Arabic Sentence Segmentation Across Genres and Punctuation Conditions
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Lightweight encoder models outperform large language models on Arabic sentence segmentation when punctuation is ambiguous or missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the AraSEG corpus, lightweight encoder models and dependency parser-based systems achieve higher sentence segmentation accuracy than LLMs under the most challenging punctuation conditions; performance saturates with more training data, cross-genre generalization is difficult, and accurate segmentation measurably improves downstream dependency parsing.
What carries the argument
AraSEG, a multi-genre corpus of Arabic texts annotated for sentence boundaries across eight genres and wide ranges of punctuation presence and document structure.
If this is right
- Accurate sentence segmentation substantially improves performance on downstream dependency parsing.
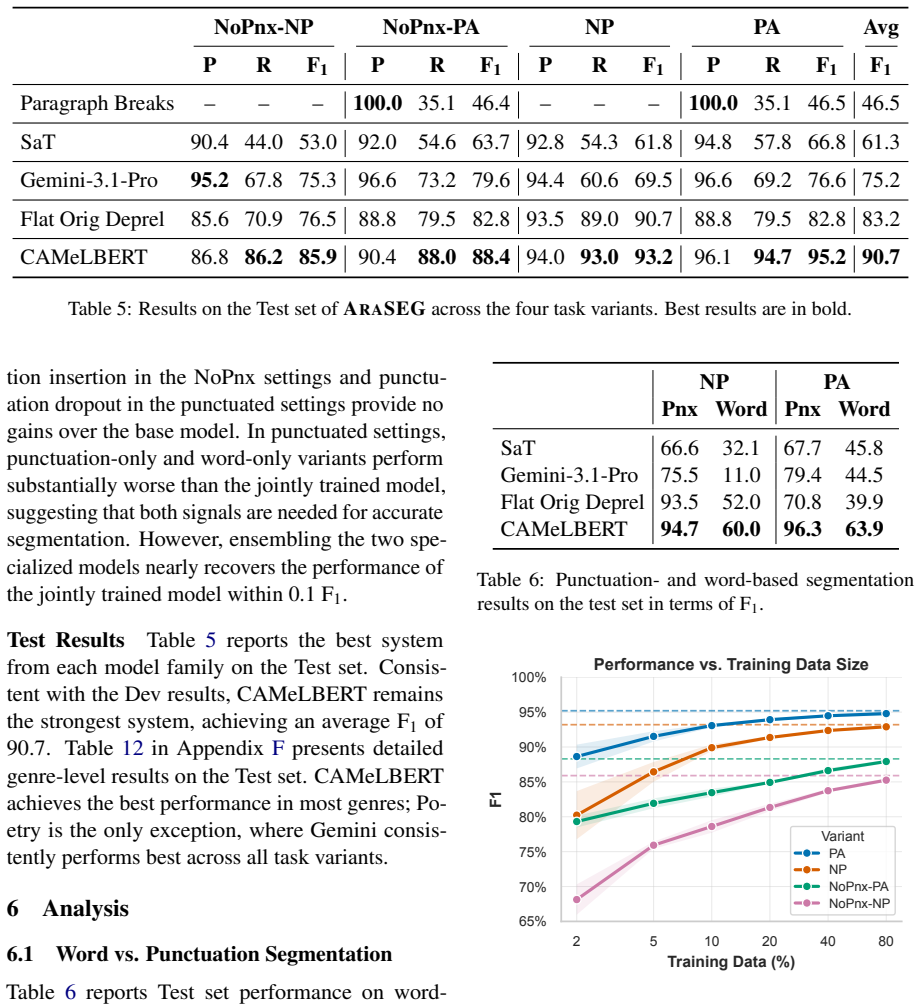
- Model performance on sentence segmentation eventually saturates as training data size grows.
- Cross-genre generalization for Arabic sentence segmentation remains challenging even with diverse training data.
Where Pith is reading between the lines
- The pattern suggests that for noisy or low-punctuation text, task-specific small models may remain preferable to general-purpose LLMs even as the latter scale.
- Similar genre-diverse evaluation setups could be applied to sentence segmentation in other languages that share punctuation ambiguity problems.
- Integrating dependency parsing signals directly into segmentation training may offer a reusable strategy for other sequence-labeling tasks with weak boundary cues.
Load-bearing premise
The eight genres and punctuation conditions collected in AraSEG are representative of the range of real-world Arabic text that downstream applications encounter.
What would settle it
A new Arabic test set drawn from additional genres or real documents with punctuation patterns outside those in AraSEG on which LLMs achieve higher segmentation accuracy than the lightweight encoders.
Figures

read the original abstract
Sentence segmentation in Arabic is challenging due to ambiguous and inconsistent punctuation, with many texts lacking reliable sentence boundary markers. Existing approaches rely heavily on punctuation cues and are typically evaluated on well-formed text, limiting their robustness in realistic Arabic settings. To address this, we introduce AraSEG, a genre-diverse sentence segmentation corpus spanning eight genres and a wide range of punctuation and document structure conditions. Using AraSEG, we evaluate LLMs, lightweight encoder models, and dependency parser-based models under increasingly challenging segmentation settings. Our experiments show that lightweight encoders, and even dependency parser-based models, outperform LLMs in the most challenging settings. We further investigate the effects of training data size and genre diversity, finding that performance eventually saturates and cross-genre generalization remains challenging. We also demonstrate that accurate sentence segmentation substantially improves downstream dependency parsing. We make our code, data, and models publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AraSEG, a new genre-diverse corpus for Arabic sentence segmentation spanning eight genres and a range of punctuation and document-structure conditions. It evaluates LLMs, lightweight encoder models, and dependency parser-based models under increasingly challenging settings, reporting that lightweight encoders and dependency parsers outperform LLMs in the hardest cases. Additional experiments examine training data size and genre diversity, finding performance saturation and persistent cross-genre generalization difficulties; the work also shows that accurate segmentation improves downstream dependency parsing. Code, data, and models are released publicly.
Significance. If the empirical results hold under broader conditions, the paper supplies a useful public benchmark that questions the default preference for LLMs on Arabic segmentation tasks and demonstrates practical downstream gains. The explicit release of resources is a clear strength that supports reproducibility and follow-on work. The saturation and cross-genre observations usefully temper expectations for scaling-based solutions.
major comments (1)
- [Abstract and §4] Abstract and §4 (experiments): the central claim that lightweight encoders and dependency-parser models outperform LLMs in the most challenging settings is evaluated exclusively on AraSEG. Because the abstract itself notes that cross-genre generalization remains challenging, the representativeness of the eight selected genres plus punctuation conditions is load-bearing for any practical recommendation; no quantitative justification or external validation of genre coverage is provided.
minor comments (1)
- [Abstract] The abstract states that performance saturates with more data; the corresponding learning curves or data-size ablation table should be referenced explicitly in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the scope of our claims regarding AraSEG. We address the concern about genre representativeness and the load-bearing nature of the eight genres below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the central claim that lightweight encoders and dependency-parser models outperform LLMs in the most challenging settings is evaluated exclusively on AraSEG. Because the abstract itself notes that cross-genre generalization remains challenging, the representativeness of the eight selected genres plus punctuation conditions is load-bearing for any practical recommendation; no quantitative justification or external validation of genre coverage is provided.
Authors: We agree that all reported results are specific to AraSEG and that the abstract explicitly flags cross-genre generalization difficulties. AraSEG was constructed precisely to fill the absence of any prior genre-diverse Arabic sentence segmentation resource; the eight genres were chosen to span formal/informal registers, literary, journalistic, legal, religious, and social-media styles that exhibit systematically different punctuation reliability and document structures (detailed in §3). Performance variation across these genres in our experiments provides internal evidence of diversity. Because no comparable annotated Arabic corpora exist, quantitative external validation (e.g., genre-overlap metrics against other resources) is not feasible; the benchmark itself constitutes the first such testbed. The central claim is therefore scoped to “the most challenging settings represented in AraSEG” rather than universal superiority. We are happy to expand the genre-selection rationale and limitations discussion in a revision if the editor deems it useful. revision: partial
Circularity Check
Empirical benchmark study with new dataset; no circularity in performance claims or derivations
full rationale
The paper introduces the AraSEG corpus spanning eight genres and punctuation conditions, then reports direct experimental comparisons of LLMs, lightweight encoders, and dependency parsers on segmentation tasks under varying difficulty settings. The central performance claims (lightweight models outperforming LLMs in challenging conditions) are obtained by training and evaluating models on the newly collected data splits; no equations, fitted parameters, or self-citations are used to derive or redefine these metrics. The study contains no derivation chain that reduces outputs to inputs by construction, and the representativeness of the genres is presented as an empirical assumption rather than a self-referential result. This is a standard self-contained benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The collected genres and punctuation conditions in AraSEG constitute a valid proxy for real-world Arabic text variability.
Reference graph
Works this paper leans on
-
[1]
Ahmed Abdelali, Kareem Darwish, Nadir Durrani, and Hamdy Mubarak. 2016. Farasa: A fast and furious segmenter for A rabic. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 11--16, San Diego, California
2016
-
[2]
Abbas Mahmoud Al-Akkad. 1938. https://www.hindawi.org/books/72707304/ Sarah . Hindawi
arXiv 1938
-
[3]
Imam Muhammad al Bukhari. 846. Sahih al-Bukhari. Dar Ibn Khathir
-
[4]
Bayan Al-Safadi. 2005. Al-Kashkoul: selection of poetry and prose for children ( \<الكشكول: مختارات من الشعر والنثر للأطفال> ) . Al-Sa'ih Library ( \<مكتبة السائح> )
2005
-
[5]
Mai Alammar, Khalil El Hindi, and Hend Al-Khalifa. 2025. https://doi.org/10.3390/computation13060151 English-arabic hybrid semantic text chunking based on fine-tuning bert . Computation, 13(6)
-
[6]
A. Alfaifi. 2015. https://doi.org/10.13140/RG.2.2.32081.53608 Building the Arabic Learner Corpus and a System for Arabic Error Annotation . Ph.D. thesis, University of Leeds
-
[7]
Bashar Alhafni, Go Inoue, Christian Khairallah, and Nizar Habash. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.396 Advancements in A rabic grammatical error detection and correction: An empirical investigation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6430--6448, Singapore. Association for Comp...
-
[8]
Alshanqiti, Sami Albouq, Ahmad B
Abdullah M. Alshanqiti, Sami Albouq, Ahmad B. Alkhodre, Abdallah Namoun, and Emad Nabil. 2022. https://doi.org/10.3390/app122010559 Employing a multilingual transformer model for segmenting unpunctuated arabic text . Applied Sciences, 12(20)
-
[9]
Shatha Altammami, Eric Atwell, and Ammar Alsalka. 2019. The arabic--english parallel corpus of authentic hadith. International Journal on Islamic Applications in Computer Science And Technology-IJASAT
2019
-
[10]
Touir Ameur, Mathkour Hassan, and Al-Sanea Waleed. 2008. https://doi.org/10.3923/itj.2008.1009.1015 Semantic-based segmentation of arabic texts . Information Technology Journal, 7
-
[11]
Mohamed Anwar, Abdelhakim Freihat, George Ibrahim, Mostafa Awad, Abdelrahman Atef Mohamed Ali Sadallah, Gurpreet Gosal, Gokul Ramakrishnan, Sarath Chandran, Biswajit Mishra, Rituraj Joshi, Ahmed Frikha, Etienne Goffinet, Abhishek Maiti, Ali El Filali, Sarah Al Barri, Samujjwal Ghosh, Rahul Pal, Parvez Mullah, Awantika Shukla, and 41 others. 2025. Jais 2: ...
2025
-
[12]
Doug Beeferman, Adam Berger, and John Lafferty. 1999. https://doi.org/10.1023/A:1007506220214 Statistical models for text segmentation . Machine Learning, 34(1):177--210
-
[13]
Guy Bilitski, Lev Shechter, Sonam Jamtsho, Nir Marciano, Nicola Bajetta, Rebecca Sunden, Omri Drori, Kai Golan Hashiloni, Orr Zwebner, Asaf Shina, Orna Almogi, Dorji Wangchuk, and Kfir Bar. 2026. https://doi.org/10.63317/2iyfjjv9boc6 Automatic segmentation of classical tibetan texts into autochthonous and allochthonous regions . In Proceedings of the Fift...
-
[14]
Houda Bouamor, Nizar Habash, Mohammad Salameh, Wajdi Zaghouani, Owen Rambow, Dana Abdulrahim, Ossama Obeid, Salam Khalifa, Fadhl Eryani, Alexander Erdmann, and Kemal Oflazer. 2018. https://aclanthology.org/L18-1535/ The MADAR A rabic dialect corpus and lexicon . In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (...
2018
-
[15]
Kirill Chirkunov, Younes Samih, Abed Alhakim Freihat, and Hanan Aldarmaki. 2026. https://arxiv.org/abs/2605.06276 Linear semantic segmentation for low-resource spoken dialects . Preprint, arXiv:2605.06276
Pith/arXiv arXiv 2026
-
[16]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, and 3416 others. 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pus...
Pith/arXiv arXiv 2025
-
[17]
Timothy Dozat and Christopher D. Manning. 2016. https://arxiv.org/abs/1611.01734 Deep biaffine attention for neural dependency parsing . CoRR, abs/1611.01734
Pith/arXiv arXiv 2016
-
[18]
Kais Dukes, Eric Atwell, and Nizar Habash. 2013. Supervised collaboration for syntactic annotation of quranic arabic. Language resources and evaluation, 47(1):33--62
2013
-
[19]
Matthias Eck and Chiori Hori. 2005. https://aclanthology.org/2005.iwslt-1.1/ Overview of the IWSLT 2005 evaluation campaign . In Proceedings of the Second International Workshop on Spoken Language Translation, Pittsburgh, Pennsylvania, USA
2005
-
[20]
Mo El-Haj and Saad Ezzini. 2024. https://aclanthology.org/2024.osact-1.7/ The multilingual corpus of world ' s constitutions ( MCWC ) . In Proceedings of the 6th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT) with Shared Tasks on Arabic LLMs Hallucination and Dialect to MSA Machine Translation @ LREC-COLING 2024, pages 57--66, Torino,...
2024
-
[21]
Elmadani, Nizar Habash, and Hanada Taha-Thomure
Khalid N. Elmadani, Nizar Habash, and Hanada Taha-Thomure. 2025. https://doi.org/10.18653/v1/2025.findings-acl.842 A large and balanced corpus for fine-grained A rabic readability assessment . In Findings of the Association for Computational Linguistics: ACL 2025, pages 16376--16400, Vienna, Austria. Association for Computational Linguistics
-
[22]
Ahmed Elshabrawy, Muhammed AbuOdeh, Go Inoue, and Nizar Habash. 2023. https://doi.org/10.18653/v1/2023.arabicnlp-1.15 C amel P arser2.0: A state-of-the-art dependency parser for A rabic . In Proceedings of ArabicNLP 2023, pages 170--180, Singapore (Hybrid). Association for Computational Linguistics
-
[23]
Markus Frohmann, Igor Sterner, Ivan Vuli \'c , Benjamin Minixhofer, and Markus Schedl. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.665 Segment any text: A universal approach for robust, efficient and adaptable sentence segmentation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11908--11941, Miami,...
-
[24]
Nizar Habash, Muhammed AbuOdeh, Dima Taji, Reem Faraj, Jamila El Gizuli, and Omar Kallas. 2022. https://aclanthology.org/2022.lrec-1.286/ Camel treebank: An open multi-genre A rabic dependency treebank . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 2672--2681, Marseille, France. European Language Resources Association
2022
-
[25]
Nizar Habash and David Palfreyman. 2022. https://aclanthology.org/2022.lrec-1.9/ ZAEBUC : An annotated A rabic- E nglish bilingual writer corpus . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 79--88, Marseille, France. European Language Resources Association
2022
-
[26]
Nizar Habash, Abdelhadi Soudi, and Tim Buckwalter. 2007. On A rabic Transliteration . In A. van den Bosch and A. Soudi, editors, A rabic Computational Morphology: Knowledge-based and Empirical Methods , pages 15--22. Springer, Netherlands
2007
-
[27]
Lamia Hadrich Belguith, Leila Baccour, and Mourad Ghassan. 2005. https://aclanthology.org/2005.jeptalnrecital-court.12/ Segmentation de textes arabes bas \'e e sur l ' analyse contextuelle des signes de ponctuations et de certaines particules . In Actes de la 12 \`e me conf \'e rence sur le Traitement Automatique des Langues Naturelles. Articles courts , ...
2005
-
[28]
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. https://doi.org/10.5281/zenodo.1212303 spacy: Industrial-strength natural language processing in python
-
[29]
Go Inoue, Bashar Alhafni, Nurpeiis Baimukan, Houda Bouamor, and Nizar Habash. 2021. https://aclanthology.org/2021.wanlp-1.10/ The interplay of variant, size, and task type in A rabic pre-trained language models . In Proceedings of the Sixth Arabic Natural Language Processing Workshop, pages 92--104, Kyiv, Ukraine (Virtual). Association for Computational L...
2021
-
[30]
Iskandar Keskes, Farah Benamara, and Lamia Hadrich Belguith. 2012. https://aclanthology.org/L12-1559/ Clause-based discourse segmentation of A rabic texts . In Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12) , pages 2826--2832, Istanbul, Turkey. European Language Resources Association (ELRA)
2012
-
[31]
Muhamed Al Khalil, Hind Saddiki, Nizar Habash, and Latifa Alfalasi. 2018. A Leveled Reading Corpus of Modern Standard A rabic . In Proceedings of the Language Resources and Evaluation Conference (LREC), Miyazaki, Japan
2018
-
[32]
Tibor Kiss and Jan Strunk. 2006. https://doi.org/10.1162/coli.2006.32.4.485 Unsupervised multilingual sentence boundary detection . Computational Linguistics, 32(4):485--525
-
[33]
Fajri Koto, Haonan Li, Sara Shatnawi, Jad Doughman, Abdelrahman Sadallah, Aisha Alraeesi, Khalid Almubarak, Zaid Alyafeai, Neha Sengupta, Shady Shehata, Nizar Habash, Preslav Nakov, and Timothy Baldwin. 2024. https://doi.org/10.18653/v1/2024.findings-acl.334 A rabic MMLU : Assessing massive multitask language understanding in A rabic . In Findings of the ...
-
[34]
Pierre Lison and J \"o rg Tiedemann. 2016. Open S ubtitles2016: E xtracting L arge P arallel C orpora from M ovie and TV S ubtitles. In Proceedings of the Language Resources and Evaluation Conference (LREC), Portoro z , Slovenia
2016
-
[35]
Zhichen Liu, Yongyuan Li, and Yang Xu. 2026. https://arxiv.org/abs/2604.10135 Think in sentences: Explicit sentence boundaries enhance language model's capabilities . Preprint, arXiv:2604.10135
Pith/arXiv arXiv 2026
-
[36]
Asma Mekki, In \`e s Zribi, Mariem Ellouze, and Lamia Hadrich Belguith. 2022. https://doi.org/10.1007/s10579-021-09538-4 Sentence boundary detection of various forms of tunisian arabic . Language Resources and Evaluation, 56(1):357--385
-
[37]
Benjamin Minixhofer, Jonas Pfeiffer, and Ivan Vuli \'c . 2023. https://doi.org/10.18653/v1/2023.acl-long.398 Where ' s the point? self-supervised multilingual punctuation-agnostic sentence segmentation . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7215--7235, Toronto, Canada. As...
-
[38]
Behrang Mohit, Alla Rozovskaya, Nizar Habash, Wajdi Zaghouani, and Ossama Obeid. 2014. https://doi.org/10.3115/v1/W14-3605 The first QALB shared task on automatic text correction for A rabic . In Proceedings of the EMNLP 2014 Workshop on A rabic Natural Language Processing ( ANLP ) , pages 39--47, Doha, Qatar. Association for Computational Linguistics
-
[39]
Joakim Nivre and Chiao-Ting Fang. 2017. https://aclanthology.org/W17-0411/ U niversal D ependency evaluation . In Proceedings of the N o D a L i D a 2017 Workshop on Universal Dependencies ( UDW 2017) , pages 86--95, Gothenburg, Sweden. Association for Computational Linguistics
2017
-
[40]
Ossama Obeid, Nasser Zalmout, Salam Khalifa, Dima Taji, Mai Oudah, Bashar Alhafni, Go Inoue, Fadhl Eryani, Alexander Erdmann, and Nizar Habash. 2020. https://aclanthology.org/2020.lrec-1.868/ CAM e L tools: An open source python toolkit for A rabic natural language processing . In Proceedings of the Twelfth Language Resources and Evaluation Conference, pa...
2020
-
[41]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, and 262 others. 2024. https://arxiv.org/abs/2303.08774 Gpt-4 technical r...
Pith/arXiv arXiv 2024
-
[42]
Lev Pevzner and Marti A. Hearst. 2002. https://doi.org/10.1162/089120102317341756 A critique and improvement of an evaluation metric for text segmentation . Computational Linguistics, 28(1):19--36
-
[43]
Wenjie Qiu, Yi-Chen Li, Xuqin Zhang, Tianyi Zhang, Yihang Zhang, Zongzhang Zhang, and Yang Yu. 2025. https://arxiv.org/abs/2503.04793 Sentence-level reward model can generalize better for aligning llm from human preference . Preprint, arXiv:2503.04793
arXiv 2025
-
[44]
Fabian Retkowski and Alexander Waibel. 2026. https://doi.org/10.63317/3eczsids4mek Paragraph segmentation revisited: Towards a standard task for structuring speech . In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 747--759, Palma, Mallorca, Spain. European Language Resources Association (ELRA)
-
[45]
Nipun Sadvilkar and Mark Neumann. 2020. https://doi.org/10.18653/v1/2020.nlposs-1.15 P y SBD : Pragmatic sentence boundary disambiguation . In Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), pages 110--114, Online. Association for Computational Linguistics
-
[46]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, and 467 others. 2026. https://arxiv.org/abs/2601.03267 Openai gpt-5 system ca...
Pith/arXiv arXiv 2026
-
[47]
Eli Smith and Cornelius Van Dyck. 1860. New Testament (Arabic Translation)
-
[48]
Eli Smith and Cornelius Van Dyck. 1865. Old Testament (Arabic Translation)
-
[49]
Hanada Taha-Thomure. 2007. Poems and News ( \<أشعار وأخبار> ) . Educational Book House ( \<دار الكتاب التربوي للنشر والتوزيع>)
2007
-
[50]
Toshiyuki Takezawa, Genichiro Kikui, Masahide Mizushima, and Eiichiro Sumita. 2007. https://aclanthology.org/O07-5005/ Multilingual spoken language corpus development for communication research . In International Journal of Computational Linguistics & C hinese Language Processing, Volume 12, Number 3, September 2007: Special Issue on Invited Papers from I...
2007
-
[51]
FANAR TEAM, Ummar Abbas, Mohammad Shahmeer Ahmad, Minhaj Ahmad, Abdulaziz Al-Homaid, Anas Al-Nuaimi, Enes Altinisik, Ehsaneddin Asgari, Sanjay Chawla, Shammur Chowdhury, Fahim Dalvi, Kareem Darwish, Nadir Durrani, Mohamed Elfeky, Ahmed Elmagarmid, Mohamed Eltabakh, Asim Ersoy, Masoomali Fatehkia, Mohammed Qusay Hashim, and 18 others. 2026. https://arxiv.o...
arXiv 2026
-
[52]
Ibn Tufail. 1150. https://www.hindawi.org/books/90463596/ Hayy ibn Yaqdhan . Hindawi
-
[53]
12th century
Unknown. 12th century. One Thousand and One Nights
-
[54]
Rachel Wicks and Matt Post. 2021. https://doi.org/10.18653/v1/2021.acl-long.309 A unified approach to sentence segmentation of punctuated text in many languages . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pag...
-
[55]
Nan Xu and Xuezhe Ma. 2025. https://doi.org/10.18653/v1/2025.naacl-long.172 LLM the genius paradox: A linguistic and math expert ' s struggle with simple word-based counting problems . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
-
[56]
Sane Yagi, Shehdeh Fareh, Ashraf Elnagar, Mariam Balajeed, Abdalla El-mneizel, and Mohammad Al-Badawi. 2024. https://doi.org/10.1080/23311983.2024.2303818 Is A rabic punctuation rule-governed? Cogent Arts & Humanities, 11(1):2303818
-
[57]
Wajdi Zaghouani and Dana Awad. 2016. Toward an A rabic punctuated corpus: Annotation guidelines and evaluation. In The 2nd Workshop on Arabic Corpora and Processing Tools 2016 Theme: Social Media, page 22
2016
-
[58]
Wajdi Zaghouani, Behrang Mohit, Nizar Habash, Ossama Obeid, Nadi Tomeh, Alla Rozovskaya, Noura Farra, Sarah Alkuhlani, and Kemal Oflazer. 2014. Large Scale A rabic Error Annotation: Guidelines and Framework . In Proceedings of the Language Resources and Evaluation Conference (LREC), Reykjavik, Iceland
2014
-
[59]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. 2025. https://arxiv.org/abs/2507.18071 Group sequence policy optimization . Preprint, arXiv:2507.18071
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.