EML Trees Are Universal Approximators
Pith reviewed 2026-06-26 08:45 UTC · model grok-4.3
The pith
Trees composed of EML functions can approximate any function in W^{k,∞} to arbitrary accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that such trees enjoy a universal approximation property for functions in W^{k, ∞} for k ∈ ℕ, drawing on classical neural network approximation arguments while exploiting the ability to explicitly construct EML trees that mimic polynomial representations. We further propose a learning algorithm for EML-type trees equipped with fitting parameters, and demonstrate its feasibility in practical optimization problems.
What carries the argument
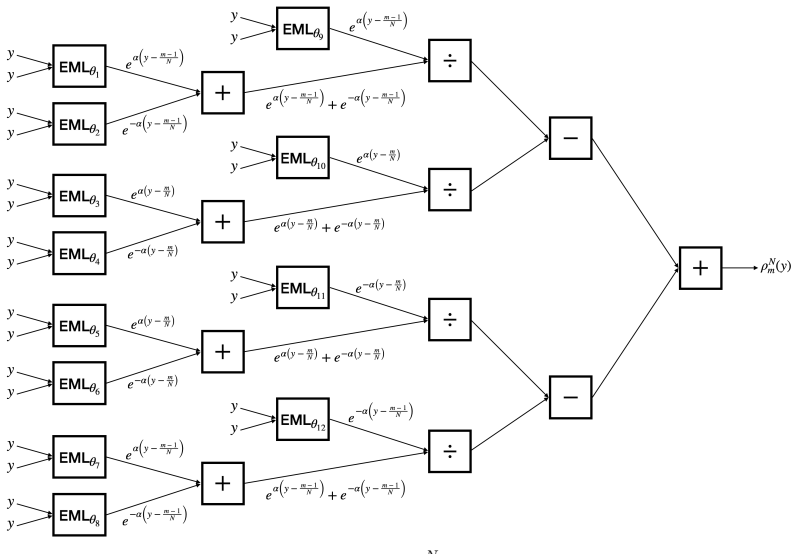
Tree-structured compositions of the EML (exp-minus-log) function, which serves as a continuous analogue of NAND gates and enables explicit mimicry of polynomial representations.
If this is right
- EML trees inherit universal approximation from neural-network theory once the polynomial-mimicry construction is available.
- A parameter-fitting algorithm exists that can optimize EML trees on concrete optimization problems.
- The framework supplies theoretical grounding for using EML trees as function approximators in machine-learning settings.
- Approximation holds for every natural number k, covering functions with increasing smoothness requirements.
Where Pith is reading between the lines
- Because the trees can mimic polynomials, they may achieve exact representation for polynomial targets under suitable parameter choices.
- The same construction technique could be tested on other continuous gate analogues to check whether universal approximation transfers similarly.
- Practical scaling behavior of the learning algorithm on high-dimensional inputs remains open for direct measurement.
Load-bearing premise
It is possible to explicitly construct EML trees that mimic polynomial representations for any target function in W^{k,∞}.
What would settle it
A concrete function in W^{k,∞} on a compact domain for which no finite-depth EML tree sequence converges in the Sobolev norm would refute the universal approximation claim.
Figures
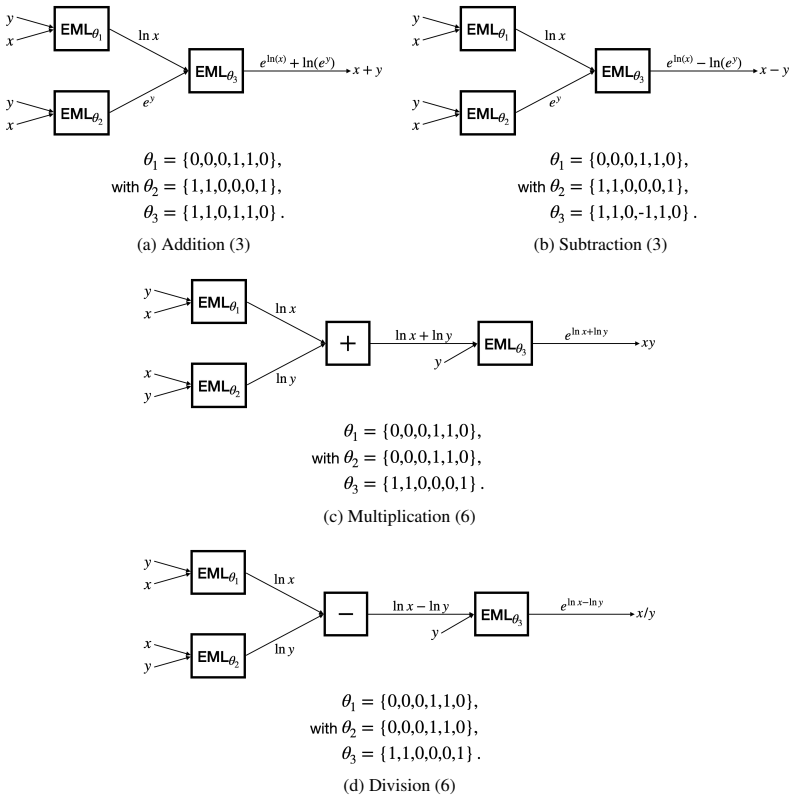
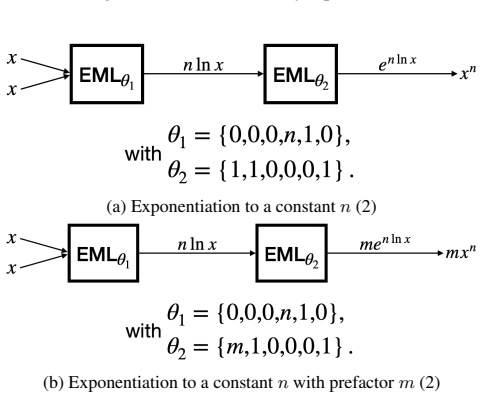
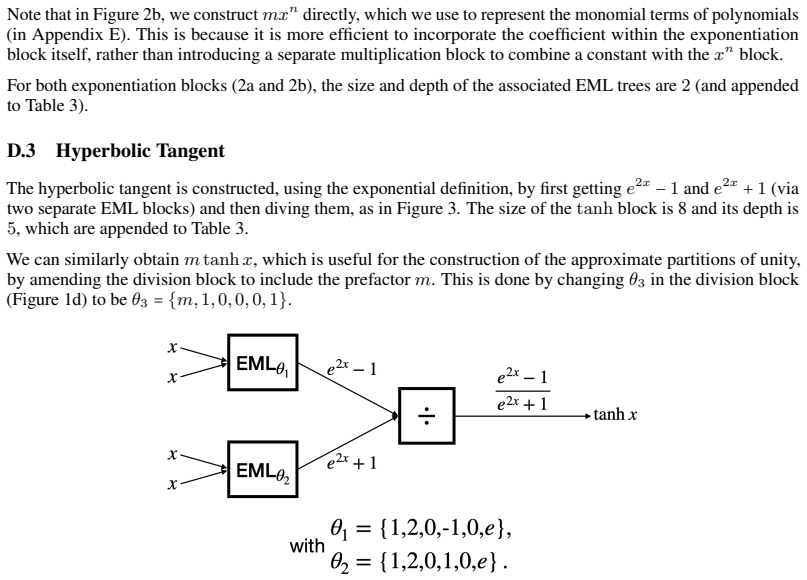
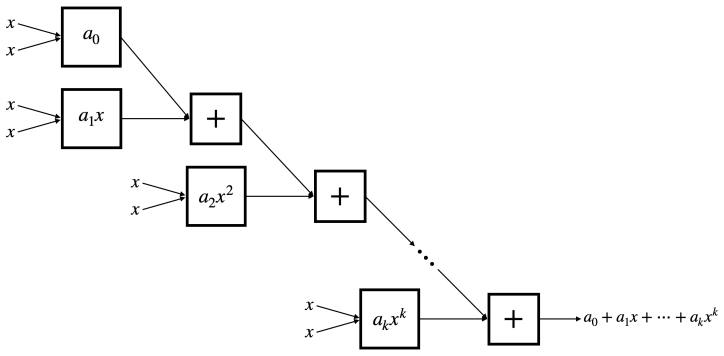
read the original abstract
The recently introduced EML (Exp-Minus-Log) function acts as continuous analogue of NAND gates, providing a compositional building block capable of representing elementary functions. In this work, we study the expressive power of tree-structured compositions of EML functions. We show that such trees enjoy a universal approximation property for functions in $W^{k, \infty}$ for $k \in \mathbb N$, drawing on classical neural network approximation arguments while exploiting the ability to explicitly construct EML trees that mimic polynomial representations. We further propose a learning algorithm for EML-type trees equipped with fitting parameters, and demonstrate its feasibility in practical optimization problems. Our results establish EML trees as a theoretically grounded framework for function approximation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that tree-structured compositions of the EML (Exp-Minus-Log) function, serving as a continuous analogue of NAND gates, possess a universal approximation property for functions in the Sobolev space W^{k,∞} (k ∈ ℕ). The argument draws on classical neural-network approximation results while relying on an explicit construction of EML trees that mimic polynomial representations; a learning algorithm for EML-type trees equipped with fitting parameters is also proposed and its feasibility shown on practical optimization tasks.
Significance. If the explicit construction is rigorously established with error bounds, the result would supply a new theoretically grounded class of universal approximators grounded in a continuous logic-gate primitive, extending existing NN theory to tree-structured EML compositions and offering a framework that could be directly useful for approximation and optimization.
major comments (2)
- [Abstract and main theorem] Abstract and the main existence argument: the transfer of classical NN universal-approximation guarantees to EML trees for the full class W^{k,∞} rests entirely on the asserted ability to explicitly construct EML trees that mimic arbitrary polynomials. No derivation from the EML definition or the tree composition rules is supplied showing how addition, multiplication, or monomials of degree >1 are obtained, nor are approximation error bounds or verification for the Sobolev norm provided; without these steps the central claim cannot be verified.
- [Learning algorithm] Learning-algorithm section: the proposed fitting procedure introduces free parameters inside the EML trees, yet it is not shown whether the optimization step preserves the polynomial-mimicking property or the resulting approximation rate for W^{k,∞}; this interaction is load-bearing for any claim that the learned trees inherit the universal-approximation guarantee.
minor comments (1)
- [Preliminaries] The notation for tree depth, composition rules, and the precise definition of the EML primitive would benefit from an additional displayed equation block for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and main theorem] Abstract and the main existence argument: the transfer of classical NN universal-approximation guarantees to EML trees for the full class W^{k,∞} rests entirely on the asserted ability to explicitly construct EML trees that mimic arbitrary polynomials. No derivation from the EML definition or the tree composition rules is supplied showing how addition, multiplication, or monomials of degree >1 are obtained, nor are approximation error bounds or verification for the Sobolev norm provided; without these steps the central claim cannot be verified.
Authors: We agree that the explicit constructions and error bounds are not derived in sufficient detail in the current manuscript. In the revision we will insert a new subsection that starts from the EML definition and tree composition rules, shows how addition and multiplication are realized, extends the construction to monomials of arbitrary degree, and supplies the corresponding approximation error bounds together with verification in the W^{k,∞} norm. This will make the appeal to classical neural-network results fully rigorous and verifiable. revision: yes
-
Referee: [Learning algorithm] Learning-algorithm section: the proposed fitting procedure introduces free parameters inside the EML trees, yet it is not shown whether the optimization step preserves the polynomial-mimicking property or the resulting approximation rate for W^{k,∞}; this interaction is load-bearing for any claim that the learned trees inherit the universal-approximation guarantee.
Authors: The universal-approximation statement is a property of the entire class of EML trees; any concrete tree, including one whose parameters have been fitted by the proposed algorithm, remains an element of that class. We will revise the manuscript to state this distinction explicitly and to note that while membership in the class guarantees the existence result, the concrete approximation rate achieved by a learned tree is governed by the optimization outcome rather than by the specific polynomial-mimicking constructions used in the existence proof. A short discussion of this point will be added to the learning-algorithm section. revision: yes
Circularity Check
No circularity detected; relies on external NN theory
full rationale
The paper's central claim transfers universal approximation from classical neural network results in W^{k,∞} by asserting an explicit construction of EML trees that mimic polynomials. This is an existence argument grounded in prior external theory rather than any self-referential definition, fitted parameter renamed as prediction, or self-citation chain. No equations or steps in the abstract reduce the result to its own inputs by construction. The construction step, while undetailed here, does not constitute circularity under the specified patterns as it is not shown to be tautological or statistically forced within the paper's own framework.
Axiom & Free-Parameter Ledger
free parameters (1)
- fitting parameters inside EML trees
axioms (1)
- domain assumption Classical neural network approximation arguments apply once EML trees can mimic polynomials
Reference graph
Works this paper leans on
-
[1]
Demystifying black-box models with symbolic metamodels
Ahmed M Alaa and Mihaela Van der Schaar. Demystifying black-box models with symbolic metamodels. Advances in neural information processing systems, 32, 2019
2019
-
[2]
Universal approximation bounds for superpositions of a sigmoidal function.IEEE Transactions on Information theory, 39(3):930–945, 2002
Andrew R Barron. Universal approximation bounds for superpositions of a sigmoidal function.IEEE Transactions on Information theory, 39(3):930–945, 2002
2002
-
[3]
Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the national academy of sciences, 113(15):3932–3937, 2016
Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the national academy of sciences, 113(15):3932–3937, 2016
2016
-
[4]
Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems, 33:17429–17442, 2020
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems, 33:17429–17442, 2020
2020
-
[5]
Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[6]
On the approximation of functions by tanh neural networks.Neural Networks, 143:732–750, 2021
Tim De Ryck, Samuel Lanthaler, and Siddhartha Mishra. On the approximation of functions by tanh neural networks.Neural Networks, 143:732–750, 2021
2021
-
[7]
Error analysis for physics-informed neural networks (pinns) approximating kolmogorov pdes.Advances in Computational Mathematics, 48(6):79, 2022
Tim De Ryck and Siddhartha Mishra. Error analysis for physics-informed neural networks (pinns) approximating kolmogorov pdes.Advances in Computational Mathematics, 48(6):79, 2022
2022
-
[8]
Generic bounds on the approximation error for physics-informed (and) operator learning.Advances in Neural Information Processing Systems, 35:10945–10958, 2022
Tim De Ryck and Siddhartha Mishra. Generic bounds on the approximation error for physics-informed (and) operator learning.Advances in Neural Information Processing Systems, 35:10945–10958, 2022
2022
-
[9]
On polynomial approximation in sobolev spaces.SIAM journal on numerical analysis, 20(5):985–988, 1983
Ricardo G Durán. On polynomial approximation in sobolev spaces.SIAM journal on numerical analysis, 20(5):985–988, 1983
1983
-
[10]
Sparse identification of nonlinear dynamics and koopman operators with shallow recurrent decoder networks.Proceedings of the National Academy of Sciences, 123(16):e2508144123, 2026
Mars Liyao Gao, Jan P Williams, and J Nathan Kutz. Sparse identification of nonlinear dynamics and koopman operators with shallow recurrent decoder networks.Proceedings of the National Academy of Sciences, 123(16):e2508144123, 2026
2026
-
[11]
Error bounds for approximations with deep relu neural networks in w s, p norms.Analysis and Applications, 18(05):803–859, 2020
Ingo Gühring, Gitta Kutyniok, and Philipp Petersen. Error bounds for approximations with deep relu neural networks in w s, p norms.Analysis and Applications, 18(05):803–859, 2020
2020
-
[12]
Harris, K
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin Shepp...
2020
-
[13]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
1989
-
[14]
On universal approximation and error bounds for fourier neural operators.Journal of Machine Learning Research, 22(290):1–76, 2021
Nikola Kovachki, Samuel Lanthaler, and Siddhartha Mishra. On universal approximation and error bounds for fourier neural operators.Journal of Machine Learning Research, 22(290):1–76, 2021
2021
-
[15]
Neural oscillators are universal.Advances in Neural Information Processing Systems, 36:46786–46806, 2023
Samuel Lanthaler, T Konstantin Rusch, and Siddhartha Mishra. Neural oscillators are universal.Advances in Neural Information Processing Systems, 36:46786–46806, 2023
2023
-
[16]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020
Pith/arXiv arXiv 2010
-
[17]
Neural operator: Graph kernel network for partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations. arXiv preprint arXiv:2003.03485, 2020
Pith/arXiv arXiv 2003
-
[18]
Kan: Kolmogorov-arnold networks.arXiv preprint arXiv:2404.19756, 2024
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks.arXiv preprint arXiv:2404.19756, 2024
Pith/arXiv arXiv 2024
-
[19]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature machine intelligence, 3(3):218–229, 2021
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature machine intelligence, 3(3):218–229, 2021. 10
2021
-
[20]
Extrapolation and learning equations.arXiv preprint arXiv:1610.02995, 2016
Georg Martius and Christoph H Lampert. Extrapolation and learning equations.arXiv preprint arXiv:1610.02995, 2016
Pith/arXiv arXiv 2016
-
[21]
Estimates on the generalization error of physics-informed neural networks for approximating pdes.IMA Journal of Numerical Analysis, 43(1):1–43, 2023
Siddhartha Mishra and Roberto Molinaro. Estimates on the generalization error of physics-informed neural networks for approximating pdes.IMA Journal of Numerical Analysis, 43(1):1–43, 2023
2023
-
[22]
All elementary functions from a single binary operator.arXiv preprint arXiv:2603.21852, 2026
Andrzej Odrzywołek. All elementary functions from a single binary operator.arXiv preprint arXiv:2603.21852, 2026
Pith/arXiv arXiv 2026
-
[23]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[24]
Optimal approximation of piecewise smooth functions using deep relu neural networks.Neural Networks, 108:296–330, 2018
Philipp Petersen and Felix V oigtlaender. Optimal approximation of piecewise smooth functions using deep relu neural networks.Neural Networks, 108:296–330, 2018
2018
-
[25]
Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
Allan Pinkus. Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
1999
-
[26]
Data-driven discovery of partial differential equations.Science advances, 3(4):e1602614, 2017
Samuel H Rudy, Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Data-driven discovery of partial differential equations.Science advances, 3(4):e1602614, 2017
2017
-
[27]
Nonparametric regression using deep neural networks with ReLU activation function.Ann
Johannes Schmidt-Hieber. Nonparametric regression using deep neural networks with ReLU activation function.Ann. Stat., 48(4):1875–1897, August 2020
2020
-
[28]
Ai feynman: A physics-inspired method for symbolic regression
Silviu-Marian Udrescu and Max Tegmark. Ai feynman: A physics-inspired method for symbolic regression. Science advances, 6(16):eaay2631, 2020
2020
-
[29]
A note on polynomial approximation in sobolev spaces.ESAIM: Mathematical Modelling and Numerical Analysis, 33(4):715–719, 1999
Rüdiger Verfürth. A note on polynomial approximation in sobolev spaces.ESAIM: Mathematical Modelling and Numerical Analysis, 33(4):715–719, 1999
1999
-
[30]
On the expressiveness and spectral bias of kans.arXiv preprint arXiv:2410.01803, 2024
Yixuan Wang, Jonathan W Siegel, Ziming Liu, and Thomas Y Hou. On the expressiveness and spectral bias of kans.arXiv preprint arXiv:2410.01803, 2024
arXiv 2024
-
[31]
Common task framework for a critical evaluation of scientific machine learning algorithms.Advances in Neural Information Processing Systems, 38, 2026
Philippe Wyder, Judah Goldfeder, Alexey Yermakov, Yue Zhao, Stefano Riva, Jan Williams, David Zoro, Amy Rude, Matteo Tomasetto, Joe Germany, et al. Common task framework for a critical evaluation of scientific machine learning algorithms.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[32]
Error bounds for approximations with deep relu networks.Neural networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep relu networks.Neural networks, 94:103–114, 2017
2017
-
[33]
The seismic wavefield common task framework.arXiv preprint arXiv:2512.19927, 2025
Alexey Yermakov, Yue Zhao, Marine Denolle, Yiyu Ni, Philippe M Wyder, Judah Goldfeder, Stefano Riva, Jan Williams, David Zoro, Amy Sara Rude, et al. The seismic wavefield common task framework.arXiv preprint arXiv:2512.19927, 2025. 11 A Notation We briefly recall the multi-index notation. Given a d-tuple of non-negative integers α∈Nd 0 with d∈N, we have ∣...
Pith/arXiv arXiv 2025
-
[34]
Lemma 2.Let Ω⊂Rd be an open and bounded set of diameter 0<h<e −1/2d−3/2which is star-shaped with respect to every point in an open ball B⊂Ω with diameter ρh
and [29]. Lemma 2.Let Ω⊂Rd be an open and bounded set of diameter 0<h<e −1/2d−3/2which is star-shaped with respect to every point in an open ball B⊂Ω with diameter ρh. Then, for every f∈W s,∞(Ω), there exists a polynomial ˆfof degree at mosts−1such that for anyk∈N 0 withk<s, it holds that ∥f−ˆf∥W k,∞(Ω) ≤π1/4√s(d √ deh)s−k (s−k−1)! ∣f∣W s,∞(Ω) .(29) We re...
-
[35]
C(d, k, s, f) N s−k , (58) with suitably chosenε. Whereas for1≤k<s, we have ∥˜f N −˜pN∥W k,∞(I N i ) = ⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪ ∑ j∈AN (f−pN j )Φ N j ⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟⎥rro⟪⟪⟩r⟪⌟...
-
[36]
H Proof of Corollary 1 Proof.Letη>0
C(d,0, s, f) N s , (71) where we have chosenεto satisfy ε= δ2 min{1, √ C(d, k, s, f)} N2s+2d+kkk2(k+1)d dmax{1,∥f∥1/2 W k,∞([0,1]d)} .(72) 22 Additionally, for1≤k<s, (72) implies that ε 1 k+1 ≥ δmin{1, √ C(d, k, s, f)} N s+d+1k2d √ dmax{1,∥f∥1/2 W k,∞([0,1]d)} .(73) Therefore, we obtain the bound ∥f−˜pN θ ∥W k,∞((0,1]d) ≤3d(1+δ)(2(k+1)) 3k max{Rk,ln k (βN...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.