Federated Foundation Models over Vehicular Networks
Pith reviewed 2026-06-27 22:55 UTC · model grok-4.3
The pith
Multi-modal multi-task federated foundation models integrate into vehicular networks to enable next-generation intelligence with privacy preservation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unifying the expressive power of multi-modal multi-task foundation models with the privacy-preserving and distributed learning capabilities of federated learning allows M3T FedFMs to be deployed over vehicular networks for next-generation vehicular intelligence.
What carries the argument
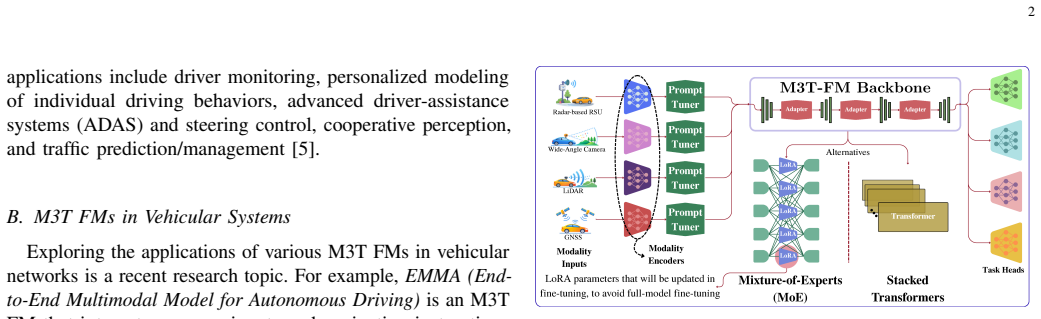
M3T FedFMs, defined as multi-modal multi-task federated foundation models that combine foundation-model expressiveness with federated-learning privacy and distribution.
If this is right
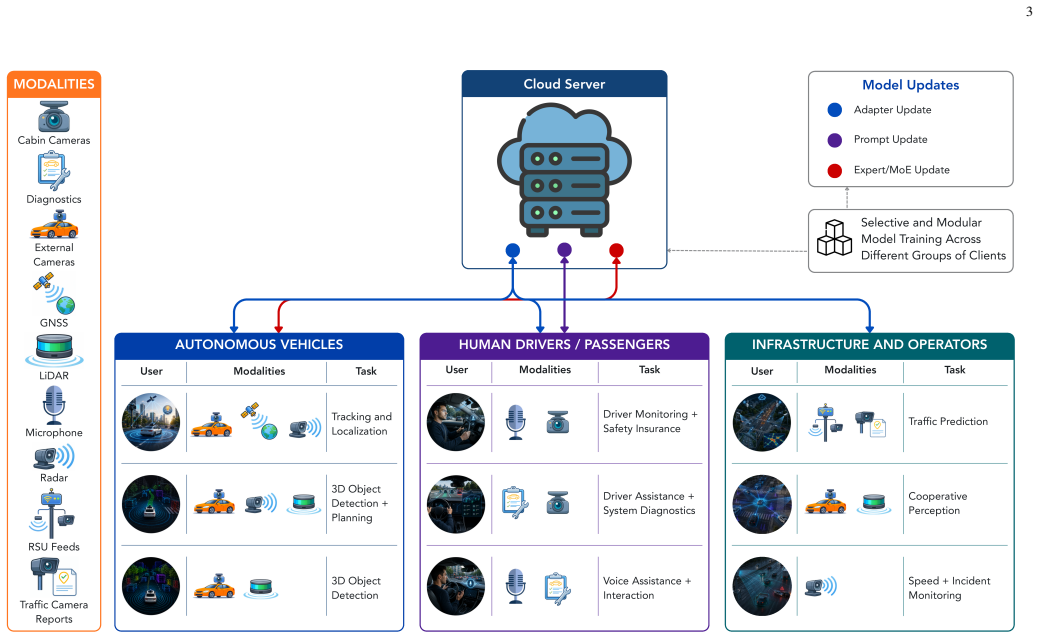
- Representative use cases include multi-modal perception for autonomous driving and collaborative decision-making across fleets.
- Practical deployment requires solutions for high mobility, limited onboard resources, and heterogeneous data distributions.
- Proposed research directions target these constraints to move from vision to implementation.
- The Waymo case study provides initial empirical support for the overall approach.
Where Pith is reading between the lines
- If the research directions succeed, similar model fusions could extend to other mobile settings such as drone swarms or roadside sensor networks.
- Releasing the implementation code lowers the barrier for others to test the same integration on different datasets or hardware.
- The approach implies a shift from centralized cloud training toward edge-based, privacy-first model evolution in transportation systems.
Load-bearing premise
The key constraints inherent to vehicular environments can be addressed through the proposed forward-looking research directions, enabling practical deployment of M3T FedFMs.
What would settle it
A follow-up experiment on additional real-world vehicular datasets that shows M3T FedFMs fail to deliver performance gains over simpler federated baselines while respecting latency and bandwidth limits would disprove the integration vision.
Figures
read the original abstract
This paper presents a forward-looking vision for integrating the emerging multi-modal multi-task federated foundation models (M3T FedFMs) into vehicular networks, with the goal of unifying the expressive power of multi-modal multi-task foundation models (M3T FMs) with the privacy-preserving and distributed learning capabilities of federated learning (FL). Given the largely underexplored nature of this research direction, we first introduce the fundamental training/fine-tuning principles of M3T FedFMs. We then discuss a range of their representative use cases in vehicular networks, illustrating the significant potential of M3T FedFMs to enable next-generation vehicular intelligence. Afterwards, we identify key constraints inherent to vehicular environments that challenge the practical deployment of M3T FedFMs, and articulate a set of forward-looking research directions to address these challenges. Furthermore, through a case study conducted on a real-world vehicular dataset (i.e., Waymo Open Dataset), we demonstrate the promise of M3T FedFMs for vehicular networks and release our implementation to facilitate reproducibility and stimulate research in this emerging area (repository: https://github.com/KasraBorazjani/vehicular-fedfm)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a forward-looking vision for integrating multi-modal multi-task federated foundation models (M3T FedFMs) into vehicular networks. It unifies the capabilities of M3T foundation models with federated learning (FL) to enable privacy-preserving distributed intelligence in vehicles. The manuscript introduces training principles, representative use cases, key vehicular constraints (mobility, latency, connectivity), forward-looking research directions to address them, and a case study on the Waymo Open Dataset demonstrating basic promise, with code released for reproducibility.
Significance. If the proposed integration proves feasible, the work could open a new research direction at the intersection of foundation models, FL, and vehicular networks, enabling advanced multi-modal tasks under privacy constraints. The release of implementation code is a positive contribution that supports reproducibility and further exploration.
major comments (2)
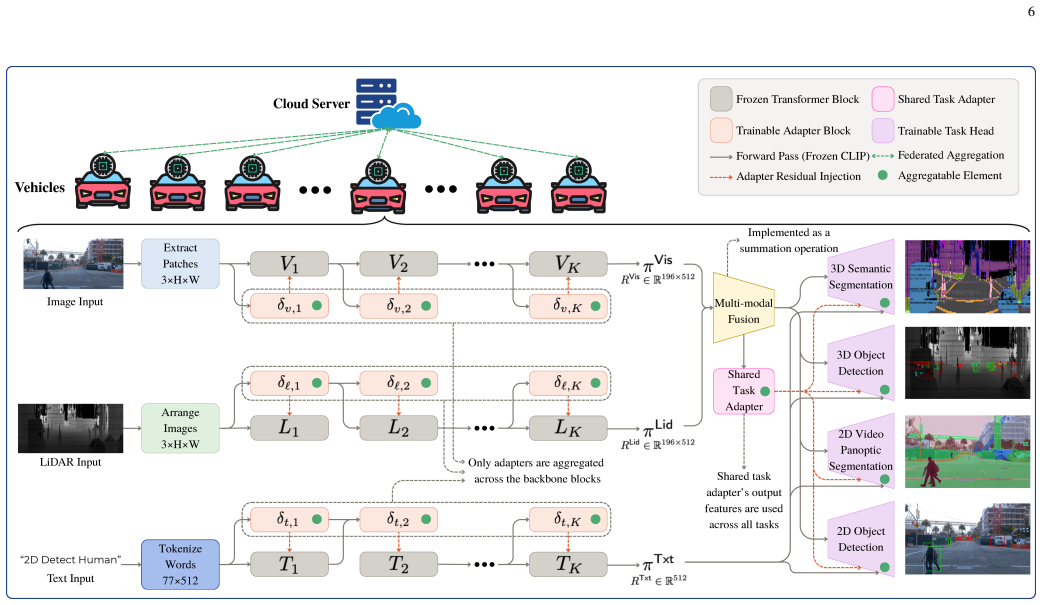
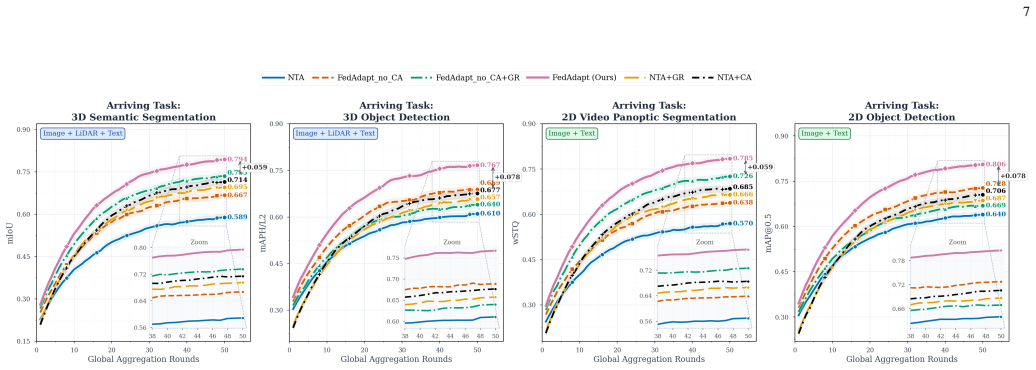
- [Case study / Waymo evaluation] Case study section: The evaluation on the Waymo Open Dataset demonstrates basic multi-task performance but does not incorporate or simulate any vehicular network dynamics (e.g., high mobility, intermittent connectivity, or strict latency requirements) identified earlier as central challenges. This leaves the claim of 'demonstrat[ing] the promise of M3T FedFMs for vehicular networks' unsupported by evidence addressing the paper's own constraints.
- [Research directions] Research directions section: The listed forward-looking directions (specific FL variants, model adaptations, architectures) are articulated at a high level without any quantitative analysis, preliminary simulations, theoretical bounds, or feasibility arguments showing they can resolve the identified constraints such as mobility-induced data heterogeneity or latency/privacy trade-offs. This makes the central deployment claim rest on an untested assumption.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction use the acronym M3T FedFMs before fully defining it; a brief parenthetical expansion on first use would improve readability.
- [Figures / Case study] Figure captions and the case study description could more explicitly note which vehicular constraints are (or are not) modeled, to align with the challenges section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comments below, clarifying the scope of our vision paper and proposing revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Case study / Waymo evaluation] Case study section: The evaluation on the Waymo Open Dataset demonstrates basic multi-task performance but does not incorporate or simulate any vehicular network dynamics (e.g., high mobility, intermittent connectivity, or strict latency requirements) identified earlier as central challenges. This leaves the claim of 'demonstrat[ing] the promise of M3T FedFMs for vehicular networks' unsupported by evidence addressing the paper's own constraints.
Authors: We agree that the case study evaluates multi-task performance on the Waymo Open Dataset without simulating network dynamics such as mobility or connectivity. As this is a vision paper, the case study is intended to validate the core M3T capabilities on real vehicular sensor data as a foundational step, while network constraints and their integration with federated learning are addressed conceptually in the challenges and research directions sections. We will revise the abstract, introduction, and conclusion to clarify that the case study demonstrates the promise of the M3T components for vehicular data, with full deployment under vehicular network constraints positioned as future work. revision: yes
-
Referee: [Research directions] Research directions section: The listed forward-looking directions (specific FL variants, model adaptations, architectures) are articulated at a high level without any quantitative analysis, preliminary simulations, theoretical bounds, or feasibility arguments showing they can resolve the identified constraints such as mobility-induced data heterogeneity or latency/privacy trade-offs. This makes the central deployment claim rest on an untested assumption.
Authors: We acknowledge that the research directions are outlined at a high level. This aligns with the vision-paper scope, which aims to identify open problems and promising approaches rather than deliver quantitative solutions. We will revise the section to incorporate additional references to related literature offering preliminary feasibility insights or bounds for several directions, thereby providing stronger grounding without introducing new experiments. revision: partial
Circularity Check
Vision paper with no derivations or self-referential predictions
full rationale
The paper is a high-level vision proposal introducing M3T FedFMs concepts, use cases, constraints, and research directions, plus a case study on the Waymo dataset. No equations, parameter fits, or predictions are present that could reduce to inputs by construction. No load-bearing self-citations or uniqueness claims are invoked. The central claim is a forward-looking unification proposal whose feasibility is left to future work, making the derivation chain self-contained with no circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vehicular networks possess sufficient communication and computation resources to support federated training of large foundation models.
- domain assumption Multi-modal multi-task foundation models can be effectively fine-tuned in a federated manner across distributed vehicular clients.
invented entities (1)
-
M3T FedFMs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wang,et al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
2024
-
[2]
Multi-modal sensor fusion for auto driving perception: A survey,
K. Huang, B. Shi, X. Li, X. Li, S. Huang, and Y . Li, “Multi-modal sensor fusion for auto driving perception: A survey,”arXiv preprint arXiv:2202.02703, 2022
arXiv 2022
-
[3]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics, pp. 1273–1282, PMLR, 2017
2017
-
[4]
Advances and open challenges in federated foundation models,
C. Ren, H. Yu, H. Peng, X. Tang, B. Zhao, L. Yi, A. Z. Tan, Y . Gao, A. Li, X. Li,et al., “Advances and open challenges in federated foundation models,”IEEE Communications Surveys & Tutorials, 2025
2025
-
[5]
Federated learning for vehicular internet of things: Recent advances and open issues,
Z. Du, C. Wu, T. Yoshinaga, K.-L. A. Yau, Y . Ji, and J. Li, “Federated learning for vehicular internet of things: Recent advances and open issues,”IEEE Open Journal of the Computer Society, vol. 1, pp. 45–61, 2020
2020
-
[6]
EMMA: End-to-end multimodal model for autonomous driving,
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp,et al., “EMMA: End-to-end multimodal model for autonomous driving,”arXiv preprint arXiv:2410.23262, 2024. 8
Pith/arXiv arXiv 2024
-
[7]
Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models,
T.-H. Wang, A. Maalouf, W. Xiao, Y . Ban, A. Amini, G. Rosman, S. Karaman, and D. Rus, “Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 6687– 6694, IEEE, 2024
2024
-
[8]
Deepin- teraction++: Multi-modality interaction for autonomous driving,
Z. Yang, N. Song, W. Li, X. Zhu, L. Zhang, and P. H. Torr, “Deepin- teraction++: Multi-modality interaction for autonomous driving,”arXiv preprint arXiv:2408.05075, 2024
arXiv 2024
-
[9]
W.-B. Kou, Q. Lin, M. Tang, S. Xu, R. Ye, Y . Leng, S. Wang, G. Li, Z. Chen, G. Zhu,et al., “pFedLVM: A large vision model (LVM)-driven and latent feature-based personalized federated learning framework in autonomous driving,”arXiv preprint arXiv:2405.04146, 2024
arXiv 2024
-
[10]
On disentanglement of asymmetrical knowledge transfer for modality-task agnostic federated learning,
J. Chen and A. Zhang, “On disentanglement of asymmetrical knowledge transfer for modality-task agnostic federated learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 11311–11319, 2024
2024
-
[11]
FedDAT: An approach for foundation model finetuning in multi-modal heterogeneous federated learning,
H. Chen, Y . Zhang, D. Krompass, J. Gu, and V . Tresp, “FedDAT: An approach for foundation model finetuning in multi-modal heterogeneous federated learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 11285–11293, 2024
2024
-
[12]
Rothman,Transformers for Natural Language Processing and Computer Vision: Explore Generative AI and Large Language Models with Hugging Face, ChatGPT, GPT-4V , and DALL-E 3
D. Rothman,Transformers for Natural Language Processing and Computer Vision: Explore Generative AI and Large Language Models with Hugging Face, ChatGPT, GPT-4V , and DALL-E 3. Packt Publishing Ltd, 2024
2024
-
[13]
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,
A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo,et al., “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,”arXiv preprint arXiv:2405.04434, 2024
Pith/arXiv arXiv 2024
-
[14]
Conflict-averse gradient de- scent for multi-task learning,
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu, “Conflict-averse gradient de- scent for multi-task learning,”Advances in neural information processing systems, vol. 34, pp. 18878–18890, 2021
2021
-
[15]
GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks,
Z. Chen, V . Badrinarayanan, C.-Y . Lee, and A. Rabinovich, “GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks,” inInternational conference on machine learning, pp. 794–803, PMLR, 2018. Kasra Borazjaniis a Ph.D. student in the Department of Electrical Engineering at the University at Buffalo–SUNY , USA. Fardis Nadimii...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.