PivCo-Huffman
Pith reviewed 2026-06-27 23:36 UTC · model grok-4.3
The pith
PivCo-Huffman adapts wavelet tree pivots to Huffman trees for SIMD-friendly operations and higher decoding throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
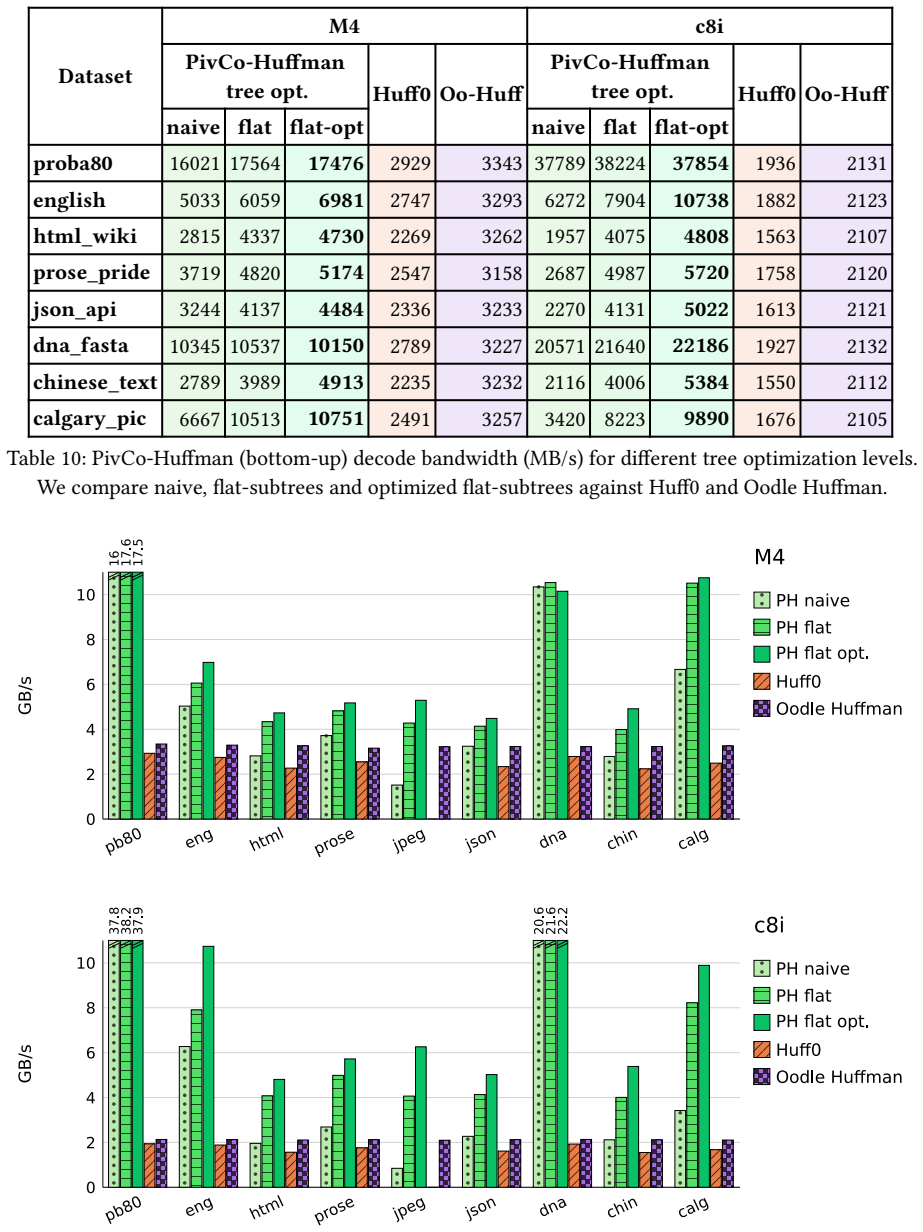
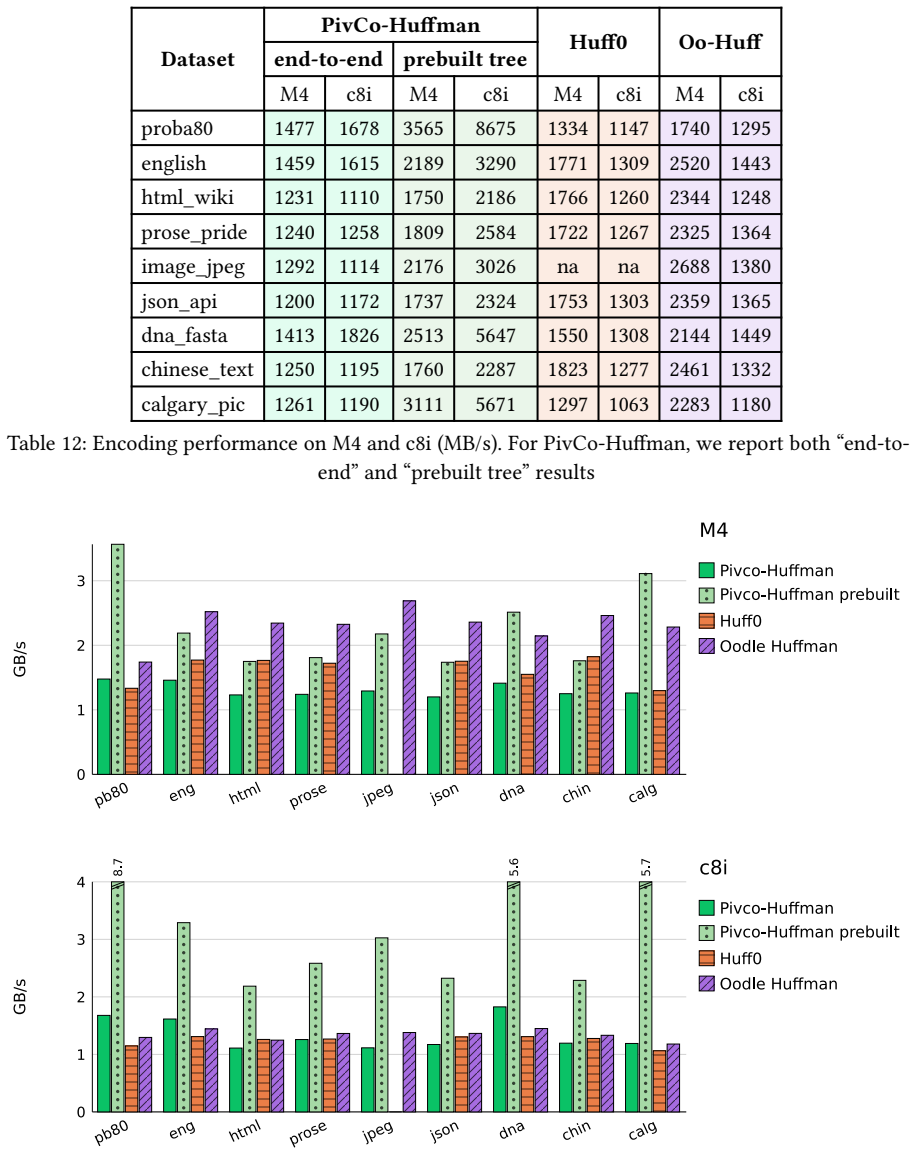
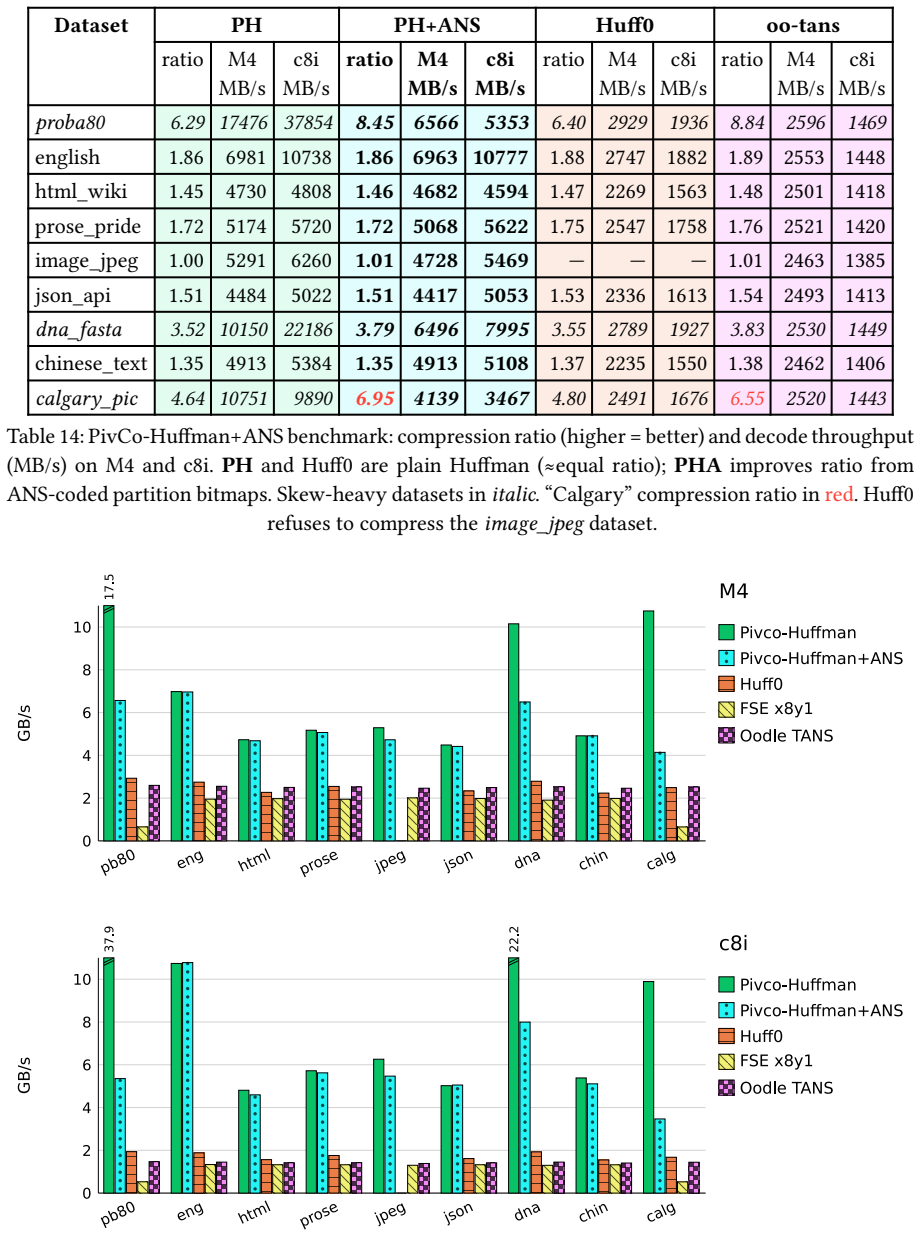
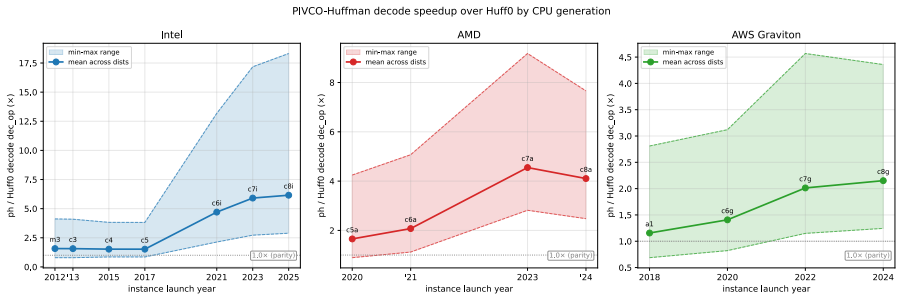
Mapping the pivot structure from wavelet trees onto Huffman trees yields a layout that supports efficient SIMD vectorized encoding and decoding operations, resulting in higher decoding throughput than state-of-the-art Huffman codecs, while also enabling selective application of ANS coding to skewed nodes to reach compression ratios approaching those of ANS-based codecs without sacrificing decompression speed.
What carries the argument
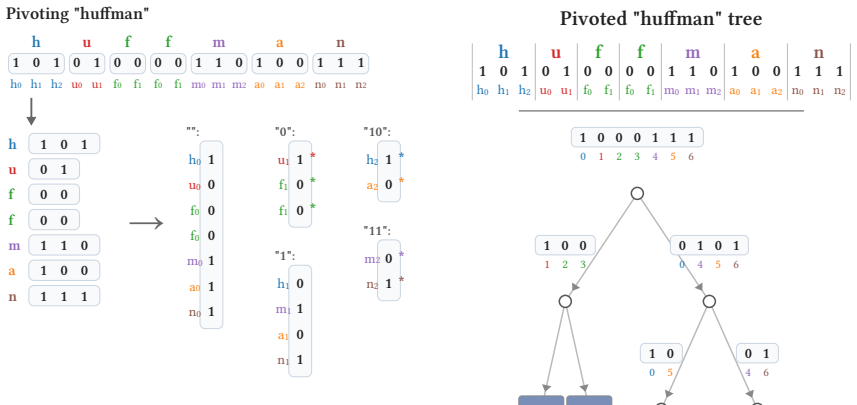
The pivot-coded Huffman structure that organizes Huffman trees using wavelet-tree pivots to support vectorized access patterns.
If this is right
- Decoding throughput exceeds that of state-of-the-art Huffman codecs.
- Encoding and decoding operations become amenable to SIMD vectorization.
- Selective ANS coding on skewed nodes produces compression ratios approaching ANS-based methods.
- The hybrid structure maintains very high decompression speeds alongside the improved ratios.
Where Pith is reading between the lines
- The pivot layout might be adapted to other tree-based prefix codes beyond Huffman.
- Hardware-specific tuning of pivot placement could further increase SIMD utilization on particular processors.
- The approach suggests a general route for blending wavelet-style navigation with entropy coding for new data types.
Load-bearing premise
The wavelet-tree pivot structure can be mapped onto Huffman trees without unacceptable overhead in construction time, memory use, or compression ratio, while keeping the layout suitable for efficient SIMD vectorization on real hardware.
What would settle it
A side-by-side benchmark on standard corpora showing that PivCo-Huffman decoding throughput does not exceed that of the best prior Huffman codecs.
Figures







read the original abstract
Huffman encoding has been an enduring technique for 70+ years, ubiquitous in compression algorithms since its invention. In this paper we propose a new approach to Huffman coding, based on a data structure from wavelet trees. The resulting pivot-coded Huffman (PivCo-Huffman) enables high-performance SIMD-friendly encoding and decoding operations. In our tests PivCo-Huffman consistently outperforms state-of-the-art Huffman codecs in decoding throughput. Additionally, we show how ANS-coding can be selectively applied to skewed nodes in this structure, yielding compression ratios approaching those of ANS-based codecs while preserving very high decompression speeds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PivCo-Huffman, a Huffman coding variant that grafts wavelet-tree pivot structures onto Huffman trees. It claims this layout enables SIMD-friendly encoding/decoding operations, yields higher decoding throughput than existing Huffman codecs, and permits selective ANS coding on skewed nodes to reach compression ratios approaching those of ANS codecs while retaining high decompression speed.
Significance. If the mapping produces a genuinely branch-free, vector-load-friendly layout with no material overhead in construction time, memory, or ratio, the result would be a useful data-structure contribution for high-throughput decompression on SIMD hardware. The hybrid Huffman-plus-selective-ANS idea is also potentially practical.
major comments (2)
- [Abstract] Abstract: the central empirical claim that PivCo-Huffman 'consistently outperforms state-of-the-art Huffman codecs in decoding throughput' is stated without any measurements, baselines, error bars, or implementation details, so the claim cannot be assessed.
- [Abstract] Abstract (and implied § on construction): the claim that the wavelet-tree pivot layout produces a memory layout whose decoding walk is branch-free and vector-load friendly is asserted without quantifying random memory accesses per symbol, pointer-chasing depth, or alignment properties of the pivot arrays. This directly affects whether the SIMD advantage can materialize on real hardware.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract and the description of the memory layout. We agree that both points identify areas where the manuscript can be strengthened by making empirical support and structural properties more explicit. We will revise the abstract and add the requested analysis in the construction and decoding sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that PivCo-Huffman 'consistently outperforms state-of-the-art Huffman codecs in decoding throughput' is stated without any measurements, baselines, error bars, or implementation details, so the claim cannot be assessed.
Authors: We agree that the abstract presents the throughput claim without supporting numbers. The experiments section reports concrete throughput figures against multiple Huffman baselines (including canonical Huffman and other SIMD variants), with repeated runs providing standard deviations. We will revise the abstract to include a concise summary of these results (e.g., average speedup and primary baselines) so the claim can be assessed without reading further. revision: yes
-
Referee: [Abstract] Abstract (and implied § on construction): the claim that the wavelet-tree pivot layout produces a memory layout whose decoding walk is branch-free and vector-load friendly is asserted without quantifying random memory accesses per symbol, pointer-chasing depth, or alignment properties of the pivot arrays. This directly affects whether the SIMD advantage can materialize on real hardware.
Authors: The manuscript explains that the pivot arrays replace traditional tree traversal with fixed-position array accesses, enabling branch-free SIMD loads. However, we acknowledge that explicit metrics for random accesses per symbol, pointer-chasing depth, and alignment are not quantified. We will add a short analysis subsection reporting these properties (average random accesses, maximum depth, and 64-byte alignment of pivot arrays) to substantiate the SIMD claim. revision: yes
Circularity Check
No circularity: proposal is a structural mapping with no self-referential equations or fitted predictions
full rationale
The paper introduces a wavelet-tree pivot layout grafted onto Huffman trees as a new encoding structure. No equations, fitted parameters, or predictions appear in the provided abstract or description. The central claim is an empirical performance assertion about SIMD throughput and selective ANS application; it does not reduce any derived quantity back to its own inputs by construction. No self-citation load-bearing steps or ansatz smuggling are visible. The derivation chain is therefore self-contained as a design proposal rather than a closed mathematical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Method for the Construction of Minimum-Redundancy Codes,
D. A. Huffman, “A Method for the Construction of Minimum-Redundancy Codes, ” Proceedings of the IRE, vol. 40, no. 9, pp. 1098–1101, 1952, doi: 10.1109/JRPROC.1952.273898
-
[2]
On the Implementation of Minimum Redundancy Prefix Codes,
A. Moffat and A. Turpin, “On the Implementation of Minimum Redundancy Prefix Codes, ” IEEE Transactions on Communications, vol. 45, no. 10, pp. 1200–1207, 1997, doi: 10.1109/26.634683
-
[3]
Arithmetic coding for data compression,
I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression, ” Communica- tions of the ACM, vol. 30, no. 6, pp. 520–540, 1987, doi: 10.1145/214762.214771
-
[4]
J. Duda, “Asymmetric numeral systems: entropy coding combining speed of Huffman coding with compression rate of arithmetic coding. ” [Online]. Available: https://arxiv.org/abs/1311.2540
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Generating a canonical prefix encoding,
E. S. Schwartz and B. Kallick, “Generating a canonical prefix encoding, ” Communications of the ACM, vol. 7, no. 3, pp. 166–169, 1964, doi: 10.1145/363958.363991
-
[6]
F. Giesen, “Interleaved entropy coders. ” [Online]. Available: https://arxiv.org/abs/1402.3392
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Entropy decoding in Oodle Data: x86-64 6-stream Huffman decoders
F. Giesen, “Entropy decoding in Oodle Data: x86-64 6-stream Huffman decoders. ” [Online]. Available: https://fgiesen.wordpress.com/2023/10/29/entropy-decoding-in-oodle-data-x86-64-6- stream-huffman-decoders/
2023
-
[8]
FiniteStateEntropy: New Generation Entropy coders)
Y. Collet, “FiniteStateEntropy: New Generation Entropy coders). ” [Online]. Available: https:// github.com/cyan4973/FiniteStateEntropy
-
[9]
zstd: A real-time lossless data compression library
Y. Collet and others, “zstd: A real-time lossless data compression library. ” [Online]. Available: https://github.com/facebook/zstd
-
[10]
Entropy coding in Oodle Data: Huffman coding
F. Giesen, “Entropy coding in Oodle Data: Huffman coding. ” [Online]. Available: https://fgiesen. wordpress.com/2021/08/30/entropy-coding-in-oodle-data-huffman-coding/
2021
-
[11]
Balancing Vectorized Query Execution with Bandwidth-Optimized Storage,
M. Zukowski, “Balancing Vectorized Query Execution with Bandwidth-Optimized Storage, ” Doc- toral dissertation, 2009. [Online]. Available: https://pure.uva.nl/ws/files/942072/72163_thesis.pdf
2009
-
[12]
High-order entropy-compressed text indexes,
R. Grossi, A. Gupta, and J. S. Vitter, “High-order entropy-compressed text indexes, ” in Proc. SODA 2003, SIAM, 2003, pp. 841–850. [Online]. Available: https://dl.acm.org/doi/10.5555/644108.644250
-
[13]
Bit-Parallel (Compressed) Wavelet Tree Construction,
P. Dinklage, J. Fischer, F. Kurpicz, and J.-P. Tarnowski, “Bit-Parallel (Compressed) Wavelet Tree Construction, ” in Proc. DCC 2023 , 2023. [Online]. Available: https://www.kurpicz.org/assets/ publications/dcc_2023.pdf
2023
-
[14]
Range ANS (rANS) - faster direct replacement for range coding
“Range ANS (rANS) - faster direct replacement for range coding. ” [Online]. Available: https:// encode.su/threads/1870-Range-ANS-(rANS)-faster-direct-replacement-for-range-coding
-
[15]
Oodle Data Compression Suite
RAD Game Tools (now Epic), “Oodle Data Compression Suite. ” 2025
2025
-
[16]
Neoverse V1 platform
Arm Limited, “Neoverse V1 platform. ” [Online]. Available: https://www.arm.com/products/ silicon-ip-cpu/neoverse/neoverse-v1
-
[17]
Run-length encodings,
S. W. Golomb, “Run-length encodings, ” IEEE Transactions on Information Theory , vol. 12, no. 3, pp. 399–401, 1966
1966
-
[18]
Some Practical Universal Noiseless Coding Techniques,
R. F. Rice, “Some Practical Universal Noiseless Coding Techniques, ” technical report JPL-79–22, 1979
1979
-
[19]
Partitioned Elias-Fano indexes,
G. Ottaviano and R. Venturini, “Partitioned Elias-Fano indexes, ” in Proc. SIGIR 2014, 2014
2014
-
[20]
Synthesis of noiseless compression codes,
B. P. Tunstall, “Synthesis of noiseless compression codes, ” Doctoral dissertation, 1967
1967
-
[21]
Compressing relations and indexes,
J. Goldstein, R. Ramakrishnan, and U. Shaft, “Compressing relations and indexes, ” in Proc. 14th Intl. Conf. on Data Engineering (ICDE '98), IEEE Computer Society, 1998, pp. 370–379. doi: 10.1109/ ICDE.1998.655800
-
[22]
Stream VByte: breaking new speed records for integer compression
D. Lemire, “Stream VByte: breaking new speed records for integer compression. ” [Online]. Avail- able: https://lemire.me/blog/2017/09/27/stream-vbyte-breaking-new-speed-records-for-integer- compression/
2017
-
[23]
Sayood, Introduction to Data Compression, 5th ed
K. Sayood, Introduction to Data Compression, 5th ed. Morgan Kaufmann, 2017
2017
-
[24]
The myriad virtues of Wavelet Trees,
P. Ferragina, R. Giancarlo, and G. Manzini, “The myriad virtues of Wavelet Trees, ” Information and Computation, vol. 207, no. 8, pp. 849–866, 2009, [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0890540108001594
2009
-
[25]
Practical Wavelet Tree Construction,
P. Dinklage, J. Ellert, J. Fischer, F. Kurpicz, and M. Löbel, “Practical Wavelet Tree Construction, ” ACM Journal of Experimental Algorithmics (JEA) , vol. 26, no. 1, pp. Article1.8, 67pp., 2021, doi: 10.1145/3457197
-
[26]
R. Raman, V. Raman, and S. R. Satti, “Succinct Indexable Dictionaries with Applications to Encoding k-ary Trees, Prefix Sums and Multisets, ” ACM Transactions on Algorithms, vol. 3, no. 4, p. Article43, 2007, [Online]. Available: https://arxiv.org/abs/0705.0552
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[27]
Super-Scalar RAM-CPU Cache Compression,
M. Zukowski, S. Héman, N. Nes, and P. Boncz, “Super-Scalar RAM-CPU Cache Compression, ” in Proc. 22nd Intl. Conf. on Data Engineering (ICDE '06), IEEE Computer Society, 2006. doi: 10.1109/ ICDE.2006.150
2006
-
[28]
Decoding billions of integers per second through vectorization,
D. Lemire and L. Boytsov, “Decoding billions of integers per second through vectorization, ” Software: Practice and Experience, vol. 45, no. 1, pp. 1–29, 2015, doi: 10.1002/spe.2203
-
[29]
The FastLanes Compression Layout: Decoding >100 Billion Integers per Second with Scalar Code,
A. Afroozeh and P. Boncz, “The FastLanes Compression Layout: Decoding >100 Billion Integers per Second with Scalar Code, ” Proceedings of the VLDB Endowment, vol. 16, no. 9, pp. 2132–2144, 2023, doi: 10.14778/3598581.3598587
-
[30]
Simple batch decoding of unary codes
F. Giesen, “Simple batch decoding of unary codes. ” [Online]. Available: https://fgiesen.wordpress. com/2026/05/30/simple-batch-decoding-of-unary-codes/ Appendices A Datasets Name #syms H (bits) Huffman (bits) min max Source / description calgary_pic 159 1.210 1.690 1 11 Calgary Corpus 1bpp CCITT scanned page, proba80-like real data (calgary_pic) chinese_...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.