Dolph2Vec: Self-Supervised Representations of Dolphin Vocalizations
Pith reviewed 2026-06-27 10:46 UTC · model grok-4.3
The pith
Dolph2Vec, trained only on dolphin recordings, outperforms general audio models on whistle classification and detection while its codebook units match known whistle categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dolph2Vec, the first large-scale species-specific self-supervised model trained on longitudinal recordings from five dolphins, produces embeddings that outperform general-purpose baselines on signature whistle classification and whistle detection; its learned codebook structure further captures interpretable acoustic units aligned with dolphin whistle categories and possibly sub-whistle structure.
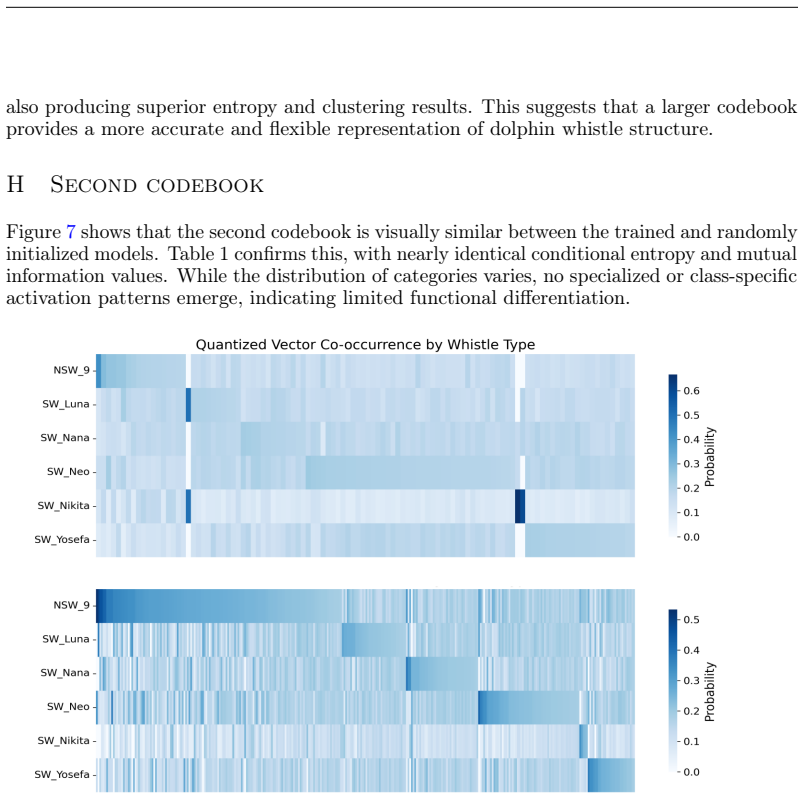
What carries the argument
Dolph2Vec, the adapted Wav2Vec2.0 model whose discrete codebook units function as acoustic building blocks that align with known whistle categories.
If this is right
- Fine-grained study of dolphin communication patterns can proceed with reduced need for manual annotation of individual calls.
- Sub-whistle acoustic elements become observable through the organization of the learned codebook.
- Self-supervised models can function simultaneously as performance tools and as instruments for generating hypotheses about animal signaling.
- Species-specific training data yields representations better matched to within-species structure than cross-species models.
Where Pith is reading between the lines
- If the codebook units remain stable when the model is applied to new individuals, they could form the basis for a standardized inventory of dolphin sound elements.
- The same training approach could be used to compare communication structure across different dolphin populations or related species.
- Longer recordings that include social context might reveal whether the learned units combine in systematic ways during interactions.
Load-bearing premise
Recordings from five dolphins in one semi-naturalistic setting supply a sufficient sample for learning generalizable features of dolphin communication.
What would settle it
Testing the same model on vocalizations from a separate group of dolphins recorded in a different environment and finding that classification accuracy falls to the level of general baselines or that codebook units no longer align with whistle categories.
Figures
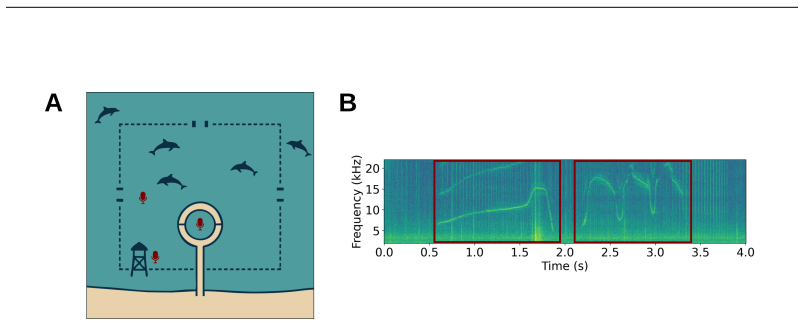
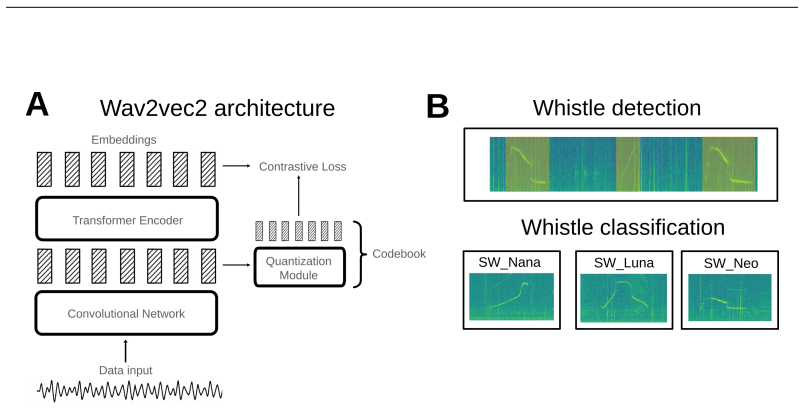
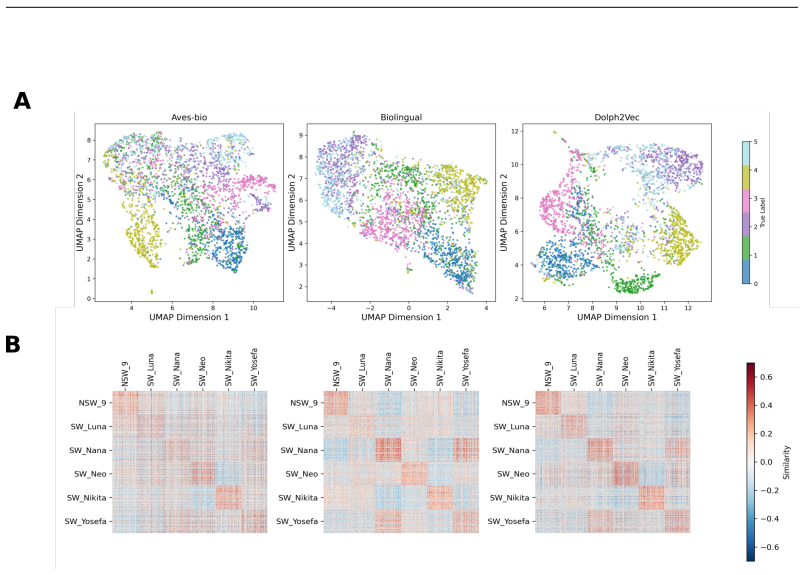
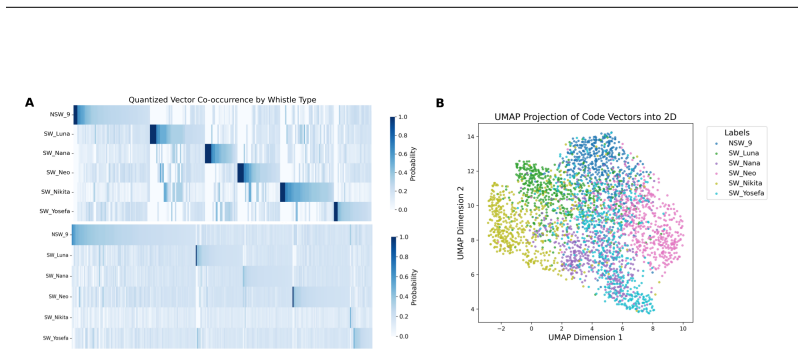


read the original abstract
Self-supervised learning (SSL) has opened new opportunities in bioacoustics by enabling scalable modeling of animal vocalizations without the need for expensive manual annotation. However, current SSL models in this domain prioritize broad generalization across species and are not optimized for uncovering the fine-grained structure of individual communication systems. In this work, we collect and release a novel dataset of over five years of longitudinal recordings, from five known dolphins in a semi-naturalistic marine environment, an unprecedented resource for studying dolphin communication. We adapt the Wav2Vec2.0 Baevski et al. (2020) architecture to this domain and introduce Dolph2Vec, the first large-scale, species-specific SSL model trained exclusively on this data. We benchmark our model on two biologically relevant tasks: signature whistle classification and whistle detection. Dolph2Vec significantly outperforms general-purpose baselines in both tasks. Beyond performance, we show that learned embeddings and codebook structure capture interpretable acoustic units aligned with dolphin whistle categories and possibly sub-whistle structure, enabling fine-grained analysis of communication patterns. Our findings demonstrate how SSL can serve as both a model and a scientific tool to explore hypotheses in animal communication research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dolph2Vec, an adaptation of the Wav2Vec2.0 architecture trained exclusively on a new longitudinal dataset of dolphin vocalizations collected over five years from five known individuals in a semi-naturalistic environment. It claims that the model significantly outperforms general-purpose baselines on signature whistle classification and whistle detection tasks, and that the learned embeddings and codebook units capture interpretable acoustic structure aligned with established whistle categories (and possibly sub-whistle units), thereby serving as a tool for studying dolphin communication systems.
Significance. If the empirical results hold under proper controls for generalization, the work would supply both a reusable species-specific SSL model and a public dataset that could accelerate hypothesis-driven research in bioacoustics; the explicit release of five years of labeled longitudinal recordings from identified animals is a concrete strength.
major comments (2)
- [Abstract] Abstract: the central framing that the model enables study of “dolphin communication systems” (rather than the communication of these five individuals) is load-bearing yet unsupported; all training data, signature-whistle labels, and evaluation sets come from the same five dolphins at one site, so any performance gain or apparent alignment with whistle categories could reflect individual or site-specific acoustic idiosyncrasies instead of transferable species-level features.
- [Abstract] Abstract: the assertion of “significant outperformance” on both tasks is presented without any quantitative metrics, error bars, dataset-split protocol, or statistical tests, rendering the magnitude and reliability of the claimed gains impossible to evaluate from the provided text.
minor comments (1)
- [Abstract] Abstract: the citation “Wav2Vec2.0 Baevski et al. (2020)” should be expanded to the full reference on first use for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that both points identify areas where the current text overstates scope and lacks supporting detail, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central framing that the model enables study of “dolphin communication systems” (rather than the communication of these five individuals) is load-bearing yet unsupported; all training data, signature-whistle labels, and evaluation sets come from the same five dolphins at one site, so any performance gain or apparent alignment with whistle categories could reflect individual or site-specific acoustic idiosyncrasies instead of transferable species-level features.
Authors: We agree the framing risks implying species-wide transferability that the five-individual, single-site dataset does not demonstrate. 'Species-specific' in the manuscript denotes training exclusively on dolphin vocalizations rather than a multi-species corpus. We will revise the abstract to refer explicitly to vocalizations from these five individuals and add a limitations paragraph discussing possible individual or site-specific idiosyncrasies. revision: yes
-
Referee: [Abstract] Abstract: the assertion of “significant outperformance” on both tasks is presented without any quantitative metrics, error bars, dataset-split protocol, or statistical tests, rendering the magnitude and reliability of the claimed gains impossible to evaluate from the provided text.
Authors: The detailed metrics, splits, error bars, and statistical tests appear in the experimental sections of the full manuscript. However, we accept that the abstract claim is insufficiently substantiated on its own. We will incorporate concise quantitative results and a reference to the evaluation protocol into the revised abstract. revision: yes
Circularity Check
No circularity: empirical adaptation and benchmarks are self-contained
full rationale
The paper adapts the external Wav2Vec2.0 architecture to a new longitudinal dolphin dataset and reports empirical results on signature whistle classification and detection tasks, plus qualitative embedding inspection. No equations, predictions, or uniqueness claims reduce by construction to fitted parameters or self-citations; the central claims rest on performance deltas against general-purpose baselines and visual alignment with whistle categories, all externally falsifiable via the released data and standard SSL training. This matches the default expectation of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- Wav2Vec2.0 adaptation hyperparameters
axioms (1)
- domain assumption The Wav2Vec2.0 self-supervised objective remains effective when the training distribution is restricted to a single species' vocalizations.
Reference graph
Works this paper leans on
-
[1]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli
URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 92d1e1eb1cd6f9fba3227870bb6d7f07-Paper.pdf. Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. data2vec: A general framework for self-supervised learning in speech, vision and language. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Ni...
2020
-
[2]
URLhttps://arxiv.org/ abs/2303.10931. Peter C Bermant. Biocppnet: automatic bioacoustic source separation with deep neural networks.Scientific Reports, 11(1):23502,
-
[3]
URLhttps://www.biorxiv.org/content/early/2022/10/16/2022.10.12.511740.1
doi: 10.1101/2022.10.12.511740. URLhttps://www.biorxiv.org/content/early/2022/10/16/2022.10.12.511740.1. Daniel T Blumstein, Daniel J Mennill, Patrick Clemins, Lewis Girod, Kung Yao, Gail Patricelli, Jill L Deppe, Alan H Krakauer, Christopher Clark, Kathryn A Cortopassi, et al. Acoustic monitoring in terrestrial environments using microphone arrays: appli...
-
[4]
doi: 10.1162/tacl_a_00051. URLhttps://aclanthology. org/Q17-1010/. John R Buck and Peter L Tyack. A quantitative measure of similarity for tursiops truncatus signature whistles.The Journal of the Acoustical Society of America, 94(5):2497–2506,
-
[5]
Investigating self-supervised speech models’ ability to classify animal vocalizations: The case of gibbon’s vocal signatures
JulesCauzinille, BenoîtFavre, RicardMarxer, DenaClink, AbdulHamidAhmad, andArnaud Rey. Investigating self-supervised speech models’ ability to classify animal vocalizations: The case of gibbon’s vocal signatures. InInterspeech 2024, pages 132–136. ISCA; ISCA,
2024
-
[6]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725. IEEE, 2020a. Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xi...
2020
-
[7]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , volume=
doi: 10.1109/JSTSP.2022.3188113. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020b. Richard C Connor and Rachel A Smolker. ’pop’goes the dolphin: A vocalization male bottle...
-
[8]
doi: 10.1109/ICSPCC59353. 2023.10400331. Francesco Di Nardo, Rocco De Marco, Alessandro Lucchetti, and David Scaradozzi. A wav file dataset of bottlenose dolphin whistles, clicks, and pulse sounds during trawling interactions.Scientific Data, 10:650,
-
[9]
URL https://doi.org/10.1038/s41597-023-02547-8
doi: 10.1038/s41597-023-02547-8. URL https://doi.org/10.1038/s41597-023-02547-8. John Firth. A synopsis of linguistic theory, 1930-1955.Studies in linguistic analysis, pages 10–32,
-
[10]
URLhttps://doi.org/10.1038/s41598-025-00996-2
doi: 10.1038/s41598-025-00996-2. URLhttps://doi.org/10.1038/s41598-025-00996-2. Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap your own latent - a new ...
-
[11]
URL https://proceedings.neurips.cc/paper/2020/file/ f3ada80d5c4ee70142b17b8192b2958e-Paper.pdf. G. Gubnitsky, Y. Mevorach, S. Gero, et al. Automatic detection and annotation of eastern caribbean sperm whale codas.Scientific Reports, 15(12790),
2020
-
[12]
URLhttps://doi.org/10.1038/s41598-025-97009-z
doi: 10.1038/s41598-025-97009-z. URLhttps://doi.org/10.1038/s41598-025-97009-z. Masato Hagiwara. Aves: Animal vocalization encoder based on self-supervision,
-
[13]
URL https://arxiv.org/abs/2210.14493. Masato Hagiwara, Benjamin Hoffman, Jen-Yu Liu, Maddie Cusimano, Felix Effenberger, and Katie Zacarian. Beans: The benchmark of animal sounds. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5,
arXiv 2023
-
[14]
A learnable spatial mapping for decoding the directional focus of auditory attention using EEG,
doi: 10.1109/ICASSP49357.2023.10096686. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June
-
[15]
Tyack, Randall S
Frants Havmand Jensen, Piper Wolters, Louisa van Zeeland, Evan Morrison, Gracie Ermi, Scott Smith, Peter L. Tyack, Randall S. Wells, Sam McKennoch, Vincent M. Janik, and Laela S. Sayigh.Automatic Deep-Learning-Based Classification of Bot- tlenose Dolphin Signature Whistles, pages 2059–2070. Springer International Publishing, Cham,
2059
-
[16]
URL https://doi.org/10.1007/ 978-3-031-50256-9_143
doi: 10.1007/978-3-031-50256-9_143. URL https://doi.org/10.1007/ 978-3-031-50256-9_143. Stefan Kahl, Connor M Wood, Maximilian Eibl, and Holger Klinck. Birdnet: A deep learning solution for avian diversity monitoring.Ecological Informatics, 61:101236,
-
[17]
doi: 10.1109/5.726791. Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.Nature, 521:436–444,
-
[18]
doi: 10.1111/j.1439-0310.1995.tb00325.x
ISSN 0179-1613. doi: 10.1111/j.1439-0310.1995.tb00325.x. URL http://dx.doi.org/10.1111/J.1439-0310. 1995.TB00325.X. Paulius Micikevicius, Sharan Narang, Jonah Alben, Greg Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740,
-
[19]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean
doi: 10.1109/ICASSP.2011.5947611. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space,
-
[20]
ISSN 0001-4966. doi: 10.1121/1.1496079. URLhttp://dx.doi.org/10.1121/1.1496079. 13 Abdelrahman Mohamed, Hung-yi Lee, Lasse Borgholt, Jakob D. Havtorn, Joakim Edin, Christian Igel, Katrin Kirchhoff, Shang-Wen Li, Karen Livescu, Lars Maaløe, Tara N. Sainath, and Shinji Watanabe. Self-supervised speech representation learning: A review. IEEE Journal of Selec...
-
[21]
1109/JSTSP.2022.3207050. Faadil Mustun, Chiara Semenzin, Dean Rance, Emiliano Marachlian, Zohria-Lys Guillerm, Agathe Mancini, Inès Bouaziz, Elisabeth Fleck, Nadav Shashar, Gonzalo G de Polavieja, et al. Whistle variability and social acoustic interactions in bottlenose dolphins.bioRxiv, pages 2024–10,
arXiv 2022
-
[22]
Machine learning for efficient segregation and labeling of potential biological sounds in long-term underwater recordings.Frontiers in Remote Sensing, Volume 5 - 2024,
Clea Parcerisas, Elena Schall, Kees te Velde, Dick Botteldooren, Paul Devos, and Elisabeth Debusschere. Machine learning for efficient segregation and labeling of potential biological sounds in long-term underwater recordings.Frontiers in Remote Sensing, Volume 5 - 2024,
2024
-
[23]
doi: 10.3389/frsen.2024.1390687
ISSN 2673-6187. doi: 10.3389/frsen.2024.1390687. URLhttps://www.frontiersin. org/journals/remote-sensing/articles/10.3389/frsen.2024.1390687. Michael A Pardo, Kurt Fristrup, David S Lolchuragi, Joyce H Poole, Petter Granli, Cynthia Moss, Iain Douglas-Hamilton, and George Wittemyer. African elephants address one another with individually specific name-like...
-
[24]
Transferable models for bioacoustics with human language supervision
David Robinson, Adelaide Robinson, and Lily Akrapongpisak. Transferable models for bioacoustics with human language supervision. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1316–1320,
2024
-
[25]
doi: 10.1109/ICASSP48485.2024.10447250. David Robinson, Marius Miron, Masato Hagiwara, and Olivier Pietquin. NatureLM-audio: an audio-language foundation model for bioacoustics. InThe Thirteenth International Conference on Learning Representations,
-
[26]
Eklavya Sarkar and Mathew Magimai
doi: 10.1109/CRV.2019.00010. Eklavya Sarkar and Mathew Magimai. Doss. Comparing self-supervised learning models pre-trained on human speech and animal vocalizations for bioacoustics processing,
-
[27]
URLhttps://arxiv.org/abs/2501.05987. 14 Laela Sayigh, Mary Ann Daher, Julie Allen, Helen Gordon, Katherine Joyce, Claire Stuhlmann, and Peter Tyack. The watkins marine mammal sound database: an on- line, freely accessible resource. InProceedings of Meetings on Acoustics, volume
-
[28]
Very Deep Convolutional Networks for Large-Scale Image Recognition
doi: 10.1038/s41467-024-47221-8. URLhttps://doi.org/10.1038/s41467-024-47221-8. Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41467-024-47221-8
-
[29]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[30]
A Additonal related work: self-super vised learning The traditional supervised learning approach for dolphin vocalization embeddings has long been criticized for enforcing a human-biased perspective Schlenker et al. (2022). This bias stems from linking each vocalization directly to expert annotations or predefined features assumed by humans to be importan...
2022
-
[31]
C Dataset properties Studying a small, stable pod of five dolphins across several years provides advantages rarely available in animal communication research
Data acquisition was automated using scheduled crontab commands. C Dataset properties Studying a small, stable pod of five dolphins across several years provides advantages rarely available in animal communication research. The individuals’ sex, family history, and kinship relations are well documented Mustun et al. (2024); Perelberg et al. (2010), enabli...
2024
-
[32]
Category Count SW_Luna 2,934 SW_Neo 2,239 SW_Nikita 888 NSW_9 658 SW_Yosefa 626 SW_Nana 521 SW_Dana 335 SW_Shy 81 NSW_3 45 NSW_6 27 Table 3: Distribution of annotated whistle categories. To balance categories, all classes with at least 500 examples were subsampled to 500 instances each (SW_Luna, SW_Neo, SW_Nikita, NSW_9, SW_Yosefa, SW_Nana), ensuring an e...
2019
-
[33]
Wav2Vec2 refers to the base model pretrained on human speech at 16 kHz Baevski et al. (2020).Dolph2Vec-random init denotes theDolph2Vecmodel with randomly initialized weights, i.e., before any self-supervised pretraining.Dolph2Vec-shuffled is a variant ofDolph2Vecin which the temporal structure of the learned representations is disrupted by shuffling the ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.