MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
Pith reviewed 2026-06-25 19:32 UTC · model grok-4.3
The pith
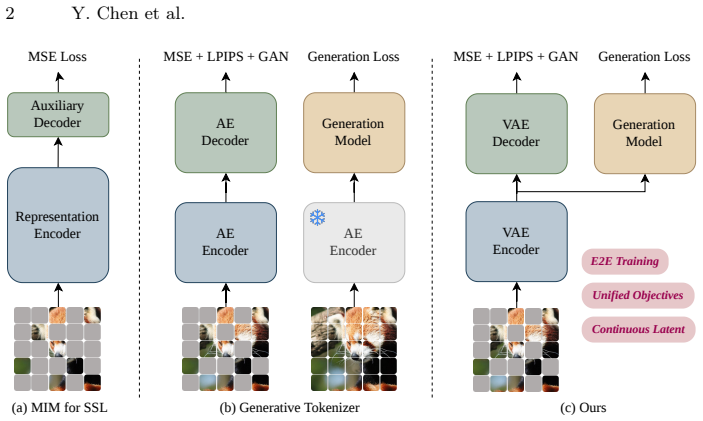
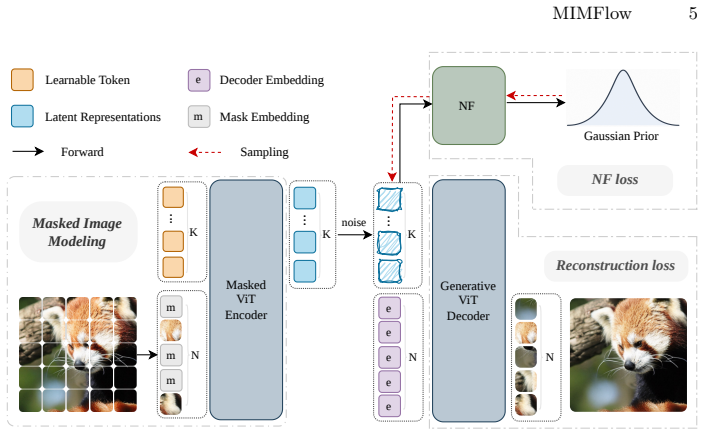
MIMFlow uses a VAE encoder on masked images to let normalizing flows model only a low-frequency semantic manifold while a decoder handles details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By employing a VAE encoder to infer semantic latent from masked images, MIMFlow achieves a principled decoupling of the generative task: the Normalizing Flow focuses on modeling a simplified, low-frequency semantic manifold, while a specialized decoder handles high-frequency synthesis.
What carries the argument
VAE encoder on masked images that infers semantic latent for the normalizing flow, enabling decoupling of low-frequency manifold modeling from high-frequency pixel synthesis.
Load-bearing premise
A VAE encoder applied to masked images will extract a semantic latent low-frequency and simplified enough that the normalizing flow can model it without wasting capacity.
What would settle it
Training a standard normalizing flow directly on latents extracted from unmasked images and obtaining equal or better FID scores on ImageNet 256x256 would show the masking step adds no benefit to the claimed decoupling.
Figures

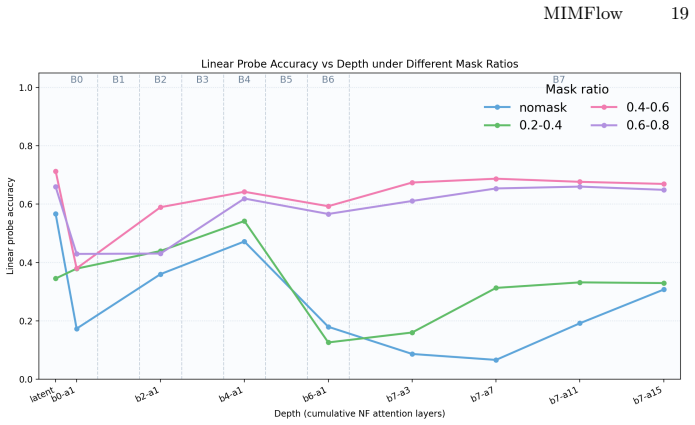
read the original abstract
Normalizing Flows (NFs) are powerful generative models capable of exact density estimation and sampling. However, their strict invertibility often forces the model to exhaust its capacity on low-level pixel details, hindering the capture of high-level semantic structures. While Masked Image Modeling (MIM) has excelled in representation learning, its integration into generative pipelines has remained largely modular and disjointed. In this paper, we propose MIMFlow, a unified end-to-end framework that jointly optimizes latent semantics, pixel reconstruction, and generative flow. By employing a VAE encoder to infer semantic latent from masked images, MIMFlow achieves a principled decoupling of the generative task: the Normalizing Flow focuses on modeling a simplified, low-frequency semantic manifold, while a specialized decoder handles high-frequency synthesis. This design effectively resolves the inherent capacity bottleneck of NFs, allowing the model to prioritize global structural coherence over redundant noise. Empirical results on ImageNet 256$\times$256 show that MIMFlow-L reaches 71.3\% linear probing accuracy and an FID of 2.50. Despite using only 128 tokens (50\% fewer than standard models), it yields a 32.8\% performance gain over similar-scale NF baselines. Our code is available at https://github.com/MCG-NJU/MIMFlow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MIMFlow, a unified end-to-end framework integrating Masked Image Modeling with Normalizing Flows. A VAE encoder infers semantic latents from masked images, allowing the NF to model a simplified low-frequency semantic manifold while a specialized decoder handles high-frequency synthesis. This is claimed to resolve NF capacity bottlenecks on pixel details. On ImageNet 256×256, MIMFlow-L reports FID 2.50 and 71.3% linear probing accuracy using 128 tokens (50% fewer than standard models), with a 32.8% gain over similar-scale NF baselines. Code is released.
Significance. If the decoupling mechanism is substantiated, the approach could meaningfully improve the applicability of exact-likelihood NF models to high-resolution image synthesis by freeing capacity for semantic structure. Releasing code supports reproducibility and follow-up work.
major comments (2)
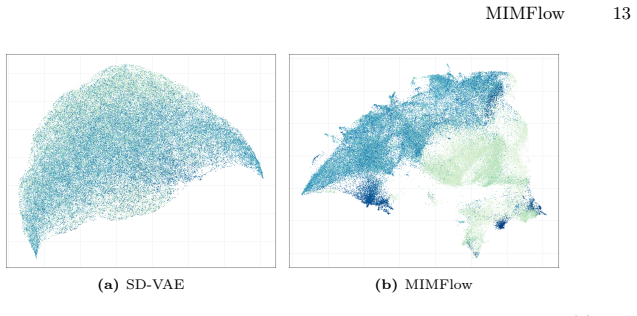
- [Abstract] Abstract: The central claim that the VAE encoder on masked images produces a 'simplified, low-frequency semantic manifold' (allowing the NF to avoid high-frequency modeling) is load-bearing for attributing the FID and accuracy gains to the proposed decoupling, yet the manuscript provides no frequency-spectrum analysis, power-spectrum comparisons, or latent visualizations confirming reduced high-frequency energy in the inferred latent relative to pixels or unmasked inputs.
- [Abstract] Abstract: The reported metrics (FID 2.50, 71.3% probing accuracy, 32.8% gain) and the claim of principled decoupling are presented without ablations, baseline details, or controls that isolate the contribution of the MIM-VAE-NF integration versus other design choices (e.g., decoder architecture or token count), leaving the mechanism unverified.
minor comments (1)
- [Abstract] The abstract refers to 'MIMFlow-L' without defining the variant (model scale, depth, or other hyperparameters).
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger empirical support of the decoupling claim. We address each point below and will revise the manuscript to incorporate the requested analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the VAE encoder on masked images produces a 'simplified, low-frequency semantic manifold' (allowing the NF to avoid high-frequency modeling) is load-bearing for attributing the FID and accuracy gains to the proposed decoupling, yet the manuscript provides no frequency-spectrum analysis, power-spectrum comparisons, or latent visualizations confirming reduced high-frequency energy in the inferred latent relative to pixels or unmasked inputs.
Authors: We agree that the manuscript does not currently contain frequency-spectrum analysis, power-spectrum comparisons, or supporting latent visualizations. In the revision we will add these elements, including power-spectrum plots of the inferred latents versus raw pixels and unmasked inputs, together with qualitative latent visualizations, to directly substantiate the reduced high-frequency content. revision: yes
-
Referee: [Abstract] Abstract: The reported metrics (FID 2.50, 71.3% probing accuracy, 32.8% gain) and the claim of principled decoupling are presented without ablations, baseline details, or controls that isolate the contribution of the MIM-VAE-NF integration versus other design choices (e.g., decoder architecture or token count), leaving the mechanism unverified.
Authors: We concur that additional controls are required to isolate the contribution of the MIM-VAE-NF integration. The revised manuscript will include ablations that disable the masked VAE encoder, vary token count while holding other components fixed, and compare against decoder-only variants, thereby clarifying the source of the reported gains. revision: yes
Circularity Check
No circularity: decoupling presented as architectural design, not reduced by construction
full rationale
The abstract asserts that applying a VAE encoder to masked images produces a low-frequency semantic latent allowing NF to model only that manifold, but supplies no equations, fitted parameters, or self-citations that make this decoupling equivalent to its inputs by definition. The performance numbers (FID 2.50, 71.3% probing) are reported as empirical outcomes rather than predictions forced by the modeling choice itself. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the provided text; the central mechanism is a stated design assumption whose validity is left to external verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, H., Han, Y., Chen, F., Li, X., Wang, Y., Wang, J., Wang, Z., Liu, Z., Zou, D., Raj, B.: Masked autoencoders are effective tokenizers for diffusion models (2025), https://arxiv.org/abs/2502.03444
arXiv 2025
-
[2]
Chen, R.T.Q., Rubanova, Y., Bettencourt, J., Duvenaud, D.: Neural ordinary dif- ferential equations (2019),https://arxiv.org/abs/1806.07366
Pith/arXiv arXiv 2019
-
[3]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
arXiv 2025
-
[4]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Y., Xu, X., Wang, S., Zhu, C., Wen, R., Li, X., Ge, T., Wang, L.: Flowing backwards: Improving normalizing flows via reverse representation alignment. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 3074– 3082 (2026)
2026
-
[5]
IEEE Conference on Computer Vision and Pattern Recognition pp
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.:ImageNet:ALarge-scale Hierarchical Image Database. IEEE Conference on Computer Vision and Pattern Recognition pp. 248–255 (2009)
2009
-
[6]
Advances in Neural Information Processing Systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems34, 8780–8794 (2021)
2021
-
[7]
arXiv preprint arXiv:1410.8516 (2014)
Dinh, L., Krueger, D., Bengio, Y.: Nice: Non-linear independent components esti- mation. arXiv preprint arXiv:1410.8516 (2014)
Pith/arXiv arXiv 2014
-
[8]
arXiv preprint arXiv:1605.08803 (2016)
Dinh, L., Sohl-Dickstein, J., Bengio, S.: Density estimation using real nvp. arXiv preprint arXiv:1605.08803 (2016)
Pith/arXiv arXiv 2016
-
[9]
In: International Conference on Artificial Intelligence and Statistics
Draxler, F., Sorrenson, P., Zimmermann, L., Rousselot, A., Köthe, U.: Free-form flows: Make any architecture a normalizing flow. In: International Conference on Artificial Intelligence and Statistics. pp. 2197–2205. PMLR (2024)
2024
-
[10]
arXiv preprint arXiv:2402.06578 (2024)
Draxler, F., Wahl, S., Schnörr, C., Köthe, U.: On the universality of volume- preserving and coupling-based normalizing flows. arXiv preprint arXiv:2402.06578 (2024)
arXiv 2024
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, S., Zhou, P., Cheng, M.M., Yan, S.: Masked diffusion transformer is a strong image synthesizer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23164–23173 (2023)
2023
-
[12]
Gao, Y., Chen, C., Chen, T., Gu, J.: One layer is enough: Adapting pretrained visual encoders for image generation (2025),https://arxiv.org/abs/2512.07829
arXiv 2025
-
[13]
Advances in Neu- ral Information Processing Systems33, 22104–22117 (2020) MIMFlow 21
Giaquinto, R., Banerjee, A.: Gradient boosted normalizing flows. Advances in Neu- ral Information Processing Systems33, 22104–22117 (2020) MIMFlow 21
2020
-
[14]
arXiv preprint arXiv:2506.06276 (2025)
Gu,J.,Chen,T.,Berthelot,D.,Zheng,H.,Wang,Y.,Zhang,R.,Dinh,L.,Bautista, M.A., Susskind, J., Zhai, S.: Starflow: Scaling latent normalizing flows for high- resolution image synthesis. arXiv preprint arXiv:2506.06276 (2025)
arXiv 2025
-
[15]
Gu, J., Chen, T., Shen, Y., Berthelot, D., Zhai, S., Susskind, J.: Normalizing trajectory models (2026),https://arxiv.org/abs/2605.08078
Pith/arXiv arXiv 2026
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, J., Shen, Y., Chen, T., Dinh, L., Wang, Y., Bautista, M.A., Berthelot, D., Susskind, J., Zhai, S.: Starflow-v: End-to-end video generative modeling with au- toregressive normalizing flows. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9084–9094 (2026)
2026
-
[17]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners (2021),https://arxiv.org/abs/2111.06377
Pith/arXiv arXiv 2021
-
[18]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[19]
arXiv preprint arXiv:2410.19324 (2024)
Hoogeboom, E., Mensink, T., Heek, J., Lamerigts, K., Gao, R., Salimans, T.: Simpler diffusion (sid2): 1.5 fid on imagenet512 with pixel-space diffusion. arXiv preprint arXiv:2410.19324 (2024)
arXiv 2024
-
[20]
arXiv preprint arXiv:2212.11972 (2022)
Jabri, A., Fleet, D., Chen, T.: Scalable adaptive computation for iterative genera- tion. arXiv preprint arXiv:2212.11972 (2022)
arXiv 2022
-
[21]
Kingma, D.P., Dhariwal, P.: Glow: Generative flow with invertible 1x1 convolutions (2018),https://arxiv.org/abs/1807.03039
Pith/arXiv arXiv 2018
-
[22]
IEEE transactions on pattern analysis and machine intelligence43(11), 3964–3979 (2020)
Kobyzev, I., Prince, S.J., Brubaker, M.A.: Normalizing flows: An introduction and review of current methods. IEEE transactions on pattern analysis and machine intelligence43(11), 3964–3979 (2020)
2020
-
[23]
Advances in Neural Information Processing Systems32(2019)
Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., Aila, T.: Improved precision and recall metric for assessing generative models. Advances in Neural Information Processing Systems32(2019)
2019
-
[24]
In: arXiv preprint arXiv:2405.18373 (2024)
Lee, S.H., Park, S., Kim, G.M.: REPA-E: End-to-end training of latent-diffusion models via representation alignment. In: arXiv preprint arXiv:2405.18373 (2024)
arXiv 2024
-
[25]
Advances in Neural Information Processing Systems37, 56424–56445 (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation with- out vector quantization. Advances in Neural Information Processing Systems37, 56424–56445 (2024)
2024
-
[26]
arXiv preprint arXiv:2401.08740 (2024)
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. arXiv preprint arXiv:2401.08740 (2024)
arXiv 2024
-
[27]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[28]
Journal of Machine Learning Research22(57), 1–64 (2021)
Papamakarios, G., Nalisnick, E., Rezende, D.J., Mohamed, S., Lakshminarayanan, B.: Normalizing flows for probabilistic modeling and inference. Journal of Machine Learning Research22(57), 1–64 (2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4195–4205 (2023)
2023
-
[30]
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., Liu, D., Zhou, J., Lin, J.: Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free (2025),https://arxiv. org/abs/2505.06708
Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2103.00020 (2021) 22 Y
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020 (2021) 22 Y. Chen et al
Pith/arXiv arXiv 2021
-
[32]
arXiv preprint arXiv:2502.20388 (2025)
Ren, S., Yu, Q., He, J., Shen, X., Yuille, A., Chen, L.C.: Beyond next-token: Next- x prediction for autoregressive visual generation. arXiv preprint arXiv:2502.20388 (2025)
arXiv 2025
-
[33]
In: Bach, F., Blei, D
Rezende, D., Mohamed, S.: Variational inference with normalizing flows. In: Bach, F., Blei, D. (eds.) Proceedings of the 32nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 37, pp. 1530–1538. PMLR, Lille, France (07–09 Jul 2015),https://proceedings.mlr.press/v37/ rezende15.html
2015
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[35]
Advances in neural information processing systems29(2016)
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. Advances in neural information processing systems29(2016)
2016
-
[36]
Shen, Y., Chen, T., Gao, Y., Zhang, Y., Wang, Y., Ángel Bautista, M., Zhai, S., Susskind, J.M., Gu, J.: Starflow2: Bridging language models and normalizing flows for unified multimodal generation (2026),https://arxiv.org/abs/2605.08029
Pith/arXiv arXiv 2026
-
[37]
Singh, J., Zheng, B., Wu, Z., Zhang, R., Shechtman, E., Xie, S.: Improved baselines with representation autoencoders (2026),https://arxiv.org/abs/2605.18324
Pith/arXiv arXiv 2026
-
[38]
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalableimagegenerationvianext-scaleprediction.Advancesinneuralinformation processing systems37, 84839–84865 (2024)
2024
-
[39]
arXiv preprint arXiv:2411.19722 (2024)
Tschannen, M., Pinto, A.S., Kolesnikov, A.: Jetformer: An autoregressive genera- tive model of raw images and text. arXiv preprint arXiv:2411.19722 (2024)
arXiv 2024
-
[40]
Tu, G., Fu, X., Yu, S., Tang, Y., Kang, H., Qin, L., Zhang, Y., Gu, J.: Latent reasoning with normalizing flows (2026),https://arxiv.org/abs/2606.06447
Pith/arXiv arXiv 2026
-
[41]
Wang, S., Gao, Z., Zhu, C., Huang, W., Wang, L.: Pixnerd: Pixel neural field diffusion (2025),https://arxiv.org/abs/2507.23268
arXiv 2025
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, S., Tian, Z., Huang, W., Wang, L.: Ddt: Decoupled diffusion transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 40633–40642 (June 2026)
2026
-
[43]
Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., Hu, H.: Simmim: A simple framework for masked image modeling (2022),https://arxiv.org/abs/ 2111.09886
arXiv 2022
-
[44]
Yang, J., Li, T., Fan, L., Tian, Y., Wang, Y.: Latent denoising makes good tok- enizers (2026),https://arxiv.org/abs/2507.15856
arXiv 2026
-
[45]
Yao, J., Song, Y., Zhou, Y., Wang, X.: Towards scalable pre-training of visual tokenizers for generation (2025),https://arxiv.org/abs/2512.13687
arXiv 2025
-
[46]
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models (2025),https://arxiv.org/abs/2501.01423
arXiv 2025
-
[47]
arXiv preprint arXiv:2410.06940 (2024)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024)
Pith/arXiv arXiv 2024
-
[48]
arXiv preprint arXiv:2412.06329 (2024)
Zhai, S., Zhang, R., Nakkiran, P., Berthelot, D., Gu, J., Zheng, H., Chen, T., Bautista, M.A., Jaitly, N., Susskind, J.: Normalizing flows are capable generative models. arXiv preprint arXiv:2412.06329 (2024)
arXiv 2024
-
[49]
Zhao, Q., Zheng, G., Yang, T., Zhu, R., Leng, X., Gould, S., Zheng, L.: Simflow: Simplified and end-to-end training of latent normalizing flows (2025),https:// arxiv.org/abs/2512.04084
arXiv 2025
-
[50]
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders (2025),https://arxiv.org/abs/2510.11690 MIMFlow 23
Pith/arXiv arXiv 2025
-
[51]
Zheng, G., Zhao, Q., Yang, T., Xiao, F., Lin, Z., Wu, J., Deng, J., Zhang, Y., Zhu, R.: Farmer: Flow autoregressive transformer over pixels (2025),https://arxiv. org/abs/2510.23588
arXiv 2025
-
[52]
In: Transactions on Machine Learning Research (TMLR) (2024)
Zheng, H., Nie, W., Vahdat, A., Anandkumar, A.: Fast training of diffusion mod- els with masked transformers. In: Transactions on Machine Learning Research (TMLR) (2024)
2024
-
[53]
In: arXiv preprint arXiv:2405.15438 (2024)
Zheng, Y., Tian, Y., Li, S., Wu, Z., Liu, B., Li, J., Ye, B., Zhou, J.R.: LightningDiT: A vision-foundation-model-aligned VAE for fast and high-quality generation. In: arXiv preprint arXiv:2405.15438 (2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.