Shape Your Body: Value Gradients for Multi-Embodiment Robot Design
Pith reviewed 2026-06-28 18:39 UTC · model grok-4.3
The pith
A value function trained across many robot designs can optimize the body of a new robot using its gradients alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
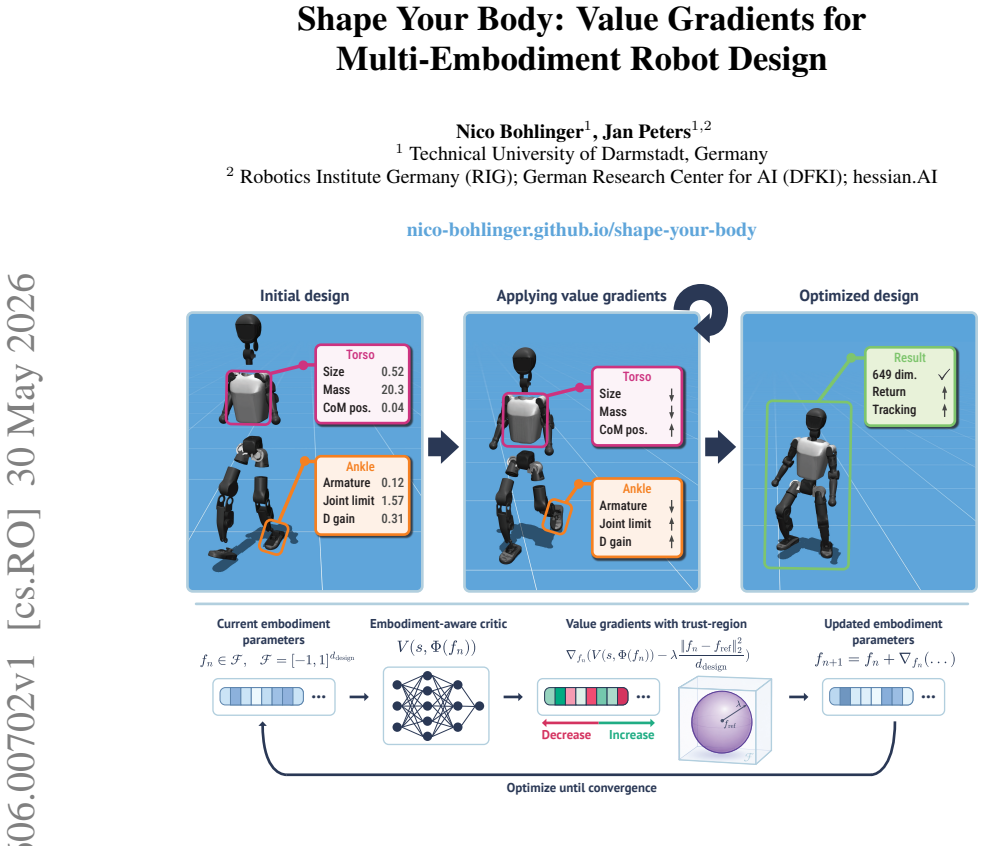
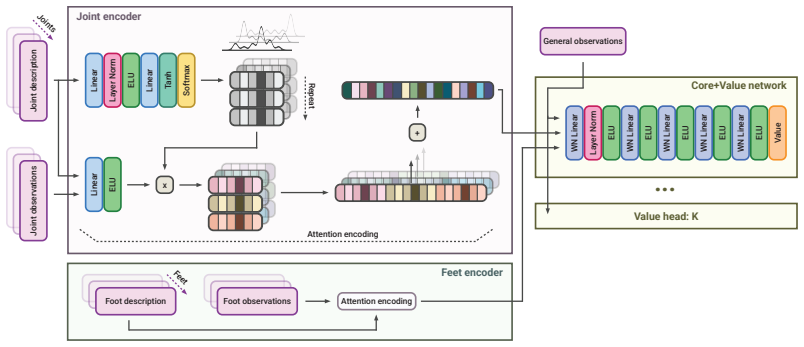
Instead of co-designing policy and embodiment from scratch for each robot, a single embodiment-aware value function trained on many designs serves as a reusable, differentiable model that directly supplies gradients for improving new robot bodies.
What carries the argument
The frozen value function acting as a differentiable surrogate for embodiment optimization.
If this is right
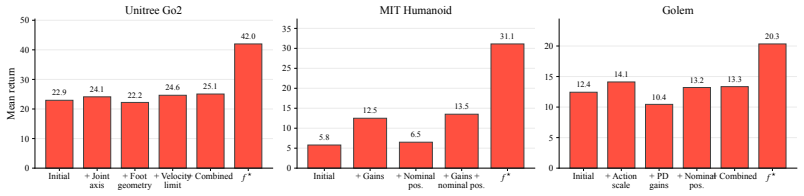
- Optimizing complete robot embodiments across held-out morphologies without retraining.
- Identifying which design and control parameters most limit performance.
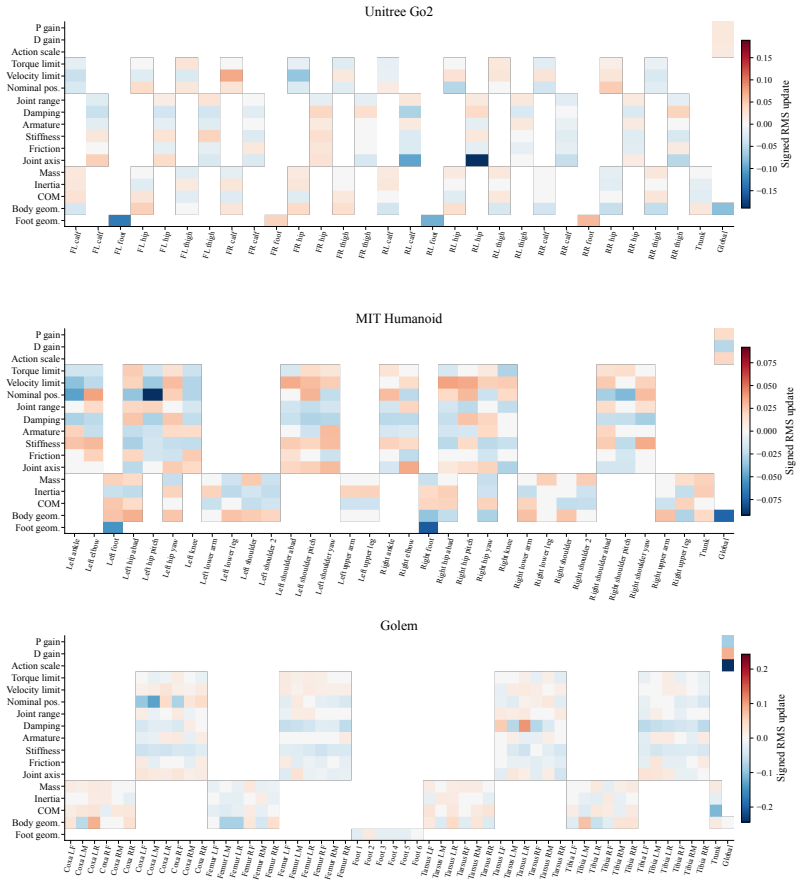
- Scaling to design spaces with over 1100 continuous parameters using one model.
- Analyzing new designs by highlighting performance bottlenecks via gradients.
Where Pith is reading between the lines
- Value gradients could extend to physical robot hardware if the value model generalizes to real-world dynamics.
- Similar surrogate approaches might apply to other co-design problems like vehicle or aircraft shaping.
- The method assumes access to a diverse training set of robots, which may limit use for entirely novel morphology classes.
Load-bearing premise
A value function trained on a set of robot embodiments will produce useful gradients for optimizing new and potentially dissimilar robot shapes.
What would settle it
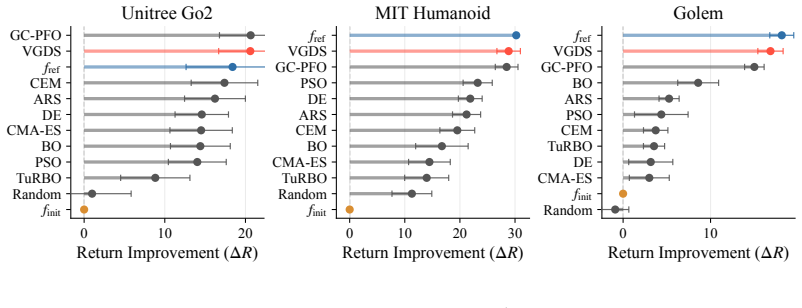
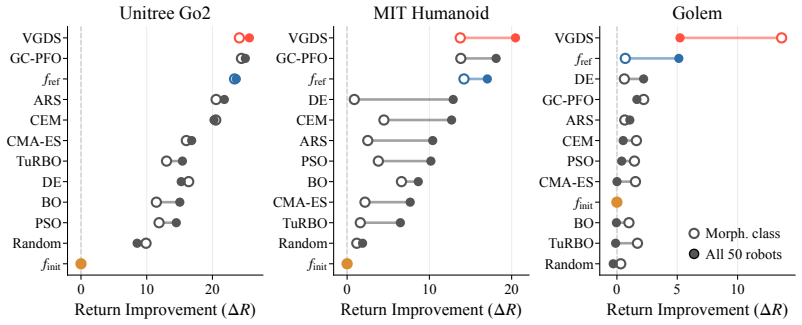
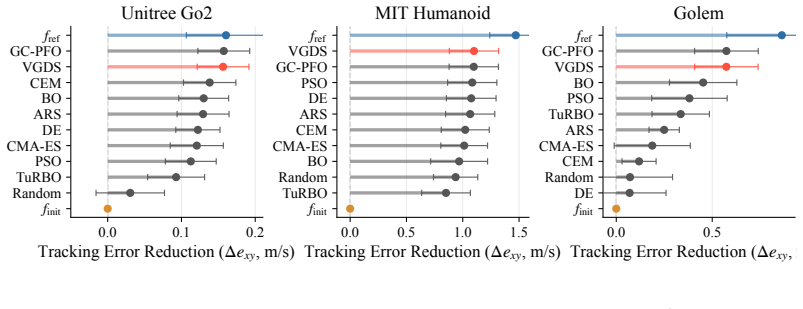
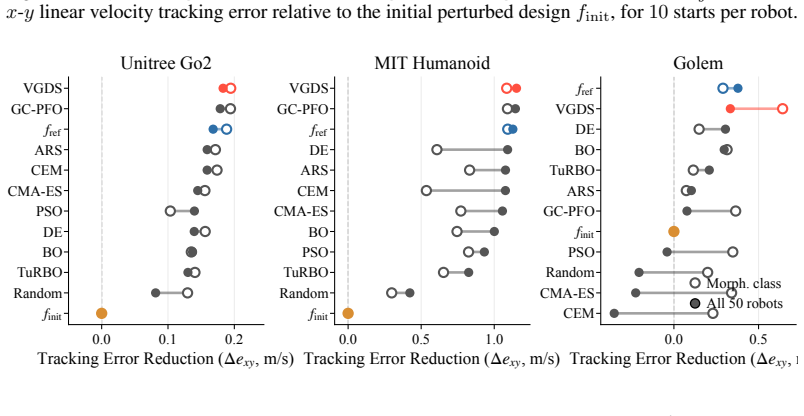
Optimize a held-out robot from a different morphology class using the gradients from a value function trained on 50 other robots and measure whether the resulting design performs better than the original.
Figures





read the original abstract
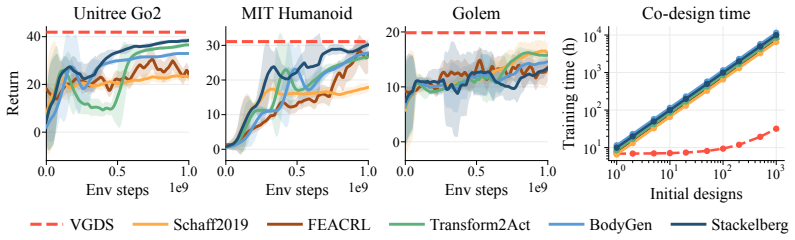
We propose to turn generalist multi-embodiment value functions into reusable models for robot design. Instead of running a new reinforcement learning co-design loop for each robot, we first train an embodiment-aware policy and value function across many robot designs. After training, the frozen value function is used as a differentiable surrogate to optimize candidate embodiments through value gradients. We evaluate our approach across different robot design settings, from perturbed single robots to held-out robots across morphology classes, with single models trained on up to 50 robots and design spaces of over 1100 continuous embodiment parameters. Beyond optimizing complete embodiments, we show that value gradients can identify performance-limiting design and control parameters, enabling both the optimization and the analysis of new robot designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a multi-embodiment value function trained across many robot designs can be frozen after training and reused as a differentiable surrogate for optimizing new robot embodiments via value gradients, avoiding per-robot RL co-design loops. It reports evaluation from perturbed single-robot cases to held-out robots across morphology classes, using models trained on up to 50 robots with design spaces exceeding 1100 continuous parameters, and demonstrates the gradients' utility for both optimization and identifying performance-limiting design/control parameters.
Significance. If the central claim holds, the work offers a practical route to amortize the cost of multi-embodiment RL across design tasks, enabling faster iteration on robot morphologies and parameter analysis without retraining. The approach of treating a frozen Q-function as a reusable design surrogate is a concrete contribution to co-design methods.
major comments (2)
- [Abstract, §4] Abstract and §4 (evaluation protocol): the claim that value gradients optimize held-out morphologies across classes rests on the assumption that the learned value surface extrapolates reliably outside the training distribution of ≤50 robots; the reported results do not indicate whether optimized trajectories were validated against ground-truth returns obtained by re-training or rolling out the embodiment-specific policy, leaving open the possibility that gradient steps exploit value-function artifacts rather than true performance gains.
- [§3.2] §3.2 (value-gradient optimization): the method treats the frozen value function as a surrogate whose gradients are used directly for embodiment-parameter descent; no analysis is provided of gradient norm stability or convexity properties when the embodiment parameters lie far from the training morphologies, which is load-bearing for the held-out-robot claim.
minor comments (2)
- Notation for embodiment parameters and state-embodiment concatenation should be introduced once with a clear table or diagram rather than inline.
- The abstract states 'over 1100 continuous embodiment parameters' but does not clarify whether this is the total dimensionality or per-robot; a sentence in §2 or §4 would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments in detail below and indicate the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (evaluation protocol): the claim that value gradients optimize held-out morphologies across classes rests on the assumption that the learned value surface extrapolates reliably outside the training distribution of ≤50 robots; the reported results do not indicate whether optimized trajectories were validated against ground-truth returns obtained by re-training or rolling out the embodiment-specific policy, leaving open the possibility that gradient steps exploit value-function artifacts rather than true performance gains.
Authors: We appreciate this observation. Our current evaluation protocol includes direct comparisons of the optimized designs against baseline methods using the multi-embodiment policy and value function, as well as some ground-truth evaluations on perturbed cases. However, we acknowledge that for the held-out optimized robots, we have not reported results from re-training embodiment-specific policies to obtain independent ground-truth returns. This is a valid concern regarding potential artifacts. In the revised version, we will include additional experiments where we re-train policies on a selection of the optimized held-out embodiments and compare the returns to validate the performance improvements. revision: yes
-
Referee: [§3.2] §3.2 (value-gradient optimization): the method treats the frozen value function as a surrogate whose gradients are used directly for embodiment-parameter descent; no analysis is provided of gradient norm stability or convexity properties when the embodiment parameters lie far from the training morphologies, which is load-bearing for the held-out-robot claim.
Authors: We agree that further analysis of gradient behavior would be beneficial. Our empirical results across held-out robots demonstrate successful optimization, suggesting practical stability in the tested regimes. However, we did not provide explicit analysis of gradient norms or convexity. In the revision, we will add plots and discussion of gradient norms during the optimization process for held-out cases to address stability. A full theoretical analysis of convexity is beyond the scope as the value function is a neural network, but we can discuss the empirical properties. revision: partial
Circularity Check
No circularity: standard train-freeze-optimize pipeline with independent held-out evaluation
full rationale
The paper trains an embodiment-aware policy and value function across a collection of robot designs, then freezes the value function to serve as a differentiable surrogate for gradient-based embodiment optimization on new or held-out designs. This workflow does not reduce any claimed result to its own fitted parameters by construction; the optimization step uses the learned model as an external surrogate rather than re-deriving quantities already implicit in the training data. Evaluation explicitly includes held-out robots across morphology classes, providing an independent test of generalization outside the training distribution. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the described chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Sims. Evolving 3d morphology and behavior by competition.Artificial life, 1(4):353–372, 1994
1994
-
[2]
Lipson and J
H. Lipson and J. B. Pollack. Automatic design and manufacture of robotic lifeforms.Nature, 406(6799):974–978, 2000
2000
-
[3]
K. S. Luck, H. B. Amor, and R. Calandra. Data-efficient co-adaptation of morphology and behaviour with deep reinforcement learning. InConference on Robot Learning, pages 854–
- [4]
-
[5]
Bohlinger, G
N. Bohlinger, G. Czechmanowski, M. Krupka, P. Kicki, K. Walas, J. Peters, and D. Tateo. One policy to run them all: an end-to-end learning approach to multi-embodiment locomotion. Conference on Robot Learning, 2024
2024
-
[6]
B. Ai, L. Dai, N. Bohlinger, D. Li, T. Mu, Z. Wu, K. Fay, H. I. Christensen, J. Peters, and H. Su. Towards embodiment scaling laws in robot locomotion.Conference on Robot Learning (CoRL), 2025
2025
-
[7]
R. C. Bertossa. Morphology and behaviour: functional links in development and evolution. Philosophical Transactions of the Royal Society B: Biological Sciences, 366(1574):2056– 2068, 2011
2056
-
[8]
G. S. Hornby and J. B. Pollack. Body-brain co-evolution using l-systems as a generative encod- ing. InProceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, pages 868–875, 2001
2001
-
[9]
T. Wang, Y . Zhou, S. Fidler, and J. Ba. Neural graph evolution: Towards efficient automatic robot design.arXiv preprint arXiv:1906.05370, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[10]
Banarse, Y
D. Banarse, Y . Bachrach, S. Liu, G. Lever, N. Heess, C. Fernando, P. Kohli, and T. Graepel. The body is not a given: Joint agent policy learning and morphology evolution. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, pages 1134–1142. International Foundation for Autonomous Agents and Multiagent Systems, 2019
2019
-
[11]
A. Zhao, J. Xu, M. Konakovi ´c-Lukovi´c, J. Hughes, A. Spielberg, D. Rus, and W. Matusik. Robogrammar: graph grammar for terrain-optimized robot design.ACM Transactions on Graphics (TOG), 39(6):1–16, 2020
2020
-
[12]
J. Xu, A. Spielberg, A. Zhao, D. Rus, and W. Matusik. Multi-objective graph heuristic search for terrestrial robot design. In2021 IEEE international conference on robotics and automation (ICRA), pages 9863–9869. IEEE, 2021
2021
- [13]
-
[14]
C. Schaff and M. R. Walter. N-limb: Neural limb optimization for efficient morphological design.arXiv preprint arXiv:2207.11773, 2022. 9
- [15]
- [16]
-
[17]
J. Hu, J. Whitman, and H. Choset. Glso: Grammar-guided latent space optimization for sample-efficient robot design automation. InConference on Robot Learning, pages 1321–
-
[18]
K. Ikemura, Y . Dong, and F. T. Pokorny. Latent diffeomorphic co-design of end-effectors for deformable and fragile object manipulation.arXiv preprint arXiv:2602.17921, 2026
-
[19]
Identifying Inductive Biases for Robot Co-Design
A. Vaish and O. Brock. Identifying inductive biases for robot co-design.arXiv preprint arXiv:2604.11768, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
D. Ha. Reinforcement learning for improving agent design.Artificial life, 25(4):352–365, 2019
2019
-
[21]
Schaff, D
C. Schaff, D. Yunis, A. Chakrabarti, and M. R. Walter. Jointly learning to construct and control agents using deep reinforcement learning. In2019 international conference on robotics and automation (ICRA), pages 9798–9805. IEEE, 2019
2019
-
[22]
T. Chen, Z. He, and M. Ciocarlie. Hardware as policy: Mechanical and computational co- optimization using deep reinforcement learning. InConference on Robot Learning, pages 1158–1173. PMLR, 2021
2021
-
[23]
Y . Wang, S. Wu, H. Fu, Q. Fu, T. Zhang, Y . Chang, and X. Wang. Curriculum-based co- design of morphology and control of voxel-based soft robots. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[24]
H. Dong, J. Zhang, T. Wang, and C. Zhang. Symmetry-aware robot design with structured sub- groups. InInternational Conference on Machine Learning, pages 8334–8355. PMLR, 2023
2023
-
[25]
M. Li, D. Matthews, and S. Kriegman. Reinforcement learning for freeform robot design. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8799–8806. IEEE, 2024
2024
-
[26]
H. Lu, Z. Wu, J. Xing, J. Li, R. Li, Z. Li, and Y . Shi. Bodygen: Advancing towards efficient embodiment co-design. InThe Thirteenth International Conference on Learning Representa- tions, 2025
2025
-
[27]
Y . Dai, Y . Wang, D. R. Ashley, and J. Schmidhuber. Efficient morphology–control co-design via stackelberg PPO. InThe Fourteenth International Conference on Learning Representa- tions, 2026
2026
-
[28]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[29]
Kennedy and R
J. Kennedy and R. Eberhart. Particle swarm optimization. InProceedings of ICNN’95- international conference on neural networks, volume 4, pages 1942–1948. ieee, 1995
1942
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
T. Wang, R. Liao, J. Ba, and S. Fidler. Nervenet: Learning structured policy with graph neural networks. InInternational conference on learning representations, 2018. 10
2018
-
[32]
Huang, I
W. Huang, I. Mordatch, and D. Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. InInternational Conference on Machine Learning, pages 4455–4464. PMLR, 2020
2020
-
[33]
Gupta, L
A. Gupta, L. Fan, S. Ganguli, and L. Fei-Fei. Metamorph: learning universal controllers with transformers. InInternational Conference on Learning Representations. ICLR, 2022
2022
-
[34]
Patel and S
A. Patel and S. Song. Get-zero: Graph embodiment transformer for zero-shot embodiment generalization. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 14262–14269. IEEE, 2025
2025
-
[35]
Sferrazza, D.-M
C. Sferrazza, D.-M. Huang, F. Liu, J. Lee, and P. Abbeel. Body transformer: Leveraging robot embodiment for policy learning. InConference on Robot Learning, pages 3407–3424. PMLR, 2025
2025
-
[36]
M. Liu, D. Pathak, and A. Agarwal. Locoformer: Generalist locomotion via long-context adaptation. InConference on Robot Learning, pages 532–546. PMLR, 2025
2025
-
[37]
D. Li, B. Ai, N. Bohlinger, J. Peters, H. I. Christensen, and H. Su. Online embodiment adap- tation for quadrupedal locomotion. 2026
2026
-
[38]
Smith, I
L. Smith, I. Kostrikov, and S. Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning. InRobotics: Science and systems, 2023
2023
-
[39]
Smith, Y
L. Smith, Y . Cao, and S. Levine. Grow your limits: Continuous improvement with real-world rl for robotic locomotion. InInternational conference on robotics and automation, pages 10829– 10836. IEEE, 2024
2024
-
[40]
J. Levy, T. Westenbroek, and D. Fridovich-Keil. Learning to walk from three minutes of real- world data with semi-structured dynamics models. InConference on robot learning, 2024
2024
-
[41]
Bohlinger, J
N. Bohlinger, J. Kinzel, D. Palenicek, L. Antczak, and J. Peters. Gait in eight: Efficient on-robot learning for omnidirectional quadruped locomotion.International Conference on Intelligent Robots and Systems, 2025
2025
-
[42]
N. Bohlinger and J. Peters. Multi-embodiment locomotion at scale with extreme embodiment randomization.arXiv preprint arXiv:2509.02815, 2025
-
[43]
Balandat, B
M. Balandat, B. Karrer, D. Jiang, S. Daulton, B. Letham, A. G. Wilson, and E. Bakshy. Botorch: A framework for efficient monte-carlo bayesian optimization.Advances in neural information processing systems, 33:21524–21538, 2020
2020
-
[44]
Hansen and A
N. Hansen and A. Ostermeier. Completely derandomized self-adaptation in evolution strate- gies.Evolutionary computation, 9(2):159–195, 2001
2001
-
[45]
R. Y . Rubinstein and D. P. Kroese.The cross-entropy method: a unified approach to combi- natorial optimization, Monte-Carlo simulation, and machine learning, volume 133. Springer, 2004
2004
-
[46]
Storn and K
R. Storn and K. Price. Differential evolution–a simple and efficient heuristic for global opti- mization over continuous spaces.Journal of global optimization, 11(4):341–359, 1997
1997
-
[47]
Mania, A
H. Mania, A. Guy, and B. Recht. Simple random search of static linear policies is competitive for reinforcement learning.Advances in neural information processing systems, 31, 2018
2018
-
[48]
Eriksson, M
D. Eriksson, M. Pearce, J. Gardner, R. D. Turner, and M. Poloczek. Scalable global optimiza- tion via local bayesian optimization.Advances in neural information processing systems, 32, 2019. 11
2019
- [49]
-
[50]
Faccio, L
F. Faccio, L. Kirsch, and J. Schmidhuber. Parameter-based value functions. InInternational Conference on Learning Representations, 2021
2021
-
[51]
Faccio, A
F. Faccio, A. Ramesh, V . Herrmann, J. Harb, and J. Schmidhuber. General policy evaluation and improvement by learning to identify few but crucial states. InDecision Awareness in Reinforcement Learning Workshop at ICML 2022, 2022
2022
-
[52]
N. Bohlinger and J. Peters. Massively scaling explicit policy-conditioned value functions. arXiv preprint arXiv:2502.11949, 2025
-
[53]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015
2015
-
[54]
Bohlinger and K
N. Bohlinger and K. Dorer. Rl-x: A deep reinforcement learning library (not only) for robocup. InRobot World Cup, pages 228–239. Springer, 2023
2023
-
[55]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
- [56]
-
[57]
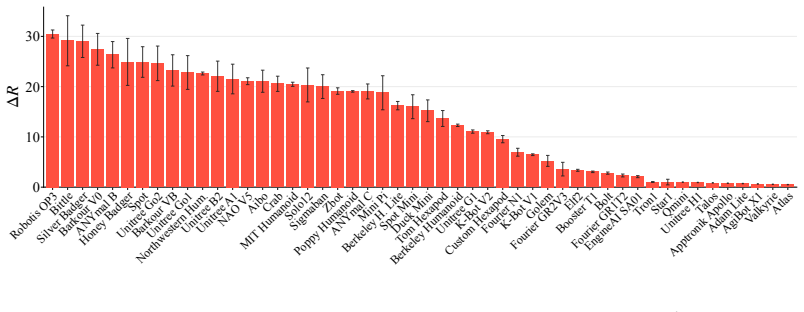
T. Salimans and D. P. Kingma. Weight normalization: A simple reparameterization to acceler- ate training of deep neural networks.Advances in neural information processing systems, 29, 2016. 12 Figure 6:Overview of all 50 robots used in the multi-embodiment RL training [42]. Appendix A Experimental Setup Details A.1 Environment All robots are simulated in ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.