GaussLite: Online Task-Conditioned 3D Gaussian Splatting for Real-Time Robotic Mapping
Pith reviewed 2026-07-01 06:16 UTC · model grok-4.3
The pith
GaussLite conditions 3D Gaussian Splatting density on natural-language task masks to improve relevant-region quality at fixed budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
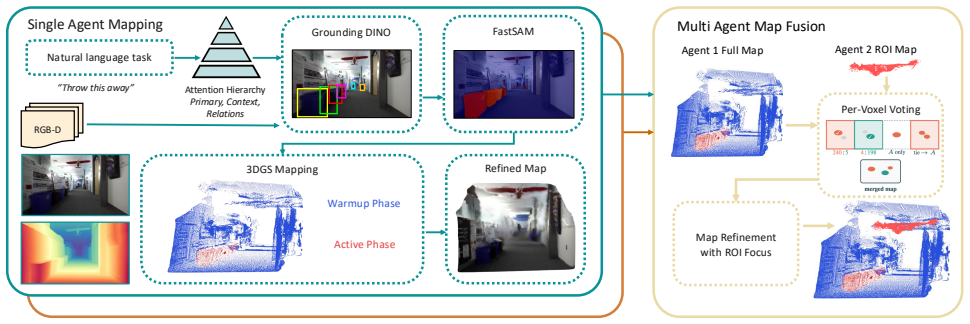
GaussLite is a task-driven 3DGS mapping system that conditions representation density on a natural-language task specification. Given a posed RGB-D stream and a task, it uses a one-shot LLM parser to extract target and anchor objects, grounds them per-frame by an open-vocabulary detector, and segments to produce per-pixel relevance masks in real time. The mapper then allocates seeding density, gradient flow, and scaling by task relevance. At matched Gaussian budget and real-time mapping at 4 Hz on resource-constrained hardware, it outperforms baselines on ROI PSNR on the Replica Dataset by an average +2.72 dB and on real-hardware demonstration in indoor and outdoor settings by +2.23 dB. Two
What carries the argument
Per-pixel relevance masks derived from LLM task parsing and open-vocabulary detection that control seeding density, gradient flow, and scaling inside 3D Gaussian Splatting.
If this is right
- ROI PSNR rises by an average 2.72 dB on Replica at the same total Gaussian count and 4 Hz mapping rate.
- Real indoor and outdoor hardware runs show a 2.23 dB ROI PSNR gain under identical constraints.
- Maps from two task-specialized agents fuse in real time via per-voxel voting on optimization counts.
- The fused map outperforms simple concatenation by 3.42 dB while sharing only 7.08% of the map on average.
Where Pith is reading between the lines
- The mask mechanism could be updated on the fly when a robot's task changes, reallocating capacity without rebuilding the entire map.
- Similar relevance-driven allocation might be applied to other scene representations such as neural radiance fields to reduce memory in long-running deployments.
- The low sharing percentage in fusion suggests that task-specialized maps could scale to many agents with modest communication cost.
Load-bearing premise
The one-shot LLM parser combined with the open-vocabulary detector produces accurate per-pixel relevance masks that correctly identify all geometry needed for the task without critical omissions or false positives.
What would settle it
Run the system with deliberately noisy or incomplete relevance masks and check whether the reported +2.72 dB and +2.23 dB ROI PSNR gains over uniform baselines disappear.
Figures



read the original abstract
Existing 3D Gaussian Splatting (3DGS) systems distribute representation capacity uniformly across a scene, ignoring the fact that many downstream robotic tasks engage only a fraction of the reconstructed geometry. This causes valuable onboard compute to be allocated towards optimizing irrelevant parts of the scene, either limiting online capacity or under-optimizing the most relevant parts of the scene. We introduce GaussLite, a task-driven 3DGS mapping system that conditions its representation density on a natural-language task specification. Given a posed RGB-D stream and a task such as "prepare to pick up the object on the desk," GaussLite uses a one-shot LLM parser to extract target and anchor objects, which are grounded per-frame by an open-vocabulary detector and segmented to produce per-pixel relevance masks in real time. The mapper allocates seeding density, gradient flow and scaling by task relevance. At matched Gaussian budget and real-time mapping at 4 Hz on resource-constrained hardware, GaussLite outperforms baselines on ROI PSNR on the Replica Dataset by an average +2.72 dB and on a real-hardware demonstration in indoor and outdoor settings by +2.23 dB. We further show that two task-specialized agents' maps can be fused into a single shared map via per-voxel voting on active-optimization counts in real time, outperforming concatenation by +3.42 dB while only sharing an average 7.08% of the map.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GaussLite, a task-conditioned 3D Gaussian Splatting system for real-time robotic mapping. Given a posed RGB-D stream and a natural-language task, it employs a one-shot LLM parser to extract target and anchor objects, grounded by an open-vocabulary detector to produce per-pixel relevance masks. These masks condition the allocation of seeding density, gradient flow, and scaling in the 3DGS mapper. The paper reports that at matched Gaussian budget and 4 Hz mapping on resource-constrained hardware, GaussLite achieves average ROI PSNR improvements of +2.72 dB on the Replica Dataset and +2.23 dB on real hardware demonstrations compared to baselines. Additionally, it shows that maps from two task-specialized agents can be fused in real time via per-voxel voting on active-optimization counts, outperforming simple concatenation by +3.42 dB while sharing only 7.08% of the map on average.
Significance. If the results hold under rigorous validation, the work could enable more efficient allocation of limited onboard compute in robotic 3D mapping by focusing representation capacity on task-relevant geometry. The real-time multi-agent fusion via per-voxel voting on optimization counts is a practical contribution that could support collaborative mapping scenarios with low communication overhead.
major comments (2)
- [Abstract] Abstract: The reported +2.72 dB Replica and +2.23 dB hardware ROI PSNR gains at matched Gaussian budget are load-bearing on the claim that the one-shot LLM parser combined with the open-vocabulary detector produces accurate per-pixel relevance masks that correctly identify all task geometry without critical omissions or false positives. No quantitative mask-quality metric (IoU, precision/recall) or ablation on mask error is referenced.
- [Abstract] Abstract: The abstract states quantitative PSNR improvements and fusion results but provides no details on baseline implementations, exact data splits, error bars, or ablation controls, preventing confirmation that the gains are attributable to the proposed conditioning rather than other factors.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the number of tasks, scenes, and runs used for the reported averages to allow readers to assess statistical robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger validation of the relevance masks and clearer experimental reporting. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported +2.72 dB Replica and +2.23 dB hardware ROI PSNR gains at matched Gaussian budget are load-bearing on the claim that the one-shot LLM parser combined with the open-vocabulary detector produces accurate per-pixel relevance masks that correctly identify all task geometry without critical omissions or false positives. No quantitative mask-quality metric (IoU, precision/recall) or ablation on mask error is referenced.
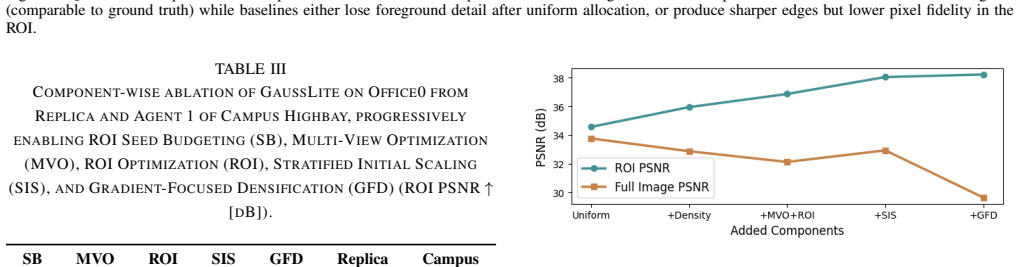
Authors: We agree that direct quantitative metrics on mask quality would strengthen the claims. The current evaluation relies on downstream ROI PSNR as evidence of effective conditioning. In revision we will add a dedicated evaluation subsection reporting IoU, precision, and recall of the generated masks against manually annotated ground-truth on a held-out subset of Replica sequences, plus an ablation measuring PSNR sensitivity to controlled mask perturbations (e.g., false-positive or false-negative rates). revision: yes
-
Referee: [Abstract] Abstract: The abstract states quantitative PSNR improvements and fusion results but provides no details on baseline implementations, exact data splits, error bars, or ablation controls, preventing confirmation that the gains are attributable to the proposed conditioning rather than other factors.
Authors: The abstract is space-constrained, but the full manuscript already specifies baseline implementations (uniform 3DGS and task-agnostic variants in Section 4.2), uses the standard Replica train/test splits, reports per-scene standard deviations, and includes component ablations (Section 4.3). We will revise the abstract to include a one-sentence pointer to these sections and ensure all result tables explicitly list error bars and data-split details. revision: partial
Circularity Check
No circularity; empirical system with performance claims from direct comparisons
full rationale
The paper describes an engineering system that allocates Gaussian density using per-pixel relevance masks from an LLM parser plus open-vocabulary detector, then reports ROI PSNR gains on Replica and hardware at fixed budget. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method; the +2.72 dB / +2.23 dB / +3.42 dB figures are presented as measured outcomes of the full pipeline rather than quantities forced by construction from the inputs. The load-bearing assumption (mask accuracy) is an empirical premise, not a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakiset al., “3d gaussian splatting for real-time radiance field rendering.”ACM TOG, vol. 42, no. 4, pp. 139–1, 2023
2023
-
[2]
Gaussian-slam: Photo-realistic dense slam with gaussian splatting,
V . Yugay, Y . Li, T. Gevers, and M. R. Oswald, “Gaussian-slam: Photo-realistic dense slam with gaussian splatting,”arXiv preprint arXiv:2312.10070, 2023
-
[3]
Splatmap: Online dense monocular slam with 3d gaussian splatting,
Y . Hu, R. Liu, M. Chen, P. Beerel, and A. Feng, “Splatmap: Online dense monocular slam with 3d gaussian splatting,”PACMCGIT, vol. 8, no. 1, pp. 1–18, 2025
2025
-
[4]
Densesplat: Densifying gaussian splatting slam with neural radiance prior,
M. Li, S. Liu, T. Deng, and H. Wang, “Densesplat: Densifying gaussian splatting slam with neural radiance prior,”IEEE Transactions on Visualization and Computer Graphics, 2025
2025
-
[5]
Lightgaus- sian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,
Z. Fan, K. Wang, K. Wen, Z. Zhu, D. Xu, and Z. Wang, “Lightgaus- sian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,”NeurIPS, vol. 37, pp. 140 138–140 158, 2024
2024
-
[6]
PUP 3D-GS: Principled uncertainty pruning for 3D gaussian splatting,
A. Hanson, A. Tu, V . Singla, M. Jayawardhana, M. Zwicker, and T. Goldstein, “PUP 3D-GS: Principled uncertainty pruning for 3D gaussian splatting,”arXiv preprint arXiv:2406.10219, 2024
-
[7]
Optimized minimal 3d gaussian splatting,
J. C. Lee, J. H. Ko, and E. Park, “Optimized minimal 3d gaussian splatting,”NeurIPS, vol. 38, pp. 135 864–135 888, 2026
2026
-
[8]
Controlgs: Consistent struc- tural compression control for deployment-aware gaussian splatting,
F. Zhang, Y . Sun, H. Cao, and R. Huang, “Controlgs: Consistent struc- tural compression control for deployment-aware gaussian splatting,” arXiv preprint arXiv:2505.10473, 2025
-
[9]
A hierarchical 3D gaussian representation for real-time rendering of very large datasets,
B. Kerbl, A. Meuleman, G. Kopanas, M. Wimmer, A. Lanvin, and G. Drettakis, “A hierarchical 3D gaussian representation for real-time rendering of very large datasets,”ACM TOG, vol. 43, no. 4, pp. 1–15, 2024
2024
-
[10]
LODGE: Level- of-detail large-scale gaussian splatting with efficient rendering,
J. Kulhanek, M.-J. Rakotosaona, F. Manhardt, C. Tsalicoglou, M. Niemeyer, T. Sattler, S. Peng, and F. Tombari, “LODGE: Level- of-detail large-scale gaussian splatting with efficient rendering,”arXiv preprint arXiv:2505.23158, 2025
-
[11]
Clod-gs: Continuous level-of-detail via 3d gaussian splatting,
Z. Cheng, M. Sun, Y . Liu, Z. Ge, L. Tang, M. Xu, Y . Li, and P. Pan, “Clod-gs: Continuous level-of-detail via 3d gaussian splatting,”arXiv preprint arXiv:2510.09997, 2025
-
[12]
arXiv preprint arXiv:2403.17898 (2024) 3
K. Ren, L. Jiang, T. Lu, M. Yu, L. Xu, Z. Ni, and B. Dai, “Octree- gs: Towards consistent real-time rendering with lod-structured 3d gaussians,”arXiv preprint arXiv:2403.17898, 2024
-
[13]
Compact 3D Gaussian Splatting For Dense Visual SLAM
T. Deng, Y . Chen, L. Zhang, J. Yang, S. Yuan, J. Liu, D. Wang, H. Wang, and W. Chen, “Compact 3d gaussian splatting for dense visual slam,”arXiv preprint arXiv:2403.11247, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Eye movements in natural behavior,
M. Hayhoe and D. Ballard, “Eye movements in natural behavior,” Trends in cognitive sciences, vol. 9, no. 4, pp. 188–194, 2005
2005
-
[15]
A. L. Yarbus,Eye movements and vision. Springer, 2013
2013
-
[16]
In what ways do eye movements contribute to everyday activities?
M. F. Land and M. Hayhoe, “In what ways do eye movements contribute to everyday activities?”Vision research, vol. 41, no. 25- 26, pp. 3559–3565, 2001
2001
-
[17]
W. Jiang, B. Lei, and K. Daniilidis, “Fisherrf: Active view selection and uncertainty quantification for radiance fields using fisher informa- tion,”arXiv preprint arXiv:2311.17874, 2023
-
[18]
Activenerf: Learning where to see with uncertainty estimation,
X. Pan, Z. Lai, S. Song, and G. Huang, “Activenerf: Learning where to see with uncertainty estimation,” inECCV. Springer, 2022, pp. 230–246
2022
-
[19]
Vr-splatting: Foveated radiance field rendering via 3d gaussian splatting and neural points,
L. Franke, L. Fink, and M. Stamminger, “Vr-splatting: Foveated radiance field rendering via 3d gaussian splatting and neural points,” PACMCGIT, vol. 8, no. 1, pp. 1–21, 2025
2025
-
[20]
Deepfovea: Neural reconstruction for foveated rendering and video compression using learned statistics of natural videos,
A. S. Kaplanyan, A. Sochenov, T. Leimk ¨uhler, M. Okunev, T. Goodall, and G. Rufo, “Deepfovea: Neural reconstruction for foveated rendering and video compression using learned statistics of natural videos,”ACM TOG, vol. 38, no. 6, pp. 1–13, 2019
2019
-
[21]
Rtgs: Real-time 3d gaussian splatting slam via multi-level redundancy reduction,
L. Li, J. Qin, J. Peng, Z. Wan, H. Qu, Y . Han, P. Zheng, H. Zhang, Y . Cao, T. Chenet al., “Rtgs: Real-time 3d gaussian splatting slam via multi-level redundancy reduction,” inIEEE/ACM International Symposium on Microarchitecture, 2025, pp. 1838–1851
2025
-
[22]
Vista: Open-vocabulary, task-relevant robot exploration with online semantic gaussian splatting,
K. Nagami, T. Chen, J. Yu, O. Shorinwa, M. Adang, C. Dougherty, E. Cristofalo, and M. Schwager, “Vista: Open-vocabulary, task-relevant robot exploration with online semantic gaussian splatting,”IEEE Robotics and Automation Letters, 2026
2026
-
[23]
Gaus- sianlens: Localized high-resolution reconstruction via on-demand gaussian densification,
Y . Weng, Z. Wang, S. Peng, S. Xie, H. Zhou, and L. J. Guibas, “Gaus- sianlens: Localized high-resolution reconstruction via on-demand gaussian densification,”arXiv preprint arXiv:2509.25603, 2025
-
[24]
Gaussian splatting slam,
H. Matsuki, R. Murai, P. H. Kelly, and A. J. Davison, “Gaussian splatting slam,” inCVPR, 2024, pp. 18 039–18 048
2024
-
[25]
Splatam: Splat track & map 3d gaussians for dense rgb-d slam,
N. Keetha, J. Karhade, K. M. Jatavallabhulaet al., “Splatam: Splat track & map 3d gaussians for dense rgb-d slam,” inCVPR, 2024, pp. 21 357–21 366
2024
-
[26]
Nice-slam: Neural implicit scalable encoding for slam,
Z. Zhu, S. Peng, V . Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, and M. Pollefeys, “Nice-slam: Neural implicit scalable encoding for slam,” inCVPR, 2022, pp. 12 786–12 796
2022
-
[27]
Grand-slam: Local optimization for globally consistent large-scale multi-agent gaussian slam,
A. Thomas, A. Sonawalla, A. Rose, and J. P. How, “Grand-slam: Local optimization for globally consistent large-scale multi-agent gaussian slam,”IEEE Robotics and Automation Letters, 2025
2025
-
[28]
Mip-splatting: Alias-free 3d gaussian splatting,
Z. Yu, A. Chen, B. Huang, T. Sattler, and A. Geiger, “Mip-splatting: Alias-free 3d gaussian splatting,” inCVPR, 2024, pp. 19 447–19 456
2024
-
[29]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering,
T. Lu, M. Yu, L. Xu, Y . Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold-gs: Structured 3d gaussians for view-adaptive rendering,” inCVPR, 2024, pp. 20 654–20 664
2024
-
[30]
Smerf: Streamable memory efficient radiance fields for real-time large-scene exploration,
D. Duckworth, P. Hedman, C. Reiser, P. Zhizhin, J.-F. Thibert, M. Lu ˇci´c, R. Szeliski, and J. T. Barron, “Smerf: Streamable memory efficient radiance fields for real-time large-scene exploration,”ACM TOG, vol. 43, no. 4, pp. 1–13, 2024
2024
-
[31]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacyet al., “Learning transferable visual models from natural language supervision,” inICML. PmLR, 2021, pp. 8748–8763
2021
-
[32]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inICCV, 2023, pp. 4015–4026
2023
-
[33]
Lerf: Language embedded radiance fields,
J. Kerr, C. M. Kim, K. Goldberget al., “Lerf: Language embedded radiance fields,” inICCV, 2023, pp. 19 729–19 739
2023
-
[34]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” inCVPR, 2024, pp. 20 051–20 060
2024
-
[35]
K. M. Jatavallabhula, A. Kuwajerwala, Q. Guet al., “Conceptfusion: Open-set multimodal 3d mapping,”arXiv preprint arXiv:2302.07241, 2023
-
[36]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
2024
-
[37]
Semantic gaussians: Open- vocabulary scene understanding with 3d gaussian splatting,
J. Guo, X. Ma, Y . Fan, H. Liu, and Q. Li, “Semantic gaussians: Open- vocabulary scene understanding with 3d gaussian splatting,”IEEE Transactions on Circuits and Systems for Video Technology, 2026
2026
-
[38]
OpenGaussian: Towards point-level 3D gaussian-based open vocabulary understanding,
Y . Wu, J. Li, F. Luo, J. Liu, X. Guoet al., “OpenGaussian: Towards point-level 3D gaussian-based open vocabulary understanding,” in NeurIPS, 2024
2024
-
[39]
Clio: Real-time task-driven open-set 3d scene graphs,
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone, “Clio: Real-time task-driven open-set 3d scene graphs,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8921–8928, 2024
2024
-
[40]
Bayesian fields: Task-driven open-set semantic gaussian splatting,
D. Maggio and L. Carlone, “Bayesian fields: Task-driven open-set semantic gaussian splatting,”arXiv preprint arXiv:2503.05949, 2025
-
[41]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Microsoft, “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inECCV. Springer, 2024, pp. 38–55
2024
-
[43]
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,”arXiv preprint arXiv:2306.12156, 2023
-
[44]
Direct lidar-inertial odometry: Lightweight lio with continuous-time motion correction,
K. Chen, R. Nemiroff, and B. T. Lopez, “Direct lidar-inertial odom- etry: Lightweight lio with continuous-time motion correction,”arXiv preprint arXiv:2203.03749, 2022
-
[45]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Vermaet al., “The replica dataset: A digital replica of indoor spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.