CylindTrack: Depth-Aware Cylindrical Motion Modeling for Panoramic Multi-Object Tracking
Pith reviewed 2026-06-30 06:52 UTC · model grok-4.3
The pith
CylindTrack models panoramic tracking by converting horizontal motion to continuous angular states on a cylinder and filtering depth at the trajectory level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
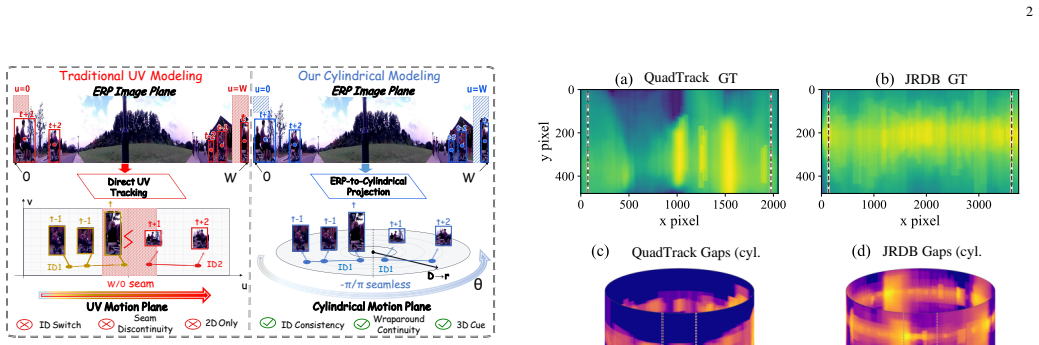
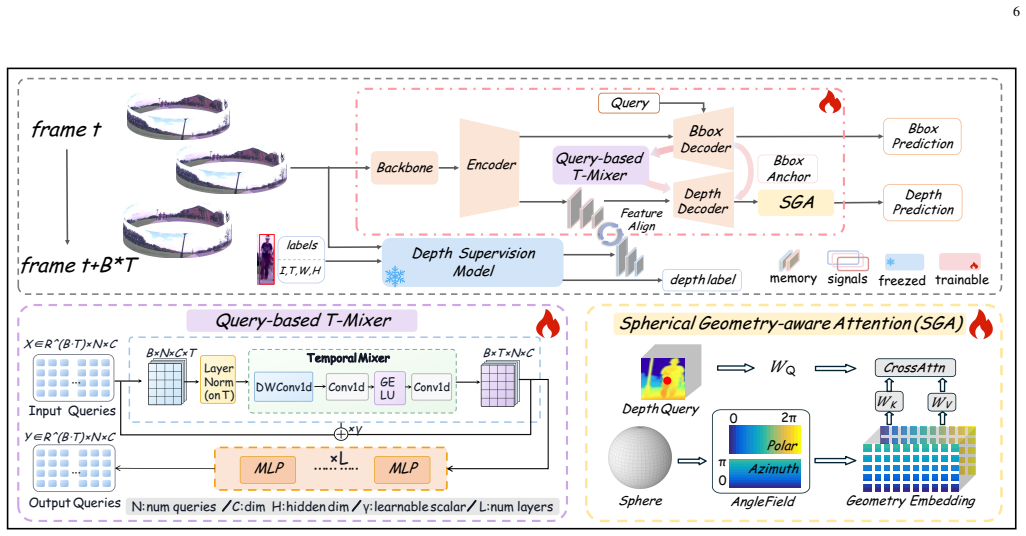
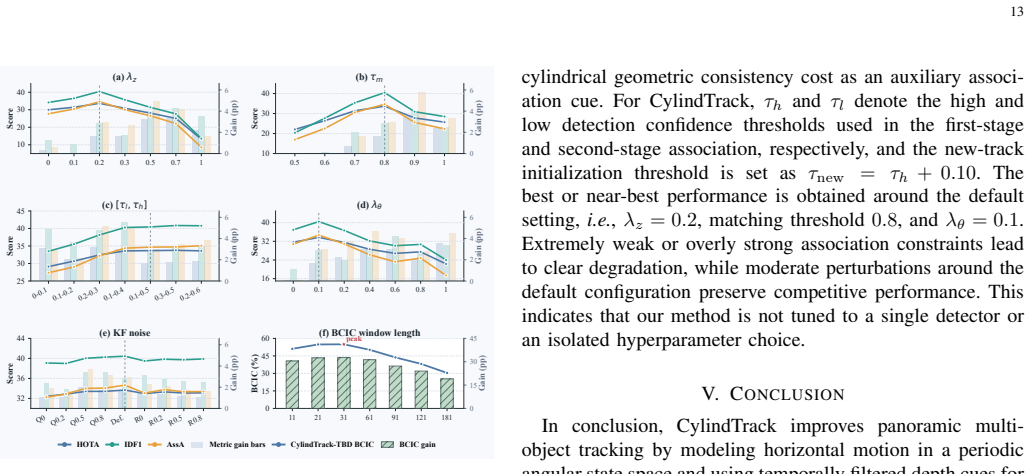
CylindTrack introduces Depth-Temporal Trajectory Modeling to raise frame-wise depth to a filtered trajectory state, Spherical Spatio-Temporal Consistency Learning that uses a Temporal Mixer and Spherical Geometry-aware Attention to enforce coherence, and a Topology-Aware Cylindrical Motion Model that performs seam-consistent prediction in the periodic angular domain. These components together improve identity preservation and trajectory continuity when objects cross the seam or change apparent size.
What carries the argument
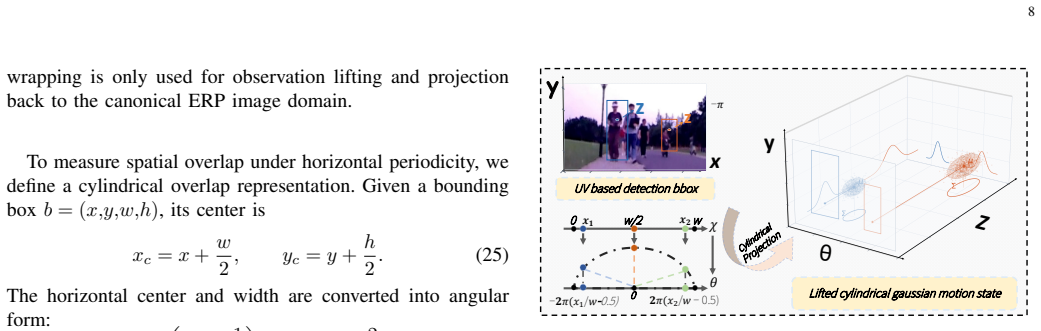
The Topology-Aware Cylindrical Motion Model, which replaces planar Euclidean motion with continuous angular prediction on a cylinder so that association remains consistent across the periodic horizontal boundary.
If this is right
- Association near the seam becomes reliable without special seam-handling rules.
- Depth observations become usable even when they fluctuate strongly between frames.
- Trajectory continuity improves for objects that remain visible for many frames in large-FoV scenes.
- The same depth-temporal pipeline can be applied to any tracker that already produces per-frame depth estimates.
Where Pith is reading between the lines
- The cylindrical representation could be extended to other sensors whose output is periodic, such as certain lidar scan patterns.
- A natural next test would be whether the same motion model reduces drift when panoramic video is used for visual odometry.
- If depth comes from a noisy monocular estimator rather than stereo, the temporal mixer may need retuning to avoid propagating errors.
Load-bearing premise
Frame-wise depth measurements in wide panoramic scenes can be turned into stable trajectory states by temporal mixing and spherical attention without creating new errors.
What would settle it
On a panoramic test sequence containing multiple objects crossing the 0/360 seam, a version of the tracker that removes the cylindrical motion model would produce the same or fewer identity switches than the full model.
Figures



read the original abstract
Multi-Object Tracking (MOT) is a core capability for embodied perception, and panoramic cameras are attractive for embodied systems because their 360{\deg} field of view reduces blind spots and keeps surrounding targets observable for longer durations. However, panoramic MOT is not a straightforward extension of perspective MOT. In equirectangular panoramic videos, the horizontal image domain is periodic rather than Euclidean, which breaks planar motion assumptions and makes IoU-based association unreliable near the 0{\deg}/360{\deg} seam. Meanwhile, large-FoV scenes often contain more objects, stronger scale variation, and more frequent interactions, making online association particularly sensitive to unstable frame-wise depth cues. To address these issues, we propose CylindTrack, a depth-aware cylindrical tracking-by-detection framework for panoramic MOT. CylindTrack first introduces Depth-Temporal Trajectory Modeling (DTM), which promotes instance depth from an isolated frame-wise cue to a temporally filtered trajectory-level state. To improve the reliability of depth observations, we further develop Spherical Spatio-Temporal Consistency Learning (SSTC), which combines a Temporal Mixer and Spherical Geometry-aware Attention to enhance temporal coherence and panoramic geometric alignment in depth-aware representations. Finally, we design a Topology-Aware Cylindrical Motion Model (TCMM) that lifts horizontal motion into a continuous angular state space and performs seam-consistent motion prediction and association in the periodic panoramic domain. By jointly modeling trajectory-level depth consistency and panoramic topology, CylindTrack improves identity preservation and trajectory continuity in challenging panoramic scenes. The source code will be released at https://github.com/warriordby/CylindTrack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CylindTrack, a depth-aware cylindrical tracking-by-detection framework for panoramic multi-object tracking. It identifies challenges in equirectangular panoramic videos including the periodic (non-Euclidean) horizontal domain that breaks planar motion assumptions and makes IoU association unreliable near the seam, plus unstable frame-wise depth cues in large-FoV scenes with many objects and interactions. The framework introduces Depth-Temporal Trajectory Modeling (DTM) to promote instance depth from frame-wise cues to temporally filtered trajectory-level states, Spherical Spatio-Temporal Consistency Learning (SSTC) that combines a Temporal Mixer and Spherical Geometry-aware Attention for temporal coherence and panoramic geometric alignment, and Topology-Aware Cylindrical Motion Model (TCMM) that lifts horizontal motion into a continuous angular state space for seam-consistent prediction and association. The central claim is that jointly modeling trajectory-level depth consistency and panoramic topology improves identity preservation and trajectory continuity; source code release is promised.
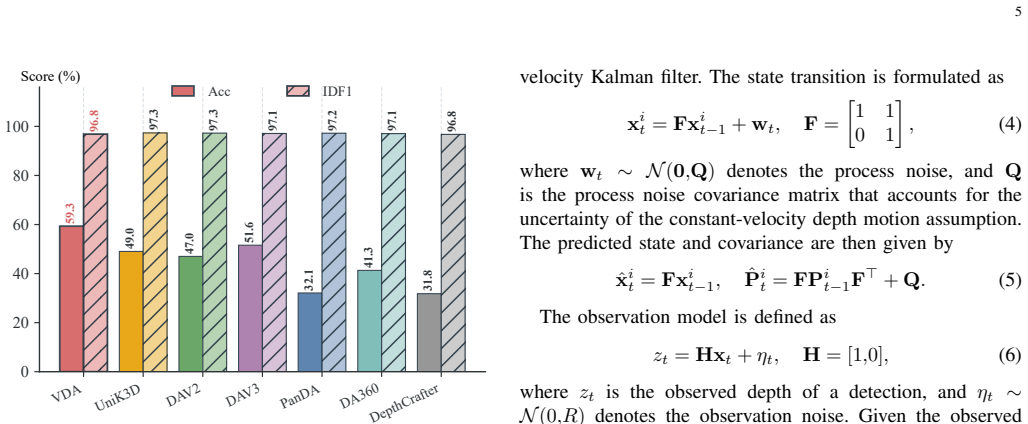
Significance. If validated, the work would address genuine, under-served challenges in panoramic MOT for embodied perception by replacing planar assumptions with cylindrical and spherical geometry. The explicit commitment to release source code is a positive factor for reproducibility. However, the manuscript supplies no quantitative results, ablations, baseline comparisons, or failure-case analysis, so the significance remains prospective rather than demonstrated.
major comments (2)
- [Abstract] Abstract: the central claim that DTM + SSTC + TCMM jointly improve identity preservation and trajectory continuity is unsupported by any experimental results, ablation studies, or quantitative evidence. This is load-bearing because the abstract states the motivation and high-level components but provides no validation that the components deliver the claimed gains.
- [Abstract] Abstract: the assumption that frame-wise depth cues can be reliably promoted to temporally filtered trajectory states via the Temporal Mixer and Spherical Geometry-aware Attention without introducing new instabilities is stated but receives no supporting analysis, stability discussion, or empirical check.
minor comments (1)
- [Abstract] Abstract: the descriptions of DTM, SSTC, and TCMM remain high-level; concrete architectural diagrams, loss formulations, or pseudocode would improve clarity even before experiments are added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for empirical grounding. We agree that the central claims require supporting quantitative evidence, ablations, and stability analysis, which are absent from the current manuscript. We will perform a major revision to incorporate these elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DTM + SSTC + TCMM jointly improve identity preservation and trajectory continuity is unsupported by any experimental results, ablation studies, or quantitative evidence. This is load-bearing because the abstract states the motivation and high-level components but provides no validation that the components deliver the claimed gains.
Authors: We acknowledge that the abstract currently states the intended benefits of the joint modeling without referencing supporting results. This is a valid observation given the manuscript's current content. In revision we will either qualify the abstract wording or add concise references to the quantitative gains once the experimental section is expanded with results, ablations, and baseline comparisons. revision: yes
-
Referee: [Abstract] Abstract: the assumption that frame-wise depth cues can be reliably promoted to temporally filtered trajectory states via the Temporal Mixer and Spherical Geometry-aware Attention without introducing new instabilities is stated but receives no supporting analysis, stability discussion, or empirical check.
Authors: We agree that the manuscript lacks any stability analysis or empirical verification for the depth promotion step. In the revised version we will add a dedicated discussion of stability properties together with targeted ablations or checks demonstrating that the Temporal Mixer and Spherical Geometry-aware Attention do not introduce new instabilities. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context describe a proposed framework (DTM, SSTC, TCMM) for panoramic MOT without any equations, fitted parameters, or self-citations that reduce claimed improvements to inputs by construction. No load-bearing derivation steps are present that match the enumerated circularity patterns. The central claim of joint modeling for better identity preservation is presented as a novel architectural combination rather than a self-referential prediction or renamed known result. This is the most common honest finding for a methods-description paper lacking quantitative derivations in the supplied text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The horizontal image domain in equirectangular panoramic videos is periodic rather than Euclidean, breaking planar motion assumptions and making IoU-based association unreliable near the 0/360 seam.
Reference graph
Works this paper leans on
-
[1]
JRDB: A dataset and benchmark of egocentric robot visual perception of humans in built environments,
R. Martín-Martínet al., “JRDB: A dataset and benchmark of egocentric robot visual perception of humans in built environments,”IEEE Trans- actions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 6748–6765, 2023
2023
-
[2]
Omnidirectional multi-object tracking,
K. Luoet al., “Omnidirectional multi-object tracking,” inProc. CVPR, 2025, pp. 21 959–21 969
2025
-
[3]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” inProc. ICIP, 2016, pp. 3464–3468
2016
-
[4]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” inProc. ICIP, 2017, pp. 3645– 3649
2017
-
[5]
Hybrid-SORT: Weak cues matter for online multi-object tracking,
M. Yanget al., “Hybrid-SORT: Weak cues matter for online multi-object tracking,” inProc. AAAI, 2024, pp. 6504–6512
2024
-
[6]
DiffMOT: A real-time diffusion-based multiple object tracker with non-linear prediction,
W. Lv, Y . Huang, N. Zhang, R.-S. Lin, M. Han, and D. Zeng, “DiffMOT: A real-time diffusion-based multiple object tracker with non-linear prediction,” inProc. CVPR, 2024, pp. 19 321–19 330
2024
-
[7]
BoT-SORT: Robust as- sociations multi-pedestrian tracking,
N. Aharon, R. Orfaig, and B.-Z. Bobrovsky, “BoT-SORT: Robust associations multi-pedestrian tracking,”arXiv:2206.14651, 2022
-
[8]
JRMOT: A real-time 3D multi-object tracker and a new large-scale dataset,
A. Shenoiet al., “JRMOT: A real-time 3D multi-object tracker and a new large-scale dataset,” inProc. IROS, 2020, pp. 10 335–10 342
2020
-
[9]
B. Deng, L. Huang, K. Luo, F. Teng, and K. Yang, “DepTR-MOT: Unveiling the potential of depth-informed trajectory refinement for multi-object tracking,”arXiv:2509.17323, 2025
-
[10]
SparseTrack: Multi- object tracking by performing scene decomposition based on pseudo- depth,
Z. Liu, X. Wang, C. Wang, W. Liu, and X. Bai, “SparseTrack: Multi- object tracking by performing scene decomposition based on pseudo- depth,”IEEE Transactions on Circuits and Systems for Video Technol- ogy, vol. 35, no. 5, pp. 4870–4882, 2025
2025
-
[11]
DepthSort: Multi-object tracking optimization for unreliable detection with depth information,
Z. Cui, T. Xu, Z. Tang, X.-j. Wu, and J. Kittler, “DepthSort: Multi-object tracking optimization for unreliable detection with depth information,” IEEE Signal Processing Letters, 2026. 14
2026
-
[12]
Review on panoramic imaging and its applications in scene understanding,
S. Gao, K. Yang, H. Shi, K. Wang, and J. Bai, “Review on panoramic imaging and its applications in scene understanding,”IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1–34, 2022
2022
-
[13]
PanoFlow: Learning 360° optical flow for surrounding temporal understanding,
H. Shiet al., “PanoFlow: Learning 360° optical flow for surrounding temporal understanding,”IEEE Transactions on Intelligent Transporta- tion Systems, vol. 24, no. 5, pp. 5570–5585, 2023
2023
-
[14]
Towards oriented multi-object tracking for fisheye images: Dataset and framework,
J. Yang, C. Lin, L. Nie, Y . Tang, and Y . Zhao, “Towards oriented multi-object tracking for fisheye images: Dataset and framework,”IEEE Transactions on Circuits and Systems for Video Technology, 2026
2026
-
[15]
Simple online and realtime tracking with spherical panoramic camera,
K.-C. Liu, Y .-T. Shen, and L.-G. Chen, “Simple online and realtime tracking with spherical panoramic camera,” inProc. ICCE, 2018, pp. 1–6
2018
-
[16]
Know your surroundings: Panoramic multi-object tracking by multimodality collaboration,
Y . He, W. Yu, J. Han, X. Wei, X. Hong, and Y . Gong, “Know your surroundings: Panoramic multi-object tracking by multimodality collaboration,” inProc. CVPRW, 2021, pp. 2963–2974
2021
-
[17]
ByteTrack: Multi-object tracking by associating every detection box,
Y . Zhanget al., “ByteTrack: Multi-object tracking by associating every detection box,” inProc. ECCV, 2022, pp. 1–21
2022
-
[18]
Observation- centric SORT: Rethinking SORT for robust multi-object tracking,
J. Cao, J. Pang, X. Weng, R. Khirodkar, and K. Kitani, “Observation- centric SORT: Rethinking SORT for robust multi-object tracking,” in Proc. CVPR, 2023, pp. 9686–9696
2023
-
[19]
Occlusion-aware seamless segmentation,
Y . Caoet al., “Occlusion-aware seamless segmentation,” inProc. ECCV, 2024, pp. 129–147
2024
-
[20]
S3KF: Spherical state-space kalman filtering for panoramic 3D multi-object tracking,
Z. Liuet al., “S3KF: Spherical state-space kalman filtering for panoramic 3D multi-object tracking,”arXiv:2603.27534, 2026
-
[21]
DepthMOT: Depth cues lead to a strong multi-object tracker,
J. Wu and Y . Liu, “DepthMOT: Depth cues lead to a strong multi-object tracker,”arXiv:2404.05518, 2024
-
[22]
PD-SORT: Occlusion- robust multi-object tracking using pseudo-depth cues,
Y . Wang, D. Zhang, R. Li, Z. Zheng, and M. Li, “PD-SORT: Occlusion- robust multi-object tracking using pseudo-depth cues,”IEEE Transac- tions on Consumer Electronics, vol. 71, no. 1, pp. 165–177, 2025
2025
-
[23]
A survey of representation learning, optimization strategies, and applications for omnidirectional vision,
H. Ai, Z. Cao, and L. Wang, “A survey of representation learning, optimization strategies, and applications for omnidirectional vision,” International Journal of Computer Vision, vol. 133, no. 8, pp. 4973– 5012, 2025
2025
-
[24]
X. Linet al., “One flight over the gap: A survey from perspective to panoramic vision,”arXiv:2509.04444, 2025
-
[25]
OmniSAM: Omnidirectional segment anything model for UDA in panoramic semantic segmentation,
D. Zhonget al., “OmniSAM: Omnidirectional segment anything model for UDA in panoramic semantic segmentation,” inProc. ICCV, 2025, pp. 23 892–23 901
2025
-
[26]
Denoise and align: Towards source-free UDA for robust panoramic semantic segmentation,
Y . Chang, Z. Cao, X. Zheng, X. Mi, and Z. Dong, “Denoise and align: Towards source-free UDA for robust panoramic semantic segmentation,” inProc. CVPR, 2026
2026
-
[27]
Panoramic panoptic seg- mentation: Insights into surrounding parsing for mobile agents via unsupervised contrastive learning,
A. Jaus, K. Yang, and R. Stiefelhagen, “Panoramic panoptic seg- mentation: Insights into surrounding parsing for mobile agents via unsupervised contrastive learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 4, pp. 4438–4453, 2023
2023
-
[28]
Waymo open dataset: Panoramic video panoptic segmen- tation,
J. Meiet al., “Waymo open dataset: Panoramic video panoptic segmen- tation,” inProc. ECCV, 2022, pp. 53–72
2022
-
[29]
PanopticNeRF-360: Panoramic 3D-to-2D label transfer in urban scenes,
X. Fuet al., “PanopticNeRF-360: Panoramic 3D-to-2D label transfer in urban scenes,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 10, pp. 8804–8822, 2025
2025
-
[30]
PanDA: Towards panoramic depth anything with un- labeled panoramas and möbius spatial augmentation,
Z. Caoet al., “PanDA: Towards panoramic depth anything with un- labeled panoramas and möbius spatial augmentation,” inProc. CVPR, 2025, pp. 982–992
2025
-
[31]
arXiv preprint arXiv:2512.22819 (2025)
H. Jiang, Z. Song, Z. Lou, R. Xu, and M. Tan, “Depth anything in 360°: Towards scale invariance in the wild,”arXiv:2512.22819, 2025
-
[32]
HybridTrack: A hybrid approach for robust multi-object tracking,
L. Di Bella, Y . Lyu, B. Cornelis, and A. Munteanu, “HybridTrack: A hybrid approach for robust multi-object tracking,”IEEE Robotics and Automation Letters, vol. 10, no. 7, pp. 7238–7245, 2025
2025
-
[33]
Using panoramic videos for multi-person localization and tracking in a 3D panoramic coordinate,
F. Yang, F. Li, Y . Wu, S. Sakti, and S. Nakamura, “Using panoramic videos for multi-person localization and tracking in a 3D panoramic coordinate,” inProc. ICASSP, 2020, pp. 1863–1867
2020
-
[34]
CC-3DT: Panoramic 3D object tracking via cross-camera fusion,
T. Fischer, Y .-H. Yang, S. Kumar, M. Sun, and F. Yu, “CC-3DT: Panoramic 3D object tracking via cross-camera fusion,” inProc. CoRL, 2023, pp. 2294–2305
2023
-
[35]
Robust panoramic multi-object tracking with category- aware data association and adaptive noise estimation for unmanned surface vehicles,
Z. Yanget al., “Robust panoramic multi-object tracking with category- aware data association and adaptive noise estimation for unmanned surface vehicles,”Expert Systems with Applications, p. 132283, 2026
2026
-
[36]
The hungarian method for the assignment problem,
H. W. Kuhn, “The hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97, 1955
1955
-
[37]
Multi-object tracking model based on detection tracking paradigm in panoramic scenes,
J. Shen and H. Yang, “Multi-object tracking model based on detection tracking paradigm in panoramic scenes,”Applied Sciences, vol. 14, no. 10, p. 4146, 2024
2024
-
[38]
Depth-aware multi-object tracking in spherical videos,
L. Lo Presti, G. Mazzola, G. Averna, E. Ardizzone, and M. La Cascia, “Depth-aware multi-object tracking in spherical videos,” inProc. ICIAP, 2022, pp. 362–374
2022
-
[39]
DETrack: Depth information is predictable for tracking,
W. Zhao, Y . Jiang, Y . Gao, J. Li, and X. Gao, “DETrack: Depth information is predictable for tracking,”Neurocomputing, vol. 616, p. 128906, 2025
2025
-
[40]
Depth-aware scoring and hierarchical alignment for multiple object tracking,
M. Khanchi, M. Amer, and C. Poullis, “Depth-aware scoring and hierarchical alignment for multiple object tracking,” inProc. ICIP, 2025, pp. 2043–2048
2025
-
[41]
A depth-aware robust multi-object tracker for crowded scene by re-prioritizing association order,
C.-Y . Yanget al., “A depth-aware robust multi-object tracker for crowded scene by re-prioritizing association order,” inProc. AVSS, 2025, pp. 1–6
2025
-
[42]
Multi-object tracking optimization in densely occluded scenarios using depth estimation,
J. Peng, Y . Yao, P. Wang, C. Wang, and Z. Li, “Multi-object tracking optimization in densely occluded scenarios using depth estimation,” in Proc. FCN, 2025, pp. 1–6
2025
-
[43]
CAMOT: Camera angle-aware multi-object tracking,
F. Limanta, K. Uto, and K. Shinoda, “CAMOT: Camera angle-aware multi-object tracking,” inProc. WACV, 2024, pp. 6465–6474
2024
-
[44]
Depth perspective-aware multiple object tracking,
K. G. Quach, P. Nguyen, C. N. Duong, T. D. Bui, and K. Luu, “Depth perspective-aware multiple object tracking,” inEngineering Applications of AI and Swarm Intelligence, 2024, pp. 181–205
2024
-
[45]
View adaptive multi- object tracking method based on depth relationship cues,
H. Sun, Y . Li, G. Yang, Z. Su, and K. Luo, “View adaptive multi- object tracking method based on depth relationship cues,”Complex & Intelligent Systems, vol. 11, no. 2, p. 145, 2025
2025
-
[46]
X. Hanet al., “GRASPTrack: Geometry-reasoned association via seg- mentation and projection for multi-object tracking,”arXiv:2508.08117, 2025
-
[47]
DepthTrack: Cluster meets BEV for multi-camera multi-target 3D tracking,
T. H.-P. Tranet al., “DepthTrack: Cluster meets BEV for multi-camera multi-target 3D tracking,” inProc. ICCVW, 2025, pp. 5348–5357
2025
-
[48]
Video depth anything: Consistent depth estimation for super-long videos,
S. Chenet al., “Video depth anything: Consistent depth estimation for super-long videos,” inProc. CVPR, 2025, pp. 22 831–22 840
2025
-
[49]
UniK3D: Universal camera monocular 3D estima- tion,
L. Piccinelliet al., “UniK3D: Universal camera monocular 3D estima- tion,” inProc. CVPR, 2025, pp. 1028–1039
2025
-
[50]
Depth anything V2,
L. Yanget al., “Depth anything V2,” inProc. NeurIPS, 2024, pp. 21 875– 21 911
2024
-
[51]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Linet al., “Depth anything 3: Recovering the visual space from any views,”arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
DepthCrafter: Generating consistent long depth sequences for open-world videos,
W. Huet al., “DepthCrafter: Generating consistent long depth sequences for open-world videos,” inProc. CVPR, 2025, pp. 2005–2015
2025
-
[53]
arXiv preprint arXiv:2509.26618 (2025) 16 Y
H. Liet al., “DA 2: Depth anything in any direction,”arXiv:2509.26618, 2025
-
[54]
HOTA: A higher order metric for evaluating multi- object tracking,
J. Luitenet al., “HOTA: A higher order metric for evaluating multi- object tracking,”International Journal of Computer Vision, vol. 129, no. 2, pp. 548–578, 2021
2021
-
[55]
Evaluating multiple object tracking performance: The CLEAR MOT metrics,
K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: The CLEAR MOT metrics,”EURASIP Journal on Image and Video Processing, vol. 2008, no. 1, p. 246309, 2008
2008
-
[56]
Performance measures and a data set for multi-target, multi-camera tracking,
E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” inProc. ECCVW, 2016, pp. 17–35
2016
-
[57]
A consistent metric for performance evaluation of multi-object filters,
D. Schuhmacher, B.-T. V o, and B.-N. V o, “A consistent metric for performance evaluation of multi-object filters,”IEEE Transactions on Signal Processing, vol. 56, no. 8, pp. 3447–3457, 2008
2008
-
[58]
SAM 2: Segment anything in images and videos,
N. Raviet al., “SAM 2: Segment anything in images and videos,” in Proc. ICLR, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.