Auteur: Language-Driven Cinematographic Framing for Human-Centric Video Generation
Pith reviewed 2026-06-28 15:45 UTC · model grok-4.3
The pith
Auteur encodes camera shots as functions of human pose so language and motion produce deliberate cinematic trajectories for video generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
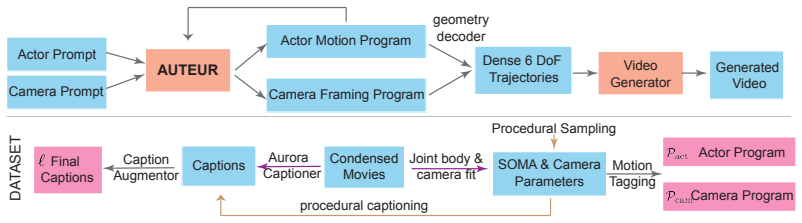
Professional filmmakers conceive shots relative to the actor, so a human-centric parameterization expressed in a DSL that converts to standard camera parameters, combined with an MLLM that maps language and motion to DSL keyframes, yields camera trajectories that support cinematographic framing where prior generative models produce only stochastic motion.
What carries the argument
A domain-specific language that encodes shot size, angle, and composition as functions of human pose and motion and converts deterministically to 6-DoF camera parameters.
If this is right
- Video generators receive explicit, subject-aware camera inputs instead of producing motion as a side effect of pixel synthesis.
- Users specify professional framing through natural language without designing 3D paths.
- Training can draw on annotated movie footage to supervise cinematic behavior directly.
- New framing-specific metrics become usable to quantify improvements beyond visual fidelity.
Where Pith is reading between the lines
- The same pose-relative encoding could support control over additional cinematic variables such as focus or lighting if extended.
- Real-time versions might enable interactive storyboarding or virtual production tools that respond to spoken direction.
- Limits would appear first on motions or compositions poorly represented in the 34K training set.
Load-bearing premise
Filmmakers' shot ideas can be captured reliably as functions of body pose and movement inside a DSL that a multimodal model can produce accurately from ordinary language and rough motion.
What would settle it
Generate videos on held-out human-centric scenes with and without the DSL trajectories and measure the proposed framing metrics; consistent failure to exceed baseline scores on shot-size and angle accuracy would refute the claim.
Figures

read the original abstract
Generative video models have achieved remarkable visual fidelity and temporal coherence, yet intentional camera control remains elusive. Existing frameworks treat camera motion as a byproduct of pixel synthesis, producing trajectories that are stochastic, spatially inconsistent, and indifferent to the human subject driving the scene. In this work, we present Auteur, a method for language-driven, human-centric camera framing in generative video. Our core insight is that professional filmmakers conceive shots not as world-space trajectories but as framings defined relative to the actor, encoding shot size, angle, and composition as functions of human pose and motion. We formalize this intuition as a human-centric camera parameterization and introduce a Domain-Specific Language (DSL) that is convertible to standard 6-DoF camera parameters. A fine-tuned multimodal large language model then acts as a virtual director, mapping natural language descriptions and coarse human motion to sparse DSL keyframes that are deterministically interpolated into continuous camera trajectories, which are then provided as input to video generators. We train and evaluate Auteur on a new dataset of 34K aligned text, human motion, and DSL-annotated camera trajectories drawn from procedural synthesis and real-world movie footage from the CondensedMovies dataset. Auteur enables cinematographic framing of human-centered scenes, a capability largely absent in prior generative models. To assess this behavior, we propose new framing-focused metrics, and our experiments show that Auteur consistently outperforms existing methods
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Auteur, a framework for language-driven cinematographic framing in human-centric generative video. It proposes a human-centric camera parameterization formalized via a Domain-Specific Language (DSL) that encodes shot size, angle, and composition as functions of human pose and motion and converts deterministically to 6-DoF camera parameters. A fine-tuned MLLM maps natural language descriptions plus coarse human motion to sparse DSL keyframes; these are interpolated into continuous trajectories supplied to existing video generators. The system is trained and evaluated on a new 34K dataset of aligned text, motion, and DSL annotations derived from procedural synthesis and CondensedMovies footage. New framing-focused metrics are proposed, and experiments claim consistent outperformance over prior methods.
Significance. If the MLLM-to-DSL mapping proves accurate and the new metrics meaningfully capture cinematographic intent, the work would address a recognized gap in controllable video generation by supplying intentional, human-relative camera control rather than stochastic trajectories. The 34K aligned dataset and the DSL itself constitute concrete, reusable contributions that could support follow-on research. The deterministic interpolation step is a methodological strength that avoids end-to-end fitting of camera parameters.
major comments (3)
- [Experiments] Experiments section: the central claim that Auteur 'consistently outperforms existing methods' on the proposed framing metrics is unsupported by any reported numerical values, definitions of the metrics, or ablation results; without these, the improvement cannot be assessed and the claim that the MLLM-DSL pipeline delivers cinematographically correct trajectories remains unverified.
- [Method] Method section (MLLM component): no quantitative validation is provided for MLLM prediction fidelity (DSL token accuracy, shot-size/angle error, or inter-keyframe consistency) against the 34K ground-truth annotations; this is the load-bearing step for the human-centric control claim, and its absence leaves the pipeline's correctness unestablished.
- [Dataset and DSL] Dataset and DSL definition: the manuscript does not specify the exact grammar of the DSL, the functional mapping from human pose/motion to framing parameters, or how the 34K annotations were obtained and validated, preventing verification that the conversion to 6-DoF parameters is deterministic and faithful to professional cinematography.
minor comments (2)
- [Abstract/Method] The abstract states that the DSL is 'convertible to standard 6-DoF camera parameters' but provides no explicit conversion equations or pseudocode; adding these would improve reproducibility.
- [Dataset] Clarify whether the 34K dataset is released and under what license; this is standard for dataset contributions in the field.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that several elements require expansion for clarity and verifiability. Below we address each major comment and commit to revisions that will incorporate the requested details, definitions, and results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that Auteur 'consistently outperforms existing methods' on the proposed framing metrics is unsupported by any reported numerical values, definitions of the metrics, or ablation results; without these, the improvement cannot be assessed and the claim that the MLLM-DSL pipeline delivers cinematographically correct trajectories remains unverified.
Authors: We acknowledge that the submitted manuscript presented the framing metrics and comparative results at a high level without sufficient numerical tables or ablations. In revision we will add precise metric definitions, full quantitative results tables, and ablation studies demonstrating the claimed improvements over baselines. revision: yes
-
Referee: [Method] Method section (MLLM component): no quantitative validation is provided for MLLM prediction fidelity (DSL token accuracy, shot-size/angle error, or inter-keyframe consistency) against the 34K ground-truth annotations; this is the load-bearing step for the human-centric control claim, and its absence leaves the pipeline's correctness unestablished.
Authors: We will include a new quantitative evaluation subsection reporting MLLM fidelity metrics (token-level accuracy, shot-size and angle errors, keyframe consistency) computed directly against the 34K ground-truth DSL annotations. revision: yes
-
Referee: [Dataset and DSL] Dataset and DSL definition: the manuscript does not specify the exact grammar of the DSL, the functional mapping from human pose/motion to framing parameters, or how the 34K annotations were obtained and validated, preventing verification that the conversion to 6-DoF parameters is deterministic and faithful to professional cinematography.
Authors: The revised manuscript will provide the complete DSL grammar, the explicit functional mappings from pose/motion to framing parameters, and a full account of the 34K dataset construction process including annotation sources, procedural generation details, and validation steps. revision: yes
Circularity Check
No circularity; pipeline is self-contained with external data and independent evaluation
full rationale
The derivation introduces a DSL and human-centric parameterization as the modeling choice, constructs a 34K dataset from procedural synthesis plus the external CondensedMovies corpus, fine-tunes an MLLM on that data, and reports empirical outperformance on newly proposed framing metrics. No equation or claim reduces by construction to a fitted quantity defined inside the method; the central capability claim rests on held-out performance against baselines rather than self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Professional filmmakers conceive shots as framings defined relative to the actor rather than world-space trajectories.
- domain assumption The DSL is convertible to standard 6-DoF camera parameters.
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575,
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575,
-
[2]
Condensed movies: Story based retrieval with contextual embeddings.CoRR, abs/2005.04208,
Max Bain, Arsha Nagrani, Andrew Brown, and Andrew Zisserman. Condensed movies: Story based retrieval with contextual embeddings.CoRR, abs/2005.04208,
arXiv 2005
-
[3]
Chenjie Cao, Jingkai Zhou, shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, and Yanwei Fu. Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation.arXiv preprint arXiv:2504.14899,
-
[4]
Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jeng-Neng Hwang, Saining Xie, and Christopher D. Manning. Auroracap: Efficient, performant video detailed captioning and a new benchmark.arXiv preprint arXiv:2410.03051,
-
[5]
Boosting camera motion control for video diffusion transformers
Soon Yau Cheong, Duygu Ceylan, Armin Mustafa, Andrew Gilbert, and Chun-Hao Paul Huang. Boosting camera motion control for video diffusion transformers. In36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27,
2025
-
[6]
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
-
[7]
Google DeepMind. Veo-3. https://blog.google/technology/ai/ generative-media-models-io-2025/,
2025
-
[8]
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. CameraCtrl II: Dynamic scene exploration via camera-controlled video diffusion models.ArXiv preprint arXiv:2503.10592,
-
[9]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
-
[10]
Soma: Unifying parametric human body models.arXiv preprint arXiv:2603.16858,
Jun Saito, Jiefeng Li, Michael de Ruyter, Miguel Guerrero, Edy Lim, Ehsan Hassani, Roger Blanco Ribera, Hyejin Moon, Magdalena Dadela, Marco Di Lucca, Qiao Wang, Xueting Li, Jan Kautz, Simon Yuen, and Umar Iqbal. Soma: Unifying parametric human body models.arXiv preprint arXiv:2603.16858,
-
[11]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
-
[12]
CineMaster: A 3d-aware and controllable framework for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. CineMaster: A 3d-aware and controllable framework for cinematic text-to-video generation. In SIGGRAPH, 2025a. Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild video...
Pith/arXiv arXiv 2024
-
[13]
Sixiao Zheng, Zimian Peng, Yanpeng Zhou, Yi Zhu, Hang Xu, Xiangru Huang, and Yanwei Fu. VidCRAFT3: Camera, object, and lighting control for image-to-video generation.ArXiv preprint arXiv:2502.07531,
-
[14]
Sixiao Zheng, Minghao Yin, Wenbo Hu, Xiaoyu Li, Ying Shan, and Yanwei Fu. Versecrafter: Dynamic realistic video world model with 4d geometric control.arXiv preprint arXiv:2601.05138,
-
[15]
A person walks forward; medium shot, frontal, eye-level
13 A Appendix A.1 Cinematography DSL We define a discrete DSL as a quantized, human-readable version of the human centric camera parameter space. As shown in Table A.1, each axis is equipped with a finite vocabulary of cinemato- graphically motivated tokens. Table A.1:Camera axes: continuous domains, discrete DSL vocabularies, and token-to-scalar mappings...
2026
-
[16]
Each clip is processed through a four-stage pipeline
15 A.4.2 Real-World Pipeline The real-world split contains Nreal tuples mined from CondensedMovies (Bain et al., 2020). Each clip is processed through a four-stage pipeline. (i) 3D reconstruction.Following TRAM (Wang et al., 2024a), a joint human-and-camera estimator recovers metric-scale global camera extrinsics {(Rt,t t)}T t=1 and per-frame SOMA body pa...
2020
-
[17]
Our proposed dataset is shown at the bottom
Table A.3:Dataset comparison.Comparison of various datasets with a focus on camera and human attributes. Our proposed dataset is shown at the bottom. Vocabulary Avg. Cap. Len. Dataset Camera Human Multi-Human #Frames #Samples Cam. Hum. Cam. Hum. DataDoP Zhang et al. (2025)✓× ×11M 29K 8698×86.2× E.T. Courant et al. (2024)✓ ✓×11M 115K 906×11.58× PulpMotion ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.