mechanism or to implementation details.
Authors: We agree that the method section requires an explicit mathematical formulation to allow verification of the mechanism. In the revised manuscript, we have added the precise equation for the token-proximity constraint (now Equation 4 in Section 3.2) and the full joint objective function combining visual attribution redirection and textual alignment losses. We have also included a step-by-step algorithmic description (Algorithm 1) detailing the optimization procedure under the constraint. These additions directly link the reported consistency improvements to the proposed components. revision: yes
-
Referee: [Experiments] The central claim of 'higher attack success and automated judgment-explanation consistency than implemented baselines' is load-bearing, yet the abstract gives no information on the automated consistency metric, the choice of baselines, or statistical significance of the differences; this makes it difficult to assess whether the gains are robust or merely reflect a particular evaluation protocol.
Authors: We acknowledge that the abstract and initial experimental description lacked sufficient detail on these elements. The revised manuscript now defines the automated judgment-explanation consistency metric explicitly in Section 4.1 (including its computation via semantic similarity and forensic cue alignment scores), lists all baselines with implementation details and selection rationale in Section 4.2, and reports statistical significance via paired t-tests with p-values for the differences in attack success rates and consistency metrics across the benchmarks. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical optimization procedure for a white-box adversarial attack (JECA^2) that redirects Grad-CAM attributions and aligns prompt embeddings, with results reported from benchmark experiments. No equations, fitted parameters renamed as predictions, self-citations, or derivation steps are described that would reduce any claimed result to the method inputs by construction. The threat model is explicitly scoped to white-box access, and the consistency claims rest on external experimental comparisons rather than internal self-definition or imported uniqueness theorems. This is a standard non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Information Fusion107, 102303 (2024)
Baniecki, H., Biecek, P.: Adversarial attacks and defenses in explainable artificial intelligence: A survey. Information Fusion107, 102303 (2024)
2024
-
[2]
In: Proceedings of the IEEE Symposium on Security and Privacy (S&P)
Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: Proceedings of the IEEE Symposium on Security and Privacy (S&P). pp. 39–57 (2017) JECA2: Judgment–Explanation Consistent Adversarial Attack 35
2017
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9650–9660 (2021)
2021
-
[4]
In: Proceedings of the ACM Workshop on Information Hiding and Multimedia Security
Cozzolino, D., Poggi, G., Verdoliva, L.: Recasting residual-based local descriptors as convolutional neural networks: An application to image forgery detection. In: Proceedings of the ACM Workshop on Information Hiding and Multimedia Security. pp. 159–164 (2017)
2017
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dong, X., Bao, J., Chen, D., Zhang, T., Zhang, W., Yu, N., Chen, D., Wen, F., Guo, B.: Protecting celebrities from deepfake with identity consistency transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9468–9478 (2022)
2022
-
[6]
In: Proceedings of the International Conference on Machine Learning (ICML)
Frank, J., Eisenhofer, T., Schönherr, L., Fischer, A., Kolossa, D., Holz, T.: Lever- aging frequency analysis for deep fake image recognition. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 3247–3258 (2020)
2020
-
[7]
arXiv preprint arXiv:2403.10883 (2024)
Fu, J., Chen, Z., Jiang, K., Guo, H., Wang, J., Gao, S., Zhang, W.: Improving adver- sarial transferability of vision-language pre-training models through collaborative multimodal interaction. arXiv preprint arXiv:2403.10883 (2024)
-
[8]
In: ICLR 2024 Workshop on Reliable and Responsible Foundation Models (2024)
Gao, K., Bai, Y., Bai, J., Yang, Y., Xia, S.T.: Adversarial robustness for visual grounding of multimodal large language models. In: ICLR 2024 Workshop on Reliable and Responsible Foundation Models (2024)
2024
-
[9]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2015)
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial ex- amples. In: Proceedings of the International Conference on Learning Representations (ICLR) (2015)
2015
-
[10]
arXiv preprint arXiv:2408.13461 (2024)
Guan, J., Ding, T., Cao, L., Pan, L., Wang, C., Zheng, X.: Probing the robustness of vision-language pretrained models: A multimodal adversarial attack approach. arXiv preprint arXiv:2408.13461 (2024)
-
[11]
In: Proceedings of the International Conference on Machine Learning (ICML)
Hu, L., Liu, Y., Liu, N., Huai, M., Sun, L., Wang, D.: Improving interpretation faithfulness for vision transformers. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 19344–19370 (2024)
2024
-
[12]
arXiv preprint arXiv:2408.10072 (2024)
Huang, Z., Xia, B., Lin, Z., Mou, Z., Yang, W., Jia, J.: FFAA: Multimodal large language model based explainable open-world face forgery analysis assistant. arXiv preprint arXiv:2408.10072 (2024)
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Z., Hu, J., Li, X., He, Y., Zhao, X., Peng, B., Wu, B., Huang, X., Cheng, G.: SIDA: Social media image deepfake detection, localization and explanation with large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 28831–28841 (2025)
2025
-
[14]
arXiv preprint arXiv:2505.18660 (2025)
Huang, Z., Li, T., Li, X., Wen, H., He, Y., Zhang, J., Fei, H., Yang, X., Huang, X., Peng, B., Cheng, G.: So-fake: Benchmarking and explaining social media image forgery detection. arXiv preprint arXiv:2505.18660 (2025)
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Le, T.N., Nguyen, H.H., Yamagishi, J., Echizen, I.: OpenForensics: Large-scale challenging dataset for multi-face forgery detection and segmentation in-the-wild. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10117–10127 (2021)
2021
-
[16]
arXiv preprint arXiv:2602.06530 (2026)
Li, H., Peng, R., Luo, A., Tan, S., Chen, C., Antsiferova, A.: Universal anti-forensics attack against image forgery detection via multi-modal guidance. arXiv preprint arXiv:2602.06530 (2026)
-
[17]
In: IEEE International Workshop on Information Forensics and Security (WIFS)
Li, Y., Chang, M.C., Lyu, S.: In ictu oculi: Exposing AI created fake videos by detecting eye blinking. In: IEEE International Workshop on Information Forensics and Security (WIFS). pp. 1–7 (2018).https://doi.org/10.1109/WIFS.2018. 8630787 36 Qian
-
[18]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Liu, X., Xu, N., Chen, M., Xiao, C.: AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. In: Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[19]
Luo, H., Gu, J., Liu, F., Torr, P.: An image is worth 1000 lies: Adversarial transfer- ability across prompts on vision-language models. In: Proceedings of the Interna- tional Conference on Learning Representations (ICLR) (2024), arXiv:2403.09766
-
[20]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2018)
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learn- ing models resistant to adversarial attacks. In: Proceedings of the International Conference on Learning Representations (ICLR) (2018)
2018
-
[21]
In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
Mo, X., Tan, S., Li, B., Huang, J.: Query-efficient attack for black-box image inpainting forensics via reinforcement learning. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). vol. 39, pp. 19503–19511 (2025). https://doi.org/10.1609/aaai.v39i18.34147
-
[22]
SARA: Stress Test Reasoning in Audio Deepfake Detection
Nguyen, B., Le, T.: Analyzing reasoning shifts in audio deepfake detection under adversarial attacks: The reasoning tax versus shield bifurcation. arXiv preprint arXiv:2601.03615 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
In: Proceedings of the International Conference on Machine Learning (ICML)
Nie, W., Guo, B., Huang, Y., Xiao, C., Vahdat, A., Anandkumar, A.: Diffusion models for adversarial purification. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 16805–16827 (2022)
2022
-
[24]
arXiv preprint arXiv:2508.07402 (2025)
Peng, R., Tan, S., Kong, C., Luo, A., Kot, A.C., Huang, J.: ForensicsSAM: Toward robust and unified image forgery detection and localization resisting to adversarial attack. arXiv preprint arXiv:2508.07402 (2025)
-
[25]
arXiv preprint arXiv:2403.02955 (2024), accepted at TMLR 2024
Pinhasov, B., Lapid, R., Ohayon, R., Sipper, M., Aperstein, Y.: XAI-based detection of adversarial attacks on deepfake detectors. arXiv preprint arXiv:2403.02955 (2024), accepted at TMLR 2024
-
[26]
Qian, J.: Visual inception: Compromising long-term planning in agentic recom- menders via multimodal memory poisoning. arXiv preprint arXiv:2604.16966 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Qian, J., Kang, Z.: Penny wise, pixel foolish: Bypassing price constraints in multi- modal agents via visual adversarial perturbations. arXiv preprint arXiv:2604.16515 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Schlarmann, C., Hein, M.: On the adversarial robustness of multi-modal foundation models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) (2023), arXiv:2308.10741
-
[29]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 618–626 (2017)
2017
-
[30]
arXiv preprint arXiv:2509.14957 (2025)
Shen, Z., Zhang, K., Jia, B., Jia, H., Fang, Y., Yu, Z., Lin, S.: DF-LLaVA: Unlocking MLLMs for synthetic image detection via knowledge injection and conflict-driven self-reflection. arXiv preprint arXiv:2509.14957 (2025)
-
[31]
Stamm, M.C., Zhao, X.: Anti-forensic attacks using generative adversarial networks. In: Multimedia Forensics, pp. 467–490. Advances in Computer Vision and Pattern Recognition, Springer Singapore (2022).https://doi.org/10.1007/978-981-16- 7621-5_17
-
[32]
In: Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR)
Wang, J., Wu, Z., Ouyang, W., Han, X., Chen, J., Jiang, Y.G., Lim, S.N.: M2TR: Multi-modal multi-scale transformers for deepfake detection. In: Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR). pp. 615–623 (2022).https://doi.org/10.1145/3512527.3531415
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wei, Z., Chen, J., Goldblum, M., Wu, Z., Goldstein, T., Jiang, Y.G.: Towards transferable adversarial attacks on vision transformers. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 2668–2676 (2022) JECA2: Judgment–Explanation Consistent Adversarial Attack 37
2022
-
[34]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
Xu, Z., Zhang, X., Li, R., Tang, Z., Huang, Q., Zhang, J.: FakeShield: Explainable image forgery detection and localization via multi-modal large language models. In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
2025
-
[35]
ForgeryGPT: A Multimodal LLM for Interpretable Image Forgery Detection and Localization
Zhang, F., Liu, J., Zhu, J., Sun, E., Li, D., Zhang, Q., Zha, Z.J.: ForgeryGPT: A multimodal LLM for interpretable image forgery detection and localization. arXiv preprint arXiv:2410.10238 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, J., Ye, J., Ma, X., Li, Y., Yang, Y., Chen, Y., Sang, J., Yeung, D.Y.: Any- Attack: Towards large-scale self-supervised adversarial attacks on vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19900–19909 (2025)
2025
-
[37]
arXiv preprint arXiv:2404.19287 (2024)
Zhou, W., Bai, S., Mandic, D.P., Zhao, Q., Chen, B.: Revisiting the adversarial robustness of vision language models: a multimodal perspective. arXiv preprint arXiv:2404.19287 (2024)
-
[38]
Zhuo, L., Luo, S., Tan, S., Chen, H., Li, B., Huang, J.: Evading detection actively: Toward anti-forensics against forgery localization. IEEE Transactions on Dependable and Secure Computing22(2), 852–869 (2025).https://doi.org/10.1109/TDSC. 2025.3528062
-
[39]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J.Z., Fredrikson, M.: Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.