TOKI: A Bitemporal Operator Algebra for Contradiction Resolution in LLM-Agent Persistent Memory
Pith reviewed 2026-06-27 22:59 UTC · model grok-4.3
The pith
TOKI types four memory heuristics as bitemporal operators that declare isolation levels and retain audit rows for LLM-agent writes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
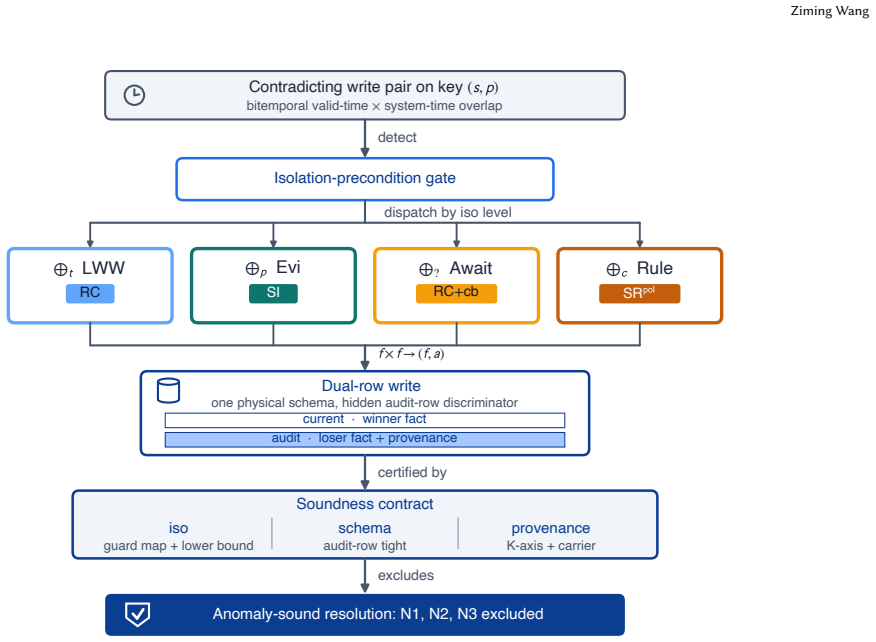
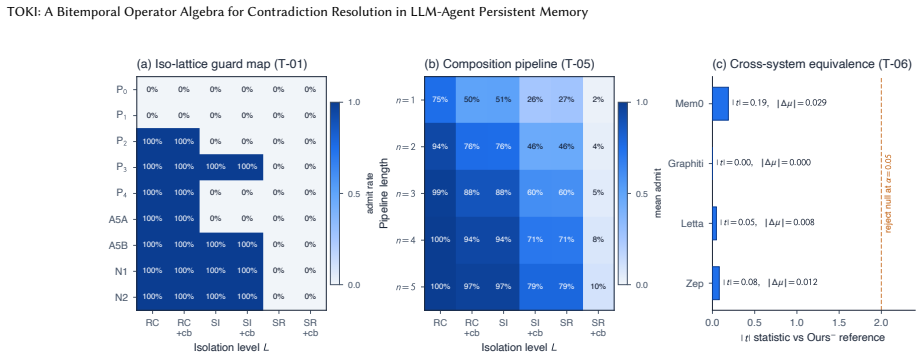
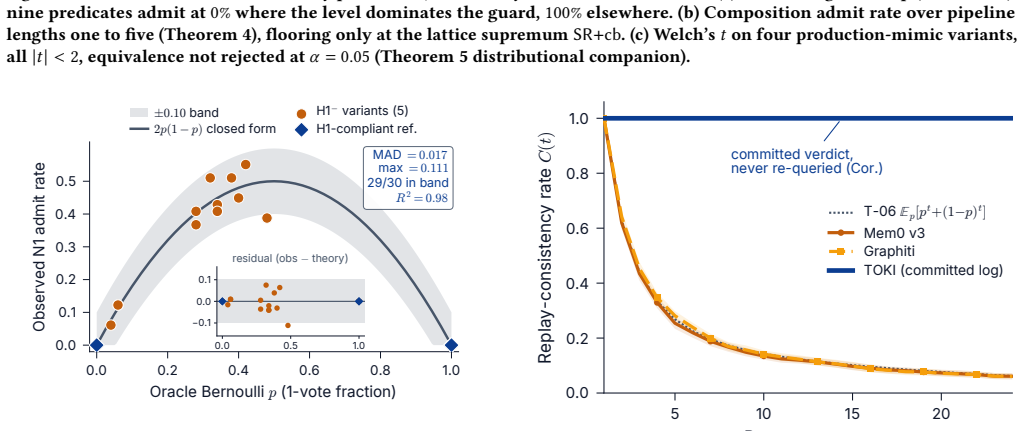
TOKI types the four standard resolution heuristics as bitemporal operators over a dual-row schema. Each operator carries an isolation precondition and a provenance annotation that preserves the losing fact. Four soundness theorems close the contract across isolation, schema, and provenance, lift the guarantees to operator pipelines, and extend the fold operators to n-ary conflict sets. A tightness companion proves that keyed logging of the adjudicating judge is necessary for replay consistency. The verdict matrix shows TOKI alone excludes replay inconsistency, belief-drift skew, and audit erasure while retaining the language-model judge on the write path.
What carries the argument
The bitemporal operator algebra, which assigns each heuristic an isolation precondition and provenance annotation over a dual-row schema to preserve audit information while supporting operator composition.
If this is right
- Each of the four heuristics now carries a declared isolation precondition and a provenance mechanism.
- Losing facts remain accessible in audit rows instead of being erased.
- Soundness extends from single operators to pipelines and to n-ary conflict sets.
- Keyed logging of the language-model judge becomes a necessary condition for replay consistency.
- Any system that removes the judge to avoid anomalies sacrifices the ability to perform judge-based adjudication.
Where Pith is reading between the lines
- The same operator-typing discipline could be applied to read paths to obtain end-to-end consistency contracts.
- Empirical validation on additional workloads beyond the single LoCoMo slice would test whether the relational schedule model holds in practice.
- Content-addressed engines that avoid anomalies by dropping the judge may require separate mechanisms if nuanced, context-dependent resolution is later needed.
- The dual-row schema plus provenance annotation supplies a concrete implementation target for production memory layers that currently use ad-hoc rules.
Load-bearing premise
The relational schedule model is an appropriate abstraction for modeling the write operations and conflict adjudication performed by LLM agents.
What would settle it
An execution trace on a TOKI implementation that exhibits replay inconsistency, belief-drift skew, or audit erasure on a workload whose schedule satisfies the stated isolation precondition would falsify the soundness theorems.
Figures

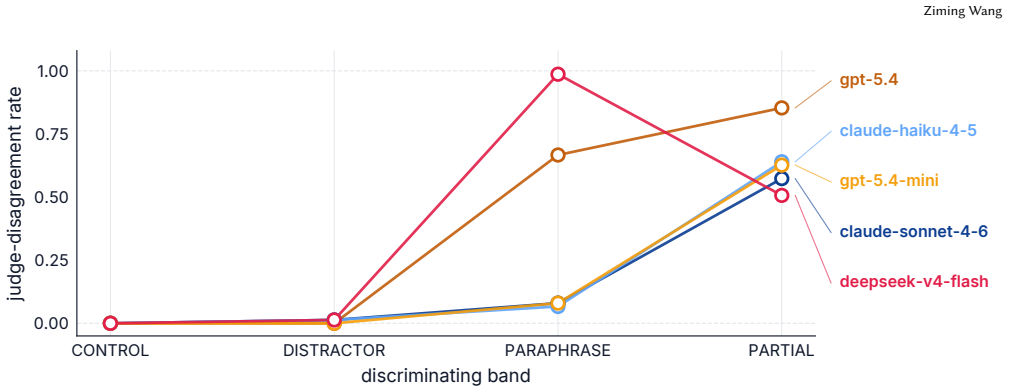
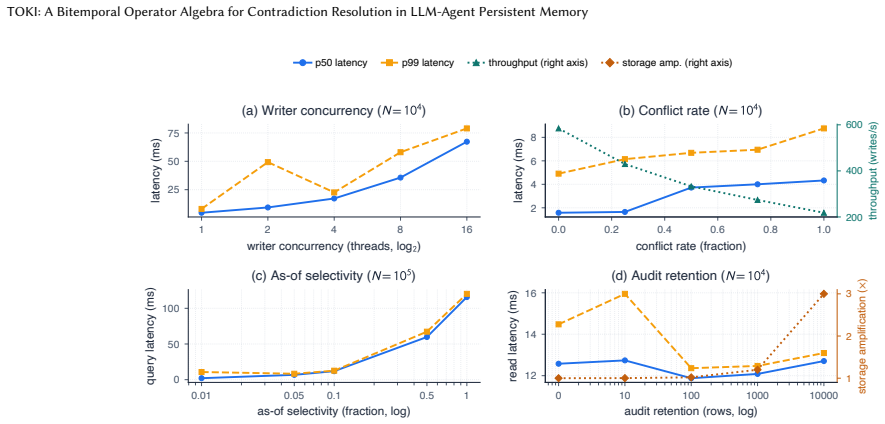
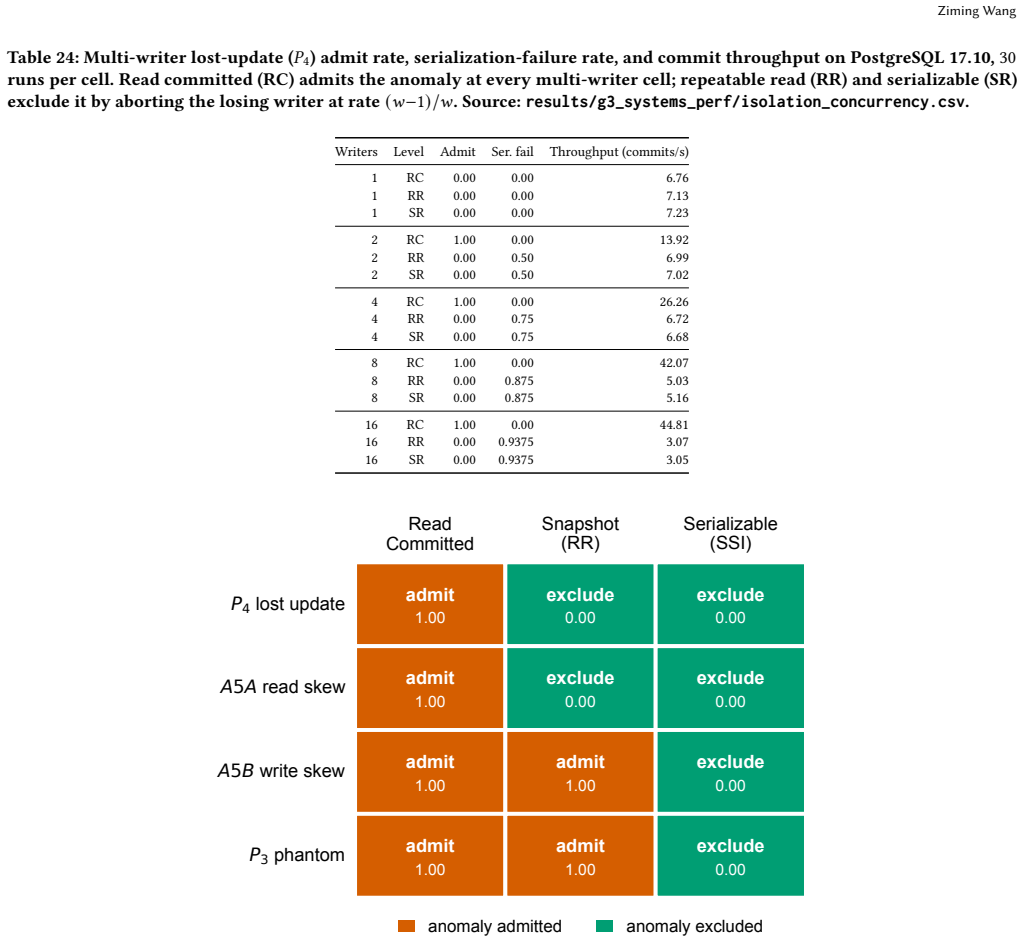
read the original abstract
Persistent memory for an LLM agent is a write-heavy substrate: every belief update is a versioned write, and a new claim may contradict a stored one. Production systems use four resolution heuristics (last-writer-wins, evidence-weighted merge, await-confirmation, per-rule policy), yet none declares the isolation level it assumes or the write-time anomalies it admits. We show that contradiction resolution is write-time concurrency control and make the missing contract explicit. TOKI types the four heuristics as one family of bitemporal operators over a dual-row schema, each with an isolation precondition and a provenance annotation that preserves the losing fact in an audit row. Four soundness theorems close the contract across isolation, schema, and provenance, lift the guarantees to operator pipelines, and extend the fold operators to n-ary conflict sets. A tightness companion proves that, within the relational schedule model, keyed logging of the adjudicating judge is necessary for replay consistency, which every audited baseline omits. A verdict matrix over eight systems localizes the gap: every baseline that keeps a language-model judge on the write path admits at least one of three write-time anomalies (replay inconsistency, belief-drift skew, audit erasure); a content-addressed engine-layer comparator avoids them only by removing the judge, and TOKI alone excludes all three while keeping it. On its one natural-workload slice the audit-row defence moves LoCoMo by 0.86, and ablating the typed memory layer removes 0.49 accuracy on 1,444 answerable LoCoMo questions; the cross-system comparison stays underpowered and claims no superiority. The contribution is the contract: a write-time correctness specification, proved sound across isolation, schema, and provenance, pinning the guarantee every production heuristic assumes but no deployed system makes explicit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contradiction resolution for LLM-agent persistent memory is a write-time concurrency control problem. It models four production heuristics as a family of bitemporal operators over a dual-row schema, each equipped with an isolation precondition and provenance annotation. Four soundness theorems are asserted to close the contract on isolation, schema, and provenance (including lifting to pipelines and n-ary conflicts), together with a tightness result proving keyed logging of the adjudicating judge is necessary for replay consistency inside the relational schedule model. A verdict matrix over eight systems shows that every baseline retaining an LM judge on the write path admits at least one of replay inconsistency, belief-drift skew, or audit erasure, while TOKI excludes all three; a single underpowered LoCoMo slice reports a 0.86 gain from audit rows and a 0.49 accuracy drop when the typed layer is ablated.
Significance. If the relational schedule model faithfully captures LLM-agent writes, the work supplies an explicit, proved correctness contract that current heuristics lack, together with a machine-checked-style localization of gaps via the verdict matrix and a tightness result on logging necessity. These formal elements would be a genuine contribution to the specification of persistent memory for agents. The empirical component is too narrow to support practical claims.
major comments (2)
- [relational schedule model and soundness theorems] The four soundness theorems and the tightness result on keyed logging are proved exclusively inside the relational schedule model with bitemporal operators and dual-row schema. The manuscript supplies neither a mapping from real LLM-agent write operations and semantic contradictions to these deterministic operators nor any empirical check that the model preserves the three anomalies it claims to exclude. This assumption is load-bearing for the central claim that TOKI alone excludes replay inconsistency, belief-drift skew, and audit erasure while retaining the LM judge.
- [verdict matrix] Verdict matrix (abstract): the localization that 'TOKI alone excludes all three' anomalies rests on the same unvalidated relational abstraction; without evidence that LLM writes satisfy the schedule assumptions, the matrix does not establish the claimed superiority outside the model.
minor comments (2)
- [abstract] Abstract: the four soundness theorems and tightness result are asserted without statements or proof sketches, forcing readers to reach the body to evaluate the formal contribution.
- [empirical evaluation] The cross-system comparison is explicitly labeled underpowered; this should be reflected more prominently when discussing the empirical slice.
Simulated Author's Rebuttal
We thank the referee for highlighting the foundational role of the relational schedule model. The contribution is a formal write-time correctness contract proved inside that model; we address the two major comments below and will revise the manuscript to clarify scope and add an explicit mapping discussion.
read point-by-point responses
-
Referee: [relational schedule model and soundness theorems] The four soundness theorems and the tightness result on keyed logging are proved exclusively inside the relational schedule model with bitemporal operators and dual-row schema. The manuscript supplies neither a mapping from real LLM-agent write operations and semantic contradictions to these deterministic operators nor any empirical check that the model preserves the three anomalies it claims to exclude. This assumption is load-bearing for the central claim that TOKI alone excludes replay inconsistency, belief-drift skew, and audit erasure while retaining the LM judge.
Authors: We agree the manuscript provides no explicit mapping from arbitrary real LLM writes to the deterministic operators and no empirical validation that the three anomalies appear in deployed systems. The relational schedule model is offered as a formal abstraction that isolates the write-time concurrency aspects of contradiction resolution, enabling the four soundness theorems and tightness result. The central claim is therefore scoped to properties that hold inside the model. We will add a new subsection (Section 3.5) that illustrates how common LLM-agent write patterns—belief updates from tool responses, user corrections, and multi-turn evidence accumulation—map onto sequences of the four typed operators, together with a limitations paragraph stating that empirical confirmation of anomaly occurrence in production traces remains future work. revision: partial
-
Referee: [verdict matrix] Verdict matrix (abstract): the localization that 'TOKI alone excludes all three' anomalies rests on the same unvalidated relational abstraction; without evidence that LLM writes satisfy the schedule assumptions, the matrix does not establish the claimed superiority outside the model.
Authors: The verdict matrix classifies each of the eight systems by whether it retains an LM judge on the write path and whether it satisfies the isolation, schema, and provenance preconditions of the relational schedule model. The localization therefore holds inside the model. We will revise the caption and surrounding text of the verdict matrix (Table 1) and the abstract to state explicitly that the comparison is performed under the assumptions of the relational schedule model and that claims of superiority are likewise scoped to that model. revision: partial
Circularity Check
No circularity; soundness theorems are model-internal and independent
full rationale
The paper introduces bitemporal operators over a dual-row schema, states four soundness theorems that close the contract across isolation/schema/provenance, and proves a tightness result inside the relational schedule model. These steps are definitional and deductive within the chosen abstraction; no equation, fitted parameter, or prediction is shown to reduce to its own inputs by construction. No self-citations appear as load-bearing premises, and the external applicability of the schedule model to LLM writes is an assumption rather than a circular derivation. The contribution is therefore self-contained against its stated model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The relational schedule model is the correct abstraction for LLM-agent write operations and judge adjudication.
invented entities (2)
-
Bitemporal operators
no independent evidence
-
Dual-row schema
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Seyed Moein Abtahi, Rasa Rahnema, Hetkumar Patel, Neel Patel, Majid Fekri, and Tara Khani. 2026. Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents.arXiv preprint arXiv:2604.22085(2026).https://arxiv.org/abs/2604.22085
Pith/arXiv arXiv 2026
-
[2]
Atul Adya, Barbara Liskov, and Patrick E. O’Neil. 2000. Generalized Isolation Level Definitions. InProceedings of the 16th International Conference on Data Engineering (ICDE). 67–78.https://doi.org/10.1109/ICDE.2000.839388
-
[3]
James F. Allen. 1983. Maintaining Knowledge about Temporal Intervals.Commun. ACM26, 11 (1983), 832–843.https://doi.org/10.1145/182.358434
-
[4]
Bahareh Sadat Arab, Su Feng Lee, Boris Glavic, Xing Niu, Seokki Lee, and Thomas Heinis. 2017. Using Reenactment to Retroactively Capture Provenance for Transactions. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE 2017). IEEE, 1077–1088.https://doi.org/10.1109/ICDE.2017.149
-
[5]
Pratyay Banerjee, Masud Moshtaghi, Shivashankar Subramanian, Amita Misra, and Ankit Chadha. 2026. APEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI.arXiv preprint arXiv:2604.14362(2026).https://arxiv.org/abs/2604.14362
Pith/arXiv arXiv 2026
-
[6]
Manuel Barros, Alcino Cunha, Jose Pereira, and Eunsuk Kang. 2026. Reasoning about Transactional Isolation Levels with Isolde.arXiv preprint arXiv:2604.00159(2026). https://arxiv.org/abs/2604.00159
arXiv 2026
-
[7]
Bernstein, Jim Gray, Jim Melton, Elizabeth J
Hal Berenson, Philip A. Bernstein, Jim Gray, Jim Melton, Elizabeth J. O’Neil, and Patrick E. O’Neil. 1995. A Critique of ANSI SQL Isolation Levels. InProceedings of the 1995 ACM SIGMOD International Conference on Management of Data. ACM, 1–10.https://doi.org/10.1145/223784.223785
-
[8]
Bernstein, Vassos Hadzilacos, and Nathan Goodman
Philip A. Bernstein, Vassos Hadzilacos, and Nathan Goodman. 1987.Concurrency Control and Recovery in Database Systems. Addison-Wesley.https://www.microsoft.com/en- us/research/wp-content/uploads/2016/05/ccontrol.zip
1987
-
[9]
Nishant Bhargava and Rodrigo Sobral Barrento. 2026. MemAudit: An Exact Package-Oracle Evaluation Protocol for Budgeted Long-Term LLM Memory Writing. arXiv:2605.02199 [cs.AI]https://arxiv.org/abs/2605.02199
Pith/arXiv arXiv 2026
-
[10]
Richard Booth and Eva Richter. 2012. On Revising Fuzzy Belief Bases.arXiv preprint arXiv:1212.2444(2012).https://arxiv.org/abs/1212.2444
Pith/arXiv arXiv 2012
-
[11]
Camille Bourgaux, Ana Ozaki, and Rafael Peñaloza. 2023. Semiring Provenance for Lightweight Description Logics.arXiv preprint arXiv:2310.16472(2023). https: //arxiv.org/abs/2310.16472
arXiv 2023
-
[12]
Sophie Brinke, Anuj Dawar, Erich Grädel, and Benedikt Pago. 2026. Preservation Theorems in Semiring Semantics. arXiv:2605.10829 [cs.LO] https://arxiv.org/abs/2605. 10829
Pith/arXiv arXiv 2026
-
[13]
Peter Buneman, Sanjeev Khanna, and Wang-Chiew Tan. 2001. Why and Where: A Characterization of Data Provenance. InDatabase Theory - ICDT 2001, 8th International Conference (Lecture Notes in Computer Science), Vol. 1973. Springer, 316–330.https://doi.org/10.1007/3-540-44503-X_20
-
[14]
Michael J. Cahill, Uwe Röhm, and Alan D. Fekete. 2008. Serializable Isolation for Snapshot Databases. InProceedings of the 2008 ACM SIGMOD International Conference on Management of Data. ACM, 729–738.https://doi.org/10.1145/1376616.1376690
-
[15]
Hanxiang Chao, Yihan Bai, Rui Sheng, Tianle Li, and Yushi Sun. 2026. STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?arXiv preprint arXiv:2605.06527(2026).https://arxiv.org/abs/2605.06527
Pith/arXiv arXiv 2026
-
[16]
Ding Chen, Simin Niu, Kehang Li, Peng Liu, Xiangping Zheng, Bo Tang, Xinchi Li, Feiyu Xiong, and Zhiyu Li. 2025. HaluMem: Evaluating Hallucinations in Memory Systems of Agents.arXiv preprint arXiv:2511.03506(2025).https://doi.org/10.48550/arXiv.2511.03506
-
[17]
Ziyang Chen, Jinzhi Liao, and Xiang Zhao. 2023. Multi-granularity Temporal Question Answering over Knowledge Graphs. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 11378–11392. https://doi.org/10.18653/v1/2023.acl- long.637
-
[18]
Chris Cheney and Engram contributors. 2026. Engram: Bitemporal, Graph-Backed Memory System for AI Coding Agents. GitHub repository, AGPL-3.0 licence, latest release mcp@0.1.9(2025-12-30), HEAD commit 1553e53 (2026-01-05T20:10:48Z), 5 stars and 1 fork at survey.https://github.com/rawcontext/engram
2026
-
[19]
James Cheney, Laura Chiticariu, and Wang-Chiew Tan. 2009. Provenance in Databases: Why, How, and Where.Foundations and Trends in Databases1, 4 (2009), 379–474. https://doi.org/10.1561/1900000006
-
[20]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413(2025).https://arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[21]
Cognitect. 2026. Datomic: An Information Model with Time, Provenance, and Accumulation. Online documentation. https://docs.datomic.com/datomic-overview.html
2026
-
[22]
Pengfei Du. 2026. Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers.arXiv preprint arXiv:2603.07670(2026). https://arxiv.org/abs/ 2603.07670
arXiv 2026
-
[23]
Alan Fekete, Dimitrios Liarokapis, Elizabeth O’Neil, Patrick O’Neil, and Dennis Shasha. 2005. Making Snapshot Isolation Serializable.ACM Transactions on Database Systems 30, 2 (2005), 492–528.https://doi.org/10.1145/1071610.1071615
-
[24]
Xpath evaluation in linear time
J. Nathan Foster, Todd J. Green, and Val Tannen. 2008. Annotated XML: Queries and Provenance. InProceedings of the 27th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS ’08). ACM, 271–280.https://doi.org/10.1145/1376916.1376953
-
[25]
Harish Santhanalakshmi Ganesan. 2026. WorldDB: A Vector Graph-of-Worlds Memory Engine with Ontology-Aware Write-Time Reconciliation. arXiv:2604.18478 [cs.AI]. https://arxiv.org/abs/2604.18478
Pith/arXiv arXiv 2026
-
[26]
Floris Geerts, Antonella Poggi, and Val Tannen. 2013. On the Limitations of Provenance for Queries with Difference. InProceedings of the Theory and Practice of Provenance Workshop (TaPP ’13). USENIX Association.https://doi.org/10.1145/2448496.2448516
-
[27]
Shabnam Ghasemirad, Si Liu, Christoph Sprenger, and David Basin. 2025. VerIso: Verifiable Isolation Guarantees for Database Transactions.Proc. VLDB Endow.18, 5 (2025), 1362–1375.https://doi.org/10.14778/3718057.3718065 41 Ziming Wang
-
[28]
Rohit Ghumare and AgentMemory contributors. 2026. AgentMemory: Persistent Memory for AI Coding Agents. GitHub repository, Apache-2.0 licence, npm package @agentmemory/agentmemory, latest release v0.9.17 (2026-05-16), HEAD commit c93c715 (2026-05-17T11:15:59Z).https://github.com/rohitg00/agentmemory
2026
-
[29]
Erich Grädel and Val Tannen. 2024. Provenance Analysis and Semiring Semantics for First-Order Logic.arXiv preprint arXiv:2412.07986(2024). https://arxiv.org/abs/ 2412.07986
arXiv 2024
-
[30]
Green, Grigoris Karvounarakis, and Val Tannen
Todd J. Green, Grigoris Karvounarakis, and Val Tannen. 2007. Provenance Semirings. InProceedings of the 26th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS). 31–40.https://doi.org/10.1145/1265530.1265535
-
[31]
Todd J. Green and Val Tannen. 2017. The Semiring Framework for Database Provenance. InProceedings of the 36th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems (PODS). 93–99.https://doi.org/10.1145/3034786.3056125
-
[32]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. In Advances in Neural Information Processing Systems 37 (NeurIPS 2024).https://arxiv.org/abs/2405.14831
arXiv 2024
-
[33]
Jun He and Deying Yu. 2026. Verifiable Agentic Infrastructure: Proof-Derived Authorization for Sovereign AI Systems. arXiv:2605.15228 [cs.AI] https://arxiv.org/abs/ 2605.15228
Pith/arXiv arXiv 2026
-
[34]
Stratos Idreos. 2025. Alphabets, Grammars, Calculators, and the End of Hand-Crafted Systems.Proceedings of the VLDB Endowment (PVLDB)18, 12 (2025), 5537. https: //doi.org/10.14778/3750601.3760522
-
[35]
Christian S. Jensen, Curtis E. Dyreson, Michael Böhlen, James Clifford, Ramez Elmasri, Shashi K. Gadia, Fabio Grandi, Pat Hayes, Sushil Jajodia, et al. 1998. The Consensus Glossary of Temporal Database Concepts—February 1998 Version. InTemporal Databases: Research and Practice, Opher Etzion, Sushil Jajodia, and Suryanarayana Sripada (Eds.). Lecture Notes ...
-
[36]
Sajjad Khan. 2026. S-Bus: Automatic Read-Set Reconstruction for Multi-Agent LLM State Coordination. arXiv:2605.17076 [cs.DC]https://arxiv.org/abs/2605.17076
Pith/arXiv arXiv 2026
-
[37]
Krishna Kulkarni and Jan-Eike Michels. 2012. Temporal Features in SQL:2011.ACM SIGMOD Record41, 3 (2012), 34–43.https://doi.org/10.1145/2380776.2380786
-
[38]
Letta Team. 2026. Context Constitution: Letta Code’s Memory Filesystem. Letta engineering blog.https://letta.com/blog/context-constitution
2026
-
[39]
Weixian Waylon Li, Jiaxin Zhang, Xianan Jim Yang, Tiejun Ma, and Yiwen Guo. 2026. Time is Not a Label: Continuous Phase Rotation for Temporal Knowledge Graphs and Agentic Memory.arXiv preprint arXiv:2604.11544(2026).https://arxiv.org/abs/2604.11544
Pith/arXiv arXiv 2026
-
[40]
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Huayi Lai, Hao Wu, Bo Tang, Zhengren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan ...
-
[41]
MemOS: A Memory OS for AI System.arXiv preprint arXiv:2507.03724(2025).https://doi.org/10.48550/arXiv.2507.03724
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.03724 2025
-
[42]
Gonzalez, and Aditya G
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2026. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. Proc. CIDR 2026, January 18–21, Chaminade.ht...
2026
-
[43]
Lorentzos and Roger G
Nikos A. Lorentzos and Roger G. Johnson. 1988. Extending Relational Algebra to Manipulate Temporal Data. InProceedings of the 14th International Conference on Very Large Data Bases (VLDB). Morgan Kaufmann, 289–296.https://vldb.org/conf/1988/P289.PDF
1988
-
[44]
Yihao Lu, Wanru Cheng, Zeyu Zhang, and Hao Tang. 2026. MMA: Multimodal Memory Agent. arXiv:2602.16493 [cs.AI]https://arxiv.org/abs/2602.16493
arXiv 2026
-
[45]
Yang Luo, Zifeng Kang, Tiantian Ji, Xinran Liu, Yong Liu, Shuyu Li, and Lingyun Peng. 2026. ShadowMerge: A Novel Poisoning Attack on Graph-Based Agent Memory via Relation-Channel Conflicts.arXiv preprint arXiv:2605.09033(2026).https://arxiv.org/abs/2605.09033
Pith/arXiv arXiv 2026
-
[46]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13851–13870. https://doi.org/10.18653/v1/2024.acl- long.747
-
[47]
Mem0 Team. 2026. Mem0 README: New Memory Algorithm (April 2026). GitHub repository README.https://github.com/mem0ai/mem0/blob/main/README.md
2026
-
[48]
Hua Meng, Zhiguo Long, Michael Sioutis, and Zhengchun Zhou. 2025. On Definite Iterated Belief Revision with Belief Algebras.arXiv preprint arXiv:2505.06505(2025). https://arxiv.org/abs/2505.06505
arXiv 2025
-
[49]
Solomon Messing. 2026. Hidden Measurement Error in LLM Pipelines Distorts Annotation, Evaluation, and Benchmarking. arXiv:2604.11581 [cs.CL] https://arxiv.org/ abs/2604.11581
Pith/arXiv arXiv 2026
-
[50]
Bardia Mohammadi, Nearchos Potamitis, Lars Klein, Akhil Arora, and Laurent Bindschaedler. 2026. Atomix: Timely, Transactional Tool Use for Reliable Agentic Workflows. arXiv:2602.14849 [cs.DC]https://arxiv.org/abs/2602.14849
Pith/arXiv arXiv 2026
-
[51]
Mehryar Mohri. 2002. Semiring Frameworks and Algorithms for Shortest-Distance Problems.Journal of Automata, Languages and Combinatorics7, 3 (2002), 321–350. http://www.cs.nyu.edu/~mohri/pub/jalc.pdf
2002
-
[52]
Praveen Kumar Myakala, Manan Agrawal, and Rahul Manche. 2026. BeliefShift: Benchmarking Temporal Belief Consistency and Opinion Drift in LLM Agents.arXiv preprint arXiv:2603.23848(2026).https://arxiv.org/abs/2603.23848
arXiv 2026
-
[53]
Ciyan Ouyang and Rui Hou. 2026. MemLineage: Lineage-Guided Enforcement for LLM Agent Memory.arXiv preprint arXiv:2605.14421(2026). https://arxiv.org/abs/ 2605.14421
Pith/arXiv arXiv 2026
-
[54]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023).https://arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2023
-
[55]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST). 1–22.https://doi.org/10.1145/3586183.3606763
-
[56]
Young Bin Park. 2026. Graph-Native Cognitive Memory for AI Agents: Formal Belief Revision Semantics for Versioned Memory Architectures.arXiv preprint arXiv:2603.17244 (2026).https://arxiv.org/abs/2603.17244
arXiv 2026
-
[57]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS.Proceedings of the VLDB Endowment (PVLDB)18, 11 (2025), 4171–4184. https://doi.org/10.14778/3749646.3749685
-
[58]
Sidharth Pulipaka, Stanislau Hlebik, Leonidas Raghav, Sahar Abdelnabi, Vyas Raina, Ivaxi Sheth, and Mario Fritz. 2026. Hidden in Memory: Sleeper Memory Poisoning in LLM Agents. arXiv:2605.15338 [cs.CR]https://arxiv.org/abs/2605.15338
Pith/arXiv arXiv 2026
-
[59]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory.arXiv preprint arXiv:2501.13956(2025).https://arxiv.org/abs/2501.13956
Pith/arXiv arXiv 2025
-
[60]
Michaël Roynard. 2026. The Missing Knowledge Layer in Cognitive Architectures for AI Agents.arXiv preprint arXiv:2604.11364(2026). https://arxiv.org/abs/2604.11364
Pith/arXiv arXiv 2026
-
[61]
Matthew Russo, Chunwei Liu, Sivaprasad Sudhir, Gerardo Vitagliano, Michael Cafarella, Tim Kraska, and Samuel Madden. 2026. Abacus: A Cost-Based Optimizer for Semantic Operator Systems.Proceedings of the VLDB Endowment (PVLDB)19, 5 (2026), 1060–1073.https://www.vldb.org/pvldb/vol19/p1060-russo.pdf
2026
-
[62]
Rashomon Memory: Towards Argumentation-Driven Retrieval for Multi-Perspective Agent Memory
Albert Sadowski and Jarosław A. Chudziak. 2026. Rashomon Memory: Towards Argumentation-Driven Retrieval for Multi-Perspective Agent Memory. https://doi.org/ 10.48550/arXiv.2604.03588arXiv:2604.03588
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03588arxiv:2604.03588 2026
-
[63]
Kenneth Salem, Hector Garcia-Molina, and Jeannie Sands. 1989. Altruistic Locking: A Strategy for Coping with Long Lived Transactions. InProceedings of the 2nd International Workshop on High Performance Transaction Systems.https://doi.org/10.1145/64162.64173
-
[64]
Dhravya Shah and Supermemory contributors. 2026. Supermemory: State-of-the-art Memory and Context Engine for AI. GitHub repository supermemoryai/supermemory, MIT licence, HEAD commit 36ecf47 (2026-05-17T07:55:12Z), 22,596 stars, zero GitHub releases, Python SDK supermemory-openai-sdk on PyPI at alpha v1.0.3. https: //github.com/supermemoryai/supermemory
2026
-
[65]
Parameswaran, and Eugene Wu
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proceedings of the VLDB Endowment (PVLDB)18, 12 (2025), 3920–3932.https://www.vldb.org/pvldb/vol18/p3920-shankar.pdf
2025
-
[66]
Richard Snodgrass and Ilsoo Ahn. 1986. Temporal Databases.IEEE Computer19, 9 (1986), 35–42.https://doi.org/10.1109/MC.1986.1663327
-
[67]
Snodgrass
Richard T. Snodgrass. 2000.Developing Time-Oriented Database Applications in SQL. Morgan Kaufmann, San Francisco, CA. https://www2.cs.arizona.edu/~rts/tdbbook. pdf 42 TOKI: A Bitemporal Operator Algebra for Contradiction Resolution in LLM-Agent Persistent Memory
2000
-
[68]
Miao Su, Yucan Guo, Zhongni Hou, Long Bai, Zixuan Li, Yufei Zhang, Guojun Yin, Wei Lin, Xiaolong Jin, Jiafeng Guo, and Xueqi Cheng. 2026. Beyond Dialogue Time: Temporal Semantic Memory for Personalized LLM Agents.arXiv preprint arXiv:2601.07468(2026).https://arxiv.org/abs/2601.07468
arXiv 2026
-
[69]
Tencent. 2026. TencentDB Agent Memory: Fully Local Long-Term Memory for AI Agents via a 4-Tier Progressive Pipeline. GitHub repository Tencent/TencentDB-Agent-Memory, MIT licence (Tencent header wrapper), HEAD commit 5736acc (2026-05-16T12:17:22Z), latest release v0.3.4 (2026-05-13), 2,674 stars, npm package@tencentdb-agent-memory/memory-tencentdb, Node >...
2026
-
[70]
The XTDB Authors. 2026. XTDB 2.x: Bitemporal SQL for the Real World. Online documentation.https://docs.xtdb.com/intro/what-is-xtdb.html
2026
-
[71]
Md Nayem Uddin, Kumar Shubham, Eduardo Blanco, Chitta Baral, and Gengyu Wang. 2026. From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents.arXiv preprint arXiv:2604.20006(2026).https://arxiv.org/abs/2604.20006
Pith/arXiv arXiv 2026
-
[72]
Pruthvinath Jeripity Venkata. 2026. Three Regimes of Context-Parametric Conflict: A Predictive Framework and Empirical Validation. arXiv:2605.11574 [cs.CL] https: //arxiv.org/abs/2605.11574
Pith/arXiv arXiv 2026
-
[73]
Joel Ward. 2025. MemoriesDB: A Temporal-Semantic-Relational Database for Long-Term Agent Memory.arXiv preprint arXiv:2511.06179(2025). https://arxiv.org/abs/ 2511.06179
arXiv 2025
-
[74]
Lei Wei, Xiao Peng, Xu Dong, Niantao Xie, and Bin Wang. 2026. FadeMem: Biologically-Inspired Forgetting for Efficient Agent Memory.arXiv preprint arXiv:2601.18642(2026). https://arxiv.org/abs/2601.18642
arXiv 2026
-
[75]
Albert Widiaatmaja, Belkis Djeffal, Ashish Dandekar, and Pierre Senellart. 2025. Demonstration of ProvSQL Update Provenance through Temporal Databases. InProvenance Week@SIGMOD.https://doi.org/10.1145/3736229.3736253
-
[76]
Di Wu, Zixiang Ji, Asmi Kawatkar, Bryan Kwan, Jia-Chen Gu, Nanyun Peng, and Kai-Wei Chang. 2026. LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues.arXiv preprint arXiv:2605.12493(2026).https://arxiv.org/abs/2605.12493
Pith/arXiv arXiv 2026
-
[77]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2025. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. In Proceedings of the 13th International Conference on Learning Representations (ICLR).https://openreview.net/forum?id=pZiyCaVuti
2025
-
[78]
Shiyao Xie and Jian Du. 2026. Neuro-Symbolic Resolution of Recommendation Conflicts in Multimorbidity Clinical Guidelines. InProceedings of the 40th Annual AAAI Conference on Artificial Intelligence, Bridge Program on Logic and AI.https://doi.org/10.48550/arXiv.2604.17340
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.17340 2026
-
[79]
Jingbo Yang, Kwei-Herng Lai, Xiaowen Wang, Shiyu Chang, Yaar Harari, and Evgeniy Gabrilovich. 2026. GroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations. arXiv:2605.14498 [cs.CL]https://arxiv.org/abs/2605.14498
Pith/arXiv arXiv 2026
-
[80]
Jiawei Yu, Yixiang Fang, Xilin Liu, and Yuchi Ma. 2026. H-Mem: A Novel Memory Mechanism for Evolving and Retrieving Agent Memory via a Hybrid Structure. arXiv:2605.15701 [cs.AI]https://arxiv.org/abs/2605.15701
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.