A11YRepair: Bridging Web Accessibility Barriers via Knowledge-Enhanced Divide-and-Conquer Repair
Pith reviewed 2026-06-26 11:54 UTC · model grok-4.3
The pith
A11YRepair repairs clusters of related web accessibility violations more effectively by grouping coordinated edits and adding WCAG knowledge to an LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
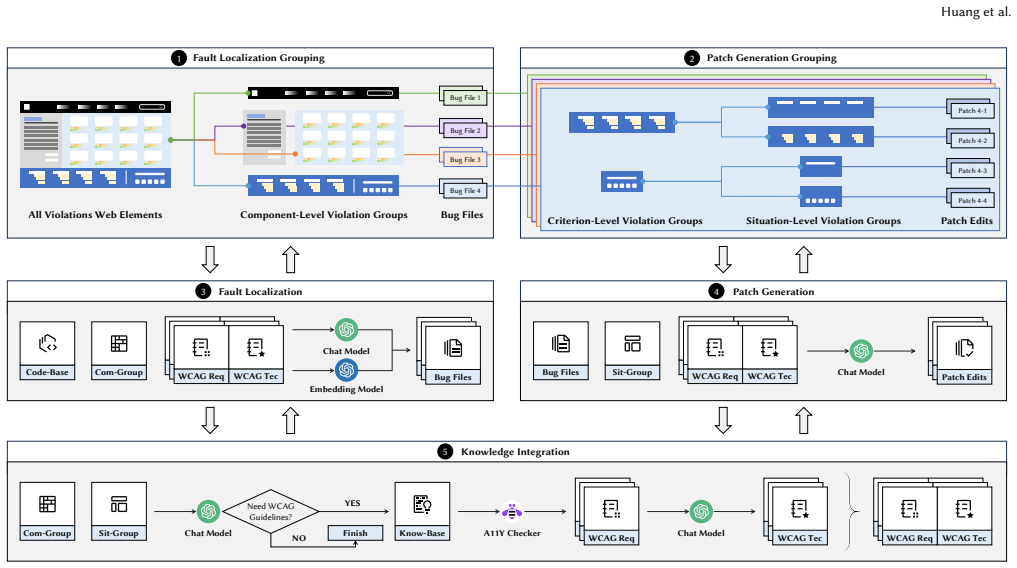
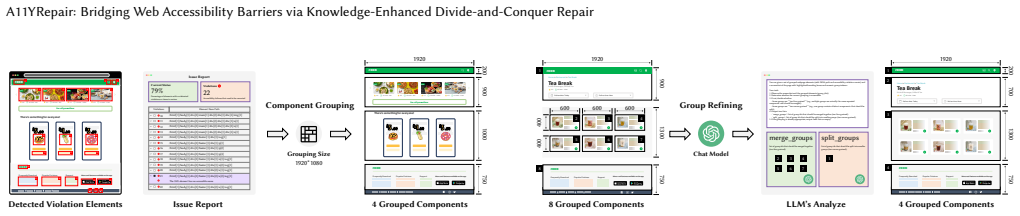
A11YRepair introduces a divide-and-conquer workflow that clusters violations requiring coordinated edits to reduce redundant localization, then decomposes each cluster by root cause so the LLM can generate focused and consistent patches. The framework further incorporates WCAG-driven knowledge to strengthen domain awareness during both fault localization and patch synthesis. On A11YBench of 60 real-world web projects, it achieves higher repair effectiveness and lower cost than state-of-the-art baselines, ablation studies confirm the importance of its design choices, and generated patches have been merged into open-source projects from Google, Microsoft, Facebook, IBM, K8s, Docker, and Alibab
What carries the argument
Divide-and-conquer workflow that clusters violations needing coordinated edits across files and decomposes them by root cause, augmented with selective WCAG knowledge for localization and synthesis.
If this is right
- Existing single-fault APR systems can be extended to multi-fault web scenarios by adding an explicit clustering step before localization.
- Selective injection of guideline documents like WCAG improves LLM patch quality without full retraining.
- Repair cost drops when redundant localization across related violations is avoided.
- Patches produced this way have a higher chance of acceptance in real open-source projects.
- The same workflow structure applies to any domain where guideline documents exist and violations tend to co-occur.
Where Pith is reading between the lines
- The clustering step could be reused for other multi-location repair tasks such as security or performance fixes that span several files.
- If root-cause decomposition proves brittle on certain page structures, hybrid human-LLM review of clusters might be needed.
- The approach suggests that guideline-aware repair could be tested on mobile or desktop accessibility issues beyond web WCAG.
Load-bearing premise
That violations can be reliably clustered by the need for coordinated edits and then decomposed by root cause such that an LLM supplied with WCAG knowledge will produce focused, consistent patches without introducing new violations.
What would settle it
A new set of web projects in which automatic clustering often groups unrelated violations or the resulting patches introduce additional WCAG violations at similar rates to baselines.
Figures









read the original abstract
Web accessibility (A11Y), which ensures web content is perceivable and usable for users with disabilities, is a critical requirement for modern web applications. Yet existing tooling overwhelmingly focuses on detecting A11Y violations rather than repairing them. Automated program repair (APR) techniques appear promising for this setting, but our study shows that state-of-the-art APR systems perform poorly when applied to real-world A11Y violations. Unlike conventional sparse-bug scenarios, web A11Y issues often manifest as multiple structurally related violations per page, requiring coordinated edits across multiple files. Existing repair systems fail to manage this multi-fault scale, as they handle each bug individually without considering their relationships or incorporating domain rules such as the Web Content Accessibility Guidelines (WCAG). We propose A11YRepair, an LLM-based framework for web A11Y repair. A11YRepair introduces a divide-and-conquer workflow that first clusters violations requiring coordinated edits to reduce redundant localization, and then decomposes each cluster by root cause so the LLM can generate focused and consistent patches. The framework further incorporates WCAG-driven knowledge to strengthen domain awareness during both fault localization and patch synthesis. To support systematic evaluation, we construct A11YBench, a benchmark of 60 real-world web projects collected from GitHub. Experimental results show that A11YRepair achieves higher repair effectiveness and lower cost than state-of-the-art baselines, and ablation studies confirm the importance of its divide-and-conquer design and selective domain knowledge integration. Specifically, patches generated by A11YRepair have been merged into open-source projects from Google, Microsoft, Facebook, IBM, K8s, Docker, and Alibaba, demonstrating its practical value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces A11YRepair, an LLM-based framework for automated repair of web accessibility (A11Y) violations. It proposes a divide-and-conquer workflow that clusters violations requiring coordinated edits across files, decomposes clusters by root cause, and augments both localization and patch generation with WCAG domain knowledge. The approach is evaluated on a newly constructed benchmark A11YBench of 60 real-world GitHub projects, claiming higher repair effectiveness and lower cost than state-of-the-art APR baselines, with ablation studies supporting the design choices and several generated patches merged into projects from major organizations.
Significance. If the experimental claims hold after verification of the evaluation protocol, the work addresses a genuine gap between A11Y detection tools and practical repair, where multi-fault, cross-file violations are common. The divide-and-conquer strategy plus selective WCAG integration is a plausible adaptation of APR ideas to this domain, and the reported upstream merges provide concrete evidence of practical utility beyond synthetic benchmarks.
major comments (2)
- [Evaluation / Experimental results] The central effectiveness claim rests on the divide-and-conquer workflow (clustering coordinated violations then root-cause decomposition) producing focused, consistent patches. However, the evaluation provides no quantitative metrics on clustering precision, recall, or inter-cluster consistency, leaving the key assumption that the LLM will generate non-conflicting edits untested.
- [Evaluation / Experimental results] No post-repair re-scanning of pages for newly introduced A11Y violations is reported. Without this check, it is impossible to confirm that the claimed effectiveness gains do not come at the cost of creating fresh violations, directly undermining the comparison to baselines.
minor comments (2)
- [Benchmark construction] The abstract states that A11YBench contains 60 projects but does not specify how projects or violations were selected or filtered; this detail belongs in the benchmark-construction subsection.
- [Ablation studies] Ablation results are summarized at a high level; tables should report per-metric deltas (e.g., success rate, cost) with statistical significance tests rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol. We address each major comment below and will incorporate revisions to strengthen the experimental claims.
read point-by-point responses
-
Referee: [Evaluation / Experimental results] The central effectiveness claim rests on the divide-and-conquer workflow (clustering coordinated violations then root-cause decomposition) producing focused, consistent patches. However, the evaluation provides no quantitative metrics on clustering precision, recall, or inter-cluster consistency, leaving the key assumption that the LLM will generate non-conflicting edits untested.
Authors: We acknowledge that the manuscript does not report direct quantitative metrics (precision, recall, or inter-cluster consistency) for the clustering step against any ground-truth clustering. The current evaluation instead relies on end-to-end repair success rates, ablation studies that isolate the contribution of clustering and decomposition, and the practical outcome of upstream patch merges. To directly test the assumption of non-conflicting edits, we will add a dedicated analysis of clustering quality in the revised manuscript, including precision/recall metrics computed against manually validated clusters on a subset of the benchmark. revision: yes
-
Referee: [Evaluation / Experimental results] No post-repair re-scanning of pages for newly introduced A11Y violations is reported. Without this check, it is impossible to confirm that the claimed effectiveness gains do not come at the cost of creating fresh violations, directly undermining the comparison to baselines.
Authors: We agree this verification is necessary to ensure the reported gains do not mask regressions. The original experiments did not include a systematic post-repair re-scan of all pages using the same detection tools. In the revision we will add this analysis, reporting the count of newly introduced violations (if any) for A11YRepair and each baseline, thereby confirming that effectiveness improvements are not achieved at the expense of additional violations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an LLM-based empirical framework for A11Y repair with divide-and-conquer clustering and WCAG integration, evaluated on a newly constructed A11YBench benchmark plus real-world patch merges. No equations, parameters, or predictions are present that could reduce to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the derivation chain. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026.A11YBench
A11YBench. 2026.A11YBench. Retrieved Mar 26, 2026 from https://sites.google. com/view/a11yrepair/a11ybench
2026
-
[2]
2026.A11YRepair
A11YRepair. 2026.A11YRepair. Retrieved Mar 26, 2026 from https://sites.google. com/view/a11yrepair
2026
-
[3]
2026.Figshare
A11YRepair. 2026.Figshare. Retrieved Mar 26, 2026 from https://doi.org/10.6084/ m9.figshare.31896229
2026
-
[4]
2026.Impact
A11YRepair. 2026.Impact. Retrieved Mar 26, 2026 from https://sites.google.com/ view/a11yrepair/impact
2026
-
[5]
Suliman K Almasoud and Hassan I Mathkour. 2019. Instant adaptation enrich- ment technique to improve web accessibility for blind users. InProceedings of the 2019 3rd International Conference on Information System and Data Mining. 159–164
2019
-
[6]
Ali S Alotaibi, Paul T Chiou, and William GJ Halfond. 2021. Automated repair of size-based inaccessibility issues in mobile applications. InProceedings of the 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). 730–742
2021
-
[7]
Abdulaziz Alshayban and Sam Malek. 2022. AccessiText: automated detection of text accessibility issues in Android apps. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 984–995
2022
-
[8]
Abdul Haddi Amjad, Muhammad Danish, Bless Jah, and Muhammad Ali Gulzar
-
[9]
InProceedings of the 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
Accessibility Issues in Ad-Driven Web Applications. InProceedings of the 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 2393–2405
2025
-
[10]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. InProceedings of the 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 2188–2200
2025
-
[11]
Jieshan Chen, Chunyang Chen, Zhenchang Xing, Xiwei Xu, Liming Zhu, Guo- qiang Li, and Jinshui Wang. 2020. Unblind your apps: Predicting natural- language labels for mobile gui components by deep learning. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE). 322–334
2020
- [12]
-
[13]
Paul T Chiou, Ali S Alotaibi, and William GJ Halfond. 2021. Detecting and localizing keyboard accessibility failures in web applications. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 855–867
2021
-
[14]
Paul T Chiou, Robert Winn, Ali S Alotaibi, and William GJ Halfond. 2024. Au- tomatically Detecting Reflow Accessibility Issues in Responsive Web Pages. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). 1811–1823
2024
-
[15]
2026.Ant Design: An enterprise-class UI design language and React UI library
Ant Design. 2026.Ant Design: An enterprise-class UI design language and React UI library. Retrieved Jan 13, 2026 from https://github.com/ant-design/ant-design.git
2026
-
[16]
2026.Ant Design: Help designers/developers building beautiful products more flexible and working with happiness
Ant Design. 2026.Ant Design: Help designers/developers building beautiful products more flexible and working with happiness. Retrieved Jan 13, 2026 from https: //ant.design/
2026
-
[17]
Nadeen Fathallah, Daniel Hernández, and Steffen Staab. 2025. AccessGuru: Leveraging LLMs to Detect and Correct Web Accessibility Violations in HTML Code. InProceedings of the 27th International ACM SIGACCESS Conference on Computers and Accessibility. 1–22
2025
-
[18]
Mexhid Ferati and Lirim Sulejmani. 2016. Automatic Adaptation Techniques to Increase the Web Accessibility for Blind Users. InInternational 2016 - Posters’ Extended Abstracts - 18th International Conference, HCI, Vol. 618. 30–36
2016
-
[19]
2025.Lighthouse
Google. 2025.Lighthouse. Retrieved Oct 01, 2025 from https://developer.chrome. com/docs/lighthouse/
2025
-
[20]
Jiahao Gu and Huaxun Huang. 2025. Characterizing and Repairing Color-Related Accessibility Issues in Android Apps. (2025), 1–13
2025
-
[21]
Alexandra-Elena Guriţă and Radu-Daniel Vatavu. 2025. When LLM-Generated Code Perpetuates User Interface Accessibility Barriers, How Can We Break the Cycle. InProceedings of the 22nd International Web for All Conference (W4A’25)
2025
- [22]
-
[23]
I Tend to View Ads Almost Like a Pestilence
Ziyao He, Syed Fatiul Huq, and Sam Malek. 2024. “I Tend to View Ads Almost Like a Pestilence”: On the Accessibility Implications of Mobile Ads for Blind Huang et al. Users. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). 2432–2444
2024
-
[24]
Ziyao He, Syed Fatiul Huq, and Sam Malek. 2025. Enhancing Web Accessibility: Automated Detection of Issues with Generative AI.Proceedings of the ACM on Software Engineering2, FSE (2025), 2264–2287
2025
- [25]
-
[26]
Kai Huang, Zhengzi Xu, Su Yang, Hongyu Sun, Xuejun Li, Zheng Yan, and Yuqing Zhang. 2024. Evolving paradigms in automated program repair: Taxonomy, challenges, and opportunities.Comput. Surveys57, 2 (2024), 1–43
2024
-
[27]
Kai Huang, Jian Zhang, Xiaofei Xie, and Chunyang Chen. 2025. Seeing is Fixing: Cross-Modal Reasoning with Multimodal LLMs for Visual Software Issue Repair. InProceedings of the 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1156–1168
2025
-
[28]
Syed Fatiul Huq, Abdulaziz Alshayban, Ziyao He, and Sam Malek. 2023. #A11yDev: Understanding Contemporary Software Accessibility Practices from Twitter Conversations. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–18
2023
-
[29]
IBM. 2025.IBM Accessibility Requirements: Here are the latest published rule sets in the IBM Equal Access Accessibility Checker.Retrieved Oct 01, 2025 from https://www.ibm.com/able/requirements/checker-rule-sets/
2025
-
[30]
IBM. 2025.IBM Accessibility Requirements: This page lists the accessibility require- ments that need to be met for several standards and regulations.Retrieved Oct 01, 2025 from https://www.ibm.com/able/requirements/requirements/
2025
-
[31]
2025.IBM Equal Access Toolkit
IBM. 2025.IBM Equal Access Toolkit. Retrieved Oct 01, 2025 from https://www. ibm.com/able/toolkit/
2025
-
[32]
2026.Label in Name
IBM. 2026.Label in Name. Retrieved Jan 25, 2026 from https://www.ibm.com/ able/requirements/requirements/?version=v7_3#2_5_3
2026
-
[33]
Shubhi Jain, Syed Fatiul Huq, Ziyao He, and Sam Malek. 2025. Automated Detection of Web Application Navigation Barriers for Screen Reader Users. In Proceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1906–1918
2025
-
[34]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations
2024
-
[35]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis (ISSTA). 437–440
2014
-
[36]
Arun Krishnavajjala, SM Hasan Mansur, Justin Jose, and Kevin Moran. 2024. Motorease: Automated Detection of Motor Impairment Accessibility Issues in Mobile App UIs. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). 2580–2592
2024
-
[37]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2012. GenProg: A Generic Method for Automatic Software Repair.IEEE Transactions on Software Engineering38, 1 (2012)
2012
-
[38]
Cheryl Lee, Chunqiu Steven Xia, Longji Yang, Jen-tse Huang, Zhouruixing Zhu, Lingming Zhang, and Michael R Lyu. 2025. UniDebugger: Hierarchical Multi- Agent Framework for Unified Software Debugging. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP). 18248– 18277
2025
-
[39]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. TBar: Revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 31–42
2019
-
[40]
Andrea Mangiatordi and Marco Lazzari. 2018. Combined use of artificial intelli- gence and crowdsourcing to provide alternative content for images on websites. InProceedings of the 2018 15th IEEE Annual Consumer Communications & Net- working Conference (CCNC). 1–6
2018
- [41]
-
[42]
Forough Mehralian, Ziyao He, and Sam Malek. 2025. Automated Accessibility Analysis of Dynamic Content Changes on Mobile Apps. InProceedings of the 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 2689–2701
2025
-
[43]
Forough Mehralian, Navid Salehnamadi, Syed Fatiul Huq, and Sam Malek. 2022. Too much accessibility is harmful! automated detection and analysis of overly accessible elements in mobile apps. InProceedings of the 37th IEEE/ACM Interna- tional Conference on Automated Software Engineering (ASE). 1–13
2022
-
[44]
Forough Mehralian, Navid Salehnamadi, and Sam Malek. 2021. Data-driven accessibility repair revisited: on the effectiveness of generating labels for icons in Android apps. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 107–118
2021
- [45]
-
[46]
Peya Mowar, Yi-Hao Peng, Jason Wu, Aaron Steinfeld, and Jeffrey P Bigham. 2025. CodeA11y: Making AI Coding Assistants Useful for Accessible Web Development. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–15
2025
-
[47]
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chan- dra. 2013. Semfix: Program repair via semantic analysis. InProceedings of the 2013 35th International Conference on Software Engineering (ICSE). 772–781
2013
-
[48]
2025.o4-mini-2025-04-16
OpenAI. 2025.o4-mini-2025-04-16. Retrieved Oct 01, 2025 from https://platform. openai.com/docs/models/o4-mini
2025
-
[49]
2025.text-embedding-3-small
OpenAI. 2025.text-embedding-3-small. Retrieved Oct 01, 2025 from https: //platform.openai.com/docs/models/text-embedding-3-small
2025
-
[50]
Haifeng Ruan, Yuntong Zhang, and Abhik Roychoudhury. 2025. SpecRover: Code Intent Extraction via LLMs. InProceedings of the 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 963–974
2025
-
[51]
Navid Salehnamadi, Forough Mehralian, and Sam Malek. 2022. Groundhog: An automated accessibility crawler for mobile apps. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1–12
2022
-
[52]
Letícia Seixas Pereira, João Guerreiro, André Rodrigues, Tiago Guerreiro, and Carlos Duarte. 2024. From Automation to User Empowerment: Investigating the Role of a Semi-automatic Tool in Social Media Accessibility.ACM Transactions on Accessible Computing17, 3 (2024), 1–25
2024
-
[53]
Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, and Graham Neubig
-
[54]
arXiv preprint arXiv:2506.03011(2025)
Coding Agents with Multimodal Browsing are Generalist Problem Solvers. arXiv preprint arXiv:2506.03011(2025)
-
[55]
2025.Axe accessibility testing tools are the best on the planet
Deque Systems. 2025.Axe accessibility testing tools are the best on the planet. Retrieved Oct 01, 2025 from https://www.deque.com/axe/
2025
-
[56]
Mahan Tafreshipour, Anmol Deshpande, Forough Mehralian, Iftekhar Ahmed, and Sam Malek. 2024. Ma11y: A Mutation Framework for Web Accessibility Testing. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 100–111
2024
-
[57]
SWE-Bench Team. 2025. SWE-Bench Multimodal Leaderboard. https://www. swebench.com/index.html#multimodal. Accessed: 2025-10-23
2025
-
[58]
Trae Research Team, Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, Yun Lin, Yingfei Xiong, Chao Peng, and Xia Liu. 2025. Trae Agent: An LLM-based Agent for Software Engineering with Test-time Scaling. (2025). arXiv:2507.23370
-
[59]
2025.Techniques for WCAG 2.2
WAI. 2025.Techniques for WCAG 2.2. Retrieved Dec 02, 2025 from https: //www.w3.org/WAI/WCAG22/Techniques/
2025
-
[60]
2025.Understanding SC 1.1.1: Non-text Content (Level A)
WAI. 2025.Understanding SC 1.1.1: Non-text Content (Level A). Retrieved Oct 01, 2025 from https://www.w3.org/WAI/WCAG22/Understanding/non-text- content.html
2025
-
[61]
2025.Understanding SC 1.4.3: Contrast (Minimum) (Level AA)
WAI. 2025.Understanding SC 1.4.3: Contrast (Minimum) (Level AA). Retrieved Oct 01, 2025 from https://www.w3.org/WAI/WCAG22/Understanding/contrast- minimum.html
2025
-
[62]
2025.Understanding SC 2.5.8: Target Size (Minimum) (Level AA)
WAI. 2025.Understanding SC 2.5.8: Target Size (Minimum) (Level AA). Retrieved Oct 01, 2025 from https://www.w3.org/WAI/WCAG22/Understanding/target- size-minimum
2025
-
[63]
2025.Web Content Accessibility Guidelines (WCAG) 2.2
WAI. 2025.Web Content Accessibility Guidelines (WCAG) 2.2. Retrieved Dec 02, 2025 from https://www.w3.org/TR/WCAG22/
2025
-
[64]
Yuxuan Wan, Chaozheng Wang, Yi Dong, Wenxuan Wang, Shuqing Li, Yintong Huo, and Michael Lyu. 2025. Divide-and-Conquer: Generating UI Code from Screenshots.Proceedings of the ACM on Software Engineering2, FSE (2025), 2099–2122
2025
-
[65]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
2025
-
[66]
2025.The 2025 report on the accessibility of the top 1,000,000 home pages
WebAIM. 2025.The 2025 report on the accessibility of the top 1,000,000 home pages. Retrieved Oct 01, 2025 from https://webaim.org/projects/million/
2025
-
[67]
2025.W A VE Web Accessibility Evaluation Tools
WebAIM. 2025.W A VE Web Accessibility Evaluation Tools. Retrieved Oct 01, 2025 from https://wave.webaim.org/
2025
-
[68]
Shaomei Wu, Jeffrey Wieland, Omid Farivar, and Julie Schiller. 2017. Automatic alt-text: Computer-generated image descriptions for blind users on a social net- work service. InProceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing. 1180–1192
2017
-
[69]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying llm-based software engineering agents.Proceedings of the ACM on Software Engineering2, FSE (2025), 801–824
2025
-
[70]
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, and Lingming Zhang
-
[71]
Live-SWE- agent: Can software engineering agents self-evolve on the fly? CoRR, abs/2511.13646, 2025
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?arXiv preprint arXiv:2511.13646(2025). A11YRepair: Bridging Web Accessibility Barriers via Knowledge-Enhanced Divide-and-Conquer Repair
-
[72]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 959–971
2022
-
[73]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 819–831
2024
- [74]
-
[75]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[76]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Yang, Sida Wang, and Ofir Press. 2025. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?. InThe Thirteenth International Conference on Learning Representations
2025
-
[77]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InThe eleventh International Conference on Learning Representations. 1–33
2023
-
[78]
He Ye, Aidan ZH Yang, Chang Hu, Yanlin Wang, Tao Zhang, and Claire Le Goues
-
[79]
AdverIntent-Agent: Adversarial Reasoning for Repair Based on Inferred Program Intent.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1398–1420
2025
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.