Investigating Action Encodings in Recurrent Neural Networks in Reinforcement Learning
Pith reviewed 2026-05-20 23:22 UTC · model grok-4.3
The pith
Different methods for feeding actions into recurrent cell updates produce measurable differences in reinforcement learning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Several distinct ways exist to incorporate previous actions into the hidden-state update of a recurrent cell, and empirical comparisons of the resulting architectures on illustrative reinforcement learning domains reveal performance differences that arise from these choices.
What carries the argument
action incorporation into the recurrent state update function
If this is right
- Recurrent agents can achieve different levels of success depending on whether actions are concatenated, added, or otherwise combined with observations inside the cell update.
- Certain incorporation methods may prove more robust when observations are noisy or when actions have delayed effects.
- Future recurrent architectures intended for reinforcement learning should treat the action pathway as a first-class design decision rather than a default concatenation.
Where Pith is reading between the lines
- The same investigation could be repeated for other signals such as rewards or termination flags to see whether they produce comparable sensitivities.
- If one encoding consistently wins on simple domains, it becomes a natural candidate for transfer to large-scale agents that already use recurrence.
- The performance gaps may shrink or grow with network depth or with the length of the temporal dependencies the agent must capture.
Load-bearing premise
The simple illustrative domains used in the experiments capture the main difficulties recurrent networks encounter when deployed in practical reinforcement learning settings.
What would settle it
A follow-up study on a larger-scale partially observable control task in which every tested action incorporation method yields statistically indistinguishable final performance would undermine the claim that these design choices matter.
Figures
























read the original abstract
Building and maintaining state to learn policies and value functions is critical for deploying reinforcement learning (RL) agents in the real world. Recurrent neural networks (RNNs) have become a key point of interest for the state-building problem, and several large-scale reinforcement learning agents incorporate recurrent networks. While RNNs have become a mainstay in many RL applications, many key design choices and implementation details responsible for performance improvements are often not reported. In this work, we discuss one axis on which RNN architectures can be (and have been) modified for use in RL. Specifically, we look at how action information can be incorporated into the state update function of a recurrent cell. We discuss several choices in using action information and empirically evaluate the resulting architectures on a set of illustrative domains. Finally, we discuss future work in developing recurrent cells and discuss challenges specific to the RL setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates multiple distinct approaches for incorporating action information into the state-update function of recurrent cells in RNNs for reinforcement learning. It describes several architectural choices for action encoding, performs an empirical comparison of the resulting networks on a set of illustrative domains, and concludes with a discussion of future work and RL-specific challenges for recurrent architectures.
Significance. If the reported performance differences hold under replication, the work provides a useful, focused examination of an under-documented design axis in recurrent RL agents. By isolating action incorporation from other RNN modifications, the study can help practitioners understand why certain recurrent architectures succeed or fail in POMDP settings. The empirical framing on illustrative domains is a reasonable starting point for such an investigation, though the paper does not claim broad generalization.
minor comments (3)
- The abstract and introduction would benefit from explicitly naming the illustrative domains, the performance metrics, the baselines, and whether statistical significance testing was performed; without these details the reader cannot immediately assess the strength of the empirical claims.
- Section 4 (or the experimental section): clarify whether the reported results include error bars or multiple random seeds, and whether the same hyper-parameter search budget was allocated to each action-encoding variant.
- Notation: ensure that the mathematical description of each action-encoding variant (e.g., concatenation, gating, or embedding) is presented with consistent symbols so that differences between the variants are immediately visible.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending minor revision. The referee's summary accurately reflects the scope and contributions of the manuscript. As no specific major comments are provided in the report, we have no individual points to address below.
Circularity Check
No significant circularity in empirical investigation
full rationale
The paper presents an empirical investigation of different methods for incorporating action information into the state update of recurrent cells for RL. It discusses architectural choices and evaluates them experimentally on illustrative domains without any claimed mathematical derivations, predictions derived from fitted parameters, or self-referential definitions. The central claims rest on experimental comparisons rather than reducing to inputs by construction, making the work self-contained against external benchmarks with no load-bearing self-citations or ansatzes identified in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recurrent networks are a suitable mechanism for building state representations in partially observable RL problems.
Reference graph
Works this paper leans on
-
[1]
F. M. Bianchi, E. Maiorino, M. C. Kampffmeyer, A. Rizzi, and R. Jenssen. An overview and comparative analysis of recurrent neural networks for short term load forecasting.arXiv:1705.04378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym. arXiv:1606.01540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
16 Published in Transactions on Machine Learning Research (12/2022) S. Chandar, C. Sankar, E. Vorontsov, S. E. Kahou, and Y. Bengio. Towards Non-saturating Recurrent Units for Modelling Long-term Dependencies.Proceedings of the Association for the Advancement of AI Conference on Artificial Intelligence,
work page 2022
- [4]
- [5]
-
[6]
Memory-based control with recurrent neural networks
N. Heess, J. J. Hunt, T. P. Lillicrap, and D. Silver. Memory-based control with recurrent neural networks. arXiv:1512.04455,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
M. Innes. Don’t unroll adjoint: Differentiating ssa-form programs.arXiv:1810.07951, 2018a. M. Innes. Flux: Elegant machine learning with julia.Journal of Open Source Software, 2018b. M. Jaderberg, V. Mnih, W. M. Czarnecki, T. Schaul, J. Z. Leibo, D. Silver, and K. Kavukcuoglu. Reinforce- ment Learning with Unsupervised Auxiliary Tasks.International Confer...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Visualizing and Understanding Recurrent Networks
17 Published in Transactions on Machine Learning Research (12/2022) A. Karpathy, J. Johnson, and L. Fei-Fei. Visualizing and understanding recurrent networks.arXiv preprint arXiv:1506.02078,
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [9]
-
[10]
18 Published in Transactions on Machine Learning Research (12/2022) E. Parisotto, F. Song, J. Rae, R. Pascanu, C. Gulcehre, S. Jayakumar, M. Jaderberg, R. L. Kaufman, A. Clark, S. Noury, et al. Stabilizing transformers for reinforcement learning. InInternational Conference on Machine Learning,
work page 2022
-
[11]
A. Samani and R. S. Sutton. Learning agent state online with recurrent generate-and-test.arXiv preprint arXiv:2112.15236,
-
[12]
Learning to Predict Independent of Span
H. van Hasselt and R. S. Sutton. Learning to predict independent of span.arXiv preprint arXiv:1508.04582,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
19 Published in Transactions on Machine Learning Research (12/2022) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems 30,
work page 2022
-
[14]
P. Zhu, X. Li, P. Poupart, and G. Miao. On improving deep reinforcement learning for pomdps.arXiv preprint arXiv:1704.07978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
20 Published in Transactions on Machine Learning Research (12/2022) A Learning Long-Temporal Dependencies from Online Data Learning long-temporal dependencies is the primary concern of both RL and SL applications of recurrent networks. While great work has been done to coalesce around a few potential architectures and algorithms for SL settings, these are...
work page 2022
-
[16]
Not only do agents need to learn from the currently stored data (i.e. in an experience replay buffer), they must also continually incorporate the newest information into their decisions (i.e. update online and incrementally). The importance of learning state from an online stream of data has been heavily emphasized in the past through predictive represent...
work page 2002
-
[17]
and GVF networks (Schlegel et al., 2021), and in modeling trace patterning systems (Rafiee et al., 2022). From a supervised learning perspective, several problems like saturating capacity and catastrophic forgetting are cited as the most pressing for any parametric continual learning system (Sodhani et al., 2019). Below we suggest a few alternative direct...
work page 2021
-
[18]
in a single architecture. They show improvement in several settings, but don’t explore the model when starved for temporal information in the update. Another approach is through stimulating traces, as shown by Rafiee et al. (2022), where traces of observations are used to bridge the gap between different stimuli. Instead of traces, an objective which lear...
work page 2022
-
[19]
One can even change the requirements on the architecture in terms of final objectives
of the trajectory could provide similar benefits as a predictive objective. One can even change the requirements on the architecture in terms of final objectives. Mozer (1991) propose to predict only the contour or general trends of a temporal sequence, reducing the resolution considerably. Value functions are another object which takes an infinite sequen...
work page 1991
-
[20]
are one possible direction. Related to the generate and test idea, echo-state networks rely on a random fixed “reservoir” net- work, where predictions are made by only adjusting the outgoing weights. Because the recurrent architecture is fixed, no gradients flow through the recurrent connections meaning no BPTT is needed to estimate the gradients. Unfortu...
work page 1995
-
[21]
are a widely used alternative to recurrent architectures in natural language processing. Transformers have also shown some success in reinforcement learning but either require the full sequence of observations at inference and learning time (Mishra et al., 2018; Parisotto et al.,
work page 2018
-
[22]
or turn the RL problem into a supervised problem using the full return as the training signal (Chen et al., 2021). Because of these compromises, it is still unclear if transformers are a viable solution to the state construction problem in continual reinforcement learning. B Insight Beyond Learning Curves Learning curves showing the agent’s performance, u...
work page 2021
-
[23]
When does the agent make a decision, and does the agent 22 Published in Transactions on Machine Learning Research (12/2022) stick to this decision? We believe answering these questions and more can lead to better understanding of recurrent agents as well as pathways to better algorithms for training such agents. C Architectural Choices Below are several a...
work page 2022
-
[24]
warming up the agent from the beginning (or some number of time steps prior) of an episode (Hausknecht and Stone, 2015). We use a third strategy here (using gradient information to refresh the hidden state to minimize the objective), but found little difference between this and the stale approach. For much more insight and discussion on this choice see Ka...
work page 2015
-
[25]
A sweep over various number of experts and a simple gating network with a single layer and softmax activation. As compared to the additive and multiplicative the mixture of experts RNN network performs in-between the two networks. The GRU, on the other hand, fails to perform well in this domain. This might be related to the results seen in section 5.2.1, ...
work page 2022
-
[26]
For DirectionalTMaze the AAGRU and MAGRU have a reasonable median performance
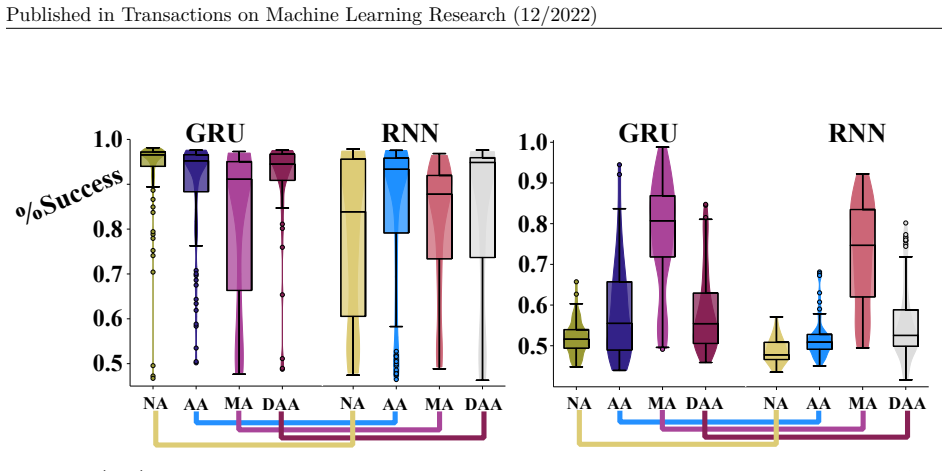
Compared to the replay setting, we can see all the variants performed worse across the board. For DirectionalTMaze the AAGRU and MAGRU have a reasonable median performance. The MARNN and FacGRU are the only other cells which have runs reaching good performance, but overall perform poorly. We expect initialization plays a large role in the networks perform...
work page 2022
-
[27]
First we provide results over various action encoding sizes for the Directional TMaze environment using the Deep Additive network from the main paper. Overall, we found the size of the encoding network to not make a large difference in the final performance. In effect, this result suggests there is still a core limitation with the deep additive operation ...
work page 2022
-
[28]
30 Published in Transactions on Machine Learning Research (12/2022) Parameter Value Steps 300,000 steps Optimizer RMSprop RMSProp RNN:η 0.01×(2.0(−11:2:−2)) RMSProp GRU:η 0.01×(2.0(−11:2:−6)) RMSpropρ 0.99 Discountγ 0.99 Truncationτ 12 Buffer Size 10000 Batch Size 8 Update freq 4 steps Target Network Freq 1000 steps Independent Runs 50 AAMA Fac AAMA FacNA...
work page 2022
-
[29]
34 Published in Transactions on Machine Learning Research (12/2022) Figure 25: Lunar Lander further results:(top left)Average final reward over the final10%of episodes for 20 runs(top middle)Total steps per episode for non-factored cells for 20 runs(top right)Total steps per episode for factored cells for 20 runs(bottom left)learning rate sensitivity curv...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.