TASER: Task-Aware Stein Regularisation for Geometry-Driven Robustness
Pith reviewed 2026-06-29 08:08 UTC · model grok-4.3
The pith
Penalizing pointwise Stein residuals induces data-aware smoothness that improves adversarial robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
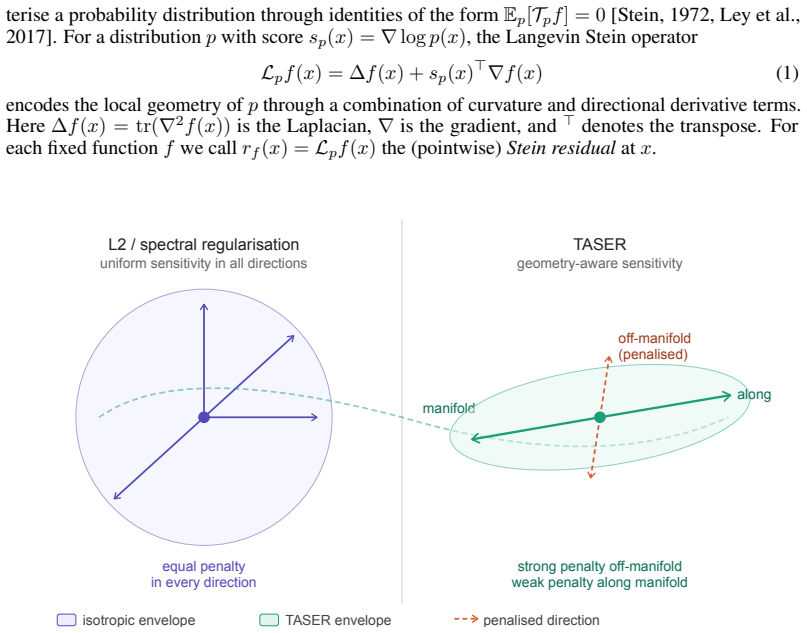
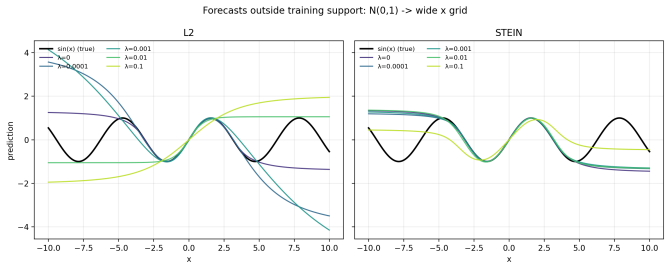
TASER is a training-time regularization framework derived from Langevin Stein operators. By penalising pointwise Stein residuals under the training distribution, TASER encourages geometric compatibility between predictors and data density, inducing anisotropic, data-aware smoothness. Theoretical links are established between Stein regularisation and reduced first-order shift sensitivity. Scalable implementation variants are developed and shown to improve robustness and stability across regression and vision benchmarks, including consistent gains in adversarial robustness on CIFAR-10 without statistically significant clean-accuracy degradation.
What carries the argument
The pointwise Stein residual penalty under the training distribution, obtained from the Langevin Stein operator, which enforces geometric compatibility between the predictor and the data density.
If this is right
- TASER can be added to established training pipelines to raise adversarial robustness on CIFAR-10.
- The same penalty produces gains on both regression and vision tasks without statistically significant clean-accuracy loss.
- Scalable variants exist that remain compatible with modern deep architectures.
- The construction supplies a direct mechanism for lowering first-order sensitivity to distribution shift.
Where Pith is reading between the lines
- The same residual penalty could be tested on tasks outside vision and regression where density estimation is feasible.
- If the geometric-compatibility effect persists at larger scales, TASER may reduce reliance on explicit adversarial data augmentation.
- The approach supplies a density-aware alternative to isotropic smoothness penalties such as weight decay.
Load-bearing premise
The theoretical connection between penalizing pointwise Stein residuals and reduced first-order shift sensitivity holds for the network architectures and loss functions used in the reported benchmarks.
What would settle it
An experiment in which adding the TASER penalty to standard training on CIFAR-10 produces no measurable increase in adversarial robustness metrics while clean accuracy remains unchanged would falsify the central practical claim.
Figures
read the original abstract
Modern deep networks remain fragile under distribution shift and adversarial perturbations, often due to excessive or poorly structured input sensitivity. We introduce TASER (Task-Aware Stein Regularisation), a training-time regularisation framework derived from Langevin Stein operators. By penalising pointwise Stein residuals under the training distribution, TASER encourages geometric compatibility between predictors and data density, inducing anisotropic, data-aware smoothness. We provide theoretical links between Stein regularisation and reduced first-order shift sensitivity, develop scalable implementation variants compatible with modern architectures, and demonstrate improved robustness and stability across regression and vision benchmarks. Across CIFAR-10 experiments, TASER consistently improves the adversarial robustness of established training methods without incurring statistically significant clean-accuracy degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TASER, a training-time regularization framework derived from Langevin Stein operators. By penalizing pointwise Stein residuals under the training distribution, it aims to encourage geometric compatibility between predictors and data density, inducing anisotropic data-aware smoothness. The paper claims theoretical links to reduced first-order shift sensitivity, develops scalable implementation variants for modern architectures, and reports improved adversarial robustness on CIFAR-10 (and other regression/vision benchmarks) without statistically significant clean-accuracy degradation when added to established training methods.
Significance. If the claimed theoretical connections between Stein residuals and shift sensitivity hold and the CIFAR-10 gains are reproducible with proper statistical controls, the framework could supply a principled, geometry-driven route to robustness that is compatible with existing pipelines. The absence of clean-accuracy trade-offs would be practically relevant.
minor comments (1)
- The abstract states theoretical links and empirical gains but supplies no derivation steps, error bars, or dataset details; the central claim cannot be evaluated from the given text.
Simulated Author's Rebuttal
We thank the referee for their summary of TASER and for noting the conditions under which the work could be significant. We acknowledge the 'uncertain' recommendation and the emphasis on verifying the theoretical connections to shift sensitivity as well as ensuring reproducible CIFAR-10 gains with proper controls. No specific major comments were listed in the report, so we have no point-by-point responses at this stage. We remain available to supply additional theoretical clarifications, statistical details, or reproducibility information to address the uncertainty.
Circularity Check
No significant circularity detected
full rationale
The abstract introduces TASER as derived from Langevin Stein operators with theoretical links to reduced shift sensitivity, but supplies no equations, fitting procedures, or self-citations that could be inspected for reduction to inputs by construction. No load-bearing derivation steps are visible, and the central empirical claim on CIFAR-10 robustness gains is presented as experimentally demonstrated rather than tautological. The derivation chain cannot be assessed as circular from the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alhussein Fawzi, Hamza Fawzi, and Pascal Frossard
URLhttps://proceedings.mlr.press/v119/croce20b.html. Alhussein Fawzi, Hamza Fawzi, and Pascal Frossard. Analysis of classifiers’ robustness to adversarial perturbations.Machine Learning, 107:481–508, 2018. doi: 10.1007/s10994-017-5663-3. Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis. Journal of the American Mat...
-
[2]
URLhttps://openreview.net/forum?id=SyUkxxZ0b. Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations, 2015. URL https://arxiv. org/abs/1412.6572. Jackson Gorham and Lester Mackey. Measuring sample quality with Stein’s method. InAdvances in Neural Inf...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr.2016.90 2015
-
[3]
Daniel Jakubovitz and Raja Giryes
doi: 10.1080/03610918908812806. Daniel Jakubovitz and Raja Giryes. Improving dnn robustness to adversarial attacks using jacobian regularization. InEuropean Conference on Computer Vision, pages 514–529. Springer, 2018. doi: 10.1007/978-3-030-01258-8 31. Michał Kozyra and Gesine Reinert. TASTE: Task-aware out-of-distribution detection via Stein operators, ...
-
[4]
Jonathan Uesato, Brendan O’Donoghue, Aaron van den Oord, and Pushmeet Kohli
URLhttps://openreview.net/forum?id=SyxAb30cY7. Jonathan Uesato, Brendan O’Donoghue, Aaron van den Oord, and Pushmeet Kohli. Adversarial risk and the dangers of evaluating against weak attacks. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 5032–5041. PMLR, 2018. URLhttps:...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.