CARE: Competence-Aware Reward Shaping for Adaptive Reasoning Length in Video-MLLMs
Pith reviewed 2026-06-26 17:54 UTC · model grok-4.3
The pith
CARE uses moving-average competence estimates to shift video reasoning models from long exploratory traces to short efficient ones during RL training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
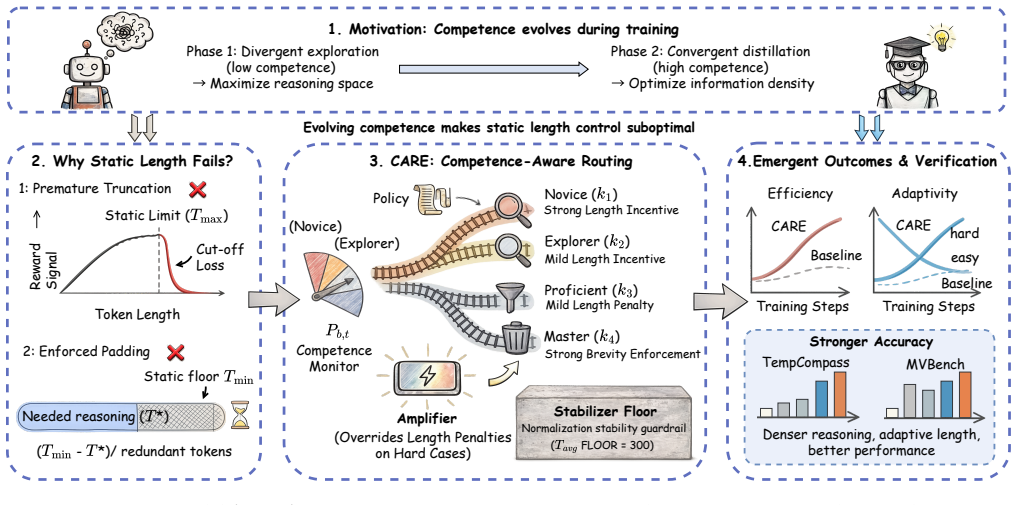
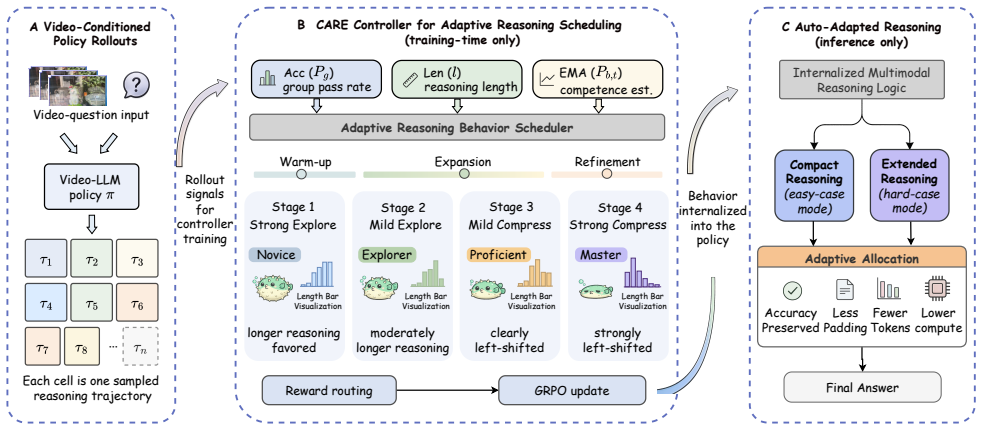
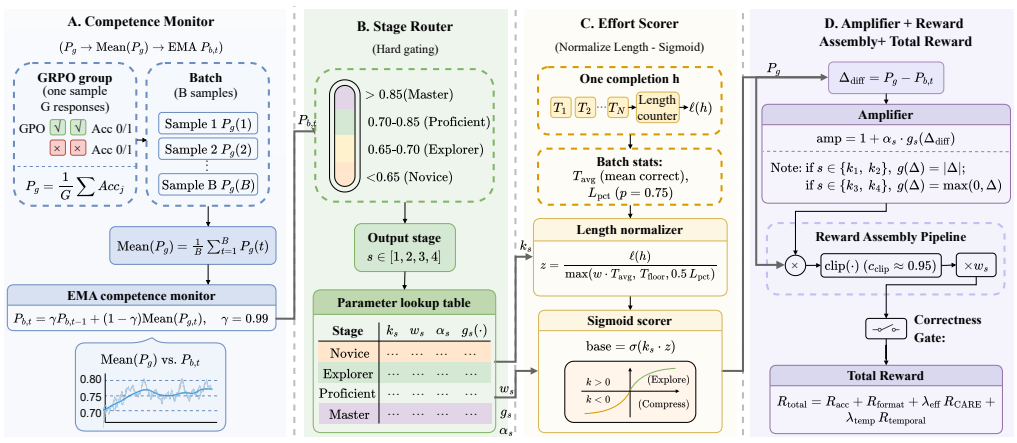
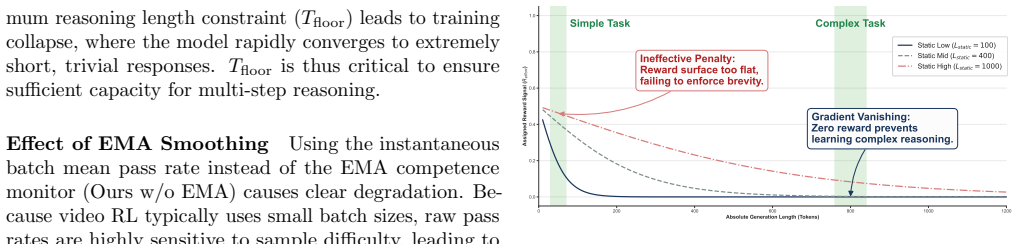
CARE maintains a smoothed competence estimate via an exponential moving average of pass rates and uses it to route training into progressive stages that shift the reward preference from exploration-oriented long-form reasoning to efficiency-oriented concise reasoning. To avoid conflating verbosity with task complexity, CARE normalizes reasoning effort with batch-level statistics and introduces a posterior amplifier to strengthen reward signals for unexpectedly strong performance on historically difficult samples. The mechanism integrates into the GRPO pipeline with no inference overhead and produces higher accuracy, more stable RL, greater token efficiency, an inverted-U reasoning-length tra
What carries the argument
Competence estimate from exponential moving average of pass rates that routes reward-shaping stages, normalizes effort at batch level, and amplifies posterior rewards on difficult samples.
If this is right
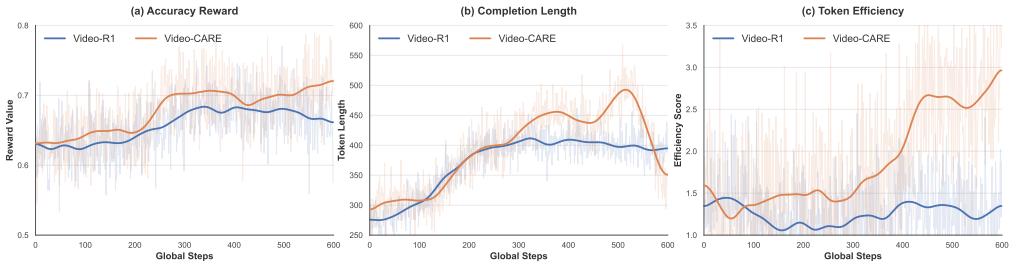
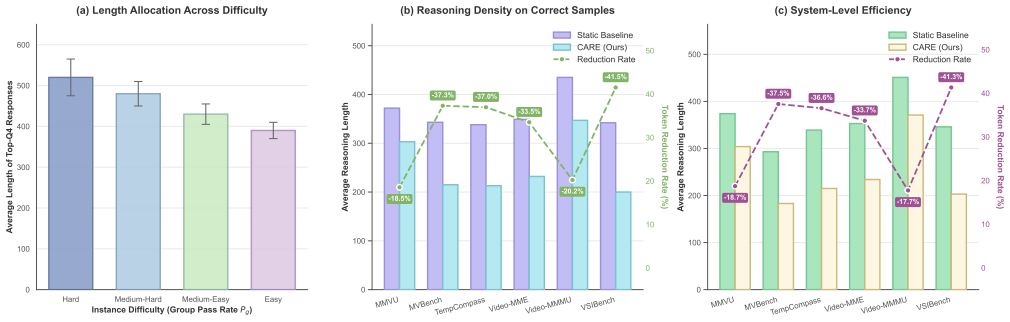
- Reasoning accuracy rises on video reasoning and general video understanding benchmarks.
- The reinforcement learning process becomes more stable during training.
- Token consumption drops substantially while output quality holds or improves.
- Reasoning length traces a characteristic inverted-U curve over the course of training.
- Final converged traces are shorter yet carry more task-relevant information.
Where Pith is reading between the lines
- The same competence-routing idea could be tested on text-only or image-only multimodal reasoning tasks to check whether the inverted-U pattern generalizes.
- If the batch-normalization step proves critical, replacing it with per-sample statistics might change the stability-accuracy trade-off.
- Deployed systems using CARE-trained models would likely need fewer compute resources per video query once the shorter traces are reached.
- A controlled study that varies only the posterior amplifier could isolate whether the boost on hard samples is what drives the final accuracy lift.
Load-bearing premise
An exponential moving average of pass rates gives a reliable, unconfounded measure of the model's intrinsic competence that can safely steer reward preferences without mixing verbosity with task difficulty.
What would settle it
Running the same GRPO pipeline with the competence router and posterior amplifier removed, then observing no gain in accuracy or token efficiency and no inverted-U pattern in reasoning length across repeated seeds, would falsify the central claim.
Figures
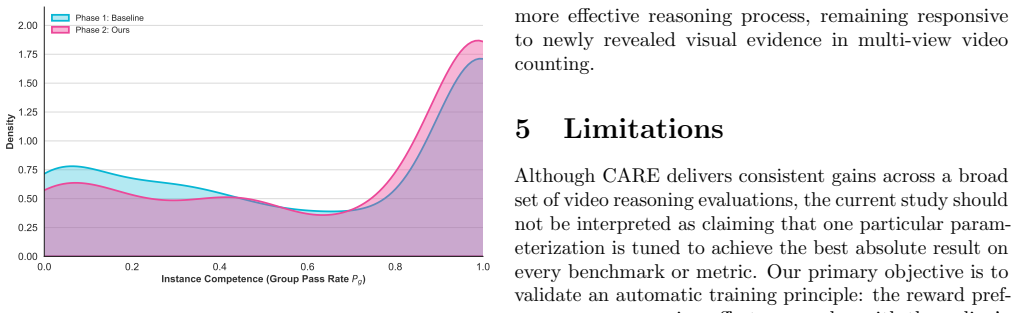
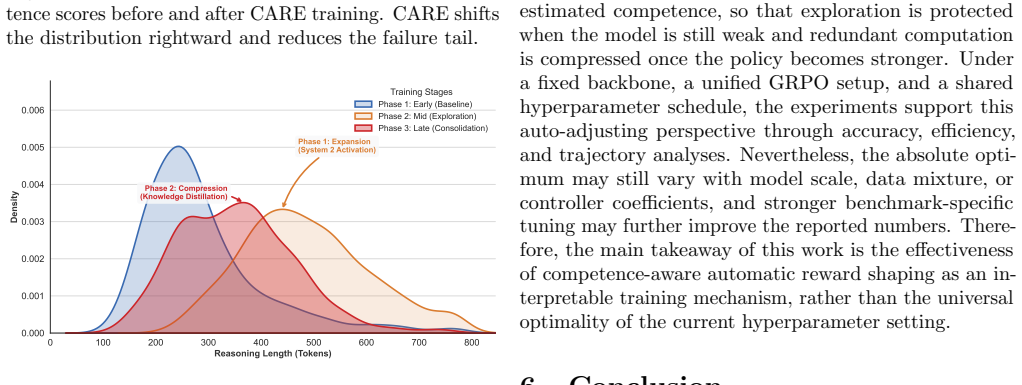

read the original abstract
In multimodal video reasoning, reinforcement learning-based methods typically rely on simplistic and inflexible reasoning-length control strategies that fail to adapt to the model's evolving competence. This mismatch may suppress necessary exploration at early stages, while encouraging redundant reasoning and inefficient decoding once the model becomes more competent. In this paper, we propose CARE, a competence-aware reward shaping framework for adaptive reasoning length optimization in multimodal reasoning. Specifically, CARE maintains a smoothed competence estimate via an exponential moving average of pass rates, and uses it to route training into progressive stages that shift the reward preference from exploration-oriented long-form reasoning to efficiency-oriented concise reasoning. To avoid conflating verbosity with intrinsic task complexity, CARE further normalizes reasoning effort with batch-level statistics, and introduces a posterior amplifier to strengthen reward signals for unexpectedly strong performance on historically difficult samples. The proposed mechanism is seamlessly integrated into the GRPO training pipeline and incurs no additional inference-time overhead. Extensive experiments on multiple video reasoning and general video understanding benchmarks demonstrate that CARE consistently improves reasoning accuracy, stabilizes reinforcement learning, and significantly enhances token efficiency. Moreover, CARE exhibits a characteristic inverted-U trajectory of reasoning length during training, and yields shorter yet more informative reasoning traces at convergence, indicating effective adaptive allocation of reasoning budget. We provide the source code for our proposed CARE framework and experiments at https://github.com/1Pansy/Video-CARE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CARE, a competence-aware reward shaping method integrated into GRPO for video-MLLMs. It computes an exponential moving average of pass rates as a competence signal to progressively route the reward from favoring long-form exploration to concise efficiency, augmented by batch-level normalization of reasoning effort and a posterior amplifier for strong performance on hard samples. The central claims are that this yields higher reasoning accuracy, more stable RL training, improved token efficiency, an inverted-U reasoning-length trajectory during training, and shorter yet more informative traces at convergence, with no inference overhead; source code is released.
Significance. If the empirical gains and trajectory hold under the proposed mechanism, CARE would provide a practical, training-only solution to the exploration-efficiency tradeoff in RL-based multimodal reasoning, a recurring issue in current video-MLLM pipelines. The release of reproducible code is a clear strength that enables direct verification and extension.
major comments (3)
- [§3.2, Eq. (3)–(5)] §3.2 (CARE mechanism) and Eq. (3)–(5): the competence estimate C_t is defined as an EMA of pass rates, yet the shaped reward R_t directly modulates the policy that produces those pass rates. The manuscript does not demonstrate that the lagged EMA breaks the feedback loop sufficiently to treat C_t as an independent measure of intrinsic competence rather than a function of the intervention itself; without an explicit independence argument or ablation that freezes the routing variable, the inverted-U trajectory and final efficiency gains could be artifacts of the closed loop.
- [§4.2, Table 2] §4.2 and Table 2: the reported accuracy and token-efficiency improvements are presented without error bars across random seeds or statistical significance tests against the GRPO baseline; given that the central claim is consistent improvement and stabilization, the absence of these quantities makes it impossible to judge whether the gains exceed run-to-run variance.
- [§3.3] §3.3 (posterior amplifier) and the batch-normalization step: these components are introduced to mitigate verbosity-task-complexity conflation, but no ablation isolates their contribution versus the EMA routing alone. If the amplifier or normalization is removed, does the inverted-U trajectory and accuracy gain persist? The current experimental design leaves this load-bearing design choice untested.
minor comments (2)
- [Abstract] The abstract states quantitative improvements but supplies no numerical values; the results section should include at least the headline deltas (accuracy, tokens) in the abstract or first paragraph of the introduction for immediate readability.
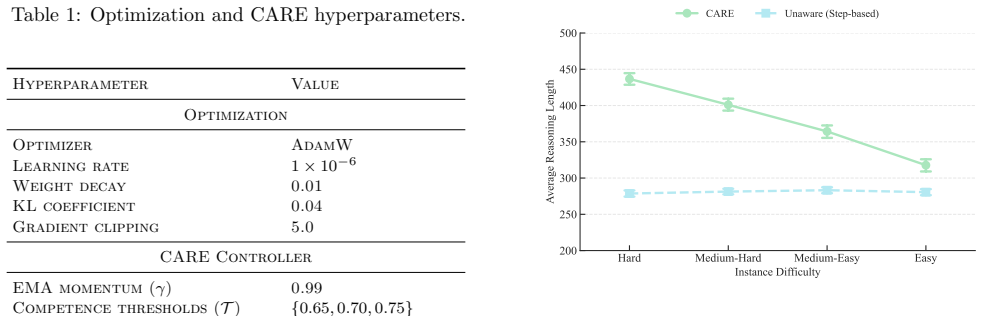
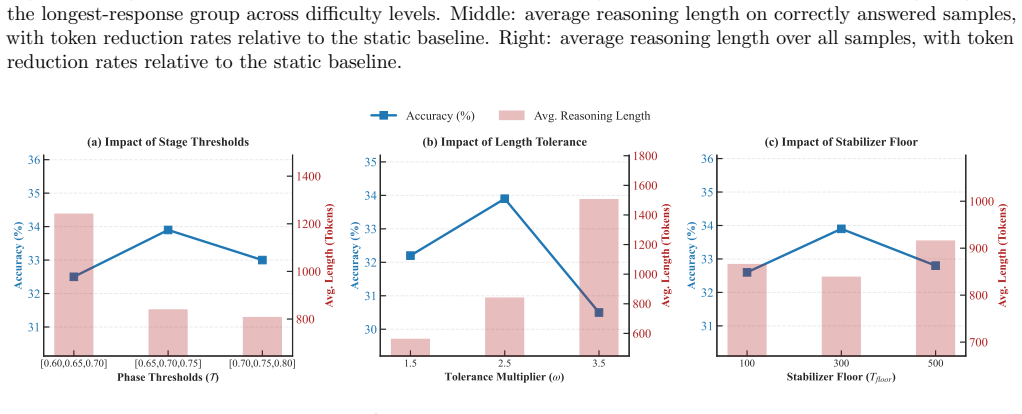
- [§3.2] Notation for the EMA smoothing factor α is introduced without a sensitivity study; a brief paragraph or appendix table showing performance for α ∈ {0.1, 0.5, 0.9} would clarify robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with plans for revisions where the concerns identify gaps in the current manuscript.
read point-by-point responses
-
Referee: [§3.2, Eq. (3)–(5)] §3.2 (CARE mechanism) and Eq. (3)–(5): the competence estimate C_t is defined as an EMA of pass rates, yet the shaped reward R_t directly modulates the policy that produces those pass rates. The manuscript does not demonstrate that the lagged EMA breaks the feedback loop sufficiently to treat C_t as an independent measure of intrinsic competence rather than a function of the intervention itself; without an explicit independence argument or ablation that freezes the routing variable, the inverted-U trajectory and final efficiency gains could be artifacts of the closed loop.
Authors: We acknowledge the validity of this concern about potential circularity. The EMA lag is intended to provide temporal decoupling, as C_t at step t is computed from pass rates up to t-1 and thus does not directly incorporate the immediate effect of the current shaped reward on the policy. However, the manuscript indeed lacks an explicit independence argument or a controlled ablation. In the revision we will add a short theoretical note in §3.2 explaining the lag-induced separation and include a new ablation that freezes the routing variable C to its initial value throughout training, allowing direct comparison of trajectories with and without the adaptive component. revision: yes
-
Referee: [§4.2, Table 2] §4.2 and Table 2: the reported accuracy and token-efficiency improvements are presented without error bars across random seeds or statistical significance tests against the GRPO baseline; given that the central claim is consistent improvement and stabilization, the absence of these quantities makes it impossible to judge whether the gains exceed run-to-run variance.
Authors: This is a fair criticism. The current results are reported from single runs, which does not permit assessment of variance. We will rerun the key experiments on the main benchmarks across at least three random seeds, report mean and standard deviation in the revised Table 2, and add pairwise statistical significance tests (e.g., paired t-tests) against the GRPO baseline to substantiate the claimed improvements. revision: yes
-
Referee: [§3.3] §3.3 (posterior amplifier) and the batch-normalization step: these components are introduced to mitigate verbosity-task-complexity conflation, but no ablation isolates their contribution versus the EMA routing alone. If the amplifier or normalization is removed, does the inverted-U trajectory and accuracy gain persist? The current experimental design leaves this load-bearing design choice untested.
Authors: We agree that isolating the contribution of batch normalization and the posterior amplifier is necessary. The manuscript currently presents only the full CARE configuration. In the revision we will add a dedicated ablation subsection that removes each component individually (and both together) while retaining the EMA routing, reporting accuracy, token counts, and reasoning-length trajectories for each variant. This will directly test whether the inverted-U pattern and final gains require the additional mechanisms. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper describes CARE as an engineering mechanism that computes an EMA of pass rates to route between exploration and efficiency rewards within the GRPO pipeline. No equations, derivations, or first-principles claims are present that reduce any prediction or result to its own inputs by construction. The competence estimate is explicitly an input to reward shaping rather than a derived output; empirical improvements and the inverted-U trajectory are reported as observed outcomes on external benchmarks. No self-citations, uniqueness theorems, or ansatzes are invoked. The feedback loop inherent to any RL reward design does not meet the enumerated circularity criteria of self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
free parameters (1)
- EMA smoothing factor
axioms (2)
- domain assumption Pass rates provide a valid proxy for model competence that can be used to stage reward preferences
- domain assumption Batch-level statistics can separate verbosity from intrinsic task complexity
Reference graph
Works this paper leans on
-
[1]
Multimodal chain-of-thought reasoning in language models,
Z. Zhang, A. Zhang, M. Li, H. Zhao, G. Karypis, and A. Smola, “Multimodal chain-of-thought reasoning in language models,”arXiv preprint arXiv:2302.00923, 2023
Pith/arXiv arXiv 2023
-
[2]
Multimodal chain-of-thought rea- soning,
Y. Wanget al., “Multimodal chain-of-thought rea- soning,”arXiv preprint arXiv:2503.12605, 2025
Pith/arXiv arXiv 2025
-
[3]
Video-r1: Rein- forcing video reasoning in mllms,
K. Feng, K. Gong, B. Li, Z. Guo, Y. Wang, T. Peng, B. Wang, and X. Yue, “Video-r1: Rein- forcing video reasoning in mllms,”arXiv preprint arXiv:2503.21776, 2025
Pith/arXiv arXiv 2025
-
[4]
J. Su, J. Healey, P. Nakov, and C. Cardie, “Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms,”arXiv preprint arXiv:2505.00127, 2025
arXiv 2025
-
[5]
Stop overthinking: A survey on efficient reasoning for large language models,
Y. Sui, Y.-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu, “Stop overthinking: A survey on efficient reasoning for large language models,”arXiv preprint arXiv:2503.16419, 2025
Pith/arXiv arXiv 2025
-
[6]
Thinking fast and right: Bal- ancing accuracy and reasoning length with adaptive rewards,
J. Su and C. Cardie, “Thinking fast and right: Bal- ancing accuracy and reasoning length with adaptive rewards,”arXiv preprint arXiv:2505.18298, 2025
arXiv 2025
-
[7]
Learn to reason efficiently with adap- tive length-based reward shaping,
W. Liuet al., “Learn to reason efficiently with adap- tive length-based reward shaping,”arXiv preprint arXiv:2505.15612, 2025
arXiv 2025
-
[8]
Modality 13 gap-driven subspace alignment training paradigm for multimodal large language models,
X. Yu, Y. Xin, W. Zhang, C. Liu, H. Zhao, X. Hu, X. Yu, Z. Qiao, H. Tang, X. Yanget al., “Modality 13 gap-driven subspace alignment training paradigm for multimodal large language models,”arXiv preprint arXiv:2602.07026, 2026
Pith/arXiv arXiv 2026
-
[9]
Visual description grounding reduces hallucinations and boosts reason- ing in lvlms,
S. Ghosh, C. K. R. Evuru, S. Kumar, U. Tyagi, O. Ni- eto, Z. Jin, and D. Manocha, “Visual description grounding reduces hallucinations and boosts reason- ing in lvlms,”arXiv preprint arXiv:2405.15683, 2024
arXiv 2024
-
[10]
Unicorn: Text-only data synthesis for vision language model training,
X. Yu, P. Ding, W. Zhang, S. Huang, S. Gao, C. Qin, K. Wu, Z. Fan, Z. Qiao, and D. Wang, “Unicorn: Text-only data synthesis for vision language model training,”arXiv preprint arXiv:2503.22655, 2025
Pith/arXiv arXiv 2025
-
[11]
Anonymous, “Thinking, less seeing? assessing am- plified hallucination in multimodal reasoning by rea- soning chain length and visual attention allocation,” arXiv preprint arXiv:2505.21523, 2025
arXiv 2025
-
[12]
Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning,
Q. Wang, Y. Yu, Y. Yuan, R. Mao, and T. Zhou, “Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning,”arXiv preprint arXiv:2505.12434, 2025
arXiv 2025
-
[13]
Visual-rft: Visual reinforce- ment fine-tuning,
Z. Liu, Z. Sun, Y. Zang, X. Dong, Y. Cao, H. Duan, D. Lin, and J. Wang, “Visual-rft: Visual reinforce- ment fine-tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2034–2044
2025
-
[14]
Reason-rft: Reinforcement fine-tuning for visual reasoning,
H. Tan, Y. Ji, X. Hao, M. Lin, P. Wang, Z. Wang, and S. Zhang, “Reason-rft: Reinforcement fine-tuning for visual reasoning,”arXiv preprint arXiv:2503.20752, 2025
arXiv 2025
-
[15]
Point-rft: Improving multimodal reason- ing with visually grounded reinforcement finetuning,
M. Ni, Z. Yang, L. Li, C.-C. Lin, K. Lin, W. Zuo, and L. Wang, “Point-rft: Improving multimodal reason- ing with visually grounded reinforcement finetuning,” arXiv preprint arXiv:2505.19702, 2025
arXiv 2025
-
[16]
V-star: Benchmarking video-llms on video spatio-temporal reasoning,
Z. Chenget al., “V-star: Benchmarking video-llms on video spatio-temporal reasoning,”arXiv preprint arXiv:2503.11495, 2025
arXiv 2025
-
[17]
Llama-vid: An image is worth 2 tokens in large language models,
Y. Li, C. Wang, and J. Jia, “Llama-vid: An image is worth 2 tokens in large language models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 323–340
2024
-
[18]
Videol- lama 2: Advancing spatial-temporal modeling and audio understanding in video-llms,
Z. Cheng, S. Leng, H. Zhang, Y. Xin, X. Li, G. Chen, Y. Zhu, W. Zhang, Z. Luo, D. Zhaoet al., “Videol- lama 2: Advancing spatial-temporal modeling and audio understanding in video-llms,”arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[19]
Long context transfer from language to vision,
P. Zhang, K. Zhang, B. Li, G. Zeng, J. Yang, Y. Zhang, Z. Wang, H. Tan, C. Li, and Z. Liu, “Long context transfer from language to vision,”arXiv preprint arXiv:2406.16852, 2024
Pith/arXiv arXiv 2024
-
[20]
Vila: On pre-training for visual language models,
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han, “Vila: On pre-training for visual language models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 689–26 699
2024
-
[21]
Unhackable temporal rewarding for scalable video mllms,
E. Yu, K. Lin, L. Zhao, Y. Wei, Z. Zhu, H. Wei, J. Sun, Z. Ge, X. Zhang, J. Wanget al., “Unhackable temporal rewarding for scalable video mllms,”arXiv preprint arXiv:2502.12081, 2025
arXiv 2025
-
[22]
Llava- onevision: Easy visual task transfer,
B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y. Li, Z. Liuet al., “Llava- onevision: Easy visual task transfer,”arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[23]
Kangaroo: A powerful video-language model supporting long-context video input,
J. Liu, Y. Wang, H. Ma, X. Wu, X. Ma, X. Wei, J. Jiao, E. Wu, and J. Hu, “Kangaroo: A powerful video-language model supporting long-context video input,”International Journal of Computer Vision, vol. 134, no. 3, p. 114, 2026
2026
-
[24]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2.5- vl technical report,”arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[25]
Deepvideo-r1: Video reinforcement fine-tuning via difficulty-aware regressive grpo,
J. Park, J. Na, J. Kim, and H. J. Kim, “Deepvideo-r1: Video reinforcement fine-tuning via difficulty-aware regressive grpo,”arXiv preprint arXiv:2506.07464, 2025
arXiv 2025
-
[26]
Tinyllava- video-r1: Towards smaller lmms for video reasoning,
X. Zhang, S. Wen, W. Wu, and L. Huang, “Tinyllava- video-r1: Towards smaller lmms for video reasoning,” arXiv preprint arXiv:2504.09641, 2025
arXiv 2025
-
[27]
Reinforcement learning tuning for videollms: Reward design and data efficiency,
H. Li, S. Han, Y. Liao, J. Luo, J. Gao, S. Yan, and S. Liu, “Reinforcement learning tuning for videollms: Reward design and data efficiency,”arXiv preprint arXiv:2506.01908, 2025
arXiv 2025
-
[28]
Video-com: Interactive video reasoning via chain of manipulations,
H. Rasheed, M. Zumri, M. Maaz, M.-H. Yang, F. S. Khan, and S. Khan, “Video-com: Interactive video reasoning via chain of manipulations,”arXiv preprint arXiv:2511.23477, 2025
arXiv 2025
-
[29]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 632–10 643
2025
-
[30]
Video-mmmu: Evaluating knowl- edge acquisition from multi-discipline professional videos,
K. Hu, P. Wu, F. Pu, W. Xiao, Y. Zhang, X. Yue, B. Li, and Z. Liu, “Video-mmmu: Evaluating knowl- edge acquisition from multi-discipline professional videos,”arXiv preprint arXiv:2501.13826, 2025
Pith/arXiv arXiv 2025
-
[31]
Mmvu: Measur- ing expert-level multi-discipline video understanding,
Y. Zhao, H. Zhang, L. Xie, T. Hu, G. Gan, Y. Long, Z. Hu, W. Chen, C. Li, Z. Xuet al., “Mmvu: Measur- ing expert-level multi-discipline video understanding,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 8475–8489. 14
2025
-
[32]
Mvbench: A comprehensive multi-modal video understanding benchmark,
K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, Y. Liu, Z. Wang, J. Xu, G. Chen, P. Luoet al., “Mvbench: A comprehensive multi-modal video understanding benchmark,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2024, pp. 22 195–22 206
2024
-
[33]
Tempcompass: Do video llms really understand videos?
Y. Liu, S. Li, Y. Liu, Y. Wang, S. Ren, L. Li, S. Chen, X. Sun, and L. Hou, “Tempcompass: Do video llms really understand videos?” inFindings of the As- sociation for Computational Linguistics: ACL 2024, 2024, pp. 8731–8772
2024
-
[34]
Video- mme: The first-ever comprehensive evaluation bench- mark of multi-modal llms in video analysis,
C. Fu, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y. Shen, M. Zhanget al., “Video- mme: The first-ever comprehensive evaluation bench- mark of multi-modal llms in video analysis,” inPro- ceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 24 108–24 118. 15
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.