EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
Pith reviewed 2026-06-27 06:59 UTC · model grok-4.3
The pith
A three-agent framework synthesizes live-web questions into an evolving benchmark that tests search agents on genuine retrieval and reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
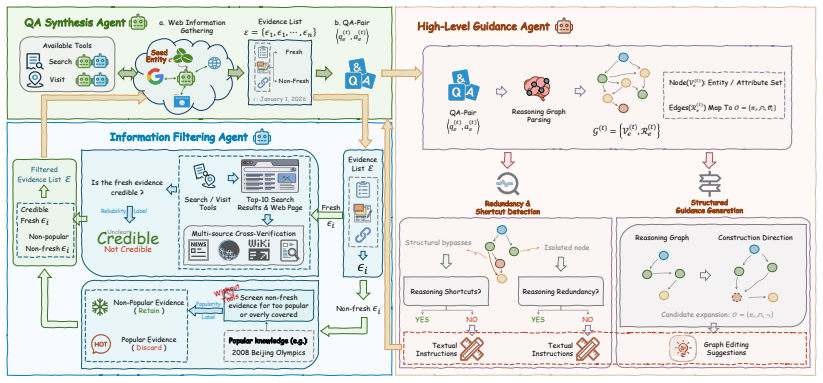
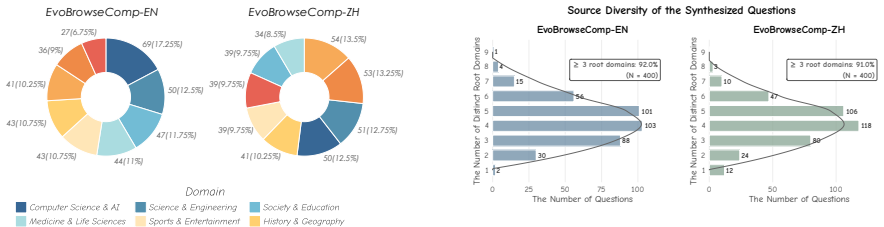
EvoBrowseComp is an evolving benchmark of 400 English and 400 Chinese contamination-free complex questions synthesized via live-web traversal. It is created using a three-agent collaborative framework where a QA synthesis agent retrieves fresh knowledge, an information filtering agent blocks parametric shortcuts by checking credibility and popularity, and a high-level guidance agent formalizes questions into reasoning graphs to reduce logical redundancy. This setup enables regular updates to prevent data contamination and maintain freshness, establishing a scalable paradigm for high-difficulty benchmarking.
What carries the argument
The three-agent collaborative framework (QA synthesis agent, information filtering agent, and high-level guidance agent) that automatically generates questions from live web data while blocking memorization shortcuts.
If this is right
- Search agents must execute broad, multi-source retrieval and multi-step reasoning to reach high scores.
- The benchmark can be regenerated on a regular schedule to remain temporally fresh.
- Performance gaps between models will reflect differences in retrieval and reasoning rather than training-data overlap.
- The automated pipeline provides a repeatable method for producing high-difficulty, reasoning-intensive questions without manual curation.
Where Pith is reading between the lines
- The same synthesis loop could be applied to other languages or specialized domains such as code or scientific literature.
- Repeated updates over months or years would create a longitudinal record of how quickly agent capabilities improve.
- Design choices in the filtering and graph-formalization steps might generalize to auto-generation of other evaluation tasks that resist memorization.
- Agents optimized against this benchmark may develop search strategies that transfer better to real-world, time-sensitive queries.
Load-bearing premise
The three-agent collaborative framework successfully produces questions that are free of parametric shortcuts and genuinely require broad horizontal search and reasoning.
What would settle it
A model achieving high accuracy on the benchmark questions using only its internal parameters and no search tool calls, or answering correctly from knowledge available before the question synthesis date.
Figures


read the original abstract
Search Agents -- large language models augmented with search tools -- have intensified the need for future-proof evaluation benchmarks. Existing benchmarks such as BrowseComp rely on static knowledge, making them vulnerable to test-set contamination and parametric memorization. Consequently, models can achieve high scores through fact recall rather than genuine retrieval, obscuring true browsing competence via reasoning shortcuts. In this paper, we introduce EvoBrowseComp, an evolving benchmark of 400 English and 400 Chinese contamination-free complex questions synthesized via live-web traversal. To collect these questions, we design a three-agent collaborative framework: (1) a QA synthesis agent that retrieves fresh knowledge from the live web to synthesize QA pairs; (2) an information filtering agent that filters retrieved knowledge in terms of credibility and popularity to block parametric shortcuts; and (3) a high-level guidance agent that formalizes questions into reasoning graphs to reduce logical redundancy and shortcuts in synthesized QA pairs. Because the framework supports fully automated synthesis, EvoBrowseComp can be regularly updated to prevent data contamination and maintain temporal freshness. Extensive experiments confirm its great difficulty, requiring broad horizontal search. It establishes a scalable paradigm for auto-updatable, high-difficulty benchmarking that keeps pace with both evolving world knowledge and advancing agent capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoBrowseComp, a benchmark consisting of 400 English and 400 Chinese complex questions synthesized from live-web traversal. It employs a three-agent collaborative framework: a QA synthesis agent to generate pairs from fresh web knowledge, an information filtering agent that applies credibility and popularity criteria to block parametric shortcuts, and a high-level guidance agent that constructs reasoning graphs to minimize logical redundancy. The automated synthesis enables regular updates to maintain temporal freshness and avoid contamination. Experiments are reported to confirm that the benchmark requires broad horizontal search rather than fact recall.
Significance. If the synthesis pipeline reliably produces questions free of parametric shortcuts, this work would establish a scalable, auto-updatable paradigm for benchmarking search agents that remains relevant as world knowledge evolves and model capabilities advance. The fully automated nature of the framework is a clear strength for reproducibility and ongoing maintenance, directly addressing contamination vulnerabilities in static benchmarks such as BrowseComp.
major comments (1)
- [§3] §3 (information filtering agent): The claim that filtering on popularity blocks parametric shortcuts lacks an orthogonal mechanism; popularity is a direct proxy for frequency in web corpora and LLM training data, and the manuscript provides no validation (e.g., shortcut ablation, recency-only filtering, or empirical test of memorization resistance) to show the filter decouples from memorization risk.
minor comments (2)
- The abstract states that 'extensive experiments confirm its great difficulty' but does not include specific quantitative metrics, baseline comparisons, or error analysis in the high-level description.
- Consider including one or two example synthesized questions (with reasoning graphs) in the main text or appendix to illustrate the output of the three-agent process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond to the single major comment.
read point-by-point responses
-
Referee: [§3] §3 (information filtering agent): The claim that filtering on popularity blocks parametric shortcuts lacks an orthogonal mechanism; popularity is a direct proxy for frequency in web corpora and LLM training data, and the manuscript provides no validation (e.g., shortcut ablation, recency-only filtering, or empirical test of memorization resistance) to show the filter decouples from memorization risk.
Authors: We agree that the manuscript currently lacks explicit validation (such as an ablation study or memorization-resistance test) demonstrating that the popularity criterion provides an orthogonal safeguard against parametric shortcuts. The filter is applied jointly with credibility scoring on live-web content to favor less frequently encountered yet verifiable facts; the automated synthesis from recent pages is intended to further reduce overlap with training data. Nevertheless, no dedicated empirical check is reported. In revision we will add to §3 a controlled comparison of question sets generated with and without the popularity filter, together with a small-scale test measuring model shortcut rates on the resulting items. revision: yes
Circularity Check
No circularity; benchmark synthesis is independent construction
full rationale
The paper describes an independent three-agent synthesis pipeline for generating contamination-free questions via live-web traversal, credibility/popularity filtering, and reasoning-graph formalization. No equations, fitted parameters, self-citations, or derivations are present that reduce any claimed result to its inputs by construction. The central claim of producing questions requiring broad search is presented as an empirical outcome of the described process rather than a tautology or renamed prior result. This is the normal case of a self-contained benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer
Deepsearchqa: Bridging the comprehensive- ness gap for deep research agents.arXiv preprint arXiv:2601.20975. Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehen- sion. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistic...
arXiv 2017
-
[2]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McK- inney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025. Browsecomp: A simple yet challeng- ing benchmark for browsing agents.arXiv preprint arXiv:2504.12516. Jialong Wu, Wenbiao Yin,...
Pith/arXiv arXiv 2025
-
[3]
Freshness: Each entity must have either newly emerged in 2026 or undergone a significant at- tribute change in 2026 (e.g., newly founded organi- zations, newly released products, newly appointed individuals, newly occurred events)
2026
-
[4]
Avoid personal blogs, self-media, and content farms
Source reliability: Each entity must be reported by authoritative news sources (e.g., Reuters, BBC, Xinhua) or official websites (e.g., .gov sites, offi- cial homepages, reputable encyclopedias). Avoid personal blogs, self-media, and content farms
-
[5]
Diversity: Cover a broad range of entity types, including people, organizations, events, products, concepts, and locations
-
[6]
domain": {
Multi-round search: Issue multiple search() calls with diversified queries to comprehensively cover the different facets of the sub-domain. Output Format { "domain": { "primary": "<primary domain>", "secondary": "<sub-domain>"}, "total_count": {num_seeds}, "seeds": [ {"id": 1, "entity_name": "<entity name>", "is_fresh": true} ] } Now begin: first plan you...
2026
-
[7]
Iterative exploration: Starting from the seed, itera- tively invoke search/visit, following hyperlinks to expand the entity network
-
[8]
2026”, “latest
Prioritize fresh knowledge: Augment queries with time-aware keywords such as “2026”, “latest”, or “current”
2026
-
[9]
Mandatory verification: Every piece of evidence must come from a page you have actually visited; do not record evidence based on search snippets alone
-
[10]
evidence_id
Chainability: Evidence items should share entities with one another so that they can later be linked into evidence chains. Output Format [ { "evidence_id": "e_001", "head_entity": "Entity A", "relation": "relation or ,→attribute description", "tail_entity": "Entity B or ,→attribute value", "evidence_text": "verbatim ,→snippet from the source page", "sourc...
-
[11]
•The final hop must be fresh knowledge
Reasoning Chain • At least 5 hops, with each hop introducing a fresh entity or relation (no looping in place). •The final hop must be fresh knowledge. (is_fresh_knowledge = true)
-
[12]
• The intersection, difference, or ranking result de- rived from multiple entities along the chain
Answer The answer must fall into one of the following types to ensure uniqueness and evaluability: • Deterministic attributes (time, number, or proper nouns with unique referents). • The intersection, difference, or ranking result de- rived from multiple entities along the chain
-
[13]
• Non-fresh knowledge: use descriptions whose indi- vidual words are common but whose combination points to a rare attribute
Obfuscation (Core) Goal: prevent the model from identifying entities via memorization or a single search; the full reasoning chain must be traversed. • Non-fresh knowledge: use descriptions whose indi- vidual words are common but whose combination points to a rare attribute. • Fresh knowledge: anchor the description on a non- core but retrievable attribut...
-
[14]
id": "qa_001
Anti-Shortcut The final interrogative clause must be tightly bound to the last unresolved entity in the reasoning chain, and must not pivot to a public event or globally known attribute. Output Format [ { "id": "qa_001", "question": "obfuscated question ,→", "answer": "final answer", "hop_count": 5, "knowledge_order": "nonfresh- ,→nonfresh-fresh-fresh-fre...
-
[15]
For each evidence item, extract the key fact represented by the triple (head_entity, relation, tail_entity)
-
[16]
The provided source_url may be visited as one reference, butmust notbe counted as an independent corrob- oration
Issue search queries to retrieve relevant results, and visit authoritative sources (official web- sites, mainstream media, reputable encyclopedias) when further confirmation is needed. The provided source_url may be visited as one reference, butmust notbe counted as an independent corrob- oration
-
[17]
Cross-validation: for each triple, find at least two independent sources that corroborate it
-
[18]
reliability
Assign an overall reliability label for the entire evidence list: •credible : every triple is consistently sup- ported by multiple independent and trustwor- thy sources. •not credible : at least one triple is con- tradicted by sources, or supported only by untrustworthy sources. •unclear : available information is insuffi- cient to make a definitive judgm...
-
[19]
Faithful to the literal semantics of the question: the reasoning_chain serves only as a refer- ence for entity and relation names; do not use it to forcibly connect subgraphs that have no logical dependency in the question itself
-
[20]
background filler,
Local connectivity: even when an isolated sub- graph functions as mere “background filler,” its internal edges must still be built according to the literal logic expressed in the question. Node Fields •node_id: starts fromn0. •label: semantic description of the node. •known_entities : entities explicitly given in the question; otherwisenull. •reference_en...
-
[21]
Completeness • Both question and answer are non-empty, non- whitespace, and free of truncation or garbled text
-
[22]
• Sentence structure is clear, avoiding excessive nested modifiers
Question Language Quality • Fluent and natural, consistent with how a human would naturally ask, with no grammatical errors or signs of machine-generated patchwork. • Sentence structure is clear, avoiding excessive nested modifiers. • Semantically unique and unambiguous, with no unclear references, vague scope, or multiple valid interpretations. • Forms a...
-
[23]
thinking
Answer Quality • Concise and definite, easy to evaluate automati- cally (e.g., a specific entity, number, or date). • Semantically unique, with no equally valid alter- native answers. • Free of ambiguous expressions or vague qualifiers. Output Format Output only the following JSON, with no additional text or code-block markers: { "thinking": "brief reason...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.