Progressive Pixel-Neighborhood Deformable Cross-Attention for Multispectral Object Detection
Pith reviewed 2026-06-26 01:20 UTC · model grok-4.3
The pith
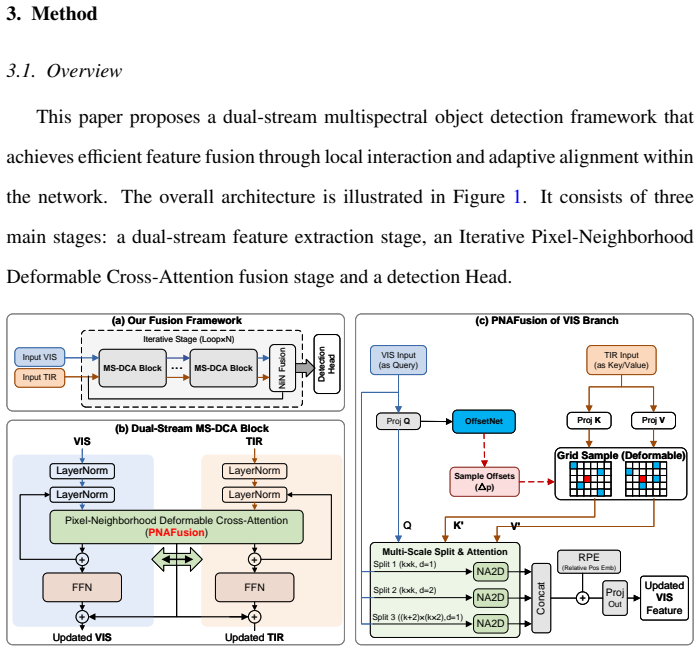
PNAFusion aligns visible and thermal features by restricting cross-attention to pixel neighborhoods and learning deformable offsets to handle local misalignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PNAFusion integrates local spatial priors through a Pixel-Neighborhood Cross-Attention module that avoids global matching and an Adaptive Deformable Alignment module that predicts pixel-wise offsets, then combines them in an iterative feedback loop that progressively improves cross-modal feature alignment for multispectral detection.
What carries the argument
Progressive Pixel-Neighborhood Deformable Cross-Attention (PNAFusion), which concentrates interaction inside local neighborhoods and uses learned offsets to model non-linear correspondences.
Load-bearing premise
Misalignment between visible and thermal images stays weak and local while semantic correspondences follow non-linear spatial mappings that fixed receptive fields cannot capture.
What would settle it
Global cross-attention or fixed-receptive-field fusion reaching equal or higher mAP on FLIR, M3FD and DroneVehicle without the reported memory or FLOP savings.
Figures


read the original abstract
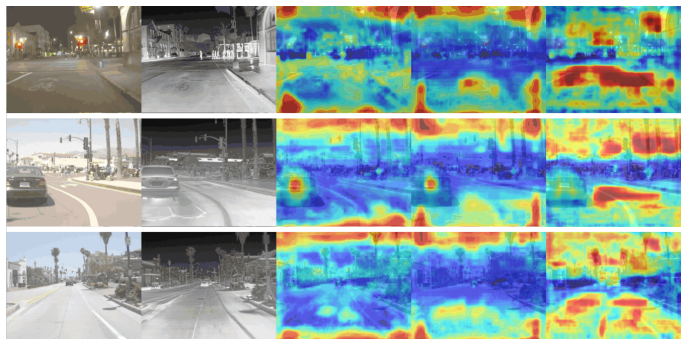
Effective cross-modal feature alignment and interaction are central challenges in multispectral object detection. Although global cross-attention provides strong long-range modeling ability, its quadratic complexity with respect to feature size limits deployment on resource-constrained platforms. We therefore propose Progressive Pixel-Neighborhood Deformable Cross-Attention for multispectral feature fusion, termed PNAFusion. The proposed framework is motivated by two observations: weak misalignment between visible and thermal images is usually concentrated around local neighborhoods, and semantic correspondence across modalities often follows non-linear spatial mappings that fixed receptive fields cannot model well. To address these issues, PNAFusion incorporates local spatial priors into its architectural design to concentrate feature interaction and alignment on the most relevant neighborhoods. Specifically, a Pixel-Neighborhood Cross-Attention (PNCA) module is introduced to avoid redundant global feature matching and suppress background noise. Meanwhile, an Adaptive Deformable Alignment (ADA) module captures non-linear spatial correspondences through learned pixel-wise offsets. These components are further integrated through an iterative feedback mechanism to progressively refine cross-modal feature alignment. Experiments on FLIR, M3FD, and DroneVehicle show that PNAFusion achieves 84.2, 90.5, and 85.5 mAP@0.5, respectively, under the YOLOv5 detector, and further reaches 86.8 mAP@0.5 on FLIR and 90.8 mAP@0.5 on M3FD when transferred to Co-DETR. Efficiency analysis indicates that PNAFusion reduces allocated GPU memory by 33.0\% compared with ICAFusion and reduces theoretical FLOPs from 194.8 G to 156.4 G, although the deformable sampling and iterative refinement introduce additional latency. Our code will be available at https://github.com/DanielQiuTian/PNAFusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PNAFusion, a multispectral feature fusion framework for object detection that uses a Pixel-Neighborhood Cross-Attention (PNCA) module to restrict interactions to local neighborhoods and an Adaptive Deformable Alignment (ADA) module to learn pixel-wise offsets for non-linear correspondences, combined via iterative refinement. Motivated by observations on local misalignment and fixed receptive fields, it reports mAP@0.5 scores of 84.2/90.5/85.5 on FLIR/M3FD/DroneVehicle with YOLOv5 and 86.8/90.8 on FLIR/M3FD with Co-DETR, plus 33% lower GPU memory and reduced FLOPs (194.8 G to 156.4 G) versus ICAFusion, with code to be released.
Significance. If the reported gains hold after proper controls, the work would offer a practical efficiency improvement for cross-modal detection on edge platforms by replacing global attention with neighborhood-focused deformable mechanisms. The explicit commitment to releasing code is a positive factor for reproducibility.
major comments (2)
- [Experiments / abstract] The experimental results (abstract and §4) report concrete mAP, memory, and FLOP numbers but contain no ablation studies isolating PNCA, ADA, or the iterative feedback mechanism, nor any details on training protocols, baseline implementations, or statistical significance. This leaves open whether the gains (e.g., 84.2 mAP on FLIR) derive from the proposed modules or from unstated factors.
- [Introduction / §3] The motivation in the introduction and method sections asserts that misalignment is 'usually concentrated around local neighborhoods' and that correspondences are non-linear, yet no quantitative analysis or visualization of misalignment statistics on the three datasets is provided to support these claims as load-bearing for the architecture choices.
minor comments (2)
- [§3.2] Notation for the iterative refinement loop and offset prediction in ADA is introduced without an accompanying equation or pseudocode block, making the progressive update rule difficult to follow precisely.
- [Efficiency analysis] The efficiency comparison table should include latency measurements alongside the reported FLOPs and memory, given the note that deformable sampling adds latency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and commit to revisions that strengthen the experimental validation and motivation sections.
read point-by-point responses
-
Referee: [Experiments / abstract] The experimental results (abstract and §4) report concrete mAP, memory, and FLOP numbers but contain no ablation studies isolating PNCA, ADA, or the iterative feedback mechanism, nor any details on training protocols, baseline implementations, or statistical significance. This leaves open whether the gains (e.g., 84.2 mAP on FLIR) derive from the proposed modules or from unstated factors.
Authors: We agree that the current version lacks explicit ablation studies isolating the individual contributions of PNCA, ADA, and the iterative refinement, as well as fuller details on training protocols, baseline re-implementations, and statistical significance. In the revised manuscript we will add these ablation experiments, expand the experimental protocol section, and report mean and standard deviation over multiple runs to demonstrate that the reported gains are attributable to the proposed modules. revision: yes
-
Referee: [Introduction / §3] The motivation in the introduction and method sections asserts that misalignment is 'usually concentrated around local neighborhoods' and that correspondences are non-linear, yet no quantitative analysis or visualization of misalignment statistics on the three datasets is provided to support these claims as load-bearing for the architecture choices.
Authors: The design choices rest on empirical observations of local misalignment and non-linear correspondences. To make the motivation more rigorous and directly address the referee's concern, we will include quantitative misalignment statistics and supporting visualizations computed on the FLIR, M3FD, and DroneVehicle datasets in the revised introduction and method sections. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical architecture proposal for multispectral detection. It states two observations about misalignment and non-linear correspondences, then describes PNCA, ADA, and iterative refinement modules to address them. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. Performance numbers (mAP, memory, FLOPs) are reported from experiments on standard datasets rather than being forced by construction from inputs. The central claim does not reduce to self-definition or renaming; it remains a standard engineering argument with independent experimental content.
Axiom & Free-Parameter Ledger
free parameters (2)
- neighborhood size
- iteration count
axioms (2)
- domain assumption Weak misalignment between visible and thermal images is usually concentrated around local neighborhoods
- domain assumption Semantic correspondence across modalities often follows non-linear spatial mappings that fixed receptive fields cannot model well
invented entities (2)
-
Pixel-Neighborhood Cross-Attention (PNCA) module
no independent evidence
-
Adaptive Deformable Alignment (ADA) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Infrared and visible image fusion methods and applica- tions: A survey.Inf
Ma, J.; Ma, Y .; Li, C. Infrared and visible image fusion methods and applica- tions: A survey.Inf. Fusion2019,45, 153–178
-
[2]
Infrared and visible image fusion technology and application: A review.Sensors2023,23, 599
Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and visible image fusion technology and application: A review.Sensors2023,23, 599
-
[3]
Combining UA V-based plant height from crop surface models, 34 visible, and near infrared vegetation indices for biomass monitoring in barley
Bendig, J.; Yu, K.; Aasen, H.; Bolten, A.; Bennertz, S.; Broscheit, J.; Gnyp, M.L.; Bareth, G. Combining UA V-based plant height from crop surface models, 34 visible, and near infrared vegetation indices for biomass monitoring in barley. Int. J. Appl. Earth Obs. Geoinf.2015,39, 79–87
2015
-
[4]
Deep residual learning for image recogni- tion
He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recogni- tion. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: New York, NY , USA, 2016; pp. 770–778
2016
-
[5]
CFT: Cross-modality fusion transformer for multispectral object detection.IEEE Trans
Qing, L.; Xu, L.; Guan, J.; Khan, M.G. CFT: Cross-modality fusion transformer for multispectral object detection.IEEE Trans. Multimed.2022,25, 4112–4124
2022
-
[6]
Spectral- Former: Rethinking hyperspectral image classification with transformers.IEEE Trans
Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. Spectral- Former: Rethinking hyperspectral image classification with transformers.IEEE Trans. Geosci. Remote Sens.2022,60, 1–15
2022
-
[7]
ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection.Pattern Recognit.2024,145, 109913
Shen, J.; Chen, Y .; Liu, Y .; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection.Pattern Recognit.2024,145, 109913
2024
-
[8]
Background-aware cross- attention multiscale fusion for multispectral object detection.Remote Sens
Guo, R.; Guo, X.; Sun, X.; Zhou, P.; Sun, B.; Su, S. Background-aware cross- attention multiscale fusion for multispectral object detection.Remote Sens. 2024,16, 4034
2024
-
[9]
Faster R-CNN: Towards real-time ob- ject detection with region proposal networks.IEEE Trans
Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time ob- ject detection with region proposal networks.IEEE Trans. Pattern Anal. Mach. Intell.2017,39, 1137–1149
2017
-
[10]
YOLOv4: Optimal speed and accuracy of object detection.arXiv2020, arXiv:2004.10934
Bochkovskiy, A.; Wang, C.-Y .; Liao, H.-Y .M. YOLOv4: Optimal speed and accuracy of object detection.arXiv2020, arXiv:2004.10934
Pith/arXiv arXiv 2004
-
[11]
Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y .; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications.arXiv2022, arXiv:2209.02976. 35
-
[12]
YOLOv10: Real-Time End-to-End Object Detection.arXiv2024, arXiv:2405.14458
Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection.arXiv2024, arXiv:2405.14458
-
[13]
Guided attentive feature fusion for multispectral pedestrian detection
Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision; 2021; pp. 72–80
2021
-
[14]
Illumination-aware multimodal hierarchical fusion network for RGB-infrared object detection.IEEE Trans
Lu, T.; Lu, J.; Fu, W.; Xi, Y . Illumination-aware multimodal hierarchical fusion network for RGB-infrared object detection.IEEE Trans. Geosci. Remote Sens. 2025,63, 1–14
2025
-
[15]
Zuo, X.; Qu, C.; Zhan, H.; Shen, J.; Yang, W. SFFR: Spatial-Frequency Feature Reconstruction for Multispectral Aerial Object Detection.arXiv2025, arXiv:2511.06298
-
[16]
Shen, J.; Zhan, H.; Dong, S.; Zuo, X.; Yang, W.; Ling, H. Multispectral State- Space Feature Fusion: Bridging Shared and Cross-Parametric Interactions for Object Detection.arXiv2025, arXiv:2507.14643
-
[17]
An im- age is worth 16×16 words: Transformers for image recognition at scale
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Un- terthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An im- age is worth 16×16 words: Transformers for image recognition at scale. In Pro- ceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021
2021
-
[18]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021
2021
-
[19]
Swin trans- former: Hierarchical vision transformer using shifted windows
Liu, Z.; Lin, Y .; Cao, Y .; Hu, H.; Wei, Y .; Zhang, Z.; Lin, S.; Guo, B. Swin trans- former: Hierarchical vision transformer using shifted windows. In Proceedings 36 of the IEEE/CVF International Conference on Computer Vision (ICCV), Mon- treal, BC, Canada, 10–17 October 2021
2021
-
[20]
Neighborhood attention trans- former
Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood attention trans- former. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: New York, NY , USA, 2023; pp. 6185–6194
2023
-
[21]
Deformable DETR: Deformable transformers for end-to-end object detection.arXiv2020, arXiv:2010.04159
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection.arXiv2020, arXiv:2010.04159
Pith/arXiv arXiv 2010
-
[22]
Learning temporal distribution and spatial correlation toward universal moving object segmentation.IEEE Trans
Dong, G.; Zhao, C.; Pan, X.; Basu, A. Learning temporal distribution and spatial correlation toward universal moving object segmentation.IEEE Trans. Image Process.2024,33, 2447–2461
2024
-
[23]
Multimodal object detection by channel switching and spatial attention
Cao, Y .; Bin, J.; Hamari, J.; Blasch, E.; Liu, Z. Multimodal object detection by channel switching and spatial attention. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition; IEEE: New York, NY , USA, 2023; pp. 403–411
2023
-
[24]
Multidimensional fusion network for multispectral object detection.IEEE Trans
Yang, F.; Liang, B.; Li, W.; Zhang, J. Multidimensional fusion network for multispectral object detection.IEEE Trans. Circuits Syst. Video Technol.2024, 35, 547–560
2024
-
[25]
Rethinking self- attention for multispectral object detection.IEEE Trans
Hu, S.; Bonardi, F.; Bouchafa, S.; Prendinger, H.; Sidibé, D. Rethinking self- attention for multispectral object detection.IEEE Trans. Intell. Transp. Syst. 2024,25, 16300–16311
2024
-
[26]
Gm-detr: Generalized muiltispectral detection transformer with efficient fusion encoder for visible- infrared detection
Xiao, Y .; Meng, F.; Wu, Q.; Xu, L.; He, M.; Li, H. Gm-detr: Generalized muiltispectral detection transformer with efficient fusion encoder for visible- infrared detection. InProceedings of the IEEE/CVF Conference on Computer 37 Vision and Pattern Recognition; IEEE: New York, NY , USA, 2024; pp. 5541– 5549
2024
-
[27]
Fusion- Mamba for cross-modality object detection.IEEE Trans
Dong, W.; Zhu, H.; Lin, S.; Luo, X.; Shen, Y .; Guo, G.; Zhang, B. Fusion- Mamba for cross-modality object detection.IEEE Trans. Multimed.2025, 27, 7392–7406
2025
-
[28]
TFDet: Target-aware fusion for RGB-T pedestrian detection.IEEE Trans
Zhang, X.; Zhang, X.; Wang, J.; Ying, J.; Sheng, Z.; Yu, H.; Li, C.; Shen, H.L. TFDet: Target-aware fusion for RGB-T pedestrian detection.IEEE Trans. Neural Netw. Learn. Syst.2024,36, 13276–13290
2024
-
[29]
DAMSDet: Dynamic adaptive multispectral detection transformer with competitive query selection and adap- tive feature fusion
Guo, J.; Gao, C.; Liu, F.; Meng, D.; Gao, X. DAMSDet: Dynamic adaptive multispectral detection transformer with competitive query selection and adap- tive feature fusion. In Proceedings of theEuropean Conference on Computer Vision; Springer; Cham, Switzerland, 2024; pp. 464–481
2024
-
[30]
SuperFusion: A versatile image registration and fusion network with semantic awareness.IEEE/CAA J
Tang, L.; Deng, Y .; Ma, Y .; Huang, J.; Ma, J. SuperFusion: A versatile image registration and fusion network with semantic awareness.IEEE/CAA J. Autom. Sin.2022,9, 2121–2137
2022
-
[31]
Dual-dynamic cross-modal interaction network for multimodal remote sensing object detection.IEEE Trans
Bao, W.; Huang, M.; Hu, J.; Xiang, X. Dual-dynamic cross-modal interaction network for multimodal remote sensing object detection.IEEE Trans. Geosci. Remote Sens.2025,63,5401013
2025
-
[32]
CCLDet: A Cross- Modality and Cross-Domain Low-Light Detector.IEEE Trans
Shang, X.; Li, N.; Li, D.; Lv, J.; Zhao, W.; Zhang, R.; Xu, J. CCLDet: A Cross- Modality and Cross-Domain Low-Light Detector.IEEE Trans. Intell. Transp. Syst.2025,26, 3284–3294
2025
-
[33]
Zhou, M.; Li, T.; Qiao, C.; Xie, D.; Wang, G.; Ruan, N.; Mei, L.; Yang, Y . DMM: Disparity-guided Multispectral Mamba for Oriented Object Detection in Remote Sensing.arXiv2024, arXiv:2407.08132. 38
-
[34]
COMO: Cross-mamba interac- tion and offset-guided fusion for multimodal object detection.Inf
Liu, C.; Ma, X.; Yang, X.; Zhang, Y .; Dong, Y . COMO: Cross-mamba interac- tion and offset-guided fusion for multimodal object detection.Inf. Fusion2026, 125, 103414
-
[35]
Reflectance-Guided Progressive Feature Alignment Network for All-Day UA V Object Detection.IEEE Trans
Zhao, Z.; Zhang, W.; Xiao, Y .; Li, C.; Tang, J. Reflectance-Guided Progressive Feature Alignment Network for All-Day UA V Object Detection.IEEE Trans. Geosci. Remote Sens.2025,63,5404215. 39
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.