Prism Transformer: Progressive Head Schedules for Hierarchical Attention Processing
Pith reviewed 2026-06-29 01:14 UTC · model grok-4.3
The pith
A progressive increase in attention heads from early to late layers lets Transformers capture complex patterns early and specialize later on the same parameter count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
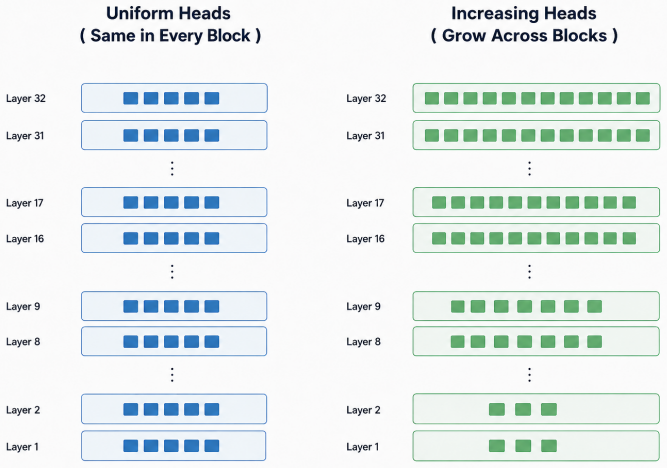
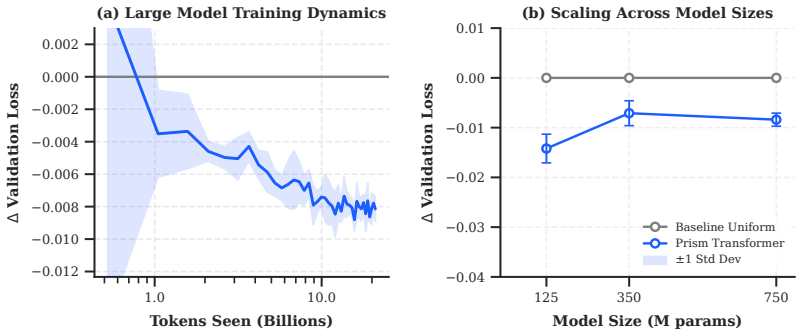
Multi-head attention normally divides the model dimension equally at every layer, so every head has the same small subspace dimension dh = dmodel/h. The Prism Transformer instead uses a monotonic increase in head count with depth. Early layers therefore receive fewer, wider heads that can represent high-dimensional local compositional patterns; later layers receive many narrow heads that decompose those patterns into specialized features. The resulting architecture is parameter-neutral and FLOP-neutral, yet yields consistent validation-loss reductions and downstream gains across 124 M, 354 M, and 757 M models.
What carries the argument
The progressive head schedule, which monotonically raises the number of heads layer by layer while keeping total parameters fixed.
If this is right
- Early layers can devote wider subspaces to local compositional patterns.
- Later layers can allocate many narrow subspaces to specialized linguistic features.
- Validation loss decreases at every tested scale without changing parameter or FLOP budgets.
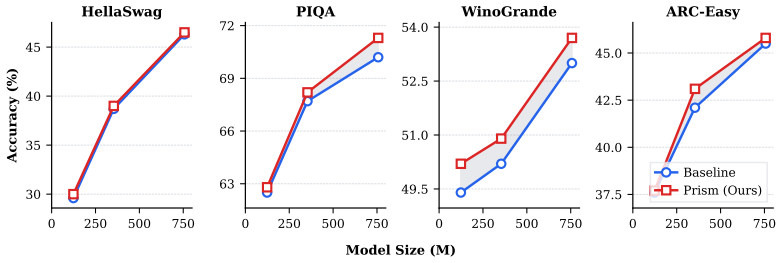
- Zero-shot accuracy rises on PIQA, HellaSwag, ARC-Easy, and WinoGrande under identical training conditions.
- Non-uniform subspace allocation extracts additional capacity from the standard Transformer design.
Where Pith is reading between the lines
- The same depth-varying allocation principle could be tested on feed-forward or other sub-layers without altering the attention mechanism itself.
- Because the change is drop-in and cost-free, it can be inserted into any existing Transformer training run to check whether the observed loss reduction scales to larger models.
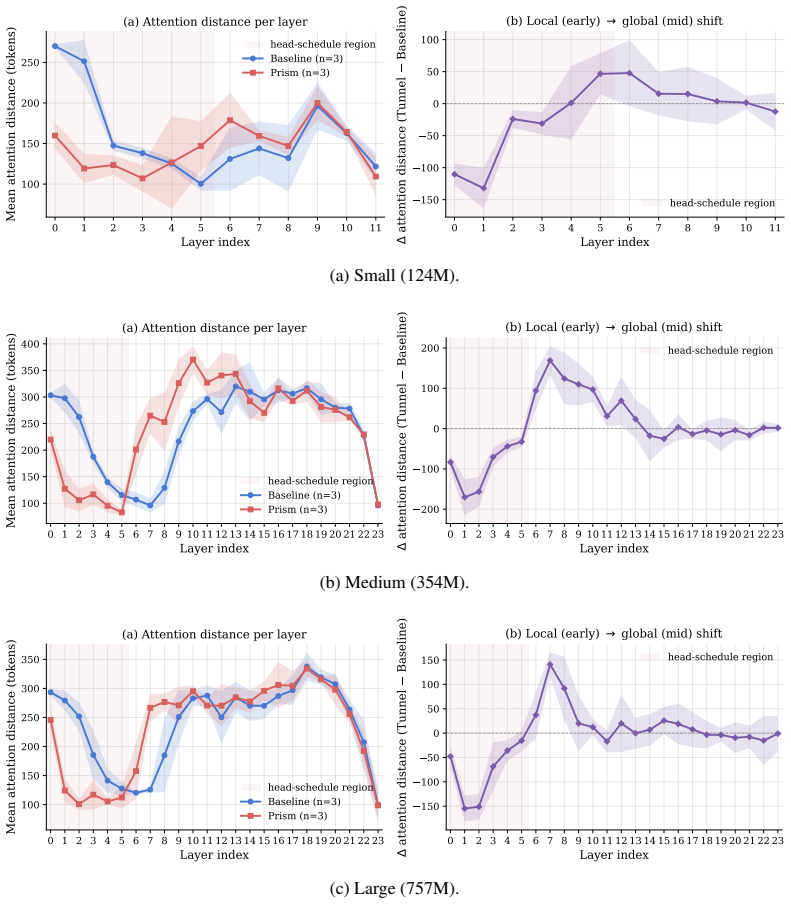
- The local-to-global hierarchy created by the schedule may produce attention maps that are easier to interpret at different depths.
Load-bearing premise
Early-layer heads cannot represent complex high-dimensional patterns when each is restricted to a small fixed subspace dimension.
What would settle it
Train matched 124 M, 354 M, and 757 M models with the progressive schedule versus the standard uniform schedule and measure whether validation loss and the listed zero-shot benchmarks show no consistent advantage for the progressive version.
Figures
read the original abstract
Multi-head attention conventionally partitions the hidden dimension equally across all heads at every layer, enforcing an identical representational subspace dimension (dh = dmodel/h) throughout the models depth. In this work, we identify this uniform allocation as a fundamental structural bottleneck: due to their restricted dimensional space, early-layer heads are unable to faithfully capture complex, high-dimensional contextual patterns. To resolve this, we introduce the Prism Transformer, a novel architectural paradigm that replaces the static, uniform head configuration with a progressive head schedule. By monotonically increasing the head count across layers, the Prism Transformer naturally establishes a local-to-global representational hierarchy: early layers leverage fewer, exceptionally wide heads to capture complex, local compositional patterns, while deep layers deploy many, narrow heads to decompose these patterns into specialized linguistic features. Crucially, this structural shift is parameter-neutral, compute-neutral, and introduces zero training or inference overhead, preserving identical weight matrices and FLOP budgets as the standard Transformer. Across three model scales (124M, 354M, and 757M), the Prism Transformer consistently outperforms uniform baselines, achieving consistent reductions in validation loss alongside consistent gains on downstream zero-shot benchmarks (including PIQA, HellaSwag, ARC-Easy, and WinoGrande). Our findings demonstrate that non-uniform subspace allocation unlocks latent capacity within the standard Transformer budget, enabling more effective use of model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Prism Transformer, which replaces uniform head allocation in multi-head attention with a progressive head schedule that monotonically increases the number of heads across layers. This is claimed to establish a local-to-global hierarchy (fewer, wider heads early for complex patterns; more, narrower heads later for decomposition), while remaining parameter-neutral and compute-neutral with identical weight matrices and FLOP budgets. Empirical results are reported to show consistent validation loss reductions and gains on zero-shot benchmarks (PIQA, HellaSwag, ARC-Easy, WinoGrande) across 124M, 354M, and 757M scales relative to uniform baselines.
Significance. If substantiated, the result would indicate that non-uniform subspace allocation can unlock latent capacity in standard Transformer budgets without added cost, providing a simple architectural lever for better capacity utilization. The parameter- and compute-neutral property is a clear strength, enabling apples-to-apples comparisons. However, the absence of experimental details and targeted ablations currently limits the strength of this assessment.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent outperformance' on validation loss and downstream benchmarks supplies no experimental details, baseline definitions, number of runs, statistical tests, or ablation results, so the data-to-claim link cannot be evaluated.
- [Abstract] Abstract: the hierarchy justification (early layers specifically require larger d_h to capture complex patterns) rests on comparison only to uniform baselines; no ablation on a reverse (monotonically decreasing) head schedule is reported, leaving it impossible to determine whether gains arise from the proposed direction or from non-uniformity in general.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' on validation loss and downstream benchmarks supplies no experimental details, baseline definitions, number of runs, statistical tests, or ablation results, so the data-to-claim link cannot be evaluated.
Authors: We agree the abstract would benefit from more supporting details. The full manuscript provides baseline definitions (standard Transformer with uniform head allocation at every layer), number of runs (three independent seeds with reported means and standard deviations), and statistical comparisons in Sections 4 and 5, with ablations in Section 6. In revision we will update the abstract to briefly reference these elements (e.g., 'across three runs on PIQA, HellaSwag, ARC-Easy, and WinoGrande') while preserving length constraints. revision: yes
-
Referee: [Abstract] Abstract: the hierarchy justification (early layers specifically require larger d_h to capture complex patterns) rests on comparison only to uniform baselines; no ablation on a reverse (monotonically decreasing) head schedule is reported, leaving it impossible to determine whether gains arise from the proposed direction or from non-uniformity in general.
Authors: The referee correctly notes that a reverse-schedule ablation would help isolate directionality. Our motivation for the increasing schedule is derived from the layer-wise analysis in Section 3, which argues that early layers require wider heads for high-dimensional pattern capture while later layers benefit from decomposition via narrower heads; this is not symmetric to a decreasing schedule. We will add an explicit discussion of this asymmetry and the rationale for focusing on the progressive direction in the revised manuscript. A full reverse ablation is not currently available and would require new experiments. revision: partial
Circularity Check
No circularity: performance claims rest on independent training runs
full rationale
The paper defines a progressive head schedule (monotonically increasing head count) and reports empirical validation loss and downstream gains versus uniform baselines across three model sizes. No equations, fitted parameters, or self-citations are invoked to derive the reported improvements; the gains are presented as observed training outcomes rather than tautological consequences of the definition. The local-to-global hierarchy description follows directly from the schedule definition but is not used to predict or force the performance numbers. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- progressive head schedule
axioms (1)
- domain assumption Multi-head attention remains functionally equivalent when head count and per-head dimension are traded off while keeping total dimension fixed.
invented entities (1)
-
Progressive head schedule
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, Sharan Wang, Aakanksha Bansal, Ankit Ramasamy, Jay Rao, and Illia Polo- sukhin. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Reddi, and Sanjiv Kumar
Srinadh Bhojanapalli, Chulhee Yun, Ankit Singh Rawat, Sashank J. Reddi, and Sanjiv Kumar. Low-rank bottleneck in multi-head attention models, 2020
2020
-
[3]
Piqa: Reasoning about physical commonsense in natural language, 2019
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language, 2019
2019
-
[4]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
2018
-
[5]
Reducing transformer depth on demand with structured dropout, 2019
Angela Fan, Edouard Grave, and Armand Joulin. Reducing transformer depth on demand with structured dropout, 2019
2019
-
[6]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[7]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
2022
-
[8]
nanogpt: The simplest, fastest repository for training/finetuning medium-sized gpts.https://github.com/karpathy/nanoGPT, 2022
Andrej Karpathy. nanogpt: The simplest, fastest repository for training/finetuning medium-sized gpts.https://github.com/karpathy/nanoGPT, 2022. GitHub repository. MIT License
2022
-
[9]
Pointer sentinel mixture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016
2016
-
[10]
Are sixteen heads really better than one?, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?, 2019
2019
-
[11]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[12]
Do vision transformers see like convolutional neural networks?, 2022
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?, 2022
2022
-
[13]
Winogrande: An adversarial winograd schema challenge at scale, 2019
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale, 2019
2019
-
[14]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[15]
Glu variants improve transformer, 2020
Noam Shazeer. Glu variants improve transformer, 2020
2020
-
[16]
Roformer: Enhanced transformer with rotary position embedding, 2023
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023
2023
-
[17]
Bert rediscovers the classical nlp pipeline, 2019
Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscovers the classical nlp pipeline, 2019
2019
-
[18]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017
2017
-
[19]
Analyzing the structure of attention in a transformer language model, 2019
Jesse Vig and Yonatan Belinkov. Analyzing the structure of attention in a transformer language model, 2019
2019
-
[20]
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned, 2019
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned, 2019
2019
-
[21]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. Blimp: The benchmark of linguistic minimal pairs for english, 2023
2023
-
[22]
Variable-width transformers, 2026
Zhaofeng Wu, Oliver Sieberling, Shawn Tan, Rameswar Panda, Yury Polyanskiy, and Yoon Kim. Variable-width transformers, 2026
2026
-
[23]
Hellaswag: Can a machine really finish your sentence?, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?, 2019. 10 A Downstream Benchmark Performance and Scale Dynamics We report the complete zero-shot downstream evaluation suite across all three model scales in Table 3. This includes benchmarks evaluating physical common sense (PIQA)...
2019
-
[24]
The Pareto Frontier of Hardware Alignment:Config-7 achieves the largest raw validation loss reduction (∆ = 0.0150 ), but it incurs a substantial hardware throughput penalty of −8.3%. This degradation occurs because an initial head count of 2 forces a per-head dimension of dh = 384, which violates the power-of-two matrix-tiling constraints required by opti...
-
[25]
The Primacy of Initial Subspace Width (h1):Isolating the starting head configurations reveals a clear trend: as the early attention layers are granted wider, more expressive channels, model performance scales monotonically. Comparing the multi-phase variants across identical layer budgets demonstrates that a starting head count of h1 = 6 (Config-2, ∆ = 0....
-
[26]
Staircase Smoothness Dictates Representation Stability:Abrupt structural shifts under- perform smoother transitions across depth. For example, transitioning aggressively from wide heads to baseline dimensions in a single step (Config 1 and Config-5) yields a lower improvement than smoother transitions (Prism and Config-7). Sustaining stable head di- mensi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.