AV-SyncBench: Decoupled Benchmarking of Temporal and Semantic Audio-Visual Synchronization
Pith reviewed 2026-07-02 14:40 UTC · model grok-4.3
The pith
AV-SyncBench evaluates audio-visual synchronization by separating temporal offset detection from semantic content matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
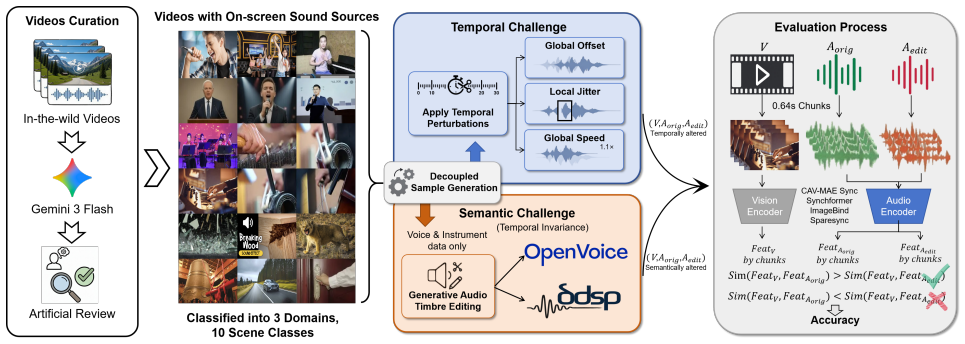
The central claim is that audio-visual feature extraction models can be assessed for temporal consistency and semantic consistency through completely separate evaluation tracks. AV-SyncBench achieves this separation by constructing its data from in-the-wild videos that are automatically filtered and manually verified to contain identifiable on-screen sound sources, then organizing the material into distinct temporal-offset and semantic-matching tasks across Voice, Music, and Sound categories.
What carries the argument
AV-SyncBench, a dataset and evaluation protocol that maintains separate tracks for temporal alignment and semantic matching while ensuring on-screen sound sources are verified.
If this is right
- Feature extraction models can now receive separate scores for timing accuracy and for content correspondence.
- Downstream multimodal tasks can be linked to one dimension or the other rather than to a single entangled metric.
- Evaluations become possible across voice, music, and ambient sound without one category dominating the combined score.
- The benchmark supplies 38,390 samples that can be used to isolate whether alignment failures stem from offset or from mismatch.
Where Pith is reading between the lines
- Designers of new models could optimize the temporal track without regard to semantic performance and vice versa.
- Similar decoupling might be applied to other paired modalities such as video-text or audio-text to reveal independent failure modes.
- If the separated scores prove stable, existing single-score leaderboards for audio-visual tasks could be replaced by paired leaderboards.
Load-bearing premise
Automatic filtering plus manual verification of in-the-wild videos produces a dataset where on-screen sound sources are reliably identified without introducing selection bias that affects the decoupled scores.
What would settle it
A result showing that model rankings on the new temporal-only and semantic-only tasks match the rankings produced by any existing coupled audio-visual synchronization benchmark.
Figures
read the original abstract
Audio-visual feature extraction is a fundamental component of multimodal understanding and generation tasks. However, existing evaluation protocols for feature extraction models exhibit dimensional bias, typically focusing on either semantic matching or temporal offset detection. Moreover, their data construction remains coupled, preventing independent assessment of temporal and semantic consistency. We propose AV-SyncBench, the first benchmark to fully separate temporal and semantic evaluation for audio-visual synchronization. Built from in-the-wild videos, it spans Voice, Music, and Sound across 10 scenarios and 5 challenge tasks. Data are automatically filtered and manually verified to ensure on-screen sound sources. The benchmark contains 3,269 videos and 38,390 samples, and we evaluate five representative models to quantify feature quality for alignment and downstream tasks. The code and dataset are available at: https://fgt7t6g.github.io/AV-SyncBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AV-SyncBench as the first benchmark to decouple temporal offset detection from semantic matching in audio-visual synchronization evaluation. It constructs a dataset of 3,269 in-the-wild videos (Voice/Music/Sound categories, 10 scenarios, 5 tasks) via automatic filtering plus manual verification to ensure on-screen sound sources, then evaluates five representative models on alignment quality and downstream tasks, with code and data released.
Significance. If the claimed decoupling holds without selection bias, the benchmark would enable independent diagnosis of temporal versus semantic failures in multimodal feature extractors, addressing a documented limitation of prior coupled protocols. The scale (38,390 samples) and public release would support reproducible progress in audio-visual understanding and generation.
major comments (2)
- [Abstract / Data construction] Abstract and data construction description: the central claim of 'fully separate temporal and semantic evaluation' rests on the assertion that automatic filtering plus manual verification reliably identifies on-screen sources without coupling the two dimensions, yet no quantitative check (e.g., correlation between temporal-task and semantic-task difficulty, or error rates from the verification step) is reported; this is load-bearing for the decoupling guarantee.
- [Evaluation section] Evaluation of five models: without reported inter-annotator agreement or false-positive rates from manual verification, it is unclear whether retained videos preferentially preserve natural correlations between visible lip motion and speech timing, which would undermine independent scoring on the five tasks.
minor comments (2)
- [Benchmark description] Clarify the exact definitions and sample counts for each of the five challenge tasks and how they map to the temporal versus semantic axes.
- [Dataset statistics] The abstract states '38,390 samples' but does not specify whether this counts clips, pairs, or annotations; add a table breaking down the dataset statistics by category and task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / Data construction] Abstract and data construction description: the central claim of 'fully separate temporal and semantic evaluation' rests on the assertion that automatic filtering plus manual verification reliably identifies on-screen sources without coupling the two dimensions, yet no quantitative check (e.g., correlation between temporal-task and semantic-task difficulty, or error rates from the verification step) is reported; this is load-bearing for the decoupling guarantee.
Authors: The primary mechanism for decoupling is the design of the five tasks themselves: temporal tasks evaluate offset detection via controlled shifts independent of content semantics, while semantic tasks evaluate matching via content mismatches without temporal offsets. Automatic filtering combined with manual verification ensures on-screen sources as a prerequisite for both task types to be valid, but this step does not couple the evaluation dimensions. We agree that explicit quantitative validation would strengthen the claim. In revision we will add correlation analysis between temporal-task and semantic-task difficulties and include available statistics on the verification step. revision: partial
-
Referee: [Evaluation section] Evaluation of five models: without reported inter-annotator agreement or false-positive rates from manual verification, it is unclear whether retained videos preferentially preserve natural correlations between visible lip motion and speech timing, which would undermine independent scoring on the five tasks.
Authors: The verification targets on-screen sound sources across Voice, Music, and Sound categories to support evaluation validity; the task construction (offset shifts for temporal tasks, content mismatches for semantic tasks) enables independent scoring regardless of residual natural correlations in the source videos. We did not originally report inter-annotator agreement or false-positive rates. We will revise the data construction section to provide a more detailed description of the verification protocol and, to the extent the original process permits, include agreement metrics or estimated error rates. revision: partial
Circularity Check
No circularity: benchmark proposal with no derivations or fitted predictions
full rationale
The paper proposes AV-SyncBench as a new dataset and evaluation protocol for audio-visual synchronization. It contains no equations, no fitted parameters, no predictions derived from prior results, and no self-citation chains that justify core claims. Data construction (automatic filtering + manual verification) is presented as a methodological choice rather than a derivation that reduces to its own inputs. The central claim—that the benchmark decouples temporal and semantic evaluation—rests on the dataset construction process itself, which is externally verifiable and not self-referential by construction. This matches the default expectation of no significant circularity for a benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AV-SyncBench: Decoupled Benchmarking of Temporal and Semantic Audio-Visual Synchronization
Introduction The inherent audio-visual alignment of video data provides an exceptionally rich supervisory signal for self-supervised learn- ing [1, 2]. High-quality features endowed with precise audio- visual alignment are not only foundational for multimodal un- derstanding tasks such as audio-visual event classification [3] and sound source localization...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Methodology We propose a comprehensive benchmarking pipeline to sys- tematically evaluate the synchronization capabilities of au- dio–visual feature extraction models by explicitly integrating decoupled assessments of temporal and semantic consistency, thereby addressing a critical gap in existing feature evaluation paradigms. The framework defines audio–...
-
[3]
Experiment 3.1. Setup All experiments are conducted on two NVIDIA H20 GPUs, with each job allocated 4 vCPUs (Intel Xeon Platinum 8469C). All models are evaluated using their officially released code- bases and pretrained checkpoints, without any additional train- ing or fine-tuning. We benchmark five representative au- dio–visual models, including Synchfo...
-
[4]
First, the semantic editing tasks rely on gener- ative methods such as DDSP and OpenV oice V2
Limitations Although A V-SyncBench provides a framework for decoupled evaluation of temporal and semantic consistency, several limi- tations remain. First, the semantic editing tasks rely on gener- ative methods such as DDSP and OpenV oice V2. While these methods preserve temporal structure, differences in generation mechanisms may introduce subtle acoust...
-
[5]
Conclusion This paper introduces A V-SyncBench, a benchmark designed to decouple the evaluation of temporal consistency and semantic consistency in audio–visual models. By constructing temporal perturbation and semantic editing tasks, the benchmark system- atically evaluates existing audio–visual feature extractors along two dimensions: fine-grained tempo...
-
[6]
These tools did not contribute to the creation of any sci- entific content, data, or conclusions
Generative AI Use Disclosure Generative AI tools were used exclusively to assist in editing and improving the manuscript’s language for better clarity and flow. These tools did not contribute to the creation of any sci- entific content, data, or conclusions. All authors thoroughly re- viewed and revised the final manuscript and are fully responsi- ble for...
-
[7]
Look, listen and learn,
R. Arandjelovi ´c and A. Zisserman, “Look, listen and learn,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[8]
Audio-visual scene analysis with self-supervised multisensory features,
A. Owens and A. A. Efros, “Audio-visual scene analysis with self-supervised multisensory features,” inProceedings of the Eu- ropean Conference on Computer Vision (ECCV), 2018, pp. 631– 648
2018
-
[9]
Audio-visual event localization in unconstrained videos,
Y . Tian, J. Shi, B. Li, Z. Duan, and C. Xu, “Audio-visual event localization in unconstrained videos,” inProceedings of the Euro- pean Conference on Computer Vision (ECCV), 2018
2018
-
[10]
The sound of pixels,
H. Zhao, C. Gan, A. Rouditchenko, C. V ondrick, J. McDermott, and A. Torralba, “The sound of pixels,” inProceedings of the Eu- ropean Conference on Computer Vision (ECCV), 2018, pp. 570– 586
2018
-
[11]
Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models,
S. Luo, C. Yan, C. Hu, and H. Zhao, “Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models,” 2023
2023
-
[12]
MMAudio: Taming multimodal joint training for high-quality video-to-audio synthesis,
H. K. Cheng, M. Ishii, A. Hayakawa, T. Shibuya, A. G. Schwing, and Y . Mitsufuji, “MMAudio: Taming multimodal joint training for high-quality video-to-audio synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2025, pp. 28 901–28 911
2025
-
[13]
FreeAudio: Training-free timing planning for controllable long-form text-to- audio generation,
Y . Jiang, Z. Chen, Z. Ju, C. Li, W. Dou, and J. Zhu, “FreeAudio: Training-free timing planning for controllable long-form text-to- audio generation,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9871–9880
2025
-
[14]
Y . Jiang, Z. Chen, Z. Ju, Y . Dai, W. Dou, and J. Zhu, “ControlAu- dio: Tackling text-guided, timing-indicated and intelligible au- dio generation via progressive diffusion modeling,”arXiv preprint arXiv:2510.08878, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
V ATT: Transformers for multimodal self- supervised learning from raw video, audio and text,
H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y . Cui, and B. Gong, “V ATT: Transformers for multimodal self- supervised learning from raw video, audio and text,” inAdvances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[16]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu, Y . Lv, Y . Wang, D. Guo, H. Wang, L. Ma, P. Zhang, X. Zhang, H. Hao, Z. Guo, B. Yang, B. Zhang, Z. Ma, X. Wei, S. Bai, K. Chen, X. Liu, P. Wang, M. Yang, D. Liu, X. Ren, B. Zheng, R. Men, F. Zhou, B. Yu, J. Yang, L. Yu, J. Zhou, and J. Lin, “Qwen3-Omni technical report,” 2025...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Kling-foley: Multimodal diffusion transformer for high-quality video-to-audio generation,
J. Wang, X. Zeng, C. Qiang, R. Chen, S. Wang, L. Wang, W. Zhou, P. Cai, J. Zhao, N. Li, Z. Li, Y . Liang, X. Wang, H. Zheng, M. Wen, K. Yin, Y . Wang, N. Li, F. Deng, L. Dong, C. Zhang, D. Zhang, and K. Gai, “Kling-foley: Multimodal diffusion transformer for high-quality video-to-audio generation,”
-
[18]
Available: https://arxiv.org/abs/2506.19774
[Online]. Available: https://arxiv.org/abs/2506.19774
-
[19]
Audio-visual synchronisation in the wild,
H. Chen, W. Xie, T. Afouras, A. Nagrani, A. Vedaldi, and A. Zisserman, “Audio-visual synchronisation in the wild,” 2021. [Online]. Available: https://arxiv.org/abs/2112.04432
-
[20]
Available: https://arxiv.org/abs/2206.04769
B. Elizalde, S. Deshmukh, M. A. Ismail, and H. Wang, “CLAP: Learning audio concepts from natural language supervision,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5. [Online]. Available: https://arxiv.org/abs/2206.04769
-
[21]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 15 180–15 190
2023
-
[22]
Contrastive audio-visual masked autoencoder,
Y . Gong, A. Rouditchenko, A. H. Liu, D. Harwath, L. Karlinsky, H. Kuehne, and J. R. Glass, “Contrastive audio-visual masked autoencoder,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=QPtMRyk5rb
2023
-
[23]
Sparse in space and time: Audio-visual synchronisation with trainable selectors,
V . Iashin, W. Xie, E. Rahtu, and A. Zisserman, “Sparse in space and time: Audio-visual synchronisation with trainable selectors,” inProceedings of the British Machine Vision Conference (BMVC), 2022. [Online]. Available: https://bmvc2022.mpi-inf. mpg.de/0395.pdf
2022
-
[24]
Synchformer: Efficient synchronization from sparse cues,
——, “Synchformer: Efficient synchronization from sparse cues,” inICASSP 2024 - 2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2024, pp. 5325– 5329
2024
-
[25]
DDSP: Differen- tiable digital signal processing,
J. Engel, L. Hantrakul, C. Gu, and A. Roberts, “DDSP: Differen- tiable digital signal processing,” inInternational Conference on Learning Representations, 2020
2020
-
[26]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780
2017
-
[27]
Vggsound: A large-scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vggsound: A large-scale audio-visual dataset,” inICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2020, pp. 721–725
2020
-
[28]
Openvoice: Versatile instant voice cloning,
Z. Qin, W. Zhao, X. Yu, and X. Sun, “Openvoice: Versatile instant voice cloning,” 2024, technical Report, arXiv v6 (last revised 18 Aug 2024). [Online]. Available: https://arxiv.org/abs/2312.01479
-
[29]
OpenV oiceV2 model card,
MyShell.ai, “OpenV oiceV2 model card,” Hugging Face, Apr. 2024, model release information for OpenV oice V2. [Online]. Available: https://huggingface.co/myshell-ai/OpenV oiceV2
2024
-
[30]
Cav-mae sync: Improving contrastive audio-visual mask au- toencoders via fine-grained alignment,
E. Araujo, A. Rouditchenko, Y . Gong, S. Bhati, S. Thomas, B. Kingsbury, L. Karlinsky, R. Feris, J. R. Glass, and H. Kuehne, “Cav-mae sync: Improving contrastive audio-visual mask au- toencoders via fine-grained alignment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2025, pp. 18 794–18 803
2025
-
[31]
Gemini 3 Flash: frontier intelligence built for speed,
T. Doshi, “Gemini 3 Flash: frontier intelligence built for speed,” Google The Keyword, Dec. 2025, accessed: 2026-03-05. [Online]. Available: https://blog.google/products-and-platforms/ products/gemini/gemini-3-flash/
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.