SAGA: Scene-Aware, Goal-Evolving Agents for Long-Horizon CivRealm Strategy Planning
Pith reviewed 2026-06-30 06:19 UTC · model grok-4.3
The pith
SAGA's three mechanisms let LLM agents reach higher civilization scores in FreeCiv by fixing scene blindness, context overload, and isolated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
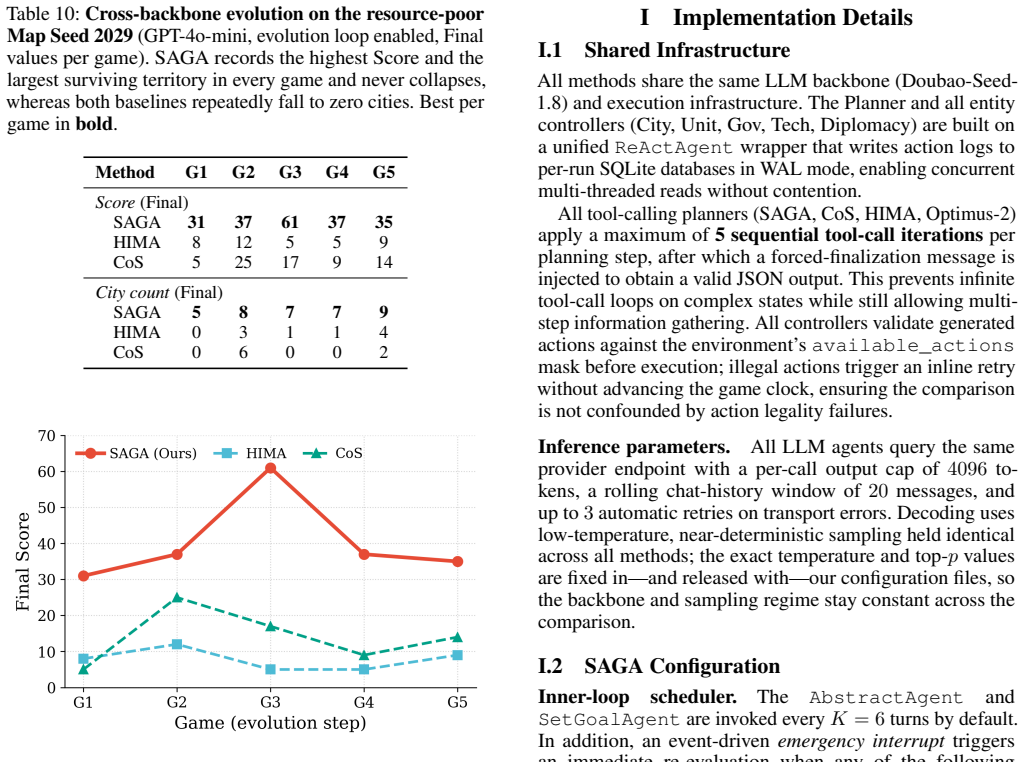
SAGA attains the highest mean civilization score with lower variance than the two strongest baselines, is the only method that significantly surpasses every baseline on infrastructure construction, outscores the two strongest baselines in most head-to-head games while cutting output tokens by 27 percent, and equipped with the cross-game evolution module reaches the highest end-of-chain score across five successive episodes.
What carries the argument
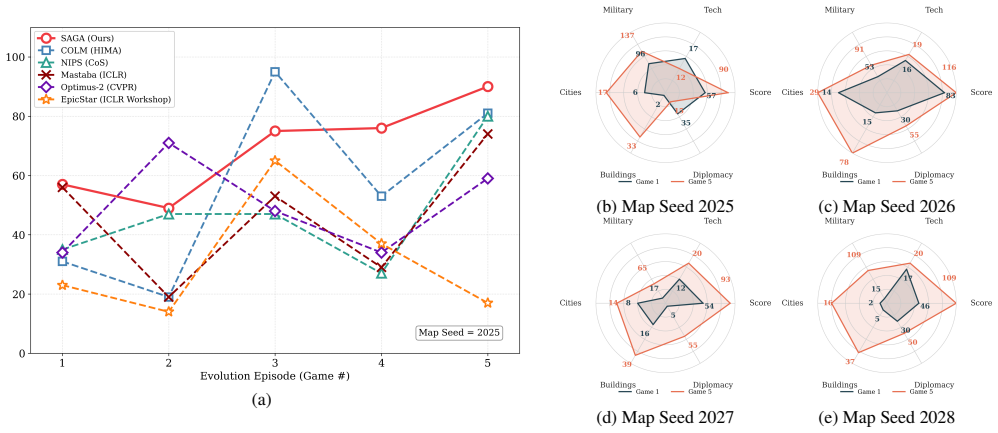
Map-Semantic Scene Graph, Tool-Augmented Planner, and Dual-Horizon Feedback Loop, each addressing one stated failure mode in LLM strategy agents.
If this is right
- Infrastructure construction improves without trade-offs against other objectives.
- Output token count drops by 27 percent while head-to-head wins increase.
- Cross-game causal post-mortems enable rising scores over successive episodes without manual reward design.
- Each of the three components contributes measurably on its own, per the reported ablations.
Where Pith is reading between the lines
- The scene-graph approach might transfer to other spatial or imperfect-information settings where raw coordinates cause planning errors.
- On-demand domain tools could lower the risk of constraint violations in any multi-domain LLM controller.
- Structured cross-episode post-mortems offer a route to continual adaptation that does not rely on environment-specific rewards.
Load-bearing premise
The three mechanisms each directly and independently fix one failure mode and that FreeCiv metrics plus baselines isolate those fixes without prompt or environment confounds.
What would settle it
An ablation that removes one mechanism yet shows no matching drop in the corresponding metric, or a new baseline that matches SAGA scores without any of the three components.
Figures
read the original abstract
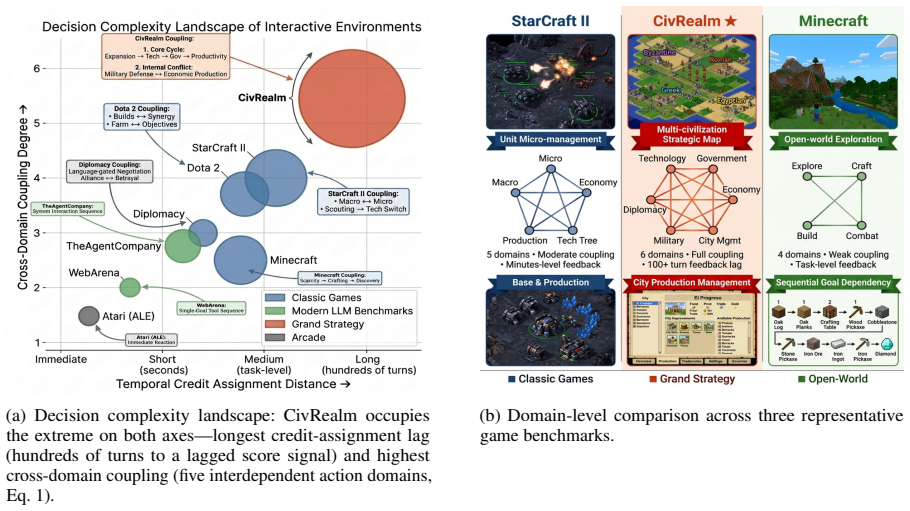
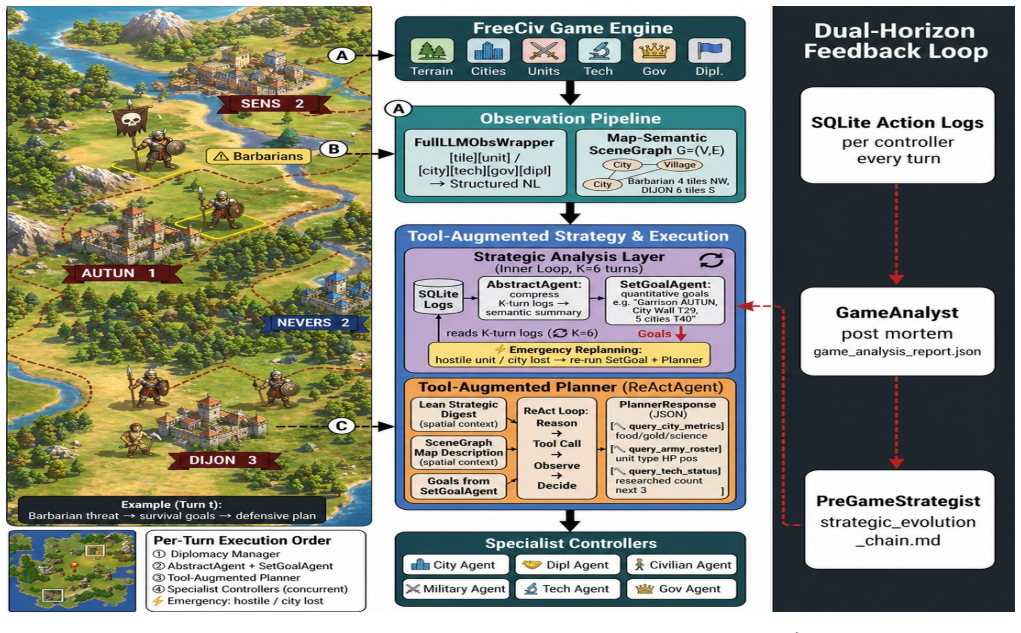
Long-horizon strategic planning in complex strategy games demands concurrent reasoning across multiple decision domains under imperfect information and sparse reward. Existing LLM-based agents suffer from three systematic failures: scene blindness from raw tile coordinates, context overflow and domain coupling from monolithic state dumps, and shallow cross-game learning that treats each episode in isolation. We present SAGA, an LLM multi-agent framework with three mechanisms each directly targeting one class of failure: (i) a Map-Semantic Scene Graph that encodes typed spatial relations among game entities into per-unit natural-language context, resolving spatial blindness without global token inflation; (ii) a Tool-Augmented Planner that pulls fine-grained domain state on demand and dispatches per-domain directives to dedicated specialist controllers, eliminating context overflow, domain coupling, and mechanical constraint violations; and (iii) a Dual-Horizon Feedback Loop that combines periodic within-game goal generation with structured cross-game causal post-mortem, enabling principled strategic evolution without manual reward engineering. Evaluated on FreeCiv, SAGA attains the highest mean civilization score -- the environment's sole sparse objective reward -- with lower variance than the two strongest baselines, and is the only method that significantly surpasses every baseline on infrastructure construction, the resource axis most readily sacrificed under multi-objective conflict. It outscores the two strongest baselines in most head-to-head games while cutting output tokens (the dominant decoding cost) by 27%. Equipped with the cross-game evolution module, SAGA reaches the highest end-of-chain score across five successive episodes. Ablation studies confirm that each architectural component contributes independently to this advantage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGA, an LLM-based multi-agent framework for long-horizon strategy planning in CivRealm (FreeCiv). It identifies three failure modes in existing agents (scene blindness from raw coordinates, context overflow/domain coupling from monolithic states, and shallow cross-game learning) and proposes three targeted mechanisms: (i) a Map-Semantic Scene Graph encoding typed spatial relations into per-unit natural-language context, (ii) a Tool-Augmented Planner that fetches domain-specific state on demand and dispatches to specialist controllers, and (iii) a Dual-Horizon Feedback Loop combining within-game goal generation with cross-game causal post-mortems. On FreeCiv, SAGA reports the highest mean civilization score with lower variance than strong baselines, is the only method to significantly outperform all baselines on infrastructure construction, reduces output tokens by 27%, wins most head-to-head games against top baselines, and achieves the highest end-of-chain score over five successive episodes when using the evolution module. Ablations are stated to confirm independent contributions from each component.
Significance. If the empirical claims hold under rigorous controls, SAGA would provide a concrete, modular architecture for improving LLM agents on sparse-reward, multi-domain, long-horizon tasks. The explicit mapping of mechanisms to failure modes, the use of a standard strategy-game benchmark, and the reported gains in both performance and token efficiency would be useful reference points for the community. The cross-game evolution component is particularly noteworthy as an attempt at principled meta-learning without manual reward design.
major comments (2)
- [Experiments / Ablation studies] Experiments / Ablation studies: The central attribution—that each of the three mechanisms independently resolves one failure mode and that the observed gains are not due to overall prompt structure or baseline prompt quality—requires a factorial ablation design or at least matched-prompt controls that vary only the claimed component. The manuscript does not appear to report such controls, leaving open the possibility that the reported superiority on civilization score, infrastructure, variance, and token count arises from differences in prompt engineering rather than the scene-graph or post-mortem modules specifically.
- [Evaluation protocol] Evaluation protocol: No details are supplied on the number of independent runs, statistical tests (e.g., significance thresholds for “significantly surpasses every baseline”), random seeds, or exact baseline implementations and prompt templates. Without these, it is impossible to verify that the head-to-head wins, infrastructure gains, and 27% token reduction are reproducible and attributable to the claimed mechanisms rather than environment-specific tuning.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction should explicitly state the total number of episodes, the precise definition of “civilization score,” and the token-budget matching procedure used for baselines.
- [Methods] Notation for the scene graph (typed relations, per-unit context construction) and the exact interface of the Tool-Augmented Planner would benefit from a small diagram or pseudocode in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger experimental controls and reproducibility details. We address each major comment below and will revise the manuscript to incorporate additional ablations and protocol information.
read point-by-point responses
-
Referee: [Experiments / Ablation studies] The central attribution—that each of the three mechanisms independently resolves one failure mode and that the observed gains are not due to overall prompt structure or baseline prompt quality—requires a factorial ablation design or at least matched-prompt controls that vary only the claimed component. The manuscript does not appear to report such controls, leaving open the possibility that the reported superiority on civilization score, infrastructure, variance, and token count arises from differences in prompt engineering rather than the scene-graph or post-mortem modules specifically.
Authors: We agree that a factorial design or matched-prompt controls would provide stronger isolation of each mechanism's contribution. Our existing ablations remove one component at a time from the full SAGA framework while preserving overall structure, and these show independent gains; however, they do not fully rule out prompt-engineering confounds. In the revision we will add a new set of matched-prompt controls that vary only the targeted component (e.g., scene-graph encoding versus equivalent-length raw-coordinate prompts) and report the resulting performance deltas. revision: yes
-
Referee: [Evaluation protocol] No details are supplied on the number of independent runs, statistical tests (e.g., significance thresholds for “significantly surpasses every baseline”), random seeds, or exact baseline implementations and prompt templates. Without these, it is impossible to verify that the head-to-head wins, infrastructure gains, and 27% token reduction are reproducible and attributable to the claimed mechanisms rather than environment-specific tuning.
Authors: We acknowledge the omission of these reproducibility details. The revised manuscript will include: the exact number of independent runs and random seeds used, the statistical tests and significance thresholds applied to claims of outperformance, and the full prompt templates plus baseline implementation details placed in an appendix. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical LLM multi-agent framework evaluated via head-to-head experiments and ablations on FreeCiv. Claims rest on observed scores, variance reductions, token savings, and component contributions rather than any mathematical derivation, equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps reduce to inputs by construction; the work is self-contained against external environment metrics and baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural-language descriptions of typed spatial relations suffice for LLM spatial reasoning in tile-based games
- domain assumption Per-domain specialist controllers can be dispatched without introducing new coupling or constraint violations
invented entities (3)
-
Map-Semantic Scene Graph
no independent evidence
-
Tool-Augmented Planner
no independent evidence
-
Dual-Horizon Feedback Loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CivRealm: A learning and reasoning odyssey in Civilization for decision-making agents
Siyuan Qi et al. CivRealm: A learning and reasoning odyssey in Civilization for decision-making agents. In Proc. ICLR, 2024
2024
-
[2]
Large language models play StarCraft II: Benchmarks and a chain of summarization approach
Weiyu Ma et al. Large language models play StarCraft II: Benchmarks and a chain of summarization approach. InAdvances in NeurIPS, 2024
2024
-
[3]
LLMs are not good strate- gists, yet memory-enhanced agency boosts reasoning
Yi Wu and Zhimin Hu. LLMs are not good strate- gists, yet memory-enhanced agency boosts reasoning. InICLR Workshop on Reasoning and Planning for LLMs, 2025
2025
-
[4]
Daechul Ahn, San Kim, and Jonghyun Choi. Society of mind meets real-time strategy: A hierarchical multi- agent framework for strategic reasoning.arXiv preprint arXiv:2408.15567, 2025
-
[5]
Optimus-2: Multimodal Minecraft agent with goal-observation-action conditioned policy
Zaijing Li et al. Optimus-2: Multimodal Minecraft agent with goal-observation-action conditioned policy. InProc. CVPR, 2025
2025
-
[6]
Rong Wu et al. EvolveR: Self-evolving LLM agents through an experience-driven lifecycle.arXiv preprint arXiv:2412.04843, 2025
-
[7]
SE-Agent: Self-evolution trajectory optimization in multi-step reasoning with LLM-based agents
Yifu Guo et al. SE-Agent: Self-evolution trajectory optimization in multi-step reasoning with LLM-based agents. InAdvances in NeurIPS, 2025
2025
-
[8]
SiriuS: Self-improving multi-agent systems via bootstrapped reasoning
Wanjia Zhao, Mert Yuksekgonul, Shirley Wu, and James Zou. SiriuS: Self-improving multi-agent systems via bootstrapped reasoning. InAdvances in NeurIPS, 2025
2025
-
[9]
The Hanabi challenge: A new fron- tier for AI research.Artificial Intelligence, 280:103216, 2020
Nolan Bard et al. The Hanabi challenge: A new fron- tier for AI research.Artificial Intelligence, 280:103216, 2020
2020
-
[10]
Leibo et al
Joel Z. Leibo et al. Scalable evaluation of multi-agent re- inforcement learning with Melting Pot. InProc. ICML, pp. 6187–6199, 2021
2021
-
[11]
Dota 2 with large scale deep re- inforcement learning
Christopher Berner et al. Dota 2 with large scale deep re- inforcement learning. Technical report, OpenAI, 2019
2019
-
[12]
Grandmaster level in StarCraft II using multi-agent reinforcement learning.Nature, 575(7782):350–354, 2019
Oriol Vinyals et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning.Nature, 575(7782):350–354, 2019
2019
-
[13]
MineDojo: Building open-ended embod- ied agents with internet-scale knowledge
Linxi Fan et al. MineDojo: Building open-ended embod- ied agents with internet-scale knowledge. InAdvances in NeurIPS, 2022
2022
-
[14]
No-press Diplomacy: Modeling multi-agent gameplay
Philip Paquette et al. No-press Diplomacy: Modeling multi-agent gameplay. InAdvances in NeurIPS, 32, 2019
2019
-
[15]
WebArena: A realistic web environ- ment for building autonomous agents
Shuyan Zhou et al. WebArena: A realistic web environ- ment for building autonomous agents. InProc. ICLR, 2024
2024
-
[16]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environ- ments
Tianbao Xie et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environ- ments. InAdvances in NeurIPS, 2024
2024
-
[17]
GAMA-Bench: Evaluating LLMs’ gaming ability in multi-agent environments
Jen-tse Huang et al. GAMA-Bench: Evaluating LLMs’ gaming ability in multi-agent environments. InProc. ICLR, 2025
2025
-
[18]
Xu et al
Frank F. Xu et al. TheAgentCompany: Benchmarking LLM agents on consequential real-world tasks. InAd- vances in NeurIPS, 2025
2025
-
[19]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao et al. ReAct: Synergizing reasoning and acting in language models. InProc. ICLR, 2023
2023
-
[20]
V oyager: An open-ended embod- ied agent with large language models
Guanzhi Wang et al. V oyager: An open-ended embod- ied agent with large language models. InAdvances in NeurIPS, 2023
2023
-
[21]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong et al. MetaGPT: Meta programming for a multi-agent collaborative framework. InProc. ICLR, 2024
2024
-
[22]
CoLLAB: Coordinating collabo- rative LLM-based agents for mathematical reasoning
Shanshan Gong et al. CoLLAB: Coordinating collabo- rative LLM-based agents for mathematical reasoning. InAdvances in NeurIPS, 2025
2025
-
[23]
EmbodiedBench: Comprehensive bench- marking multi-modal large language models for embod- ied decision making
Rui Yang et al. EmbodiedBench: Comprehensive bench- marking multi-modal large language models for embod- ied decision making. InProc. ICML, 2025
2025
-
[24]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn et al. Reflexion: Language agents with verbal reinforcement learning. InAdvances in NeurIPS, 2023
2023
-
[25]
lost in the middle
Aman Madaan et al. Self-Refine: Iterative refinement with self-feedback. InAdvances in NeurIPS, 2023. Technical Appendix A Interactive Environment Comparison Table 6 provides a structured comparison of representative interactive decision-making environments across ten criteria relevant to complex strategy research. CivRealm is the only environment satisfy...
2023
-
[26]
Diplomatic Events -- check first: wars declared, treaties, alliances. 0.5. Threat Analysis -- lost city = CRITICAL; distinguish combat vs. non-combat units before raising military alert
-
[27]
Root Cause -- tax rate, resource allocation, unit utilization
-
[28]
URGENT RETRY: <Goal>
Production & Garrison Verification -- compare city status to goals. Goal status: Completed / In Progress / Failed / Failed (Timeout). Failed goal MUST trigger “URGENT RETRY: <Goal>” in corrective_actions. Output JSON: {thoughts: {summary, corrective_actions}, goal_evaluations: {...}} J.8 Game Analyst (Post-Game Forensic Analyst) Invoked once at game end. ...
-
[29]
Garrison & Defense: coverage, Wall-Unit synergy, redundant units
-
[30]
Production: mix (Settler/Military/Infrastructure), analysis
-
[31]
Worker Tile Improvement: road network, irrigation timing, idle workers
-
[32]
Tax Rate: Luxury timing (wasted under Despotism), disorder response
-
[33]
Technology Path: full chronological sequence, gov-prerequisite trace
-
[34]
Government Transition: Despotism penalty quantification, transition pace
-
[35]
Zero-Growth Economy
Over-Militarization vs. Zero-Growth Economy
-
[36]
Recommendations must form a coherent Rapid Development Pipeline: City founding -> precise defense (Walls + military unit) -> core infrastructure
Expansion Stagnation: pace, city spacing, missed safe-land settlement. Recommendations must form a coherent Rapid Development Pipeline: City founding -> precise defense (Walls + military unit) -> core infrastructure. Output JSON: GameAnalysisResponse {final_state, success,root_causes, recommendations, ...}
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.