Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
Pith reviewed 2026-06-27 04:32 UTC · model grok-4.3
The pith
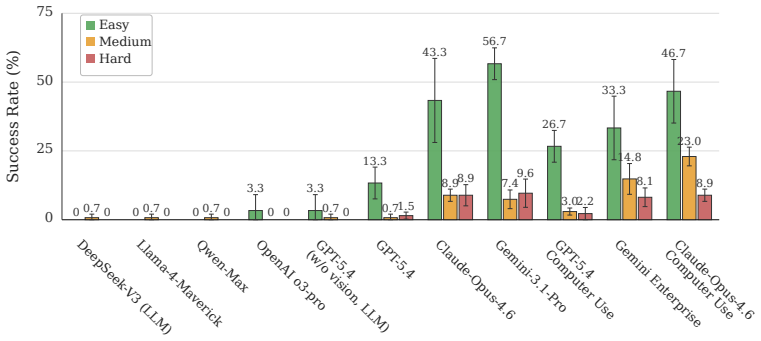
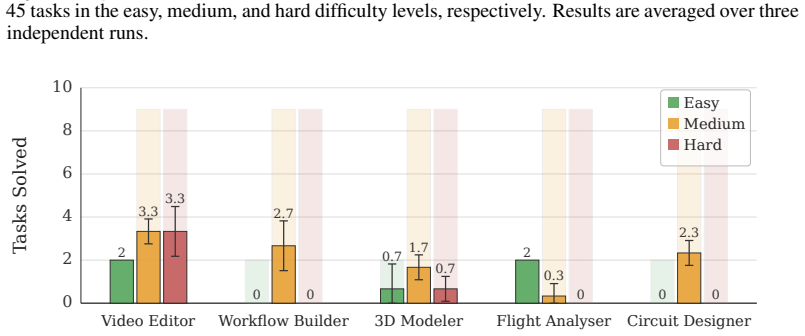
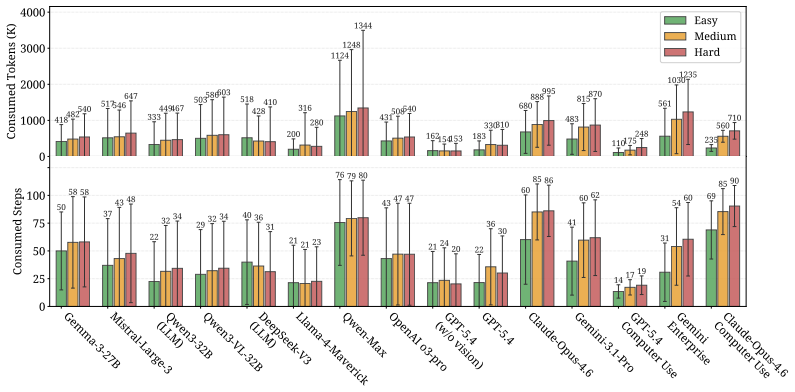
State-of-the-art agents reach only 19.1 percent success on a benchmark of 100 tasks testing temporal perception, graphical understanding, and 3D reasoning in professional tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
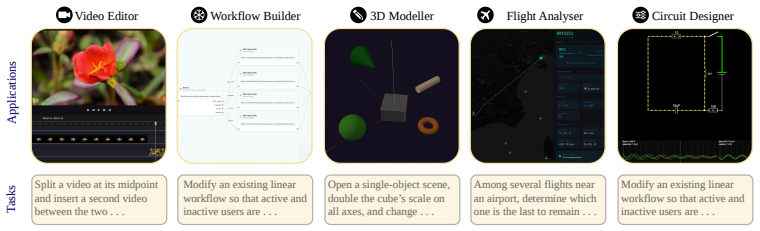
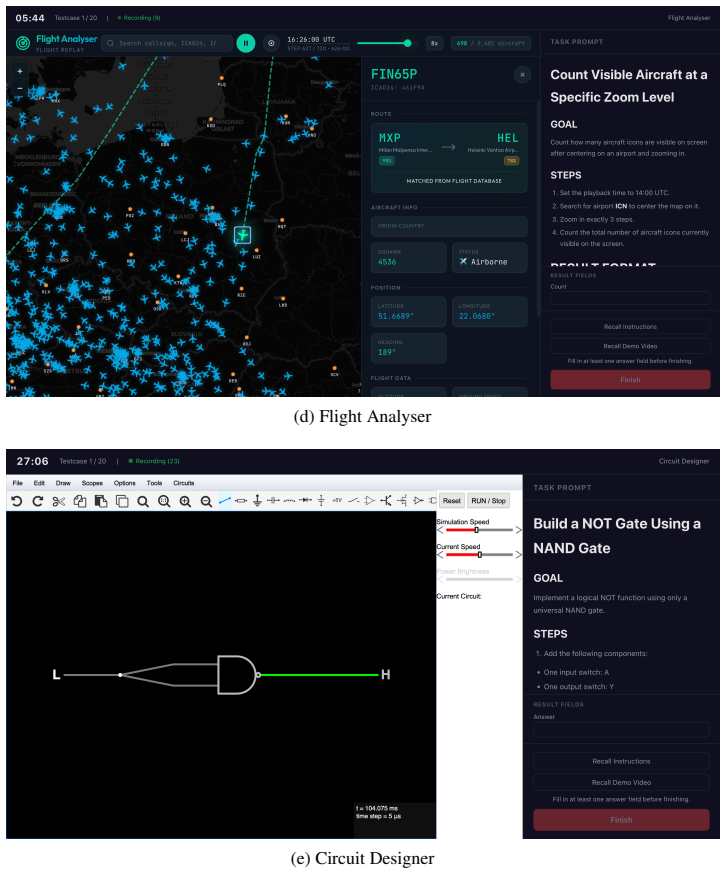
GauntletBench evaluates agent generalization through 100 tasks in five applications (Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, Circuit Designer), each probing temporal perception, graphical understanding, and 3D reasoning; even the strongest agent achieves only 19.1 percent success while humans reach over 80 percent, showing that existing benchmarks have saturated and fail to reveal these capability gaps.
What carries the argument
GauntletBench, a modular pipeline consisting of an agent-compatible environment, controlled web applications, structured task suites, and an automated evaluation engine with diverse metrics.
If this is right
- Agents require explicit support for temporal, graphical, and spatial reasoning to handle professional workflows.
- Existing saturated benchmarks must be supplemented with harder, less-covered domains to track real progress.
- Modular web-based pipelines allow consistent testing of both open- and closed-source agents without custom engineering.
- Human baselines above 80 percent confirm the tasks are feasible yet discriminative.
Where Pith is reading between the lines
- Training regimes that emphasize only familiar applications will continue to leave these three capabilities underdeveloped.
- Extending the benchmark to additional professional domains could reveal whether the 19.1 percent ceiling is specific to the five chosen tools.
- Automated metrics may undervalue partial progress on multi-step tasks, suggesting a need for finer-grained scoring in follow-up work.
Load-bearing premise
The 100 tasks measure genuine gaps in the targeted capabilities rather than artifacts of the evaluation setup that humans can overcome but agents cannot.
What would settle it
A single agent reaching over 80 percent success on the full GauntletBench suite under the same automated evaluation rules would falsify the reported capability gap.
Figures

read the original abstract
As agentic systems continue to evolve and are widely deployed in real-world scenarios, there is a growing demand to faithfully evaluate their capabilities. However, current benchmarks are typically built on popular applications with relatively simple tasks and focus on a narrow set of capabilities while overlooking broader dimensions, resulting in saturated performance on modern agents and failing to probe their limitations. To this end, we introduce GauntletBench, a web-based benchmark for evaluating agent generalisation in challenging scenarios, focusing on three underexplored capabilities (temporal perception, graphical understanding, and 3D reasoning), across five less-covered professional applications (Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, and Circuit Designer), each with 20 vision-intensive tasks (100 in total). Our benchmark provides a modular pipeline that comprises an environment compatible with both open- and closed-source agent frameworks, a controlled web-based application, a well-structured task suite, and an automated evaluation engine with diverse metrics. Contrary to widespread expectations, our empirical results reveal that frontier agentic systems remain far from achieving human-level performance. Even the state-of-the-art agent achieves only a 19.1% success rate on our GauntletBench, highlighting the limitations in these overlooked capabilities and generalisation. By comparison, non-expert human annotators achieve over 80% success on our challenging yet feasible tasks, revealing the substantial gap between current agent capabilities and those required for complex real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GauntletBench, a web-based benchmark consisting of 100 vision-intensive tasks across five professional applications (Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, Circuit Designer), each with 20 tasks targeting temporal perception, graphical understanding, and 3D reasoning. It provides a modular evaluation pipeline compatible with open- and closed-source agents and reports that even state-of-the-art agents achieve only a 19.1% success rate while non-expert humans achieve over 80%, indicating substantial gaps in generalization beyond familiar environments.
Significance. If the evaluation holds, the benchmark could meaningfully advance the field by exposing limitations in underexplored capabilities and providing a reproducible pipeline for testing generalization; the contrast with saturated performance on existing benchmarks is a useful contribution.
major comments (2)
- [Abstract] Abstract: the central claim of a 19.1% agent success rate versus >80% human success is presented without any description of task design, agent prompting, error analysis, or statistical significance testing; this directly limits assessment of whether the data supports the claim of substantial capability gaps.
- [Evaluation setup] The weakest assumption underlying the human-agent comparison—that the 100 tasks are both challenging enough to reveal true gaps and feasible for non-expert humans without bias or trivial solutions—is load-bearing; the manuscript must supply explicit details on task construction, validation, and evaluation protocol to substantiate the reported performance differential.
minor comments (1)
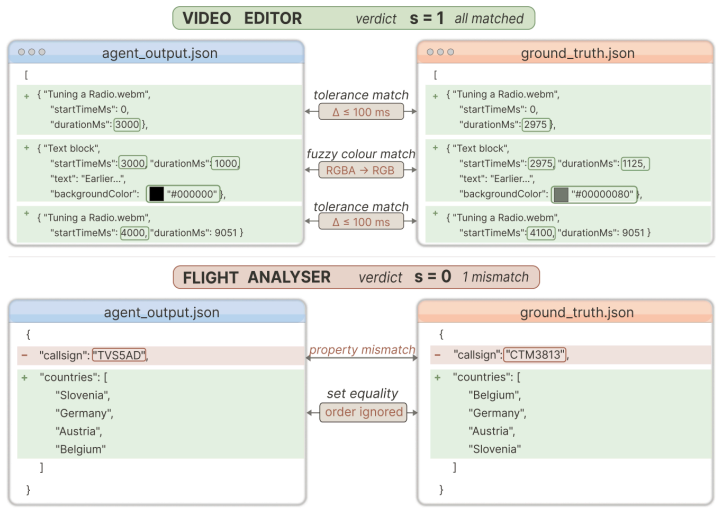
- Clarify the exact definition of 'success rate' and the automated evaluation engine metrics in the methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 19.1% agent success rate versus >80% human success is presented without any description of task design, agent prompting, error analysis, or statistical significance testing; this directly limits assessment of whether the data supports the claim of substantial capability gaps.
Authors: We agree that the abstract would benefit from additional context to support the central claim. In the revised manuscript we have expanded the abstract to include a brief description of task design across the five applications, the modular evaluation pipeline, and the human baseline collection protocol. Details on agent prompting, error analysis, and statistical significance testing remain in Sections 3 and 4, with explicit cross-references added to the abstract. revision: yes
-
Referee: [Evaluation setup] The weakest assumption underlying the human-agent comparison—that the 100 tasks are both challenging enough to reveal true gaps and feasible for non-expert humans without bias or trivial solutions—is load-bearing; the manuscript must supply explicit details on task construction, validation, and evaluation protocol to substantiate the reported performance differential.
Authors: We acknowledge the importance of substantiating the human-agent comparison. The manuscript already provides explicit details on task construction (Section 3.1), validation through pilot testing and feasibility checks (Section 3.2), and the full evaluation protocol including automated metrics and human annotation guidelines (Section 4). To strengthen this further we have added an appendix with inter-annotator agreement statistics, bias mitigation steps, and confirmation that no tasks admit trivial solutions for non-expert humans. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential reductions
full rationale
The paper introduces GauntletBench as a new empirical evaluation suite and reports direct success rates (19.1% for SOTA agents, >80% for humans) on 100 tasks. No equations, fitted parameters, uniqueness theorems, or derivation steps appear in the abstract or described structure. The central claim is the outcome of running agents on the benchmark rather than any reduction of results to inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present. This is a standard empirical benchmark paper whose results stand or fall on the task construction and evaluation protocol, not on internal circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Developing a computer use model
Anthropic. Developing a computer use model. https://www.anthropic.com/research/ developing-computer-use , 2024
2024
-
[2]
System Card: Claude Opus 4.6
Anthropic. System Card: Claude Opus 4.6. https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, February 2026
2026
-
[3]
System card: Claude opus 4 & claude sonnet 4
AI Anthropic. System card: Claude opus 4 & claude sonnet 4. Claude-4 Model Card, 2025
2025
-
[4]
Qwen3-vl technical report, 2025
Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Y ang Liu, Dayiheng Liu, Shixua...
2025
-
[5]
On the opportunities and risks of foundation models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021
Pith/arXiv arXiv 2021
-
[6]
Windows agent arena: Evaluating multi-modal os agents at scale, 2024
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Y adong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal os agents at scale, 2024
2024
-
[7]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference, 2024
2024
-
[8]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Y ang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, H...
2025
-
[9]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Y u Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Y u Su. Mind2web: Towards a generalist agent for the web, 2023
2023
-
[10]
Laradji, Manuel Del V erme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David V azquez, Nicolas Chapados, and Alexandre La- coste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del V erme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David V azquez, Nicolas Chapados, and Alexandre La- coste. Workarena: How capable are web agents at solving common knowledge work tasks?, 2024
2024
-
[11]
Real: Benchmarking autonomous agents on deterministic simulations of real websites, 2025
Divyansh Garg, Shaun V anWeelden, Diego Caples, Andis Draguns, Nikil Ravi, Pranav Putta, Naman Garg, Tomas Abraham, Michael Lara, Federico Lopez, James Liu, Atharva Gundawar, Prannay Hebbar, Y oungchul Joo, Jindong Gu, Charles London, Christian Schroeder de Witt, and Sumeet Motwani. Real: Benchmarking autonomous agents on deterministic simulations of real...
2025
-
[12]
A new era of intelligence with gemini 3
Google. A new era of intelligence with gemini 3. Google. URL: https://blog. google/products-and- platforms/products/gemini/gemini-3/( : 16.01. 2026) , 2025
2026
-
[13]
Computer Use
Google. Computer Use. https://ai.google.dev/gemini-api/docs/computer-use , 2026. Google AI for Developers
2026
-
[14]
Gemini 3.1 Pro Model Card
Google DeepMind. Gemini 3.1 Pro Model Card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf , February 2026
2026
-
[15]
Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
Hongliang He, Wenlin Y ao, Kaixin Ma, Wenhao Y u, Y ong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Y u. Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
2024
-
[16]
Language models can solve computer tasks
Geunwoo Kim, Pierre Baldi, and Stephen McAleer. Language models can solve computer tasks. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 39648–39677. Curran Associates, Inc., 2023
2023
-
[17]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks, 2024
Jing Y u Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Y u Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks, 2024
2024
-
[18]
Reinforcement learning on web interfaces using workflow-guided exploration
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. CoRR, abs/1802.08802, 2018
Pith/arXiv arXiv 2018
-
[19]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Y u, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Y u Gu, Hangliang Ding, Kaiwen Men, Kejuan Y ang, et al. Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations
-
[20]
Meta. Llama 4. https://www.llama.com/models/llama-4/, 2026
2026
-
[21]
Introducing Mistral 3
Mistral AI. Introducing Mistral 3. https://mistral.ai/news/mistral-3, 2025
2025
-
[22]
Entworld: A holistic environment and benchmark for verifiable enterprise gui agents
Ying Mo, Y u Bai, Dapeng Sun, Y uqian Shi, Y ukai Miao, Li Chen, and Dan Li. Entworld: A holistic environment and benchmark for verifiable enterprise gui agents. arXiv preprint arXiv:2601.17722, 2026
arXiv 2026
-
[23]
Chatgpt atlas - release notes
OpenAI. Chatgpt atlas - release notes. https://help.openai.com/en/articles/ 12591856-chatgpt-atlas-release-notes , 2025. Accessed: 2026-05-06
2025
-
[24]
OpenAI. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[25]
OpenAI o3-pro
OpenAI. OpenAI o3-pro. https://platform.openai.com/docs/models/o3-pro, 2025
2025
-
[26]
Computer Use
OpenAI. Computer Use. https://developers.openai.com/api/docs/guides/ tools-computer-use , 2026
2026
-
[27]
GPT-5.4 Thinking System Card
OpenAI. GPT-5.4 Thinking System Card. https://deploymentsafety.openai.com/ gpt-5-4-thinking/gpt-5-4-thinking.pdf , March 2026. 13
2026
-
[28]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology , pages 1–22, 2023
2023
-
[29]
Androidworld: A dynamic benchmarking environment for autonomous agents, 2025
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyam- agundlu, Timothy Lillicrap, and Oriana Riva. Androidworld: A dynamic benchmarking environment for autonomous agents, 2025
2025
-
[30]
Continuous benchmark generation for evaluating enterprise-scale llm agents
Divyanshu Saxena, Rishikesh Maurya, Xiaoxuan Ou, Gagan Somashekar, Shachee Mishra Gupta, Arun Iyer, Y u Kang, Chetan Bansal, Aditya Akella, and Saravan Rajmohan. Continuous benchmark generation for evaluating enterprise-scale llm agents. arXiv preprint arXiv:2511.10049, 2025
arXiv 2025
-
[31]
CircuitJS1: Electronic circuit simulator in the browser
Iain Sharp. CircuitJS1: Electronic circuit simulator in the browser. https://github.com/sharpie7/ circuitjs1, 2015. GWT port of Paul Falstad’s original Java applet. Open-source, GPL v2.0
2015
-
[32]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face
Y ongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Y ueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
-
[33]
World of bits: An open- domain platform for web-based agents
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An open- domain platform for web-based agents. In Doina Precup and Y ee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning , volume 70 of Proceedings of Machine Learning Research, pages 3135–3144. PMLR, 06–11 Aug 2017
2017
-
[34]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
2025
-
[35]
Qwen3-max: Just scale it, September 2025
Qwen Team. Qwen3-max: Just scale it, September 2025
2025
-
[36]
Androidenv: A reinforcement learning platform for android, 2021
Daniel Toyama, Philippe Hamel, Anita Gergely, Gheorghe Comanici, Amelia Glaese, Zafarali Ahmed, Tyler Jackson, Shibl Mourad, and Doina Precup. Androidenv: A reinforcement learning platform for android, 2021
2021
-
[37]
Odysseybench: Evaluating llm agents on long-horizon complex office application workflows
Weixuan Wang, Dongge Han, Daniel Madrigal Diaz, Jin Xu, Victor Rühle, and Saravan Rajmohan. Odysseybench: Evaluating llm agents on long-horizon complex office application workflows. arXiv preprint arXiv:2508.09124, 2025. 14
arXiv 2025
-
[38]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Y u. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
2024
-
[39]
Crab: Cross-environment agent benchmark for multimodal language model agents, 2025
Tianqi Xu, Linyao Chen, Dai-Jie Wu, Y anjun Chen, Zecheng Zhang, Xiang Y ao, Zhiqiang Xie, Y ongchao Chen, Shilong Liu, Bochen Qian, Anjie Y ang, Zhaoxuan Jin, Jianbo Deng, Philip Torr, Bernard Ghanem, and Guohao Li. Crab: Cross-environment agent benchmark for multimodal language model agents, 2025
2025
-
[40]
Qwen3 technical report, 2025
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Y ang, Jianhong Tu, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin ...
2025
-
[41]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Y ao, Howard Chen, John Y ang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems , 35:20744–20757, 2022
2022
-
[42]
React: Synergizing reasoning and acting in language models
Shunyu Y ao, Jeffrey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Y uan Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, 2022
2022
-
[43]
Assistantbench: Can web agents solve realistic and time-consuming tasks?, 2024
Ori Y oran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks?, 2024
2024
-
[44]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as- a-judge with mt-bench and chatbot arena, 2023
2023
-
[45]
unknown" or
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Y onatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. 15 Appendix: Table of Contents A Human Evaluation 17 B Additional Ablation Studies on Efficient 21 C Progress Rate Criteria...
2024
-
[47]
The action taken between the screenshots
-
[48]
The previous screenshot
-
[49]
The current screenshot
-
[50]
visible_action
Optionally, a compact prior visible-state summary from earlier confirmed steps Your goals: - Identify the visible UI change between the screenshots - Judge whether that change is relevant to task completion - Judge whether the step made positive progress, no progress, or negative progress - Update the visible-state summary only when the evidence is suffic...
-
[51]
The task instruction
-
[52]
The success condition
-
[53]
An objective evaluation result ( `OBJECTIVE EVALUATION RESULT `) with binary value `0` or `1`,→
-
[54]
A sequence of screenshot-based events extracted from the trajectory
-
[55]
The final screenshot
-
[56]
score": <k>,
The final agent answer Scoring rubric: - 5 = Full success clearly visible, including essential details; no meaningful visible mistakes or redundant artifacts remain,→ - 4 = Near success; most required state is achieved, but a minor non-essential issue remains,→ - 3 = Important partial progress, but at least one major requirement is missing, wrong, duplica...
-
[57]
[OUTPUT_KEY_1]
[CONTINUE AS NEEDED] # RESULT FORMAT ```json {"[OUTPUT_KEY_1]": "[FINAL_VALUE_1]", "[OUTPUT_KEY_2]": "[FINAL_VALUE_2]", "..."} ``` F .2 Per-Application Background Blocks F .2.1 Video Editor # APPLICATION BACKGROUND ## Application Overview Video Editor is a web application used for arranging and editing video, audio, and text. 29 The main workspace/interfa...
2022
-
[58]
Sample Media
Open the "Sample Media" dropdown and select "White Candle" and add it to timeline
-
[59]
Trim the clip so that only the first 5 seconds remain
-
[60]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 2 # Apply Light Correction and Boost Contrast ## GOAL Add a video, apply light correction, and increase only the contrast. ## STEPS
-
[62]
Apply light correction to the entire clip by maxing out only the contrast value
-
[63]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 34 No. Task 3 # Apply Fade-Out Transition ## GOAL Add a video and apply a fade-out transition to its last few seconds. ## STEPS
-
[64]
Sample Media
Open the "Sample Media" dropdown, select "Flower Video" and add it to the timeline
-
[65]
Apply a fade-out transition targeting the last 3 seconds of the clip
-
[66]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 4 # Trim a Video to a Specific Portion ## GOAL Add a video and trim it to keep only the segment from 4s to 11s. ## STEPS
-
[67]
Sample Media
Open the "Sample Media" dropdown, add "White Candle" video and drag to the timeline
-
[68]
Trim the video so that only the 4.00-11.00 seconds chunk remain
-
[69]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 5 # Add Background Audio to End of Video ## GOAL Add a video and an audio clip, positioning the audio as background for the end of the video. ## STEPS
-
[70]
Sample Media
Open the "Sample Media" dropdown, add "Flower Video" and audio clip to the timeline
-
[71]
Position the audio clip so that it plays as background audio during the end portion of the video clip
-
[72]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 35 No. Task 6 # Combine Three Videos in Sequence ## GOAL Place three videos on the timeline in a specific order and export. ## STEPS
-
[73]
Sample Media
Open the "Sample Media" dropdown and add "Tuning a Radio", "White Candle" and "Flower Video"
-
[74]
Drag all the videos to timeline and place them in same order
-
[75]
Flower Video
Trim ends of all videos so length of each clip matches length of "Flower Video" clip
-
[76]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 7 # The Quote ## GOAL Lift a middle segment out of a video, play it on its own first, then play the full original video. ## STEPS
-
[78]
On the timeline, first play only seconds 3 through 6 of the clip, then immediately after play the full original clip from start to end
-
[79]
Earlier
Add a 1-second text block reading "Earlier..." with white text on black background, placed immediately before the full playthrough begins
-
[80]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 36 No. Task 8 # Split Video and Insert Another in the Middle ## GOAL Split a video at its midpoint and insert a second video between the two halves. ## STEPS
-
[81]
Sample Media
Open the "Sample Media" dropdown and select "Flower Video"
-
[86]
Tuning a Radio
Insert "Tuning a Radio" between the two halves of "Flower Video"
-
[87]
‘json {"answer
Export the result. # RESULT FORMAT “‘json {"answer": "done"} “‘ Ground truth 9 # Reverse Order, Light Correction, and Fade-Out ## GOAL Arrange two videos in reverse order, apply light correction to a portion of the first, and apply a fade-out to the second. ## STEPS
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.