Anchor3R: Streaming 3D Reconstruction with Transient Anchors for Long-Horizon Visual Mapping
Pith reviewed 2026-06-28 07:01 UTC · model grok-4.3
The pith
Anchor3R reconstructs long video sequences by predicting local poses and points relative to the current frame then aligning them globally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Anchor3R reframes feed-forward reconstruction as the generation of current-centric local measurements rather than persistent global-gauge regression; at each step it outputs window-relative poses and a local pointmap in the coordinate system of the present frame, after which loop-closure reinsertion and motion averaging convert those measurements into an aligned global reconstruction.
What carries the argument
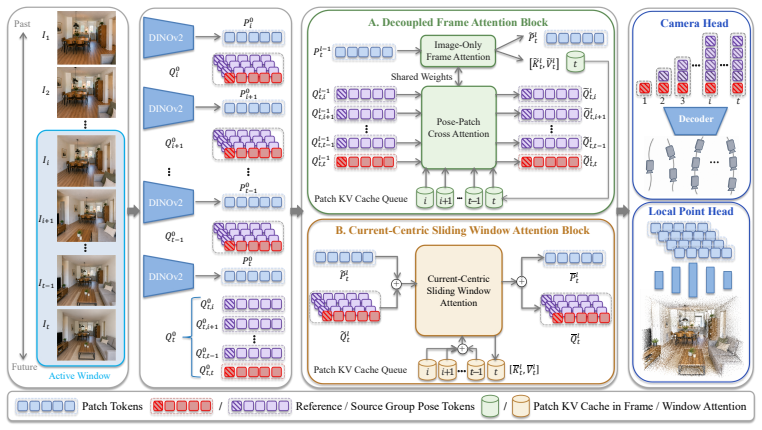
Transient anchors that encode window-relative poses and local pointmaps predicted in the current-frame coordinate system, which are later aligned by loop-closure reinsertion and motion averaging.
If this is right
- Sequences much longer than the training clips can be processed without the attention bias toward early frames that fixed-gauge models exhibit.
- Memory use stays bounded because no persistent global scene memory is maintained across time steps.
- Dense pointmap quality improves on indoor, outdoor, driving, and RGB-D benchmarks compared with prior streaming methods.
- Online inference remains feasible on resource-limited platforms because each prediction step is local.
Where Pith is reading between the lines
- The same current-centric measurement strategy could be tested on other feed-forward reconstruction networks to check whether the gain is architecture-specific or general.
- If alignment remains reliable, hybrid pipelines that combine the local predictions with classical bundle adjustment might further reduce residual drift.
- The approach suggests that training objectives for streaming models should emphasize relative rather than absolute coordinate regression.
Load-bearing premise
Local measurements made in the current frame can be aligned into one consistent global map by loop closure and motion averaging without adding new drift or inconsistencies on long sequences.
What would settle it
A long video sequence on which the final global map built from current-frame measurements shows higher pose error or lower reconstruction quality than a fixed-gauge streaming baseline run on the same data.
Figures
read the original abstract
Long-horizon online visual mapping is a core capability for robot perception, requiring continuous camera-motion and scene-geometry estimation from visual streams under bounded memory and computation. Recent feed-forward 3D reconstruction models provide strong geometric priors, but their streaming variants often predict poses in a fixed coordinate system tied to the first frame or a persistent scene memory. This fixed-gauge design leads to train--test mismatch, attention bias toward early anchors, and accumulated drift on sequences much longer than those seen during training. We propose \emph{Anchor3R}, a streaming 3D reconstruction framework that treats feed-forward reconstruction as current-centric local measurement prediction rather than persistent global-gauge regression. At each time step, Anchor3R predicts window-relative poses and a local pointmap in the current-frame coordinate system, turning streaming reconstruction into relative-pose measurement generation. These measurements support online pose updates, while loop-closure reinsertion and motion averaging align the trajectory and transform local pointmaps into a coherent global reconstruction. Experiments on indoor, outdoor, driving, and RGB-D benchmarks show that Anchor3R improves long-horizon pose accuracy and dense reconstruction quality over existing streaming baselines, while supporting bounded-memory online inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Anchor3R, a streaming 3D reconstruction method that reframes feed-forward models as generators of current-centric local measurements (window-relative poses and local pointmaps) rather than fixed-gauge global outputs. These measurements are aligned into a coherent global reconstruction via loop-closure reinsertion and motion averaging. The central claim is that this transient-anchor design reduces drift on long-horizon sequences, supports bounded-memory online inference, and yields better pose accuracy plus dense reconstruction quality than existing streaming baselines across indoor, outdoor, driving, and RGB-D benchmarks.
Significance. If the empirical gains are reproducible, the approach would be significant for robot perception by mitigating train-test mismatch and attention bias to early frames that plague persistent-memory streaming methods. The decomposition into relative measurements plus standard alignment is internally consistent with the bounded-memory goal and does not rely on unstated axioms.
major comments (2)
- [Abstract] Abstract: the central empirical claim of improved long-horizon pose accuracy and reconstruction quality is stated without any quantitative metrics, error tables, sequence lengths, or experimental protocol, which is load-bearing for assessing whether the alignment step actually delivers the promised gains without new drift.
- [Experiments] Experiments (implied by abstract claims): the paper must demonstrate via ablations or analysis that loop-closure reinsertion plus motion averaging does not introduce inconsistency or additional drift on sequences longer than the training horizon, as this is the weakest link in the stated pipeline.
minor comments (1)
- The title uses 'Transient Anchors' but the abstract does not define the term or contrast it explicitly with persistent anchors; a short definition or figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of improved long-horizon pose accuracy and reconstruction quality is stated without any quantitative metrics, error tables, sequence lengths, or experimental protocol, which is load-bearing for assessing whether the alignment step actually delivers the promised gains without new drift.
Authors: We agree that the abstract would benefit from quantitative support. In revision we will insert concise metrics (e.g., average ATE reduction and reconstruction F-score gains on sequences of 500–2000 frames) drawn directly from the experimental tables, together with a brief statement of the evaluation protocol. revision: yes
-
Referee: [Experiments] Experiments (implied by abstract claims): the paper must demonstrate via ablations or analysis that loop-closure reinsertion plus motion averaging does not introduce inconsistency or additional drift on sequences longer than the training horizon, as this is the weakest link in the stated pipeline.
Authors: The manuscript already reports results on sequences substantially longer than the training horizon and shows lower drift than persistent-memory baselines. However, we acknowledge that explicit ablations isolating the incremental effect of loop-closure reinsertion and motion averaging on drift accumulation for ultra-long sequences are not presented. We will add a targeted ablation and drift-vs-length plot in the revised experiments section. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes Anchor3R as an engineering design that reframes feed-forward reconstruction outputs as current-frame relative-pose measurements, then applies standard loop-closure reinsertion and motion averaging for global alignment. No equations, first-principles derivations, or parameter-fitting steps are presented that could reduce a claimed prediction to its own inputs by construction. The central claims rest on empirical benchmark comparisons rather than any self-referential mathematical chain, self-citation load-bearing argument, or ansatz smuggled via prior work. The approach is therefore self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[2]
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen. Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645, 2025
Pith/arXiv arXiv 2025
-
[3]
J. Dong, H. Li, S. Zhou, W. Hu, W. Xu, and Y . Wang. Memix: Writing less, remembering more for streaming 3d reconstruction.arXiv preprint arXiv:2603.15330, 2026
arXiv 2026
-
[4]
Y . Lan, Y . Luo, F. Hong, S. Zhou, H. Chen, Z. Lyu, S. Yang, B. Dai, C. C. Loy, and X. Pan. Stream3r: Scalable sequential 3d reconstruction with causal transformer.arXiv preprint arXiv:2508.10893, 2025
arXiv 2025
-
[5]
D. Zhuo, W. Zheng, J. Guo, Y . Wu, J. Zhou, and J. Lu. Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539, 2025
Pith/arXiv arXiv 2025
- [6]
-
[7]
Z. Li, J. Zhou, Y . Wang, H. Guo, W. Chang, Y . Zhou, H. Zhu, J. Chen, C. Shen, and T. He. Wint3r: Window-based streaming reconstruction with camera token pool.arXiv preprint arXiv:2509.05296, 2025
arXiv 2025
-
[8]
C. Liu, J. Yang, Z. Li, Y . Deng, J. Guo, and L. Ballan. Mem3r: Streaming 3d reconstruction with hybrid memory via test-time training.arXiv preprint arXiv:2604.07279, 2026
Pith/arXiv arXiv 2026
-
[9]
J. L. Schonberger and J.-M. Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[10]
Y . Ding, J. Yang, V . Larsson, C. Olsson, and K.˚Astr¨om. Revisiting the p3p problem. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4872–4880, 2023
2023
-
[11]
Hartley and A
R. Hartley and A. Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[12]
Triggs, P
B. Triggs, P. F. McLauchlan, R. I. Hartley, and A. W. Fitzgibbon. Bundle adjustment—a modern synthesis. InInternational workshop on vision algorithms, pages 298–372. Springer, 1999
1999
-
[13]
J. Ren, W. Liang, R. Yan, L. Mai, S. Liu, and X. Liu. Megba: A gpu-based distributed library for large-scale bundle adjustment. InEuropean Conference on Computer Vision, pages 715–731. Springer, 2022
2022
-
[14]
Mur-Artal, J
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos. Orb-slam: A versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163, 2015
2015
-
[15]
Mur-Artal and J
R. Mur-Artal and J. D. Tard´os. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE transactions on robotics, 33(5):1255–1262, 2017
2017
-
[16]
L. Pan, D. Bar´ath, M. Pollefeys, and J. L. Sch¨onberger. Global structure-from-motion revisited. InEuropean Conference on Computer Vision, pages 58–77. Springer, 2024
2024
-
[17]
S. Zhu, R. Zhang, L. Zhou, T. Shen, T. Fang, P. Tan, and L. Quan. Very large-scale global sfm by distributed motion averaging. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4568–4577, 2018
2018
-
[18]
Chatterjee and V
A. Chatterjee and V . M. Govindu. Robust relative rotation averaging.IEEE transactions on pattern analysis and machine intelligence, 40(4):958–972, 2017. 9
2017
-
[19]
Ozyesil and A
O. Ozyesil and A. Singer. Robust camera location estimation by convex programming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2674–2683, 2015
2015
-
[20]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[21]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[22]
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He.π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
Pith/arXiv arXiv 2025
-
[23]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[24]
N. Keetha, N. M¨uller, J. Sch¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414, 2025
Pith/arXiv arXiv 2025
-
[25]
S. Elflein, R. Li, S. Agostinho, Z. Gojcic, L. Leal-Taix´e, Q. Zhou, and A. Osep. Vgg-t 3: Offline feed-forward 3d reconstruction at scale.arXiv preprint arXiv:2602.23361, 2026
arXiv 2026
-
[26]
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025
Pith/arXiv arXiv 2025
-
[27]
H. Jin, R. Wu, T. Zhang, R. Gao, J. T. Barron, N. Snavely, and A. Holynski. Zipmap: Linear-time stateful 3d reconstruction via test-time training.arXiv preprint arXiv:2603.04385, 2026
Pith/arXiv arXiv 2026
-
[28]
J. Zhang, C. Herrmann, J. Hur, C. Sun, M.-H. Yang, F. Cole, T. Darrell, and D. Sun. Loger: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026
Pith/arXiv arXiv 2026
-
[29]
T. Xie, P. Yang, Y . Jin, Y . Cai, W. Yin, W. Ren, Q. Zhang, W. Hua, S. Peng, X. Guo, et al. Scal3r: Scalable test-time training for large-scale 3d reconstruction.arXiv preprint arXiv:2604.08542, 2026
Pith/arXiv arXiv 2026
-
[30]
Y . Wu, W. Zheng, J. Zhou, and J. Lu. Point3r: Streaming 3d reconstruction with explicit spatial pointer memory.arXiv preprint arXiv:2507.02863, 2025
arXiv 2025
-
[31]
P. Neal, C. Eric, P. Borja, and E. Jonathan. Distributed optimization and statistical learning via the alternating direction method of multipliers.F oundations and Trends® in Machine learning, 3(1):1–122, 2011
2011
-
[32]
H. Xia, Y . Fu, S. Liu, and X. Wang. Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos, 2024
2024
-
[33]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[34]
Roberts, J
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021. 10
2021
-
[35]
M. L. Antequera, P. Gargallo, M. Hofinger, S. R. Bulo, Y . Kuang, and P. Kontschieder. Mapillary planet-scale depth dataset. InEuropean Conference on Computer Vision, pages 589–604. Springer, 2020
2020
-
[36]
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797, 2019
Pith/arXiv arXiv 1906
-
[37]
Arnold, J
E. Arnold, J. Wynn, S. Vicente, G. Garcia-Hernando, A. Monszpart, V . Prisacariu, D. Tur- mukhambetov, and E. Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InEuropean Conference on Computer Vision, pages 690–708. Springer, 2022
2022
-
[38]
W. Wang, D. Zhu, X. Wang, Y . Hu, Y . Qiu, C. Wang, Y . Hu, A. Kapoor, and S. Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
2020
-
[39]
Huang, K
P.-H. Huang, K. Matzen, J. Kopf, N. Ahuja, and J.-B. Huang. Deepmvs: Learning multi-view stereopsis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2821–2830, 2018
2018
-
[40]
Cabon, N
Y . Cabon, N. Murray, and M. Humenberger. Virtual kitti 2, 2020
2020
-
[41]
X. Pan, N. Charron, Y . Yang, S. Peters, T. Whelan, C. Kong, O. Parkhi, R. Newcombe, and Y . C. Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133– 20143, 2023
2023
-
[42]
L. Mehl, J. Schmalfuss, A. Jahedi, Y . Nalivayko, and A. Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4981–4991, 2023
2023
-
[43]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[44]
Y . Yao, Z. Luo, S. Li, J. Zhang, Y . Ren, L. Zhou, T. Fang, and L. Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1790–1799, 2020
2020
-
[45]
Reizenstein, R
J. Reizenstein, R. Shapovalov, P. Henzler, L. Sbordone, P. Labatut, and D. Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021
2021
-
[46]
Li and N
Z. Li and N. Snavely. Megadepth: Learning single-view depth prediction from internet photos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018
2041
-
[47]
L. Ling, Y . Sheng, Z. Tu, W. Zhao, C. Xin, K. Wan, L. Yu, Q. Guo, Z. Yu, Y . Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[48]
Geiger, P
A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InConference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[49]
Brizi, E
L. Brizi, E. Giacomini, L. Di Giammarino, S. Ferrari, O. Salem, L. De Rebotti, and G. Grisetti. Vbr: A vision benchmark in rome. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 15868–15874. IEEE, 2024. 11
2024
-
[50]
Sturm, N
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers. A benchmark for the evaluation of rgb-d slam systems. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 573–580. IEEE, 2012
2012
-
[51]
Tao, M.´A
Y . Tao, M.´A. Mu˜noz-Ba˜n´on, L. Zhang, J. Wang, L. F. T. Fu, and M. Fallon. The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods.International Journal of Robotics Research, 2025
2025
-
[52]
Shotton, B
J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013
2013
-
[53]
Y . Shen, Z. Zhang, Y . Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025
Pith/arXiv arXiv 2025
-
[54]
Murai, E
R. Murai, E. Dexheimer, and A. J. Davison. Mast3r-slam: Real-time dense slam with 3d recon- struction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025
2025
-
[55]
D. Maggio, H. Lim, and L. Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025
Pith/arXiv arXiv 2025
-
[56]
S. Yuan, Y . Yang, X. Yang, X. Zhang, Z. Zhao, L. Zhang, and Z. Zhang. Infinitevggt: Visual geometry grounded transformer for endless streams.arXiv preprint arXiv:2601.02281, 2026
arXiv 2026
-
[57]
Arandjelovic, P
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016. 12 Supplementary Material A Online Motion Averaging During online inference, Anchor3R does not compose poses along a single...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.