JourneyFormer: Encoding Airbnb Guest Journey with Sequence Modeling
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
JourneyFormer applies sequence modeling to long, exploratory Airbnb guest sequences with sparse booking labels, enabling production deployment that improves ranking metrics and business KPIs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
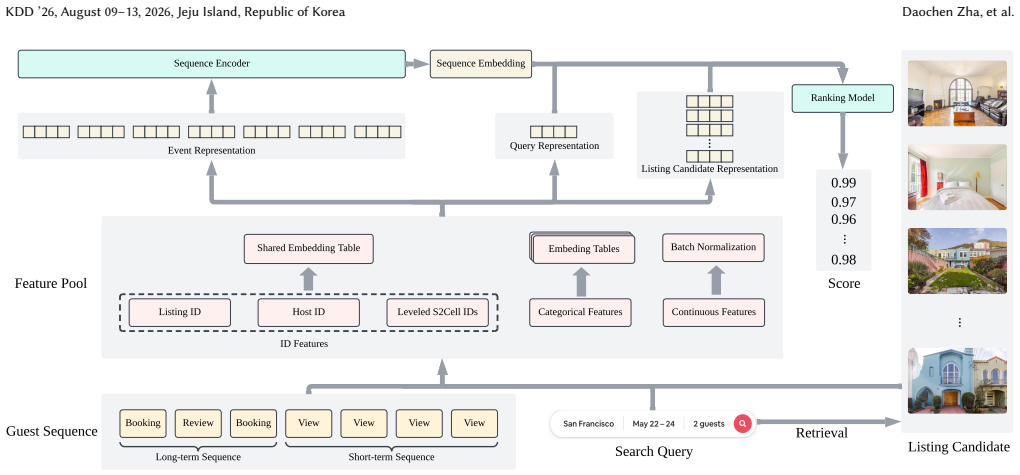
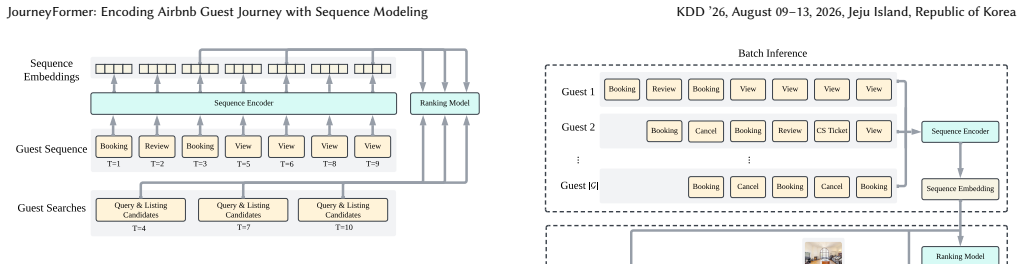
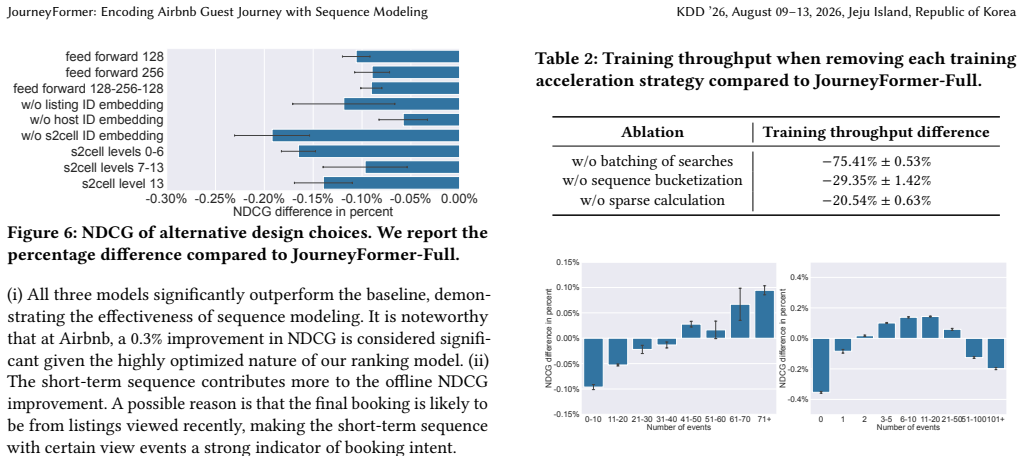
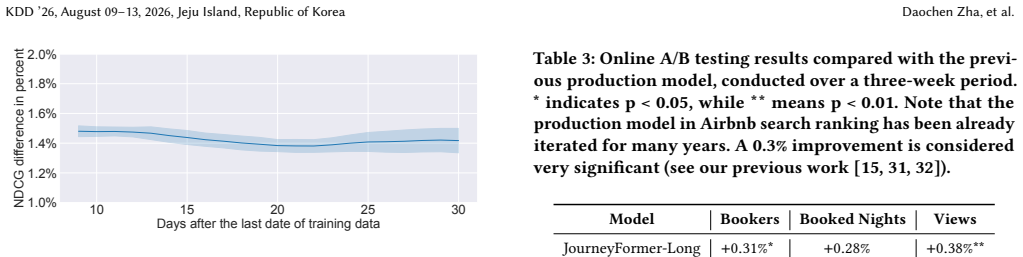
JourneyFormer is a sequence model built for Airbnb guest journeys that incorporates targeted decisions on event selection, ID embeddings, architecture, and label attribution, plus acceleration techniques for training and inference; once deployed in production it delivered gains in offline ranking metrics and statistically significant improvements in key business metrics across two production surfaces.
What carries the argument
JourneyFormer sequence model that encodes sequences of guest events to infer booking intentions for search ranking, supported by the listed design choices for data and modeling.
If this is right
- Sequence models become practical for production ranking when event selection, embedding strategy, architecture, and label rules are jointly tuned for length and sparsity.
- Acceleration methods for training and inference allow the model to meet the latency and throughput needs of live search surfaces.
- Offline ranking improvements translate to measurable online business metric gains when the model is deployed on real user traffic.
Where Pith is reading between the lines
- The same design pattern could be tested on other platforms where user sequences are long and purchase events are infrequent.
- Label attribution rules developed here might reduce noise in any ranking task that relies on delayed or sparse conversion signals.
- The emphasis on production constraints suggests that future sequence models for recommendation will need explicit handling of both data volume and serving cost.
Load-bearing premise
The observed gains in ranking metrics and business KPIs are caused by the specific JourneyFormer design decisions rather than by unrelated system changes or external factors.
What would settle it
An A/B test that swaps only the JourneyFormer component into the existing production system and measures no lift in the reported business metrics would falsify the attribution of gains to the model.
Figures



read the original abstract
Sequence modeling has become increasingly popular in recommendation and ranking algorithms, owing to its capacity to model users' historical behaviors and infer user intentions. Despite its theoretical simplicity, the practical deployment of a sequence model in production is non-trivial due to complexity of the sequence and sparse labels. For example, in Airbnb, guest sequences are often long, exploratory and complex, and we focus on booking labels, which are sparse. As such, we are often required to make various design decisions regarding data and modeling to strike a balance between effectiveness and scalability. This work delved into these production challenges and deployed JourneyFormer, a sequence modeling solution for search ranking at Airbnb. We detail crucial design considerations, covering aspects such as guest event selection, ID embeddings, model architecture, and label attribution. Additionally, we describe several tailored strategies to accelerate model training and inference. JourneyFormer has been successfully deployed within Airbnb's production, where its effectiveness and impact have been evidenced not only by improved offline ranking metrics but also by significant gains in key business metrics through online A/B testing across 2 production surfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JourneyFormer, a sequence modeling solution for encoding long, exploratory Airbnb guest journeys in search ranking. It discusses production design choices including guest event selection, ID embeddings, model architecture, label attribution, and strategies to accelerate training and inference. The central claim is successful production deployment, with effectiveness shown via improved offline ranking metrics and significant gains in business metrics from online A/B testing on two production surfaces.
Significance. If the A/B gains can be robustly attributed to the reported design choices rather than external factors, the work would provide a useful case study on deploying sequence models under sparse labels and complex user behavior at scale, offering practical guidance for recommendation systems in travel and e-commerce.
major comments (2)
- [Abstract] Abstract: The claim that JourneyFormer produced 'significant gains in key business metrics through online A/B testing across 2 production surfaces' is load-bearing for the central deployment-success assertion, yet the text supplies no description of test isolation, controls for concurrent ranking-system changes, baseline configurations, or statistical significance testing. This prevents verification that observed lifts are attributable to the listed design choices (event selection, ID embeddings, architecture, label attribution) rather than external factors.
- [Abstract] Abstract and throughout: No equations, model diagrams, data statistics (e.g., sequence lengths, label sparsity rates), baseline comparisons, or error analysis are provided, so the soundness of the sequence-modeling approach and the attribution of metric improvements cannot be evaluated against the manuscript's own evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, committing to revisions that strengthen the attribution of results and the supporting evidence while respecting the production-focused nature of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that JourneyFormer produced 'significant gains in key business metrics through online A/B testing across 2 production surfaces' is load-bearing for the central deployment-success assertion, yet the text supplies no description of test isolation, controls for concurrent ranking-system changes, baseline configurations, or statistical significance testing. This prevents verification that observed lifts are attributable to the listed design choices (event selection, ID embeddings, architecture, label attribution) rather than external factors.
Authors: We agree that the abstract claim would be strengthened by explicit details on the A/B testing protocol. In the revision we will add a dedicated online evaluation section describing test isolation procedures, baseline configurations, controls for concurrent system changes, and statistical significance testing. This will allow readers to better assess attribution to the reported design choices. revision: yes
-
Referee: [Abstract] Abstract and throughout: No equations, model diagrams, data statistics (e.g., sequence lengths, label sparsity rates), baseline comparisons, or error analysis are provided, so the soundness of the sequence-modeling approach and the attribution of metric improvements cannot be evaluated against the manuscript's own evidence.
Authors: The manuscript emphasizes production deployment challenges rather than novel algorithmic contributions, which is why new equations or architecture diagrams were omitted. We accept that adding empirical support would improve evaluability. The revision will incorporate data statistics (sequence length distributions, label sparsity), baseline comparisons, and error analysis to substantiate the offline and online results. revision: yes
Circularity Check
No derivation chain present; empirical deployment results stand on external A/B benchmarks
full rationale
The paper contains no mathematical derivation, equations, or first-principles claims. It describes design choices for a sequence model and reports measured improvements from offline metrics plus online A/B tests on production surfaces. These results are external benchmarks rather than outputs derived from the model inputs by construction. No self-citations, fitted parameters renamed as predictions, or ansatzes appear in the provided text. The central claim is therefore self-contained against the reported empirical evidence and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mustafa Abdool, Malay Haldar, Prashant Ramanathan, Tyler Sax, Lanbo Zhang, Aamir Manaswala, Lynn Yang, Bradley Turnbull, Qing Zhang, and Thomas Legrand. 2020. Managing diversity in airbnb search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2952–2960
2020
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[3]
Maarten Buyl, Paul Missault, and Pierre-Antoine Sondag. 2023. Rankformer: Listwise learning-to-rank using listwide labels. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3762–3773
2023
-
[4]
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to rank: from pairwise approach to listwise approach. InProceedings of the 24th international conference on Machine learning. 129–136
2007
-
[5]
Xu Chen, Hongteng Xu, Yongfeng Zhang, Jiaxi Tang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2018. Sequential recommendation with user memory networks. InProceedings of the eleventh ACM international conference on web search and data mining. 108–116
2018
-
[6]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. InProceedings of the ACM web conference 2022. 2172–2182
2022
-
[7]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555(2014)
Pith/arXiv arXiv 2014
-
[8]
Benjamin Coleman, Wang-Cheng Kang, Matthew Fahrbach, Ruoxi Wang, Lichan Hong, Ed Chi, and Derek Cheng. 2023. Unified Embedding: Battle-tested feature representations for web-scale ML systems.Advances in Neural Information Processing Systems36 (2023), 56234–56255
2023
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[10]
Tim Donkers, Benedikt Loepp, and Jürgen Ziegler. 2017. Sequential user-based recurrent neural network recommendations. InProceedings of the eleventh ACM conference on recommender systems. 152–160
2017
-
[11]
Xinyu Du, Huanhuan Yuan, Pengpeng Zhao, Jianfeng Qu, Fuzhen Zhuang, Guan- feng Liu, Yanchi Liu, and Victor S Sheng. 2023. Frequency enhanced hybrid attention network for sequential recommendation. InProceedings of the 46th International ACM SIGIR conference on research and development in information retrieval. 78–88
2023
-
[12]
Ziwei Fan, Zhiwei Liu, Yu Wang, Alice Wang, Zahra Nazari, Lei Zheng, Hao Peng, and Philip S Yu. 2022. Sequential recommendation via stochastic self-attention. InProceedings of the ACM web conference 2022. 2036–2047
2022
-
[13]
Alex Graves and Alex Graves. 2012. Long short-term memory.Supervised sequence labelling with recurrent neural networks(2012), 37–45
2012
-
[14]
Malay Haldar, Mustafa Abdool, Liwei He, Dillon Davis, Huiji Gao, and Sanjeev Katariya. 2023. Learning To Rank Diversely At Airbnb. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4609–4615
2023
-
[15]
Malay Haldar, Mustafa Abdool, Prashant Ramanathan, Tao Xu, Shulin Yang, Huizhong Duan, Qing Zhang, Nick Barrow-Williams, Bradley C Turnbull, Bren- dan M Collins, et al. 2019. Applying deep learning to airbnb search. Inproceedings of the 25th ACM SIGKDD international conference on knowledge discovery & Data Mining. 1927–1935
2019
-
[16]
Ruining He, Wang-Cheng Kang, and Julian McAuley. 2017. Translation-based recommendation. InProceedings of the eleventh ACM conference on recommender systems. 161–169
2017
-
[17]
Ruining He and Julian McAuley. 2016. Fusing similarity models with markov chains for sparse sequential recommendation. In2016 IEEE 16th international conference on data mining (ICDM). IEEE, 191–200
2016
-
[18]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[19]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
Pith/arXiv arXiv 2015
-
[20]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[21]
Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428
2017
-
[22]
Jiacheng Li, Yujie Wang, and Julian McAuley. 2020. Time interval aware self- attention for sequential recommendation. InProceedings of the 13th international conference on web search and data mining. 322–330
2020
-
[23]
Chen Luo, William Headden, Neela Avudaiappan, Haoming Jiang, Tianyu Cao, Qingyu Yin, Yifan Gao, Zheng Li, Rahul Goutam, Haiyang Zhang, et al . 2022. Query attribute recommendation at amazon search. InProceedings of the 16th ACM conference on recommender systems. 506–508
2022
-
[24]
Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495–3503
2022
-
[25]
Paul Missault, Arnaud de Myttenaere, Andreas Radler, and Pierre-Antoine Sondag
-
[26]
Addressing cold start with dataset transfer in e-commerce learning to rank. (2021)
2021
-
[27]
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. Pinner- former: Sequence modeling for user representation at pinterest. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 3702–3712
2022
-
[28]
Massimo Quadrana, Alexandros Karatzoglou, Balázs Hidasi, and Paolo Cremonesi
-
[29]
Inproceedings of the Eleventh ACM Conference on Recommender Systems
Personalizing session-based recommendations with hierarchical recurrent neural networks. Inproceedings of the Eleventh ACM Conference on Recommender Systems. 130–137
-
[30]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[31]
Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey Hinton. 2007. Restricted Boltz- mann machines for collaborative filtering. InProceedings of the 24th international conference on Machine learning. 791–798
2007
-
[32]
Guy Shani, David Heckerman, and Ronen I Brafman. 2005. An MDP-based recommender system.Journal of machine Learning research6, Sep (2005), 1265– 1295
2005
-
[33]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[34]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[35]
Chun How Tan, Austin Chan, Malay Haldar, Jie Tang, Xin Liu, Mustafa Abdool, Huiji Gao, Liwei He, and Sanjeev Katariya. 2023. Optimizing airbnb search jour- ney with multi-task learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4872–4881
2023
-
[36]
Jie Tang, Huiji Gao, Liwei He, and Sanjeev Katariya. 2024. Multi-objective Learning to Rank by Model Distillation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5783–5792
2024
-
[37]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[38]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[39]
Andrew Trotman, Jon Degenhardt, and Surya Kallumadi. 2017. The Architecture of eBay Search.. IneCOM@ SIGIR. 88
2017
-
[40]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[41]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD’. 1–7
2017
-
[42]
Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James Sharpnack. 2020. SSE-PT: Sequential recommendation via personalized transformer. InProceedings of the 14th ACM conference on recommender systems. 328–337
2020
-
[43]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and Andrew Zhai. 2023. TransAct: Transformer-based Realtime User Ac- tion Model for Recommendation at Pinterest.Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(2023). https: //a...
2023
-
[44]
Feng Yu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2016. A dynamic recurrent model for next basket recommendation. InProceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 729–732
2016
-
[45]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yin-Hua Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Genera- tive Recommendations.ArXivabs/2402.17152 (2024). https://api.semanticscholar. org/CorpusID:268033327
Pith/arXiv arXiv 2024
-
[46]
Yipeng Zhang, Xin Wang, Hong Chen, and Wenwu Zhu. 2023. Adaptive disen- tangled transformer for sequential recommendation. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining. 3434–3445
2023
-
[47]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068. JourneyFormer: Encoding Airbnb Guest Journey with Sequence Modeling K...
2018
-
[48]
Peilin Zhou, Qichen Ye, Yueqi Xie, Jingqi Gao, Shoujin Wang, Jae Boum Kim, Chenyu You, and Sunghun Kim. 2023. Attention calibration for transformer- based sequential recommendation. InProceedings of the 32nd ACM international conference on information and knowledge management. 3595–3605
2023
-
[49]
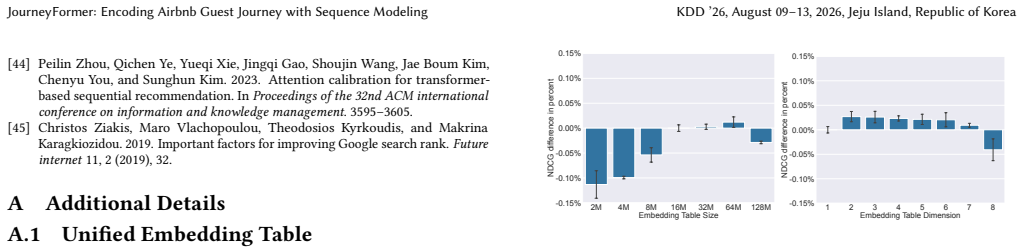
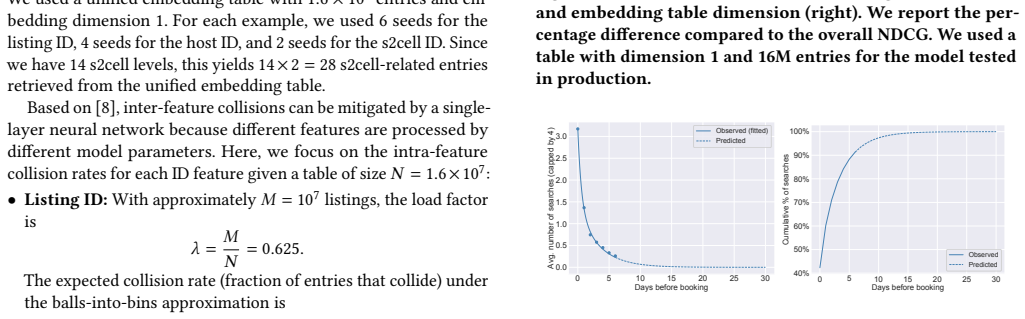
Christos Ziakis, Maro Vlachopoulou, Theodosios Kyrkoudis, and Makrina Karagkiozidou. 2019. Important factors for improving Google search rank.Future internet11, 2 (2019), 32. A Additional Details A.1 Unified Embedding Table We used a unified embedding table with1 .6 × 107 entries and em- bedding dimension 1. For each example, we used 6 seeds for the listi...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.