Multitask Learning for Blackmarket Tweet Detection
Pith reviewed 2026-05-24 23:57 UTC · model grok-4.3
The pith
A multitask learning framework with soft parameter sharing between classification and regression tasks detects blackmarket tweets at an F1-score of 0.89.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
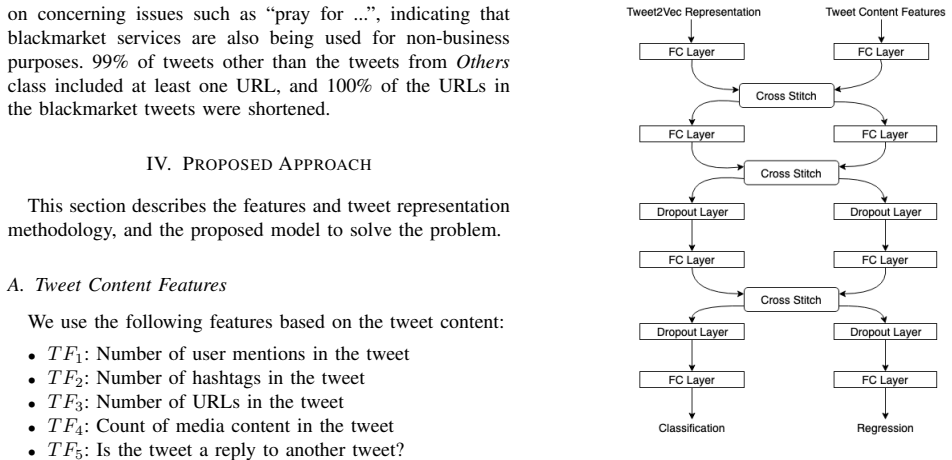
We use a multitask learning framework to leverage soft parameter sharing between a classification and a regression based task on separate inputs. This allows us to effectively detect tweets that have been posted to these blackmarket services, achieving an F1-score of 0.89 when classifying tweets as blackmarket or genuine.
What carries the argument
The multitask learning framework that performs soft parameter sharing between a classification task and a regression task on separate inputs.
Load-bearing premise
The separate inputs for the classification and regression tasks contain complementary signals that soft parameter sharing can usefully combine.
What would settle it
Training a single-task classification model on the same data and finding that its F1-score equals or exceeds 0.89 would show the multitask setup adds no benefit.
Figures
read the original abstract
Online social media platforms have made the world more connected than ever before, thereby making it easier for everyone to spread their content across a wide variety of audiences. Twitter is one such popular platform where people publish tweets to spread their messages to everyone. Twitter allows users to Retweet other users' tweets in order to broadcast it to their network. The more retweets a particular tweet gets, the faster it spreads. This creates incentives for people to obtain artificial growth in the reach of their tweets by using certain blackmarket services to gain inorganic appraisals for their content. In this paper, we attempt to detect such tweets that have been posted on these blackmarket services in order to gain artificially boosted retweets. We use a multitask learning framework to leverage soft parameter sharing between a classification and a regression based task on separate inputs. This allows us to effectively detect tweets that have been posted to these blackmarket services, achieving an F1-score of 0.89 when classifying tweets as blackmarket or genuine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multitask learning framework that applies soft parameter sharing between a classification task (blackmarket vs. genuine tweets) and a regression task on separate inputs to detect tweets posted to blackmarket services for artificial retweet boosting, reporting an F1-score of 0.89.
Significance. Detection of inorganic social media amplification is a relevant problem for platform integrity. If the claimed performance is supported by proper baselines, ablations, and dataset details, the multitask approach could offer a useful modeling strategy; however, the current presentation provides no such grounding, so significance cannot be assessed.
major comments (3)
- [Abstract] Abstract: the regression target is never defined and the two separate inputs are not described, so the central claim that soft parameter sharing exploits complementary signals cannot be evaluated or reproduced.
- [Abstract] Abstract: no dataset, collection procedure, class balance, or train/test split is provided, rendering the reported F1-score of 0.89 unverifiable and preventing any assessment of whether the multitask result exceeds standard single-task baselines.
- [Abstract] Abstract: no baseline models, ablation studies, or error analysis are mentioned, so it is impossible to attribute the 0.89 F1 to the multitask sharing mechanism rather than to the underlying features or data characteristics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires additional detail to clearly convey the model components, data, and evaluation. We will revise the abstract to incorporate summaries of these elements from the full manuscript while preserving its brevity. This will improve reproducibility and allow readers to assess the multitask contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: the regression target is never defined and the two separate inputs are not described, so the central claim that soft parameter sharing exploits complementary signals cannot be evaluated or reproduced.
Authors: We agree the abstract does not define the regression target or describe the inputs. The full manuscript specifies the classification task (blackmarket vs. genuine) and the regression task on separate inputs to capture complementary signals via soft parameter sharing. We will revise the abstract to explicitly state these elements so the central claim can be evaluated. revision: yes
-
Referee: [Abstract] Abstract: no dataset, collection procedure, class balance, or train/test split is provided, rendering the reported F1-score of 0.89 unverifiable and preventing any assessment of whether the multitask result exceeds standard single-task baselines.
Authors: We acknowledge the abstract omits dataset details. The manuscript contains a data section describing collection from blackmarket services, class balance, and the train/test split. We will add a concise summary of these to the abstract to make the F1-score verifiable and enable baseline comparisons. revision: yes
-
Referee: [Abstract] Abstract: no baseline models, ablation studies, or error analysis are mentioned, so it is impossible to attribute the 0.89 F1 to the multitask sharing mechanism rather than to the underlying features or data characteristics.
Authors: The abstract does not reference the experimental comparisons, but the manuscript reports single-task baselines, ablations on the sharing mechanism, and supporting analysis. We will revise the abstract to note that the multitask model achieves 0.89 F1 and outperforms the single-task baselines, thereby attributing gains to the proposed approach. revision: yes
Circularity Check
Empirical ML application with no derivation chain
full rationale
The paper reports an F1-score of 0.89 from training a multitask model with soft parameter sharing on tweet data. No equations, first-principles derivations, or fitted quantities are presented as predictions. The result is an experimental outcome on separate classification and regression tasks; it does not reduce to its inputs by definition, self-citation, or renaming. No load-bearing self-citations or ansatzes appear in the provided abstract or description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retweet us, we will retweet you: Spotting collusive retweeters involved in blackmarket services,
H. S. Dutta, A. Chetan, B. Joshi, and T. Chakraborty, “Retweet us, we will retweet you: Spotting collusive retweeters involved in blackmarket services,” in ASONAM. IEEE, 2018, pp. 242–249
work page 2018
-
[2]
Corerank: Rank- ing to detect users involved in blackmarket-based collusive retweeting activities,
A. Chetan, B. Joshi, H. S. Dutta, and T. Chakraborty, “Corerank: Rank- ing to detect users involved in blackmarket-based collusive retweeting activities,” in WSDM. ACM, 2019, pp. 330–338
work page 2019
-
[3]
Botornot: A system to evaluate social bots,
C. A. Davis, O. Varol, E. Ferrara, A. Flammini, and F. Menczer, “Botornot: A system to evaluate social bots,” in WWW. International World Wide Web Conferences Steering Committee, 2016, pp. 273–274
work page 2016
-
[4]
N. Shah, H. Lamba, A. Beutel, and C. Faloutsos, “The many faces of link fraud,” in ICDM. IEEE, 2017, pp. 1069–1074
work page 2017
-
[5]
Twitter spam detection based on deep learning,
T. Wu, S. Liu, J. Zhang, and Y . Xiang, “Twitter spam detection based on deep learning,” in Proceedings of the Australasian Computer Science Week Multiconference, 2017, pp. 3–10
work page 2017
-
[6]
Tweet2Vec: Character-Based Distributed Representations for Social Media
B. Dhingra, Z. Zhou, D. Fitzpatrick, M. Muehl, and W. W. Cohen, “Tweet2vec: Character-based distributed representations for social me- dia,” arXiv preprint arXiv:1605.03481 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Cross-stitch net- works for multi-task learning,
I. Misra, A. Shrivastava, A. Gupta, and M. Hebert, “Cross-stitch net- works for multi-task learning,” in CVPR, 2016, pp. 3994–4003
work page 2016
-
[8]
Detecting spam in a twitter network,
S. Yardi, D. Romero, G. Schoenebeck et al., “Detecting spam in a twitter network,” First Monday, vol. 15, no. 1, 2010
work page 2010
-
[9]
6 million spam tweets: A large ground truth for timely twitter spam detection,
C. Chen, J. Zhang, X. Chen, Y . Xiang, and W. Zhou, “6 million spam tweets: A large ground truth for timely twitter spam detection,” in ICC. IEEE, 2015, pp. 7065–7070
work page 2015
-
[10]
A survey of twitter ru- mor spreading simulations,
E. Serrano, C. A. Iglesias, and M. Garijo, “A survey of twitter ru- mor spreading simulations,” in Computational Collective Intelligence . Springer, 2015, pp. 113–122
work page 2015
-
[11]
Faking sandy: characterizing and identifying fake images on twitter during hurricane sandy,
A. Gupta, H. Lamba, P. Kumaraguru, and A. Joshi, “Faking sandy: characterizing and identifying fake images on twitter during hurricane sandy,” in WWW. ACM, 2013, pp. 729–736
work page 2013
-
[12]
Fake and spam messages: Detecting misin- formation during natural disasters on social media,
M. Rajdev and K. Lee, “Fake and spam messages: Detecting misin- formation during natural disasters on social media,” in WI-IAT, vol. 1, 2015, pp. 17–20
work page 2015
-
[13]
An analysis of underground forums,
M. Motoyama, D. McCoy, K. Levchenko, S. Savage, and G. M. V oelker, “An analysis of underground forums,” in SIGCOMM. ACM, 2011, pp. 71–80
work page 2011
-
[14]
Pay me and i’ll follow you: De- tection of crowdturfing following activities in microblog environment
Y . Liu, Y . Liu, M. Zhang, and S. Ma, “Pay me and i’ll follow you: De- tection of crowdturfing following activities in microblog environment.” in IJCAI, 2016, pp. 3789–3796
work page 2016
-
[15]
A survey on multi-task learning,
Y . Zhang and Q. Yang, “A survey on multi-task learning,” arXiv preprint arXiv:1707.08114, 2017
-
[16]
GIRNet: Interleaved Multi-Task Recurrent State Sequence Models
D. Gupta, T. Chakraborty, and S. Chakrabarti, “Girnet: Interleaved multi- task recurrent state sequence models,” arXiv preprint arXiv:1811.11456, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.