AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation
Pith reviewed 2026-06-27 08:02 UTC · model grok-4.3
The pith
AudioX-Turbo distills a multimodal audio generator into a 4-step model that outperforms multi-step baselines on text-to-audio tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
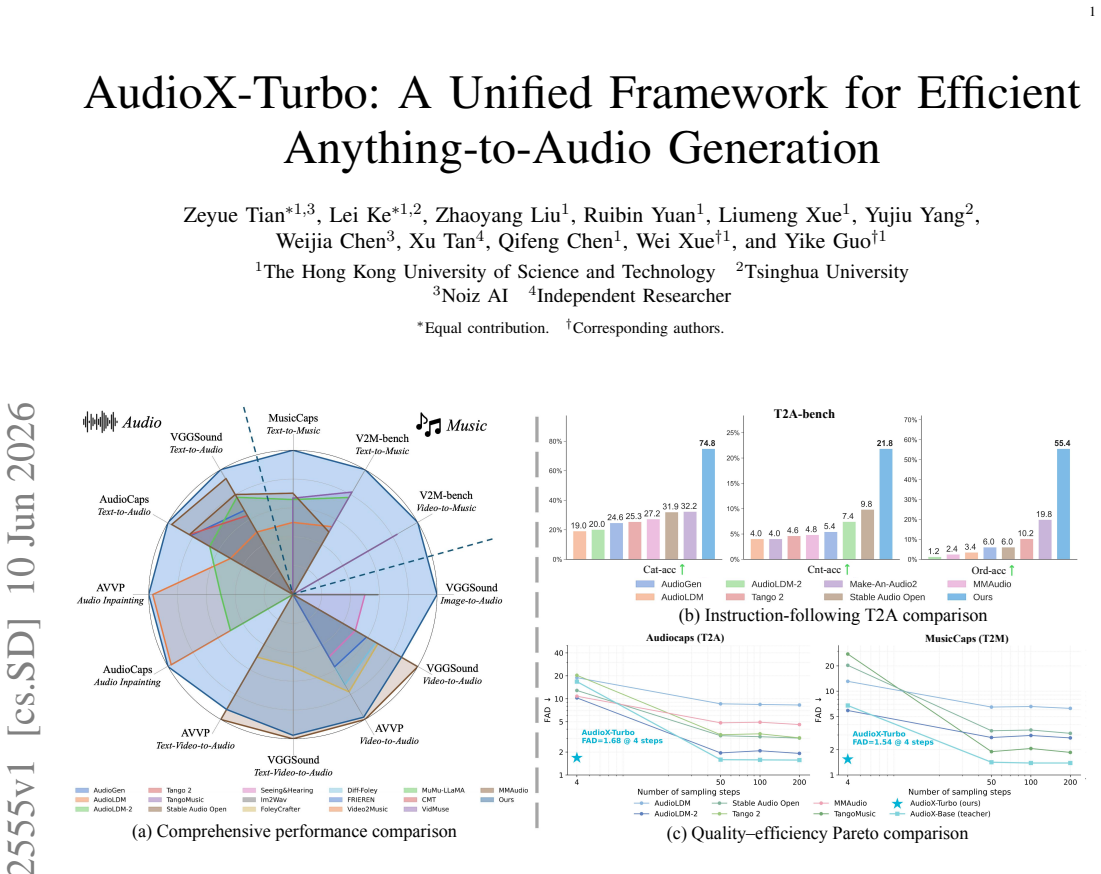
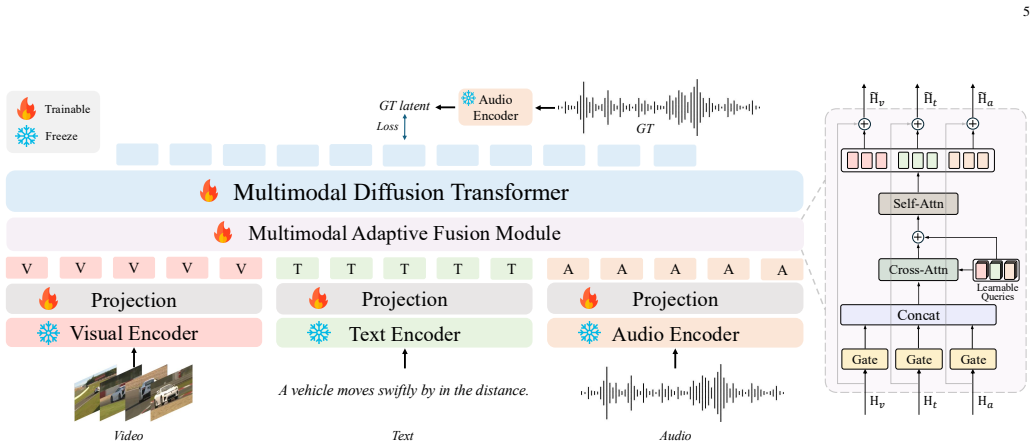
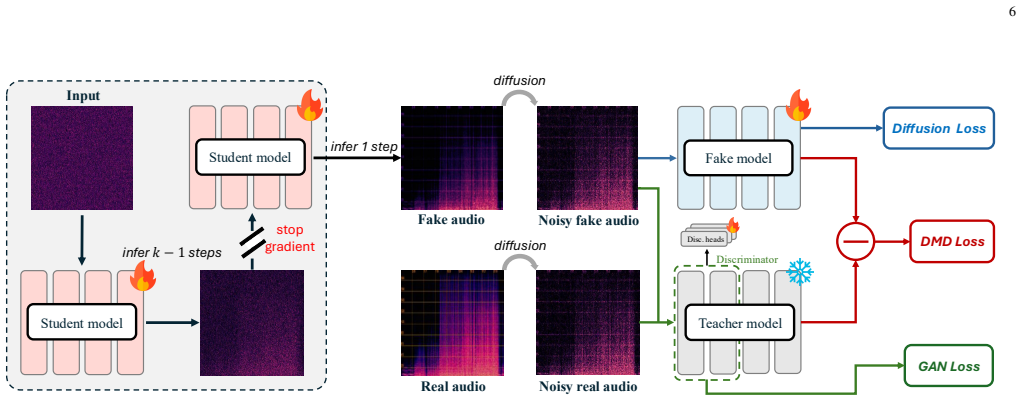
AudioX-Turbo follows a teacher-student paradigm where the teacher AudioX-Base, built on a Multimodal Diffusion Transformer with Multimodal Adaptive Fusion, is distilled into the few-step student via Distribution Matching Distillation adapted to flow matching and a diffusion-based discriminator, achieving superior performance on text-to-audio and text-to-music at 4 sampling steps with 25x fewer function evaluations.
What carries the argument
Distribution Matching Distillation adapted to flow matching combined with a diffusion-based discriminator that transfers capability from the multi-step teacher to the few-step student.
Load-bearing premise
The adapted distillation method successfully transfers high-fidelity generation ability from the teacher to the student without substantial quality degradation.
What would settle it
A direct comparison in blind listening tests where human raters consistently prefer the multi-step baseline outputs over the 4-step AudioX-Turbo outputs on the same prompts would falsify the claim of superior or comparable performance.
Figures

read the original abstract
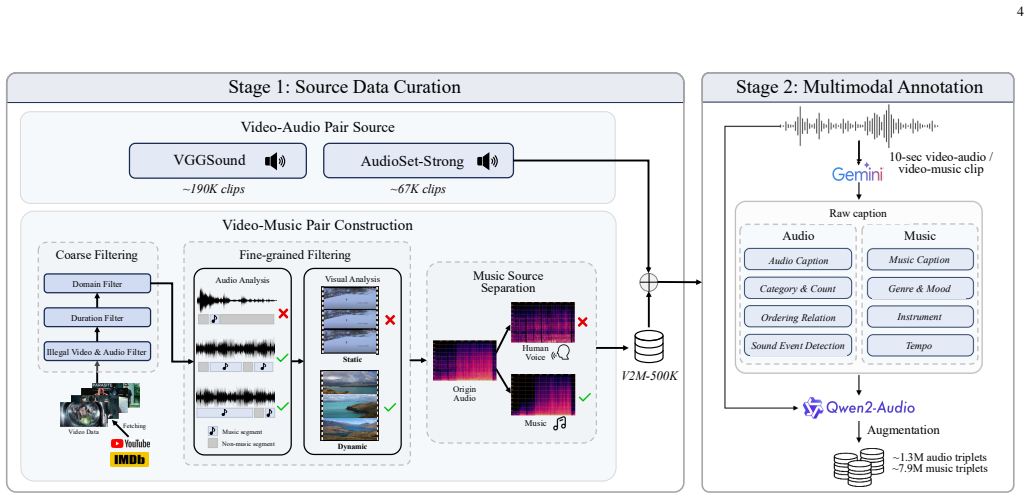
Audio and music generation based on flexible multimodal control signals is a widely applicable topic, with the following key challenges: 1) a unified multimodal modeling framework, 2) large-scale, high-quality training data, and 3) the prohibitive inference cost of multi-step diffusion sampling. As such, we propose AudioX-Turbo, a unified and efficient framework for anything-to-audio generation that integrates varied multimodal conditions (i.e., text, video, and audio signals) in this work. AudioX-Turbo follows a teacher-student paradigm. The teacher AudioX-Base is built on a Multimodal Diffusion Transformer with a Multimodal Adaptive Fusion module that aligns diverse multimodal inputs for high-fidelity synthesis, and is then distilled into the few-step student AudioX-Turbo via Distribution Matching Distillation adapted to flow matching, complemented by a diffusion-based discriminator for high-quality few-step generation. To support the training of AudioX-Turbo, we construct a large-scale, high-quality dataset, IF-caps-Pro, comprising approximately 9.2M samples curated through a two-stage data collection and annotation pipeline. We benchmark AudioX-Turbo across a wide range of tasks, finding that our model achieves superior performance, especially on text-to-audio and text-to-music generation, while operating at only 4 sampling steps and requiring approximately 25x fewer function evaluations (NFE) than multi-step baselines. These results demonstrate that our method is capable of audio generation under flexible multimodal control, showing efficient and powerful instruction-following capabilities. The code and datasets will be available at https://zeyuet.github.io/AudioX-Turbo/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AudioX-Turbo, a unified framework for anything-to-audio generation under multimodal conditions (text, video, audio). It employs a teacher-student setup in which the teacher AudioX-Base (a Multimodal Diffusion Transformer with Multimodal Adaptive Fusion) is distilled into a 4-step student via Distribution Matching Distillation adapted to flow matching, augmented by a diffusion-based discriminator. A new 9.2M-sample dataset IF-caps-Pro is constructed, and the model is reported to deliver superior performance on text-to-audio and text-to-music tasks while using approximately 25× fewer NFEs than multi-step baselines.
Significance. If the empirical claims are substantiated with quantitative benchmarks, ablations, and statistical controls, the work would offer a practically significant reduction in inference cost for high-fidelity multimodal audio synthesis, addressing a key deployment barrier in the field.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim of 'superior performance' and '25x fewer function evaluations' is stated without any reported metrics, baselines, error bars, or ablation tables; this absence prevents verification of the central performance assertion against the data.
- [Method] Method section on distillation: the adaptation of Distribution Matching Distillation to flow matching plus the diffusion-based discriminator is presented without analysis or controls demonstrating that typical few-step failure modes (mode collapse, high-frequency artifacts, degraded cross-modal alignment) are avoided on audio/music data; the transfer of quality from AudioX-Base to the 4-step student therefore remains an unverified empirical assumption.
minor comments (2)
- The dataset construction pipeline for IF-caps-Pro is described at a high level; additional details on curation criteria, annotation quality controls, and potential biases would strengthen reproducibility.
- The code and dataset release URL is given but the manuscript does not specify the exact license or access timeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional quantitative detail and analysis would strengthen the manuscript. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim of 'superior performance' and '25x fewer function evaluations' is stated without any reported metrics, baselines, error bars, or ablation tables; this absence prevents verification of the central performance assertion against the data.
Authors: We agree that the abstract states the performance claims at a high level without embedding specific numbers. The Experiments section contains benchmark comparisons on text-to-audio and text-to-music tasks, but to improve verifiability we will add a concise results table (including FAD, KL, CLAP, and subjective scores with error bars) to both the abstract and Experiments section, along with an explicit NFE calculation (4 steps versus 100-step baselines). revision: yes
-
Referee: [Method] Method section on distillation: the adaptation of Distribution Matching Distillation to flow matching plus the diffusion-based discriminator is presented without analysis or controls demonstrating that typical few-step failure modes (mode collapse, high-frequency artifacts, degraded cross-modal alignment) are avoided on audio/music data; the transfer of quality from AudioX-Base to the 4-step student therefore remains an unverified empirical assumption.
Authors: The referee is right that the current Method section lacks explicit controls for these failure modes. We will add a dedicated analysis subsection with quantitative checks (diversity metrics for mode collapse, high-frequency energy ratios and spectrogram comparisons for artifacts, and cross-modal retrieval scores for alignment) plus qualitative examples comparing teacher and student outputs. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper presents a teacher-student distillation pipeline (AudioX-Base to AudioX-Turbo via adapted DMD on flow matching plus discriminator) and reports empirical superiority on text-to-audio/music tasks at 4 steps. No equations, derivations, or 'predictions' appear that reduce by construction to fitted parameters or self-citations within the work. Performance numbers derive from benchmarking on the independently constructed IF-caps-Pro dataset against multi-step baselines, satisfying the self-contained criterion. No self-definitional, fitted-input, or uniqueness-imported patterns are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Audioldm: text-to-audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “Audioldm: text-to-audio generation with latent diffusion models,” inProceedings of the 40th International Conference on Machine Learn- ing, 2023, pp. 21 450–21 474
2023
-
[2]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Syn- naeve, Y . Adi, and A. D´efossez, “Simple and controllable music generation,”Advances in Neural Information Pro- cessing Systems, vol. 36, 2024
2024
-
[3]
Frieren: Efficient video-to-audio generation with rectified flow matching,
Y . Wang, W. Guo, R. Huang, J. Huang, Z. Wang, F. You, R. Li, and Z. Zhao, “Frieren: Efficient video-to-audio generation with rectified flow matching,”arXiv preprint arXiv:2406.00320, 2024
arXiv 2024
-
[4]
Mmaudio: Taming multi- modal joint training for high-quality video-to-audio syn- thesis,
H. K. Cheng, M. Ishii, A. Hayakawa, T. Shibuya, A. Schwing, and Y . Mitsufuji, “Mmaudio: Taming multi- modal joint training for high-quality video-to-audio syn- thesis,” inProceedings of the Computer Vision and Pat- tern Recognition Conference, 2025, pp. 28 901–28 911
2025
-
[5]
Vidmuse: A simple video-to-music generation framework with long-short- term modeling,
Z. Tian, Z. Liu, R. Yuan, J. Pan, Q. Liu, X. Tan, Q. Chen, W. Xue, and Y . Guo, “Vidmuse: A simple video-to-music generation framework with long-short- term modeling,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 18 782– 18 793
2025
-
[6]
Movie gen: A cast of media foundation models,
A. Polyak, A. Zohar, A. Brown, A. Tjandra, A. Sinha, A. Lee, A. Vyas, B. Shi, C.-Y . Ma, C.-Y . Chuanget al., “Movie gen: A cast of media foundation models,”arXiv preprint arXiv:2410.13720, 2024
Pith/arXiv arXiv 2024
-
[7]
Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds,
Y . Zhang, Y . Gu, Y . Zeng, Z. Xing, Y . Wang, Z. Wu, and K. Chen, “Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds,”arXiv preprint arXiv:2407.01494, 2024
arXiv 2024
-
[8]
Audiocaps: Generating captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “Audiocaps: Generating captions for audios in the wild,” inPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 119–132
2019
-
[9]
Vg- gsound: A large-scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vg- gsound: A large-scale audio-visual dataset,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 721–725
2020
-
[10]
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Tay- lor, and J. Pons, “Stable audio open,”arXiv preprint arXiv:2407.14358, 2024
arXiv 2024
-
[11]
Progressive distillation for fast sampling of diffusion models,
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,” inInternational Confer- ence on Learning Representations, 2022
2022
-
[12]
Latent consistency models: Synthesizing high-resolution images with few-step inference,
S. Luo, Y . Tan, L. Huang, J. Li, and H. Zhao, “Latent consistency models: Synthesizing high-resolution images with few-step inference,”arXiv preprint arXiv:2310.04378, 2023
Pith/arXiv arXiv 2023
-
[13]
One-step diffusion with distribution matching distillation,
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park, “One-step diffusion with distribution matching distillation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 6613–6623
2024
-
[14]
Improved distribution matching distillation for fast image synthesis,
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and W. T. Freeman, “Improved distribution matching distillation for fast image synthesis,”Advances in neural information processing systems, vol. 37, pp. 47 455–47 487, 2024
2024
-
[15]
Next-gpt: Any-to-any multimodal llm,
S. Wu, H. Fei, L. Qu, W. Ji, and T.-S. Chua, “Next-gpt: Any-to-any multimodal llm,”arXiv preprint arXiv:2309.05519, 2023
arXiv 2023
-
[16]
Visual instruc- tion tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruc- tion tuning,”Advances in neural information processing systems, vol. 36, 2024
2024
-
[17]
Video-llava: Learning united visual represen- tation by alignment before projection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual represen- tation by alignment before projection,”arXiv preprint arXiv:2311.10122, 2023
Pith/arXiv arXiv 2023
-
[18]
Long-form music generation with latent diffusion,
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Long-form music generation with latent diffusion,”arXiv preprint arXiv:2404.10301, 2024
arXiv 2024
-
[19]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference opti- mization,
N. Majumder, C.-Y . Hung, D. Ghosal, W.-N. Hsu, R. Mi- halcea, and S. Poria, “Tango 2: Aligning diffusion-based text-to-audio generations through direct preference opti- mization,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 564–572
2024
-
[20]
The benefit of temporally- strong labels in audio event classification,
S. Hershey, D. P. Ellis, E. Fonseca, A. Jansen, C. Liu, R. C. Moore, and M. Plakal, “The benefit of temporally- strong labels in audio event classification,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 366–370
2021
-
[21]
Z. Evans, J. D. Parker, M. Rice, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio 3,” 2026. [Online]. Available: https://arxiv.org/abs/2605.17991
Pith/arXiv arXiv 2026
-
[22]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
2024
-
[23]
Make-an-audio 2: Temporal-enhanced text-to-audio generation,
J. Huang, Y . Ren, R. Huang, D. Yang, Z. Ye, C. Zhang, J. Liu, X. Yin, Z. Ma, and Z. Zhao, “Make-an-audio 2: Temporal-enhanced text-to-audio generation,”arXiv preprint arXiv:2305.18474, 2023
arXiv 2023
-
[24]
Interngpt: 14 Solving vision-centric tasks by interacting with chat- gpt beyond language,
Z. Liu, Y . He, W. Wang, W. Wang, Y . Wang, S. Chen, Q. Zhang, Z. Lai, Y . Yang, Q. Liet al., “Interngpt: 14 Solving vision-centric tasks by interacting with chat- gpt beyond language,”arXiv preprint arXiv:2305.05662, 2023
arXiv 2023
-
[25]
Controlllm: Augment language models with tools by searching on graphs,
Z. Liu, Z. Lai, Z. Gao, E. Cui, Z. Li, X. Zhu, L. Lu, Q. Chen, Y . Qiao, J. Daiet al., “Controlllm: Augment language models with tools by searching on graphs,” in European Conference on Computer Vision. Springer, 2024, pp. 89–105
2024
-
[26]
Scalecua: Scaling open- source computer use agents with cross-platform data,
Z. Liu, J. Xie, Z. Ding, Z. Li, B. Yang, Z. Wu, X. Wang, Q. Sun, S. Liu, W. Wanget al., “Scalecua: Scaling open- source computer use agents with cross-platform data,” arXiv preprint arXiv:2509.15221, 2025
arXiv 2025
-
[27]
Visual autoregressive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregressive modeling: Scalable image generation via next-scale prediction,”Advances in neural information processing systems, vol. 37, pp. 84 839–84 865, 2024
2024
-
[28]
Freeaudio: Training-free timing planning for control- lable long-form text-to-audio generation,
Y . Jiang, Z. Chen, Z. Ju, C. Li, W. Dou, and J. Zhu, “Freeaudio: Training-free timing planning for control- lable long-form text-to-audio generation,”arXiv preprint arXiv:2507.08557, 2025
arXiv 2025
-
[29]
Llms meet multi- modal generation and editing: A survey,
Y . He, Z. Liu, J. Chen, Z. Tian, H. Liu, X. Chi, R. Liu, R. Yuan, Y . Xing, W. Wanget al., “Llms meet multi- modal generation and editing: A survey,”arXiv preprint arXiv:2405.19334, 2024
arXiv 2024
-
[30]
C.-Y . Hung, N. Majumder, Z. Kong, A. Mehrish, A. A. Bagherzadeh, C. Li, R. Valle, B. Catanzaro, and S. Poria, “Tangoflux: Super fast and faithful text to audio gen- eration with flow matching and clap-ranked preference optimization,”arXiv preprint arXiv:2412.21037, 2024
arXiv 2024
-
[31]
Text-to-audio generation using instruction-tuned llm and latent diffusion model,
D. Ghosal, N. Majumder, A. Mehrish, and S. Po- ria, “Text-to-audio generation using instruction-tuned llm and latent diffusion model,”arXiv preprint arXiv:2304.13731, 2023
arXiv 2023
-
[32]
Composerx: Multi-agent symbolic music composition with llms,
Q. Deng, Q. Yang, R. Yuan, Y . Huang, Y . Wang, X. Liu, Z. Tian, J. Pan, G. Zhang, H. Linet al., “Composerx: Multi-agent symbolic music composition with llms,” arXiv preprint arXiv:2404.18081, 2024
arXiv 2024
-
[33]
Chatmusician: Understanding and generating music intrinsically with llm,
R. Yuan, H. Lin, Y . Wang, Z. Tian, S. Wu, T. Shen, G. Zhang, Y . Wu, C. Liu, Z. Zhouet al., “Chatmusician: Understanding and generating music intrinsically with llm,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 6252–6271
2024
-
[34]
Yue: Scaling open foundation models for long-form music generation,
R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y . Zang, H. Liu, Y . Liang, W. Ma, X. Duet al., “Yue: Scaling open foundation models for long-form music generation,” arXiv preprint arXiv:2503.08638, 2025
arXiv 2025
-
[35]
Foundation models for music: A survey,
Y . Ma, A. Øland, A. Ragni, B. M. Del Sette, C. Saitis, C. Donahue, C. Lin, C. Plachouras, E. Benetos, E. Shatri et al., “Foundation models for music: A survey,”arXiv preprint arXiv:2408.14340, 2024
arXiv 2024
-
[36]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
2024
-
[37]
Diff-foley: Syn- chronized video-to-audio synthesis with latent diffusion models,
S. Luo, C. Yan, C. Hu, and H. Zhao, “Diff-foley: Syn- chronized video-to-audio synthesis with latent diffusion models,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[38]
Video-guided fo- ley sound generation with multimodal controls,
Z. Chen, P. Seetharaman, B. Russell, O. Nieto, D. Bour- gin, A. Owens, and J. Salamon, “Video-guided fo- ley sound generation with multimodal controls,”arXiv preprint arXiv:2411.17698, 2024
arXiv 2024
-
[39]
Omni2sound: Towards unified video-text-to-audio gen- eration,
Y . Dai, Z. Chen, Y . Jiang, Q. Ke, J. Cai, and J. Zhu, “Omni2sound: Towards unified video-text-to-audio gen- eration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 1661–1671
2026
-
[40]
Video2music: Suitable music generation from videos using an affective multimodal transformer model,
J. Kang, S. Poria, and D. Herremans, “Video2music: Suitable music generation from videos using an affective multimodal transformer model,”Expert Systems with Applications, vol. 249, p. 123640, 2024
2024
-
[41]
Mumu-llama: Multi-modal music understanding and generation via large language models,
S. Liu, A. S. Hussain, Q. Wu, C. Sun, and Y . Shan, “Mumu-llama: Multi-modal music understanding and generation via large language models,”arXiv preprint arXiv:2412.06660, 2024
arXiv 2024
-
[42]
Video background music generation with controllable music transformer,
S. Di, Z. Jiang, S. Liu, Z. Wang, L. Zhu, Z. He, H. Liu, and S. Yan, “Video background music generation with controllable music transformer,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2037–2045
2021
-
[43]
Diff- bgm: A diffusion model for video background music generation,
S. Li, Y . Qin, M. Zheng, X. Jin, and Y . Liu, “Diff- bgm: A diffusion model for video background music generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 348–27 357
2024
-
[44]
Vmas: Video-to-music generation via se- mantic alignment in web music videos,
Y .-B. Lin, Y . Tian, L. Yang, G. Bertasius, and H. Wang, “Vmas: Video-to-music generation via se- mantic alignment in web music videos,”arXiv preprint arXiv:2409.07450, 2024
arXiv 2024
-
[45]
Muvi: Video-to-music generation with se- mantic alignment and rhythmic synchronization,
R. Li, S. Zheng, X. Cheng, Z. Zhang, S. Ji, and Z. Zhao, “Muvi: Video-to-music generation with se- mantic alignment and rhythmic synchronization,”arXiv preprint arXiv:2410.12957, 2024
arXiv 2024
-
[46]
Unimoe-audio: Unified speech and music generation with dynamic- capacity moe,
Z. Liu, Y . Li, X. Zhang, Q. Teng, S. Jiang, X. Chen, H. Shi, J. Li, Q. Wang, H. Chenet al., “Unimoe-audio: Unified speech and music generation with dynamic- capacity moe,”arXiv preprint arXiv:2510.13344, 2025
arXiv 2025
-
[47]
Audio-flan: A prelim- inary release,
L. Xue, Z. Zhou, J. Pan, Z. Li, S. Fan, Y . Ma, S. Cheng, D. Yang, H. Guo, Y . Xiaoet al., “Audio-flan: A prelim- inary release,”arXiv preprint arXiv:2502.16584, 2025
Pith/arXiv arXiv 2025
-
[48]
Clotho: An audio captioning dataset,
K. Drossos, S. Lipping, and T. Virtanen, “Clotho: An audio captioning dataset,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP). IEEE, 2020, pp. 736–740
2020
-
[49]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[50]
The freesound loop dataset and annotation tool,
A. Ramires, F. Font, D. Bogdanov, J. B. Smith, Y .-H. Yang, J. Ching, B.-Y . Chen, Y .-K. Wu, H. Wei-Han, and X. Serra, “The freesound loop dataset and annotation tool,”arXiv preprint arXiv:2008.11507, 2020
arXiv 2008
-
[51]
Unified multisensory percep- 15 tion: Weakly-supervised audio-visual video parsing,
Y . Tian, D. Li, and C. Xu, “Unified multisensory percep- 15 tion: Weakly-supervised audio-visual video parsing,” in Computer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer, 2020, pp. 436–454
2020
-
[52]
Harmony- set: A comprehensive dataset for understanding video- music semantic alignment and temporal synchroniza- tion,
Z. Zhou, K. Mei, Y . Lu, T. Wang, and F. Rao, “Harmony- set: A comprehensive dataset for understanding video- music semantic alignment and temporal synchroniza- tion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 3152–3162
2025
-
[53]
Mmtrail: A multimodal trailer video dataset with language and music descriptions,
X. Chi, Y . Wang, A. Cheng, P. Fang, Z. Tian, Y . He, Z. Liu, X. Qi, J. Pan, R. Zhanget al., “Mmtrail: A multimodal trailer video dataset with language and music descriptions,”arXiv preprint arXiv:2407.20962, 2024
arXiv 2024
-
[54]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[55]
Score-based generative mod- eling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative mod- eling through stochastic differential equations,”arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[56]
High-resolution image synthesis with la- tent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with la- tent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[57]
Hierarchical text-conditional image genera- tion with clip latents,
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image genera- tion with clip latents,”arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
Pith/arXiv arXiv 2022
-
[58]
Instruct- pix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instruct- pix2pix: Learning to follow image editing instructions,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2023, pp. 18 392– 18 402
2023
-
[59]
Videocrafter1: Open diffusion models for high-quality video genera- tion,
H. Chen, M. Xia, Y . He, Y . Zhang, X. Cun, S. Yang, J. Xing, Y . Liu, Q. Chen, X. Wanget al., “Videocrafter1: Open diffusion models for high-quality video genera- tion,”arXiv preprint arXiv:2310.19512, 2023
Pith/arXiv arXiv 2023
-
[60]
Video diffusion models,
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,”Advances in Neural Information Processing Systems, vol. 35, pp. 8633–8646, 2022
2022
-
[61]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning,
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai, “Animatediff: Animate your personalized text-to-image diffusion models without specific tuning,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[62]
Grad-tts: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov, “Grad-tts: A diffusion probabilistic model for text-to-speech,” inInternational Conference on Ma- chine Learning. PMLR, 2021, pp. 8599–8608
2021
-
[63]
Diff-tts: A denoising diffusion model for text-to- speech,
M. Jeong, H. Kim, S. J. Cheon, B. J. Choi, and N. S. Kim, “Diff-tts: A denoising diffusion model for text-to- speech,”arXiv preprint arXiv:2104.01409, 2021
arXiv 2021
-
[64]
Diff- singer: Singing voice synthesis via shallow diffusion mechanism,
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao, “Diff- singer: Singing voice synthesis via shallow diffusion mechanism,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 10, 2022, pp. 11 020– 11 028
2022
-
[65]
Consis- tency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consis- tency models,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 32 211– 32 252
2023
-
[66]
Consis- tency trajectory models: Learning probability flow ode trajectory of diffusion,
D. Kim, C.-H. Lai, W.-H. Liao, N. Murata, Y . Takida, T. Uesaka, Y . He, Y . Mitsufuji, and S. Ermon, “Consis- tency trajectory models: Learning probability flow ode trajectory of diffusion,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[67]
Phased consistency models,
F.-Y . Wang, Z. Huang, A. W. Bergman, D. Shen, P. Gao, M. Lingelbach, K. Sun, W. Bian, G. Song, Y . Liuet al., “Phased consistency models,”Advances in neural infor- mation processing systems, vol. 37, pp. 83 951–84 009, 2024
2024
-
[68]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[69]
Flowsteer: Guiding few-step im- age synthesis with authentic trajectories,
L. Ke, H. Yin, G. Liu, Z. Lv, J. Guo, C. Li, W. Luo, Y . Yang, and J. Lyu, “Flowsteer: Guiding few-step im- age synthesis with authentic trajectories,”arXiv preprint arXiv:2511.18834, 2025
arXiv 2025
-
[70]
Proreflow: Progressive reflow with decomposed velocity,
L. Ke, H. Xu, X. Ning, Y . Li, J. Li, H. Li, Y . Lin, D. Jiang, Y . Yang, and L. Zhang, “Proreflow: Progressive reflow with decomposed velocity,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 029–28 038
2025
-
[71]
Content-based video- music retrieval using soft intra-modal structure con- straint,
S. Hong, W. Im, and H. S. Yang, “Content-based video- music retrieval using soft intra-modal structure con- straint,”arXiv preprint arXiv:1704.06761, 2017
Pith/arXiv arXiv 2017
-
[72]
Video back- ground music generation: Dataset, method and evalu- ation,
L. Zhuo, Z. Wang, B. Wang, Y . Liao, C. Bao, S. Peng, S. Han, A. Zhang, F. Fang, and S. Liu, “Video back- ground music generation: Dataset, method and evalu- ation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 15 637– 15 647
2023
-
[73]
Panns: Large-scale pretrained audio neu- ral networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumbley, “Panns: Large-scale pretrained audio neu- ral networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Process- ing, vol. 28, pp. 2880–2894, 2020
2020
-
[74]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,” arXiv preprint arXiv:2407.10759, 2024
Pith/arXiv arXiv 2024
-
[75]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[76]
Synch- former: Efficient synchronization from sparse cues,
V . Iashin, W. Xie, E. Rahtu, and A. Zisserman, “Synch- former: Efficient synchronization from sparse cues,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 5325–5329
2024
-
[77]
Exploring the limits of transfer learning with a unified text-to- 16 text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to- 16 text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[78]
Cnn architectures for large- scale audio classification,
S. Hershey, S. Chaudhuri, D. P. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seyboldet al., “Cnn architectures for large- scale audio classification,” in2017 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2017, pp. 131–135
2017
-
[79]
Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound,
A. Tjandra, Y .-C. Wu, B. Guo, J. Hoffman, B. Ellis, A. Vyas, B. Shi, S. Chen, M. Le, N. Zacharovet al., “Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound,”arXiv preprint arXiv:2502.05139, 2025
Pith/arXiv arXiv 2025
-
[80]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 180–15 190
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.