How Ethos and Pathos Appeals Resonate in Reader Interpretations of Social Media Messages
Pith reviewed 2026-07-02 13:14 UTC · model grok-4.3
The pith
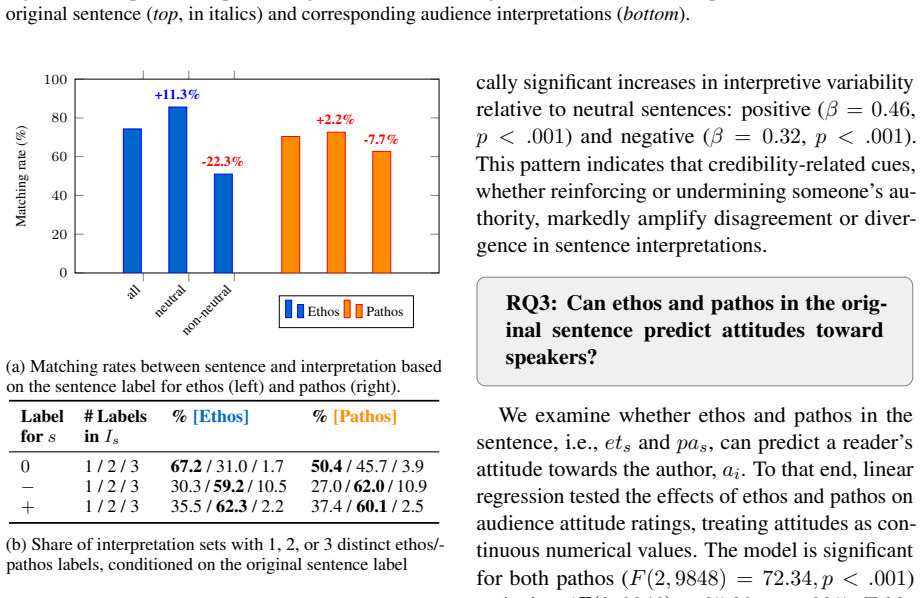
Interpretations of social media messages diverge from the originals in 30% of cases when ethos or pathos is used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
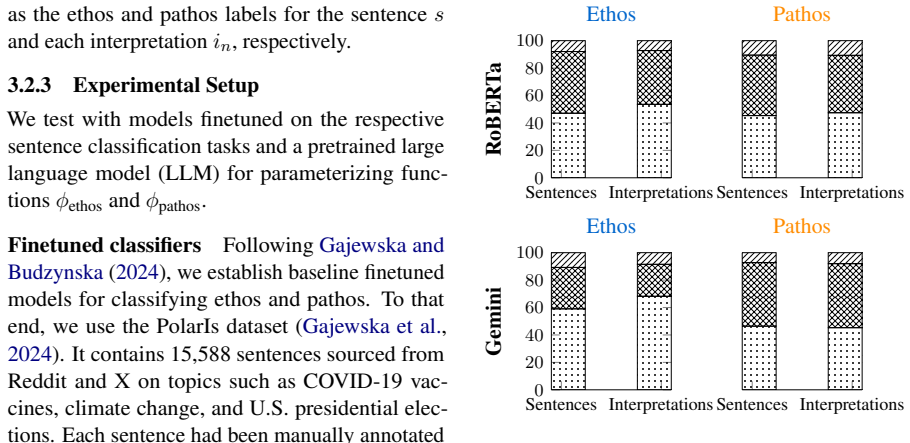
Using a dataset of social media sentences paired with human-written interpretations, the study labels both for ethos and pathos. It shows that interpretations diverge from the original sentences in 30% of cases, with rhetorically charged content eliciting greater variability than neutral content. Ethos and pathos in original sentences can predict audience attitudes toward the author.
What carries the argument
Dataset of social media sentences paired with human-written interpretations labeled for ethos and pathos to assess preservation and predictive power.
If this is right
- Rhetorically charged content elicits greater variability in interpretations than neutral content.
- Ethos and pathos in original sentences predict audience attitudes toward the author.
- Interpretations diverge in 30% of cases overall.
- Rhetoric shapes perception beyond visible engagement.
Where Pith is reading between the lines
- Studies focused only on comments may miss the majority of rhetorical effects on silent readers.
- The predictive power of ethos and pathos could be tested in controlled experiments with non-writing readers.
- Divergence in interpretations might influence how messages spread or are remembered without feedback.
- Similar analysis could be applied to other platforms or languages to check consistency.
Load-bearing premise
The dataset of social media sentences paired with human-written interpretations serves as a valid proxy for the interpretations of the silent universal audience.
What would settle it
A study collecting interpretations from silent readers who do not write comments, showing significantly lower divergence rates or no predictive power from ethos and pathos, would challenge the findings.
Figures

read the original abstract
Rhetorical strategies and their influence on audiences are often studied through social media posts and comments. However, this focus overlooks the universal audience, which is the majority of readers who remain silent and do not explicitly express how a message affects them. This study investigates how two classical modes of persuasion, ethos and pathos, resonate in the silent audience's interpretations of meaning. Using a dataset of social media sentences paired with human-written interpretations, we label both sources for ethos and pathos and assess whether these rhetorical appeals are preserved. Our analyses show that interpretations diverge from the original sentences in 30% of cases, with rhetorically charged content eliciting greater variability than neutral content. We further find that ethos and pathos in original sentences can predict audience attitudes toward the author, underscoring the subtle ways rhetoric shapes perception beyond visible engagement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a dataset of social media sentences paired with voluntary human-written interpretations can serve as a proxy for the silent universal audience. By labeling both originals and interpretations for ethos and pathos, the authors report that reader interpretations diverge from the source sentences in 30% of cases, with rhetorically charged content showing greater variability; they further claim that ethos and pathos in the originals predict audience attitudes toward the author.
Significance. If the proxy assumption and labeling procedures hold, the work would usefully extend rhetorical analysis beyond visible comments to implicit interpretations, providing concrete percentages and a predictive link that could inform studies of persuasion on social media. The empirical framing with divergence statistics is a positive step, though the absence of reliability metrics and representativeness checks limits immediate impact.
major comments (2)
- [Abstract] Abstract and dataset description: the central claim that voluntary human-written interpretations validly proxy the silent universal audience is unsupported; no demographic comparison, non-response analysis, or behavioral validation is described to establish equivalence between self-selected interpreters and non-responders, directly undermining both the 30% divergence statistic and the predictive relation to audience attitudes.
- [Abstract] Labeling and analysis procedure: the abstract reports concrete percentages and predictive relations without any mention of inter-annotator agreement, labeling reliability, statistical controls, or baseline comparisons; these omissions make it impossible to assess whether the reported divergence and predictive findings exceed chance or annotation noise.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the proxy assumption and labeling procedures. We respond point by point below, proposing targeted revisions where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract and dataset description: the central claim that voluntary human-written interpretations validly proxy the silent universal audience is unsupported; no demographic comparison, non-response analysis, or behavioral validation is described to establish equivalence between self-selected interpreters and non-responders, directly undermining both the 30% divergence statistic and the predictive relation to audience attitudes.
Authors: We agree the manuscript provides no demographic comparisons, non-response analysis, or behavioral validation, as the dataset consists solely of voluntary interpretations without accompanying metadata on participant characteristics or response rates. This prevents direct equivalence claims. The proxy is presented as a methodological approach to access implicit interpretations rather than a validated substitute for all silent readers. We will revise the abstract to qualify the central claim and add an explicit limitations subsection discussing self-selection effects and their implications for the reported 30% divergence and predictive results. revision: yes
-
Referee: [Abstract] Labeling and analysis procedure: the abstract reports concrete percentages and predictive relations without any mention of inter-annotator agreement, labeling reliability, statistical controls, or baseline comparisons; these omissions make it impossible to assess whether the reported divergence and predictive findings exceed chance or annotation noise.
Authors: The abstract omits these details, though the full methods section describes multi-annotator labeling. We will revise the abstract to reference inter-annotator agreement metrics, any statistical controls applied, and baseline comparisons demonstrating results exceed chance levels. This addition will allow evaluation of the findings relative to potential annotation variability. revision: yes
- Lack of demographic comparison, non-response analysis, or behavioral validation data for the voluntary interpreters, preventing empirical establishment of equivalence to the silent audience.
Circularity Check
No circularity: empirical annotation study with independent data analysis
full rationale
The paper conducts an empirical annotation and statistical analysis task on a collected dataset of social media sentences paired with human-written interpretations. It labels sources for ethos and pathos, computes divergence rates (e.g., 30%), and examines predictive links to audience attitudes. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the derivation chain. The central claims rest on direct measurement of the provided data rather than any reduction to inputs by construction. The proxy assumption for the silent audience is a methodological limitation, not a circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-written interpretations of social media sentences can be reliably and consistently labeled for ethos and pathos by annotators.
Reference graph
Works this paper leans on
-
[1]
Liesbeth Allein and Marie-Francine Moens. 2024. https://aclanthology.org/2024.nlperspectives-1.13/ O rigam IM : A dataset of ambiguous sentence interpretations for social grounding and implicit language understanding . In Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024, pages 116--122, Torino, Italia....
2024
-
[2]
Liesbeth Allein, Maria Mihaela Tru s cǎ, and Marie-Francine Moens. 2025. https://doi.org/10.1016/j.artint.2024.104234 Interpretation modeling: Social grounding of sentences by reasoning over their implicit moral judgments . Artificial Intelligence, 338:104234
-
[3]
Aristotle. 1991. The Art of Rhetoric. Penguin Books, London, U.K
1991
-
[5]
J \"u rgen Buder, Lisa Rabl, Markus Feiks, Mandy Badermann, and Guido Zurstiege. 2021. https://doi.org/10.1016/j.chb.2020.106663 Does negatively toned language use on social media lead to attitude polarization? Computers in Human Behavior, 116:106663
-
[6]
Federico Cabitza, Andrea Campagner, and Valerio Basile. 2023. https://doi.org/10.1609/aaai.v37i6.25840 Toward a perspectivist turn in ground truthing for predictive computing . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 6860--6868
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. https://doi.org/10.48550/arXiv.2507.06261 Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities . arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[10]
Aida Davani, Mark D \' az, Dylan Baker, and Vinodkumar Prabhakaran. 2024. https://dl.acm.org/doi/10.1145/3630106.3659021 Disentangling perceptions of offensiveness: Cultural and moral correlates . In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2007--2021
-
[11]
Michela Del Vicario, Gianna Vivaldo, Alessandro Bessi, Fabiana Zollo, Antonio Scala, Guido Caldarelli, and Walter Quattrociocchi. 2016. https://www.nature.com/articles/srep37825 Echo chambers: Emotional contagion and group polarization on facebook . Scientific reports, 6(1):37825
2016
-
[12]
Rory Duthie, Katarzyna Budzynska, and Chris Reed. 2016. https://ebooks.iospress.nl/volumearticle/45269 Mining ethos in political debate . Computational Models of Argument, pages 299--310
2016
-
[13]
Alice H Eagly. 2014. https://www.taylorfrancis.com/chapters/mono/10.4324/9781315803012-10/recipient-characteristics-determinants-responses-persuasion-alice-eagly?context=ubx&refId=e9c81a8a-c436-45d9-bb33-c0d7e73b9c1d Recipient characteristics as determinants of responses to persuasion . In Cognitive responses in persuasion, pages 173--195. Psychology Press
work page doi:10.4324/9781315803012-10/recipient-characteristics-determinants-responses-persuasion-alice-eagly 2014
-
[14]
Natalia Evgrafova, Veronique Hoste, and Els Lefever. 2024. https://aclanthology.org/2024.politicalnlp-1.5/ Analysing pathos in user-generated argumentative text . In Proceedings of the Second Workshop on Natural Language Processing for Political Sciences @ LREC-COLING 2024, pages 39--44, Torino, Italia. ELRA and ICCL
2024
-
[15]
Eve Fleisig, Su Lin Blodgett, Dan Klein, and Zeerak Talat. 2024. https://doi.org/10.18653/v1/2024.naacl-long.126 The perspectivist paradigm shift: Assumptions and challenges of capturing human labels . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
-
[16]
Simona Frenda, Gavin Abercrombie, Valerio Basile, Alessandro Pedrani, Raffaella Panizzon, Alessandra Teresa Cignarella, Cristina Marco, and Davide Bernardi. 2025. https://doi.org/10.1007/s10579-024-09766-4 Perspectivist approaches to natural language processing: a survey . Language Resources and Evaluation, 59(2):1719--1746
-
[17]
Ewelina Gajewska and Katarzyna Budzynska. 2024. Digital polarisation: Analysis of ‘us’ versus ‘them’ rhetoric in public discussions on social media. In Progress in Polish Artificial Intelligence Research 5. Proceedings of the 5th Polish Conference on Artificial Intelligence (PP-RAI’2024), Warsaw, Poland. Warsaw University of Technology. Conference held Ap...
2024
-
[19]
Kiran Garimella, Gianmarco De Francisci Morales, Aristides Gionis, and Michael Mathioudakis. 2018. https://dl.acm.org/doi/fullHtml/10.1145/3178876.3186139 Political discourse on social media: Echo chambers, gatekeepers, and the price of bipartisanship . In Proceedings of the 2018 world wide web conference, pages 913--922
-
[21]
Pierpaolo Goffredo, Shohreh Haddadan, Vorakit Vorakitphan, Elena Cabrio, and Serena Villata. 2022. https://www.ijcai.org/proceedings/2022/575 Fallacious argument classification in political debates . In Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), pages 4143--4149. International Joint Conferences on Artificial Intelli...
2022
-
[22]
Nitesh Goyal, Ian D Kivlichan, Rachel Rosen, and Lucy Vasserman. 2022. https://dl.acm.org/doi/10.1145/3555088 Is your toxicity my toxicity? exploring the impact of rater identity on toxicity annotation . Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1--28
-
[27]
Elena Musi, Myrto Aloumpi, Elinor Carmi, Simeon Yates, and Kay O'Halloran. 2022. https://www.ojcmt.net/article/developing-fake-news-immunity-fallacies-as-misinformation-triggers-during-the-pandemic-12083 Developing fake news immunity: fallacies as misinformation triggers during the pandemic . Online Journal of Communication and Media Technologies, 12(3)
2022
-
[28]
Ellie Pavlick and Tom Kwiatkowski. 2019. https://transacl.org/index.php/tacl/article/view/1780 Inherent disagreements in human textual inferences . Transactions of the Association for Computational Linguistics, 7:677--694
2019
-
[29]
Chaïm Perelman and Lucie Olbrechts-Tyteca. 1971. Trait \'e de l'argumentation. la nouvelle rh \'e torique. In Collection de sociologie générale et de philosophie sociale. Éditions de l'Institut de Sociologie de Bruxelles, 2e éd, volume 76. Revue de Métaphysique et de Morale
1971
-
[30]
Barbara Plank. 2022. https://aclanthology.org/2022.emnlp-main.731/ The “problem” of human label variation: On ground truth in data, modeling and evaluation . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10671--10682
2022
-
[32]
Alan Ramponi, Agnese Daffara, and Sara Tonelli. 2025 b . https://aclanthology.org/2025.naacl-long.34/ Fine-grained fallacy detection with human label variation . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 762--784
2025
-
[35]
Taylor Sorensen, Liwei Jiang, Jena D Hwang, Sydney Levine, Valentina Pyatkin, Peter West, Nouha Dziri, Ximing Lu, Kavel Rao, Chandra Bhagavatula, and 1 others. 2024. https://dl.acm.org/doi/10.1609/aaai.v38i18.29970 Value kaleidoscope: Engaging ai with pluralistic human values, rights, and duties . In Proceedings of the AAAI Conference on Artificial Intell...
-
[38]
Douglas Walton. 2010. https://doi.org/10.22329/il.v30i2.2868 Why fallacies appear to be better arguments than they are . Informal logic, 30(2):159--184
-
[41]
Artificial Intelligence , volume=
Interpretation modeling: Social grounding of sentences by reasoning over their implicit moral judgments , author=. Artificial Intelligence , volume=. 2025 , publisher=
2025
-
[42]
Argumentation , volume=
From theory of rhetoric to the practice of language use: The case of appeals to ethos elements , author=. Argumentation , volume=. 2022 , publisher=
2022
-
[43]
Computers in Human Behavior , volume=
Does Negatively Toned Language Use on Social Media Lead to Attitude Polarization? , author=. Computers in Human Behavior , volume=. 2021 , publisher=
2021
-
[44]
Proceedings of the 2018 world wide web conference , pages=
Political discourse on social media: Echo chambers, gatekeepers, and the price of bipartisanship , author=. Proceedings of the 2018 world wide web conference , pages=. 2018 , url=
2018
-
[45]
Scientific reports , volume=
Echo chambers: Emotional contagion and group polarization on facebook , author=. Scientific reports , volume=. 2016 , url=
2016
-
[46]
Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024 , month = may, year =
Allein, Liesbeth and Moens, Marie-Francine , editor =. Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024 , month = may, year =
2024
-
[47]
Mimicking How Humans Interpret Out-of-Context Sentences Through Controlled Toxicity Decoding
Trusca, Maria Mihaela and Allein, Liesbeth. Mimicking How Humans Interpret Out-of-Context Sentences Through Controlled Toxicity Decoding. Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025). 2025. doi:10.18653/v1/2025.trustnlp-main.19
-
[48]
Proceedings of the 1st workshop on perspectivist approaches to NLP@ LREC2022 , pages=
Variation in the expression and annotation of emotions: A wizard of oz pilot study , author=. Proceedings of the 1st workshop on perspectivist approaches to NLP@ LREC2022 , pages=
-
[49]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Hate Personified: Investigating the role of LLMs in content moderation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[50]
Analysing Pathos in User-Generated Argumentative Text
Evgrafova, Natalia and Hoste, Veronique and Lefever, Els. Analysing Pathos in User-Generated Argumentative Text. Proceedings of the Second Workshop on Natural Language Processing for Political Sciences @ LREC-COLING 2024. 2024
2024
-
[51]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[52]
, author=
The group polarization phenomenon. , author=. Psychological bulletin , volume=. 1976 , publisher=
1976
-
[53]
, author=
Group polarization: A critical review and meta-analysis. , author=. Journal of personality and social psychology , volume=. 1986 , publisher=
1986
-
[54]
Language Resources and Evaluation , volume=
Perspectivist approaches to natural language processing: a survey , author=. Language Resources and Evaluation , volume=. 2025 , publisher=
2025
-
[55]
The Art of Rhetoric , year =
Aristotle , editor =. The Art of Rhetoric , year =
-
[56]
Progress in Polish Artificial Intelligence Research 5
Gajewska, Ewelina and Budzynska, Katarzyna , title =. Progress in Polish Artificial Intelligence Research 5. Proceedings of the 5th Polish Conference on Artificial Intelligence (PP-RAI’2024) , editor =. 2024 , address =
2024
-
[57]
arXiv preprint arXiv:2404.04889 , year=
Ethos and pathos in online group discussions: Corpora for polarisation issues in social media , author=. arXiv preprint arXiv:2404.04889 , year=
-
[58]
Computational Models of Argument , year =
Duthie, Rory and Budzynska, Katarzyna and Reed, Chris , title =. Computational Models of Argument , year =
-
[59]
Bagdon, Christopher and Combs, Aidan and Silberer, Carina and Klinger, Roman. Donate or Create? Comparing Data Collection Strategies for Emotion-labeled Multimodal Social Media Posts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.847
-
[60]
Exploring the Potential of Large Language Models in Computational Argumentation
Chen, Guizhen and Cheng, Liying and Luu, Anh Tuan and Bing, Lidong. Exploring the Potential of Large Language Models in Computational Argumentation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.126
-
[61]
Why Don ' t You Do It Right? Analysing Annotators' Disagreement in Subjective Tasks
Sandri, Marta and Leonardelli, Elisa and Tonelli, Sara and Jezek, Elisabetta. Why Don ' t You Do It Right? Analysing Annotators' Disagreement in Subjective Tasks. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.178
-
[62]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Disentangling perceptions of offensiveness: Cultural and moral correlates , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=. 2024 , url=
2024
-
[63]
A Match Made in Heaven: A Multi-task Framework for Hyperbole and Metaphor Detection
Badathala, Naveen and Rajakumar Kalarani, Abisek and Siledar, Tejpalsingh and Bhattacharyya, Pushpak. A Match Made in Heaven: A Multi-task Framework for Hyperbole and Metaphor Detection. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.26
-
[64]
Euphemistic Abuse -- A New Dataset and Classification Experiments for Implicitly Abusive Language
Wiegand, Michael and Kampfmeier, Jana and Eder, Elisabeth and Ruppenhofer, Josef. Euphemistic Abuse -- A New Dataset and Classification Experiments for Implicitly Abusive Language. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.1012
-
[65]
ANALOGICAL - A Novel Benchmark for Long Text Analogy Evaluation in Large Language Models
Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Gajera, Bimal and Gowaikar, Shreeyash and Gupta, Chandan and Chadha, Aman and Reganti, Aishwarya Naresh and Sheth, Amit and Das, Amitava. ANALOGICAL - A Novel Benchmark for Long Text Analogy Evaluation in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2023. 2023...
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Toward a Perspectivist Turn in Ground Truthing for Predictive Computing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2023 , doi=
2023
-
[67]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
The “Problem” of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=. 2022 , url=
2022
-
[68]
Proceedings of the ACM on Human-Computer Interaction , volume=
Is your toxicity my toxicity? exploring the impact of rater identity on toxicity annotation , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2022 , publisher=
2022
-
[69]
V ari E rr NLI : Separating Annotation Error from Human Label Variation
Weber-Genzel, Leon and Peng, Siyao and De Marneffe, Marie-Catherine and Plank, Barbara. V ari E rr NLI : Separating Annotation Error from Human Label Variation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.123
-
[70]
Transactions of the Association for Computational Linguistics , volume=
Inherent disagreements in human textual inferences , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Value kaleidoscope: Engaging ai with pluralistic human values, rights, and duties , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , url=
2024
-
[72]
Can Large Language Models Capture Dissenting Human Voices?
Lee, Noah and An, Na Min and Thorne, James. Can Large Language Models Capture Dissenting Human Voices?. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.278
-
[73]
Before Name-Calling: Dynamics and Triggers of Ad Hominem Fallacies in Web Argumentation
Habernal, Ivan and Wachsmuth, Henning and Gurevych, Iryna and Stein, Benno. Before Name-Calling: Dynamics and Triggers of Ad Hominem Fallacies in Web Argumentation. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1036
-
[74]
Jin, Zhijing and Lalwani, Abhinav and Vaidhya, Tejas and Shen, Xiaoyu and Ding, Yiwen and Lyu, Zhiheng and Sachan, Mrinmaya and Mihalcea, Rada and Schoelkopf, Bernhard. Logical Fallacy Detection. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.532
-
[75]
Online Journal of Communication and Media Technologies , volume=
Developing fake news immunity: fallacies as misinformation triggers during the pandemic , author=. Online Journal of Communication and Media Technologies , volume=. 2022 , publisher=
2022
-
[76]
Grounding Fallacies Misrepresenting Scientific Publications in Evidence
Glockner, Max and Hou, Yufang and Nakov, Preslav and Gurevych, Iryna. Grounding Fallacies Misrepresenting Scientific Publications in Evidence. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.491
-
[77]
Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22) , pages=
Fallacious argument classification in political debates , author=. Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22) , pages=. 2022 , organization=
2022
-
[78]
Fine-grained Fallacy Detection with Human Label Variation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2025 , url=
2025
-
[79]
A rgotario: Computational Argumentation Meets Serious Games
Habernal, Ivan and Hannemann, Raffael and Pollak, Christian and Klamm, Christopher and Pauli, Patrick and Gurevych, Iryna. A rgotario: Computational Argumentation Meets Serious Games. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2017. doi:10.18653/v1/D17-2002
-
[80]
``Nice Try, Kiddo'': Investigating Ad Hominems in Dialogue Responses
Sheng, Emily and Chang, Kai-Wei and Natarajan, Prem and Peng, Nanyun. ``Nice Try, Kiddo'': Investigating Ad Hominems in Dialogue Responses. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.60
-
[81]
Fine-grained Fallacy Detection with Human Label Variation
Ramponi, Alan and Daffara, Agnese and Tonelli, Sara. Fine-grained Fallacy Detection with Human Label Variation. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.34
-
[82]
CoRR , volume =
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =
2019
-
[83]
Informal logic , volume=
Why fallacies appear to be better arguments than they are , author=. Informal logic , volume=. 2010 , url=
2010
-
[84]
C. W. Tindale , title =. 1999 , publisher =
1999
-
[85]
Cognitive responses in persuasion , pages=
Recipient characteristics as determinants of responses to persuasion , author=. Cognitive responses in persuasion , pages=. 2014 , publisher=
2014
-
[86]
Sosnowski, Witold and Modzelewski, Arkadiusz and Skorupska, Kinga and Otterbacher, Jahna and Wierzbicki, Adam. EU D isinfo T est: a Benchmark for Evaluating Language Models' Ability to Detect Disinformation Narratives. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.862
-
[87]
Collection de sociologie générale et de philosophie sociale
Perelman, Chaïm and Olbrechts-Tyteca, Lucie , title =. Collection de sociologie générale et de philosophie sociale. Éditions de l'Institut de Sociologie de Bruxelles, 2e éd , publisher =. 1971 , volume =
1971
-
[88]
Fine-Grained Analysis of Propaganda in News Articles
Da San Martino, Giovanni and Yu, Seunghak and Barr \'o n-Cede \ n o, Alberto and Petrov, Rostislav and Nakov, Preslav. Fine-Grained Analysis of Propaganda in News Articles. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. d...
-
[89]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.