Sentence-Level Contextual Entrainment in Large Language Models
Pith reviewed 2026-06-26 00:50 UTC · model grok-4.3
The pith
LLMs assign higher probability to sentences appearing in the prompt, an effect governed by 2 to 4 percent of attention heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
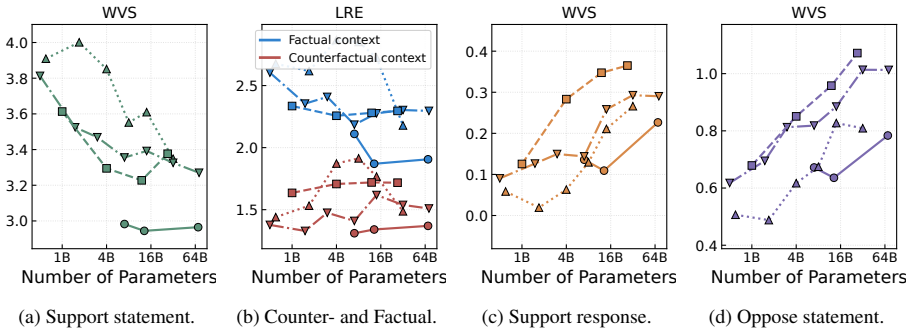
Sentence-level contextual entrainment exists such that sentences in the prompt raise their probability at inference time, tracked through per-token mean log-probability. The pattern holds across many models and datasets. Entrainment lessens with scale and is controlled by a small set of attention heads whose deactivation mitigates the effect without harming performance.
What carries the argument
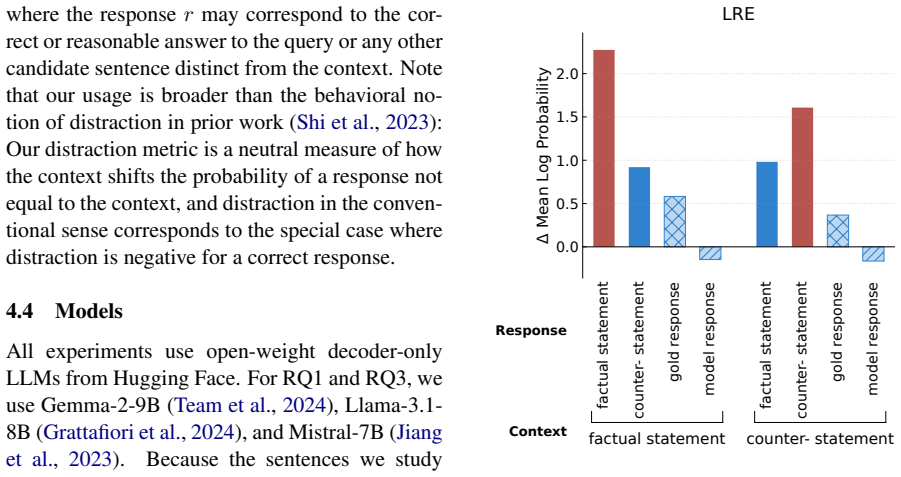
Per-token mean log-probability of a sentence as the entrainment measure, localized to 2-4 percent of attention heads that control the probability boost.
If this is right
- Sentence-level entrainment weakens as model size grows.
- Deactivating the controlling attention heads reduces entrainment.
- The effect occurs on both subjective and objective tasks.
- Counterfactual sentences in the prompt still receive the probability increase.
Where Pith is reading between the lines
- Targeted deactivation of the heads offers a route to limit unwanted repetition of prompt content.
- The same localization might allow selective control over how context shapes longer outputs.
- Prompt construction may need to consider unintended probability boosts to included material.
Load-bearing premise
That the per-token mean log-probability of a sentence validly captures entrainment and that observed increases are caused by the sentence's presence in the prompt rather than other prompt features.
What would settle it
An experiment showing no probability increase for a sentence after it is added to the prompt, or showing that deactivating the identified attention heads leaves the probability boost unchanged.
Figures

read the original abstract
Contextual entrainment, which is a newly discovered phenomenon in large language models (LLMs), refers to the tendency of a model to assign higher probabilities to tokens that appear in its context. In this work, we extend this phenomenon from the token level to the sentence level by examining the per-token mean log-probability of a sentence instead of the probabilities of individual tokens. We investigate sentence-level contextual entrainment across 26 LLMs from seven families and two datasets, which cover both subjective and objective tasks. We find that sentence-level contextual entrainment exists. This means that the sentences in the prompt (even if they are counterfactual statements) can significantly increase their probability during model inference time. As the model size increases, contextual entrainment gradually decreases. We also find that contextual entrainment is controlled by 2% to 4% of the attention heads. Turning off these attention heads can effectively mitigate contextual entrainment without hurting the model's performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends token-level contextual entrainment to the sentence level in LLMs, defining it via increases in per-token mean log-probability when a sentence (including counterfactuals) appears in the prompt. Experiments across 26 models from seven families and two datasets (subjective and objective tasks) report that entrainment exists, decreases with model scale, is localized to 2-4% of attention heads, and can be mitigated by ablating those heads without performance loss.
Significance. If the core measurements prove robust, the work offers a scalable empirical characterization of sentence-level context effects across model families and sizes, plus a practical intervention via head ablation. The breadth of models tested is a positive feature. However, the significance is limited by reliance on a single proxy metric whose validity for isolating entrainment is not yet demonstrated.
major comments (3)
- [Experimental setup and results sections] The central empirical claim (existence of sentence-level entrainment and its localization to 2-4% of heads) rests on defining entrainment as an increase in per-token mean log-probability when the sentence is present in the prompt. This metric is vulnerable to confounds including sentence length, token-frequency distributions, and positional biases that could elevate probabilities independently of the sentence's contextual presence; no length-matched non-entrained controls or shuffled-prompt ablations are described to rule these out.
- [Attention-head analysis and ablation experiments] The attention-head ablation results (mitigation without performance degradation) inherit the same measurement; because the proxy does not isolate entrainment from other prompt statistics, it is unclear whether the 2-4% heads are specifically responsible for the reported effect or for other prompt-related probability shifts.
- [Model-scale analysis] The claim that entrainment decreases with model size is presented as a trend across the 26 models, but without reported statistical tests, exact dataset names, baseline comparisons, or controls for prompt-length variation across model scales, the trend cannot be evaluated for robustness.
minor comments (2)
- [Abstract and §3] The abstract and methods should explicitly name the two datasets and report the precise statistical tests used to establish significance of probability increases.
- [Methods] Notation for per-token mean log-probability should be defined with an equation early in the methods to avoid ambiguity when comparing across subjective vs. objective tasks.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each major comment below, clarifying our approach where possible and outlining revisions to strengthen the empirical robustness of our claims.
read point-by-point responses
-
Referee: [Experimental setup and results sections] The central empirical claim (existence of sentence-level entrainment and its localization to 2-4% of heads) rests on defining entrainment as an increase in per-token mean log-probability when the sentence is present in the prompt. This metric is vulnerable to confounds including sentence length, token-frequency distributions, and positional biases that could elevate probabilities independently of the sentence's contextual presence; no length-matched non-entrained controls or shuffled-prompt ablations are described to rule these out.
Authors: We acknowledge that the per-token mean log-probability metric could be susceptible to confounds such as sentence length, token frequencies, and positional effects. Our design uses counterfactual sentences to hold lexical content constant while varying contextual presence, and compares conditions with and without the sentence in the prompt. However, we agree that additional controls would better isolate the entrainment effect. In the revised manuscript, we will add length-matched non-entrained controls and shuffled-prompt ablations to rule out these alternative explanations. revision: yes
-
Referee: [Attention-head analysis and ablation experiments] The attention-head ablation results (mitigation without performance degradation) inherit the same measurement; because the proxy does not isolate entrainment from other prompt statistics, it is unclear whether the 2-4% heads are specifically responsible for the reported effect or for other prompt-related probability shifts.
Authors: We agree that the head ablation results depend on the same proxy metric, raising questions about specificity. The localization to 2-4% of heads is determined by measuring each head's contribution to the probability increase, followed by targeted ablation. To address the concern, the revision will include further analyses comparing the effect of ablating these heads versus random or other prompt-related heads, to demonstrate that the mitigation is specific to the entrainment effect rather than general prompt statistics. revision: yes
-
Referee: [Model-scale analysis] The claim that entrainment decreases with model size is presented as a trend across the 26 models, but without reported statistical tests, exact dataset names, baseline comparisons, or controls for prompt-length variation across model scales, the trend cannot be evaluated for robustness.
Authors: The manuscript reports the trend across 26 models from seven families on two datasets covering subjective and objective tasks, but we accept that statistical tests, precise dataset names, baselines, and prompt-length controls are not explicitly detailed. In the revision, we will add statistical significance tests for the scale trend, name the exact datasets, include baseline comparisons, and incorporate controls for prompt-length variation across model sizes to allow proper evaluation of robustness. revision: yes
Circularity Check
No significant circularity; purely observational measurements
full rationale
The paper reports direct empirical measurements of per-token mean log-probability increases for sentences appearing in prompts across 26 LLMs, without any derivations, parameter fitting, or self-citation chains that reduce claims to inputs by construction. The central quantities are computed from model inference on held-out data and datasets covering subjective/objective tasks; no equations or uniqueness theorems are invoked that loop back on the observed effects. This is the expected outcome for an observational study whose reported statistics do not rely on internal redefinitions or fitted predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.759
-
[3]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[5]
International conference on machine learning , pages=
Calibrate before use: Improving few-shot performance of language models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[6]
Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLM s
Niu, Jingcheng and Yuan, Xingdi and Wang, Tong and Saghir, Hamidreza and Abdi, Amir H. Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.791
-
[7]
International Conference on Learning Representations , volume=
Learning dynamics of llm finetuning , author=. International Conference on Learning Representations , volume=
-
[8]
International Conference on Learning Representations , volume=
Linearity of relation decoding in transformer language models , author=. International Conference on Learning Representations , volume=
-
[9]
World Values Survey: Round Seven -- Country-Pooled Datafile Version 6.0 , author =. 2022 , publisher =. doi:10.14281/18241.24 , url =
-
[10]
Do LLM s Align Human Values Regarding Social Biases? Judging and Explaining Social Biases with LLM s
Liu, Yang and Chu, Chenhui. Do LLM s Align Human Values Regarding Social Biases? Judging and Explaining Social Biases with LLM s. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1178
-
[11]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
How do decisions emerge across layers in neural models? interpretation with differentiable masking , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[12]
International Conference on Learning Representations (ICLR 2017) , year=
Categorical Reparametrization with Gumble-Softmax , author=. International Conference on Learning Representations (ICLR 2017) , year=
2017
-
[13]
arXiv preprint arXiv:2206.07682 , year=
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On the alignment of large language models with global human opinion , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
arXiv preprint arXiv:2405.15032 , year=
Aya 23: Open weight releases to further multilingual progress , author=. arXiv preprint arXiv:2405.15032 , year=
-
[16]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[17]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[19]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[20]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[21]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[24]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[25]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[26]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Psychometric predictive power of large language models , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[27]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[28]
2026 , eprint=
Better and Worse with Scale: How Contextual Entrainment Diverges with Model Size , author=. 2026 , eprint=
2026
-
[29]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[30]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[31]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Induction heads as an essential mechanism for pattern matching in in-context learning , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[32]
arXiv preprint arXiv:2211.00593 , year=
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
-
[33]
arXiv preprint arXiv:2304.03208 , year=
Cerebras-gpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster , author=. arXiv preprint arXiv:2304.03208 , year=
-
[34]
International conference on machine learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[35]
International Conference on Machine Learning , pages=
Large language models can be easily distracted by irrelevant context , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[36]
arXiv preprint arXiv:2310.01558 , year=
Making retrieval-augmented language models robust to irrelevant context , author=. arXiv preprint arXiv:2310.01558 , year=
-
[37]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
The power of noise: Redefining retrieval for rag systems , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[38]
Advances in neural information processing systems , volume=
Incorporating second-order functional knowledge for better option pricing , author=. Advances in neural information processing systems , volume=
-
[39]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[40]
Mining Effective Features Using Quantum Entropy for Humor Recognition
Liu, Yang and Hou, Yuexian. Mining Effective Features Using Quantum Entropy for Humor Recognition. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.152
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Robust evaluation measures for evaluating social biases in masked language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
The annals of mathematical statistics , volume=
On information and sufficiency , author=. The annals of mathematical statistics , volume=. 1951 , publisher=
1951
-
[43]
arXiv preprint arXiv:1308.3432 , year=
Estimating or propagating gradients through stochastic neurons for conditional computation , author=. arXiv preprint arXiv:1308.3432 , year=
-
[44]
Few-shot In-context Learning on Knowledge Base Question Answering
Li, Tianle and Ma, Xueguang and Zhuang, Alex and Gu, Yu and Su, Yu and Chen, Wenhu. Few-shot In-context Learning on Knowledge Base Question Answering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.385
-
[45]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.