Beyond Global Replanning: Hierarchical Recovery for Cross-Device Agent Systems
Pith reviewed 2026-06-26 17:21 UTC · model grok-4.3
The pith
H-RePlan separates device-local recovery from global replanning via a compact failure abstraction for multi-device agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
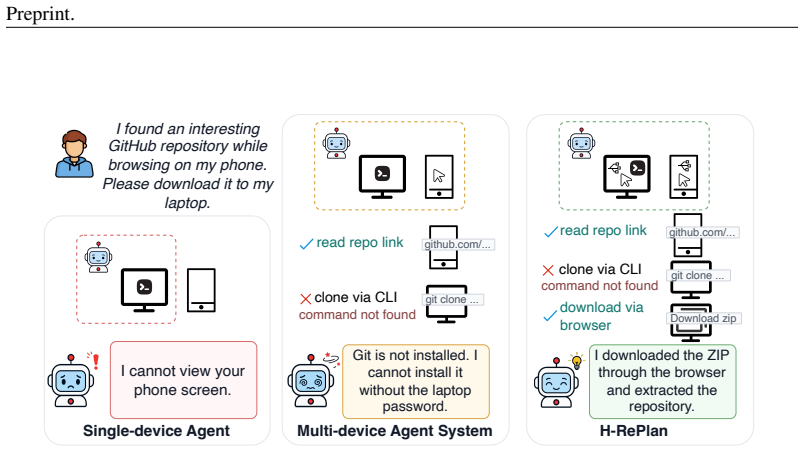
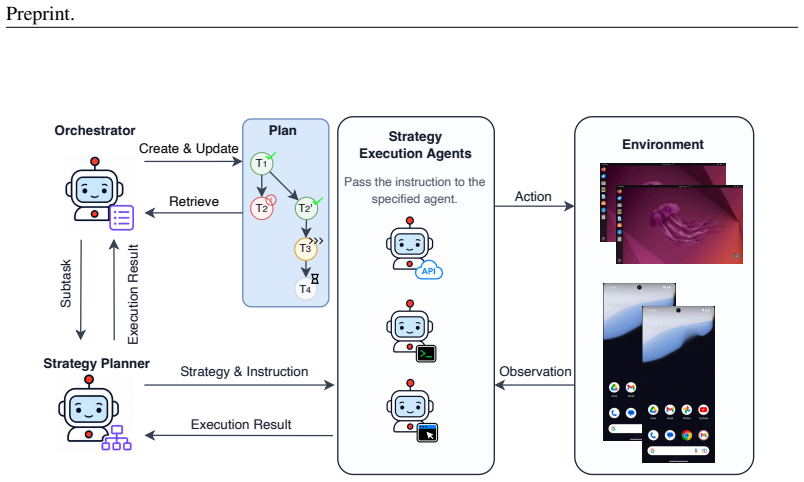
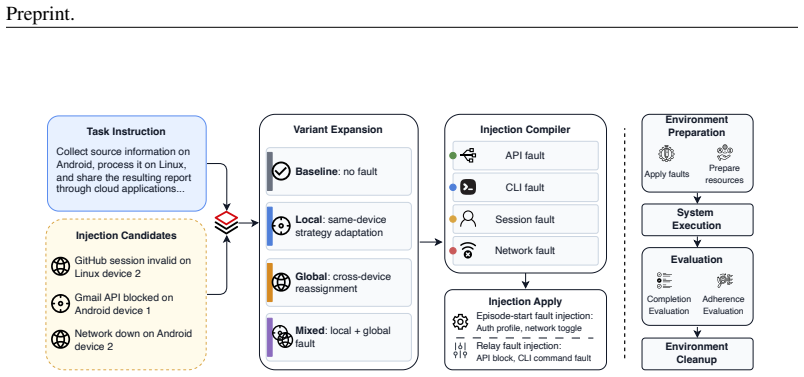
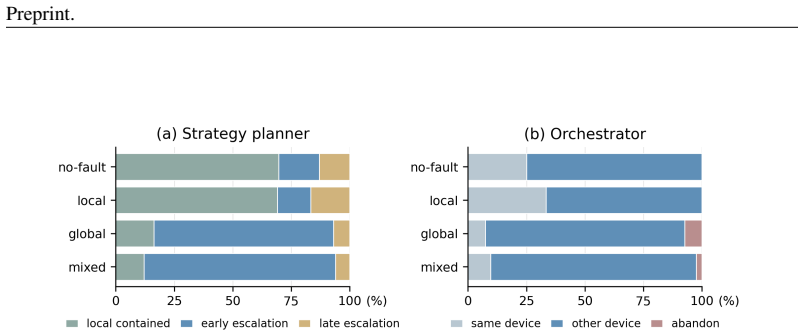
H-RePlan equips each device with interchangeable execution strategies under unified API-CLI-GUI and separates device-local strategy recovery from orchestrator-level global replanning through a compact cross-layer failure abstraction. On HeraBench, which constructs cross-device workflows and injects both strategy- and device-level failures, the method outperforms single-strategy and coarse-grained baselines in completion, instruction adherence, and perfect-pass rates while lowering the token cost required for reliable end-to-end success.
What carries the argument
Compact cross-layer failure abstraction that distinguishes strategy-level from device-level issues to choose between local recovery and global replanning.
If this is right
- Agents achieve higher instruction adherence by repairing within the current device whenever possible.
- Token cost for reliable end-to-end execution drops because global replans are invoked only when local recovery fails.
- Cross-device workflows become more robust to mixed strategy- and device-level failures without requiring full plan revision each time.
- Unified API-CLI-GUI execution allows flexible strategy switching per device without changing the orchestrator.
Where Pith is reading between the lines
- The same local-versus-global distinction could be applied to single-device agents that maintain multiple execution modes.
- If the abstraction scales, hierarchical recovery might reduce human oversight needed for long-running cross-device tasks.
- The approach suggests a general pattern for any agent system where execution environments differ in repair cost.
Load-bearing premise
The fault-injected HeraBench benchmark accurately reflects the dynamic runtime failures that occur in real cross-device agent tasks.
What would settle it
Running H-RePlan and the baselines on a set of naturally occurring failures collected from live multi-device computer-use sessions and measuring whether the reported gains in completion rate and token cost still appear.
Figures
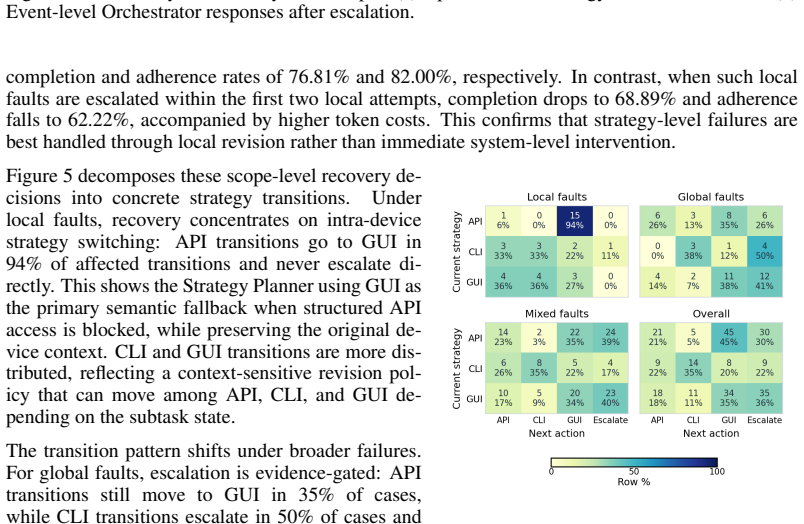
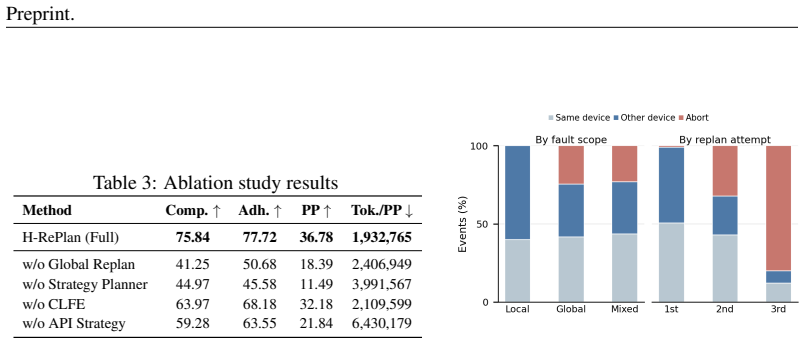
read the original abstract
Real-world computer-use tasks often span multiple applications and devices, requiring agents to coordinate heterogeneous environments under dynamic runtime failures. Existing multi-device agent systems support task decomposition and cross-device assignment, but recovery remains largely coarse-grained: when execution fails, they typically retry the same strategy, reassign the subtask, or revise the global plan, without systematically modeling the device-local strategy space. This limits their ability to distinguish failures that can be repaired within the current device from those that require cross-device replanning. We propose \textbf{H-RePlan}, a hierarchical replanning framework for multi-device agents with unified API--CLI--GUI execution. H-RePlan equips each device with interchangeable execution strategies and separates device-local strategy recovery from orchestrator-level global replanning through a compact cross-layer failure abstraction. To evaluate this capability, we introduce \textbf{HeraBench}, a fault-injected benchmark that constructs cross-device workflows over Linux and Android devices and injects strategy- and device-level failures. Experiments show that H-RePlan substantially outperforms single-strategy and coarse-grained multi-device baselines, achieving higher completion, instruction adherence, and perfect-pass rates while reducing the token cost required for reliable end-to-end success. These results demonstrate that scope-aware hierarchical recovery is essential for robust multi-device agent execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes H-RePlan, a hierarchical replanning framework for multi-device agents that equips each device with interchangeable execution strategies (unified API-CLI-GUI) and uses a compact cross-layer failure abstraction to separate device-local strategy recovery from orchestrator-level global replanning. It introduces HeraBench, a fault-injected benchmark constructing cross-device workflows over Linux and Android devices with strategy- and device-level failures. The central empirical claim is that H-RePlan substantially outperforms single-strategy and coarse-grained multi-device baselines on completion rates, instruction adherence, perfect-pass rates, and token cost for reliable end-to-end success, demonstrating that scope-aware hierarchical recovery is essential.
Significance. If the results hold, the work provides a concrete demonstration that distinguishing local from global failures via a compact abstraction can improve robustness and efficiency in heterogeneous multi-device agent systems. The introduction of HeraBench as a new evaluation platform for fault-injected cross-device workflows is a clear positive contribution that could enable future standardized comparisons. The engineering effort in supporting unified execution across device types is also noteworthy.
major comments (2)
- [HeraBench] HeraBench section: The paper provides no external validation (e.g., comparison to logged real-world failure traces from Linux/Android environments) that the injected strategy- and device-level failures occur at similar frequencies, correlations, or recovery costs as actual runtime errors. This is load-bearing for the claim that outperformance on HeraBench shows hierarchical recovery is 'essential for robust multi-device agent execution' in general rather than benchmark-specific.
- [Experiments] Experiments section: The reported outperformance lacks accompanying details on the number of trials per condition, statistical significance tests, precise failure injection methodology (e.g., distribution parameters), and exact definitions of the single-strategy and coarse-grained baselines. Without these, the quantitative claims on completion, adherence, and token cost cannot be fully assessed for reliability.
minor comments (1)
- [Abstract] The abstract states results without referencing specific tables or figures; adding such cross-references would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [HeraBench] HeraBench section: The paper provides no external validation (e.g., comparison to logged real-world failure traces from Linux/Android environments) that the injected strategy- and device-level failures occur at similar frequencies, correlations, or recovery costs as actual runtime errors. This is load-bearing for the claim that outperformance on HeraBench shows hierarchical recovery is 'essential for robust multi-device agent execution' in general rather than benchmark-specific.
Authors: We acknowledge that HeraBench uses synthetically injected failures rather than direct validation against real-world traces. The failure categories were selected to reflect commonly observed issues in cross-device settings (API timeouts, CLI errors, GUI mismatches), but we do not provide frequency or correlation matching to production logs. This is a genuine limitation for generalizing the 'essential' claim beyond the benchmark. In revision we will (1) add a dedicated Limitations section discussing the synthetic nature of HeraBench and (2) moderate the abstract and conclusion language to state that the results demonstrate benefits under controlled fault conditions rather than claiming broad necessity for all real-world deployments. revision: partial
-
Referee: [Experiments] Experiments section: The reported outperformance lacks accompanying details on the number of trials per condition, statistical significance tests, precise failure injection methodology (e.g., distribution parameters), and exact definitions of the single-strategy and coarse-grained baselines. Without these, the quantitative claims on completion, adherence, and token cost cannot be fully assessed for reliability.
Authors: We agree these details are necessary for full assessment. The original submission omitted them primarily due to space constraints. In the revised manuscript we will expand the Experiments section to report: number of trials per condition (50), statistical tests performed (Wilcoxon signed-rank with p-values), exact failure injection parameters (including distribution over strategy- and device-level faults), and precise operational definitions of all baselines. We will also release the full experimental harness and logs as supplementary material. revision: yes
Circularity Check
No circularity: empirical claims rest on new benchmark and external baselines
full rationale
The paper introduces H-RePlan (a hierarchical recovery framework) and HeraBench (a fault-injected benchmark) and reports experimental outperformance on completion, adherence, and token cost versus single-strategy and coarse-grained baselines. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation chain. The central claims are direct empirical measurements on an externally described benchmark and are therefore falsifiable outside any internal fit or renaming. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tianqi Xu and Linyao Chen and Dai
-
[2]
CoRR , volume =
Chaoyun Zhang and Liqun Li and He Huang and Chiming Ni and Bo Qiao and Si Qin and Yu Kang and Minghua Ma and Qingwei Lin and Saravan Rajmohan and Dongmei Zhang , title =. CoRR , volume =
-
[3]
CoRR , volume =
Chaoyun Zhang and Shilin He and Liqun Li and Si Qin and Yu Kang and Qingwei Lin and Dongmei Zhang , title =. CoRR , volume =
-
[4]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =
-
[5]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
-
[6]
NeurIPS , year =
Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu , title =. NeurIPS , year =
-
[7]
CoRR , volume =
Yunhe Yan and Shihe Wang and Jiajun Du and Yexuan Yang and Yuxuan Shan and Qichen Qiu and Xianqing Jia and Xinge Wang and Xin Yuan and Xu Han and Mao Qin and Yinxiao Chen and Chen Peng and Shangguang Wang and Mengwei Xu , title =. CoRR , volume =
-
[8]
Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik Narasimhan and Ofir Press , title =
John Yang and Carlos E. Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik Narasimhan and Ofir Press , title =. NeurIPS , year =
-
[9]
2026 , eprint=
CoAct-1: Computer-using Multi-Agent System with Coding Actions , author=. 2026 , eprint=
2026
-
[10]
Maddison and Tatsunori Hashimoto , title =
Yangjun Ruan and Honghua Dong and Andrew Wang and Silviu Pitis and Yongchao Zhou and Jimmy Ba and Yann Dubois and Chris J. Maddison and Tatsunori Hashimoto , title =
-
[11]
NeurIPS , year =
Haotian Sun and Yuchen Zhuang and Lingkai Kong and Bo Dai and Chao Zhang , title =. NeurIPS , year =
-
[12]
Lutfi Eren Erdogan and Nicholas Lee and Sehoon Kim and Suhong Moon and Hiroki Furuta and Gopala Anumanchipalli and Kurt Keutzer and Amir Gholami , title =
-
[13]
Learning When to Plan: Efficiently Allocating Test-Time Compute for
Davide Paglieri and Bartlomiej Cupial and Jonathan Cook and Ulyana Piterbarg and Jens Tuyls and Edward Grefenstette and Jakob Nicolaus Foerster and Jack Parker. Learning When to Plan: Efficiently Allocating Test-Time Compute for. CoRR , volume =
-
[14]
Stein and Ziyu Yao , title =
Mohamed Aghzal and Gregory J. Stein and Ziyu Yao , title =. CoRR , volume =
-
[15]
CoRR , volume =
Xing Zhang and Yanwei Cui and Guanghui Wang and Wei Qiu and Ziyuan Li and Fangwei Han and Yajing Huang and Hengzhi Qiu and Bing Zhu and Peiyang He , title =. CoRR , volume =
-
[16]
CoRR , volume =
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Shaokun Zhang and Erkang Zhu and Beibin Li and Li Jiang and Xiaoyun Zhang and Chi Wang , title =. CoRR , volume =
-
[17]
MetaGPT: Meta Programming for
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. MetaGPT: Meta Programming for
-
[18]
Chen Qian and Wei Liu and Hongzhang Liu and Nuo Chen and Yufan Dang and Jiahao Li and Cheng Yang and Weize Chen and Yusheng Su and Xin Cong and Juyuan Xu and Dahai Li and Zhiyuan Liu and Maosong Sun , title =
-
[19]
Deep Learning , author=
-
[20]
CoRR , volume =
Kimi Team , title =. CoRR , volume =
-
[21]
CoRR , volume =
Xinzge Gao and Chuanrui Hu and Bin Chen and Teng Li , title =. CoRR , volume =
-
[22]
NeurIPS , year =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , title =. NeurIPS , year =
-
[23]
Kephart and David M
Jeffrey O. Kephart and David M. Chess , title =. Computer , volume =
-
[24]
Veloso , title =
Karen Zita Haigh and Manuela M. Veloso , title =. Auton. Robots , volume =
-
[25]
Archiki Prasad and Alexander Koller and Mareike Hartmann and Peter Clark and Ashish Sabharwal and Mohit Bansal and Tushar Khot , title =
-
[26]
Ao Li and Yuexiang Xie and Songze Li and Fugee Tsung and Bolin Ding and Yaliang Li , title =
-
[27]
OpenClaw: Your Own Personal
Steinberger, Peter and. OpenClaw: Your Own Personal. 2026 , howpublished=
2026
-
[28]
Chaoyun Zhang and He Huang and Chiming Ni and Jian Mu and Si Qin and Shilin He and Lu Wang and Fangkai Yang and Pu Zhao and Bo Qiao and Chao Du and Liqun Li and Yu Kang and Paul Jiang and Suzhen Zheng and Rujia Wang and Jiaxu Qian and Minghua Ma and Jian. Trans. Mach. Learn. Res. , volume =
-
[29]
CoRR , volume =
Ehud Karpas and Omri Abend and Yonatan Belinkov and Barak Lenz and Opher Lieber and Nir Ratner and Yoav Shoham and Hofit Bata and Yoav Levine and Kevin Leyton. CoRR , volume =
-
[30]
Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle =
Timo Schick and Jane Dwivedi. Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle =
-
[31]
Patil and Tianjun Zhang and Xin Wang and Joseph E
Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , title =. NeurIPS , year =
-
[32]
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and Dahai Li and Zhiyuan Liu and Maosong Sun , title =
-
[33]
Chi Zhang and Zhao Yang and Jiaxuan Liu and Yanda Li and Yucheng Han and Xin Chen and Zebiao Huang and Bin Fu and Gang Yu , title =
-
[34]
CoRR , volume =
Junyang Wang and Haiyang Xu and Jiabo Ye and Ming Yan and Weizhou Shen and Ji Zhang and Fei Huang and Jitao Sang , title =. CoRR , volume =
-
[35]
Frank F. Xu and Yufan Song and Boxuan Li and Yuxuan Tang and Kritanjali Jain and Mengxue Bao and Zora Zhiruo Wang and Xuhui Zhou and Zhitong Guo and Murong Cao and Mingyang Yang and Hao Yang Lu and Amaad Martin and Zhe Su and Leander Maben and Raj Mehta and Wayne Chi and Lawrence Keunho Jang and Yiqing Xie and Shuyan Zhou and Graham Neubig , title =. CoRR...
-
[36]
Chang and Longling Geng , title =
Edward Y. Chang and Longling Geng , title =. Proc
-
[37]
Benchmarking Failures in Tool-Augmented Language Models , booktitle =
Eduardo Trevi. Benchmarking Failures in Tool-Augmented Language Models , booktitle =
-
[38]
CoRR , volume =
Jin Jia and Zhiling Deng and Zhuangbin Chen and Yingqi Wang and Zibin Zheng , title =. CoRR , volume =
-
[39]
NeurIPS , year =
Chang Ma and Junlei Zhang and Zhihao Zhu and Cheng Yang and Yujiu Yang and Yaohui Jin and Zhenzhong Lan and Lingpeng Kong and Junxian He , title =. NeurIPS , year =
-
[40]
Yang Liu and Dan Iter and Yichong Xu and Shuohang Wang and Ruochen Xu and Chenguang Zhu , editor =. G-Eval:. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.153 , timestamp =
-
[41]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
-
[42]
Seungone Kim and Jamin Shin and Yejin Choi and Joel Jang and Shayne Longpre and Hwaran Lee and Sangdoo Yun and Seongjin Shin and Sungdong Kim and James Thorne and Minjoon Seo , title =
-
[43]
Peiyi Wang and Lei Li and Liang Chen and Zefan Cai and Dawei Zhu and Binghuai Lin and Yunbo Cao and Lingpeng Kong and Qi Liu and Tianyu Liu and Zhifang Sui , title =
-
[44]
Measuring nominal scale agreement among many raters , volume =
Fleiss, Joseph , year =. Measuring nominal scale agreement among many raters , volume =. Psychological Bulletin , doi =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.